knn search algorithm comparison
1.0.0
1951年に導入されたK-Nearest Neighbors(K-NN)アルゴリズムは、分類タスクと回帰タスクの両方に広く使用されています。コアコンセプトには、データセット内の特定のクエリポイントに最も類似したインスタンス(近隣)を識別し、これらのネイバーを使用して予測または分類を行うことが含まれます。近年、特にテキストおよびその他のデータの広範なデータセットを処理する際に大規模な言語モデル(LLM)をサポートする情報を取得するために、ベクトルデータベースとベクトルインデックスの重要性が高まっています。このアプリケーションの顕著な例は、検索された生成(RAG)です。
このプロジェクトでは、さまざまなデータセットサイズと寸法にわたるさまざまなK-NN検索アルゴリズムのパフォーマンスを比較します。比較されたアルゴリズムは次のとおりです。
KD-Tree(K次元ツリー):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
ポイント:a(1,3)、b(3,1)、c(4,3)、d(3,3)ツリー構造:root(x = 2) - >左(y = 2) - >右(x = 3)
ボールツリー:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
外側の円にはすべてのポイントが含まれ、内側円はサブセットを分割します。
完全なKNN(ブルートフォース):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
距離の計算:QA = 1.41、QB = 1、QC = 2.24、QD = 1.41結果:最寄りの2つの隣人はBとA(またはD)です
HNSW(階層航行可能な小さな世界):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
検索は、上層のランダムなポイントで始まり、下降し、底に到達するまで各レベルの隣人を探索します。
これらのアルゴリズムの選択は、データセットのサイズ、寸法、必要な精度、クエリ速度に依存します。 KD-Treeとボールツリーは正確な結果を提供し、低から中程度の寸法に効率的です。完全なKNNは単純ですが、大きなデータセットでは遅くなります。 HNSWは、特に高次元データまたは大規模なデータセットの場合、速度と精度のバランスが良いです。
このリポジトリをクローンします:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
