knn search algorithm comparison
1.0.0
Algoritma tetangga K-Nearest (K-NN), yang diperkenalkan pada tahun 1951, telah banyak digunakan untuk tugas klasifikasi dan regresi. Konsep inti melibatkan mengidentifikasi K yang paling mirip (tetangga) ke titik kueri yang diberikan dalam dataset dan menggunakan tetangga ini untuk membuat prediksi atau klasifikasi. Dalam beberapa tahun terakhir, pentingnya basis data vektor dan indeks vektor telah berkembang, terutama untuk pengambilan informasi untuk mendukung model bahasa besar (LLM) dalam memproses set data teks yang luas dan data lainnya. Contoh yang menonjol dari aplikasi ini adalah Retrieval-Agusted Generation (RAG).
Proyek ini membandingkan kinerja berbagai algoritma pencarian K-NN di berbagai ukuran dan dimensi dataset. Algoritma dibandingkan adalah:
KD-Tree (pohon K-dimensi):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Poin: A (1,3), B (3,1), C (4,3), D (3,3) Struktur pohon: root (x = 2) -> kiri (y = 2) -> kanan (x = 3)
Pohon bola:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
Lingkaran luar berisi semua titik, lingkaran dalam membagi subset.
Knn penuh (brute force):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Hitung Jarak: QA = 1.41, QB = 1, QC = 2.24, QD = 1.41 Hasil: 2 tetangga terdekat adalah B dan A (atau D)
HNSW (Dunia Kecil yang Dapat Dilakukan Hierarkis):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
Pencarian dimulai pada titik acak di lapisan atas dan turun, menjelajahi tetangga di setiap level sampai mencapai bagian bawah.