仮想環境を作成します(オプションですが推奨):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
必要な依存関係をインストールします。
pip install -r requirements.txt
これにより、numpy、scipy、scikit-learn、hnswlib、tabulate、tqdmなど、 requirements.txtファイルにリストされている必要なすべてのパッケージがインストールされます。
デフォルトのパラメーターで比較テストを実行するには:
python app.py
コマンドライン引数を使用して、テストパラメーターをカスタマイズすることもできます。
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
利用可能な議論:
--vectors :テストするベクトルカウントのリスト(デフォルト:1000、2000、5000、10000、20000、50000、100000、200000)--dimensions :テストする寸法のリスト(デフォルト:4 16 256 1024)--num-tests :各組み合わせに対して実行するテストの数(デフォルト:10)--k :検索する最寄りの隣人の数(デフォルト:10)スクリプトには、実行中に進行状況バーが表示され、残りの時間の推定値が表示されます。
スクリプトは、Ctrl+cを押すことでいつでも中断することができます。 HNSWインデックスの構築などの時間のかかる操作中であっても、優雅に終了しようとします。
スクリプトは進行状況を表示し、コンソールに結果をもたらします。完了後、ご覧のとおりです。
単一の組み合わせの出力の例:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
最終結果テーブルとCSVファイルには、各アルゴリズムのビルド時間と検索時間の両方が含まれているため、さまざまなベクトル数と寸法にわたるパフォーマンスの包括的な比較が可能になります。
app.pyの次の変数を変更して、テストパラメーターを調整できます。
NUM_VECTORS_LIST :テストするベクトルカウントのリストNUM_DIMENSIONS_LIST :テストする寸法のリストNUM_TESTS :各組み合わせに対して実行するテストの数K :検索する最寄りの隣人の数貢献は大歓迎です!プルリクエストをお気軽に送信してください。
このプロジェクトはオープンソースであり、MITライセンスの下で利用可能です。
以下は、KNN検索結果を示すチャートです。
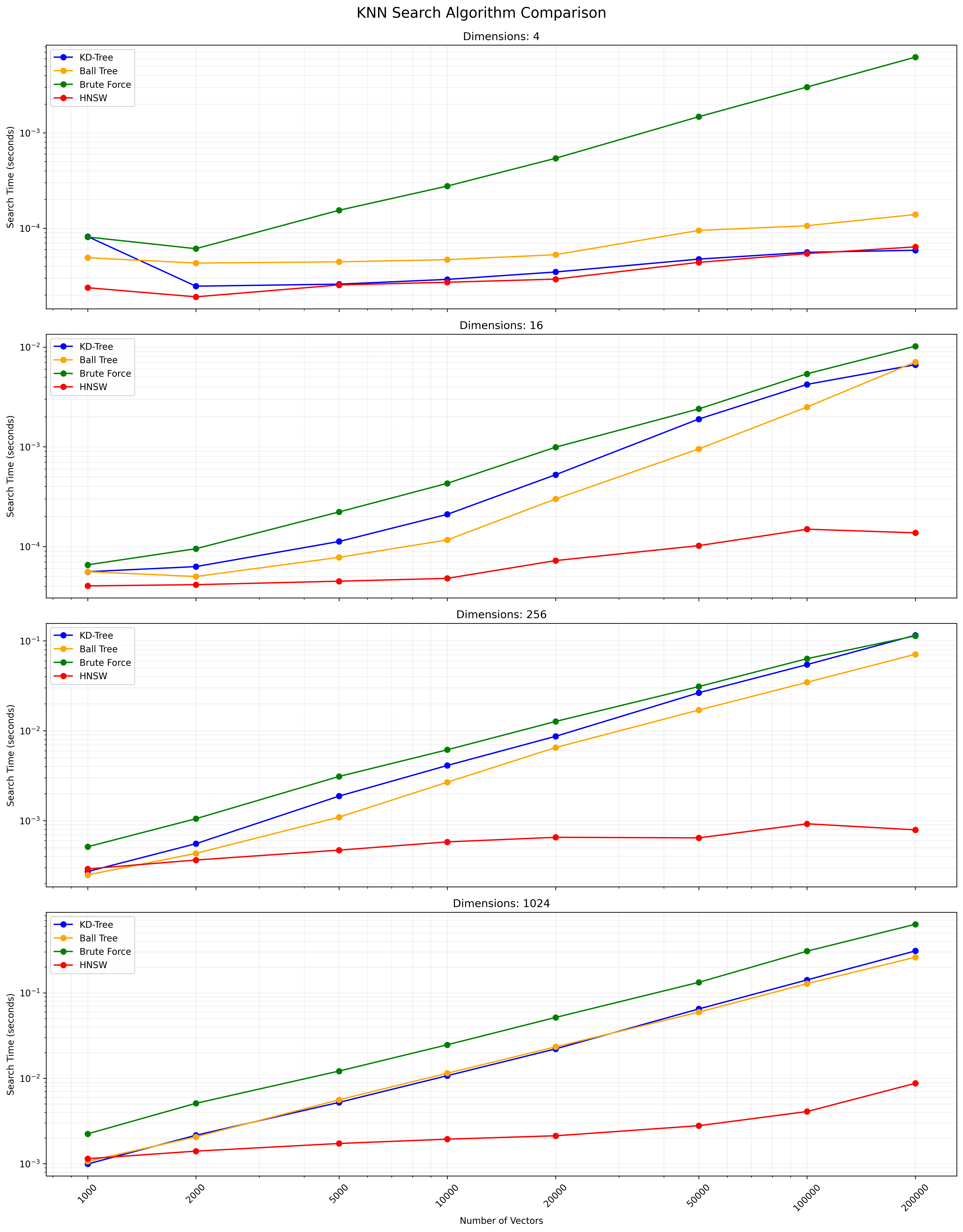
詳細な結果を含むCSVファイルはこちらから入手できます。


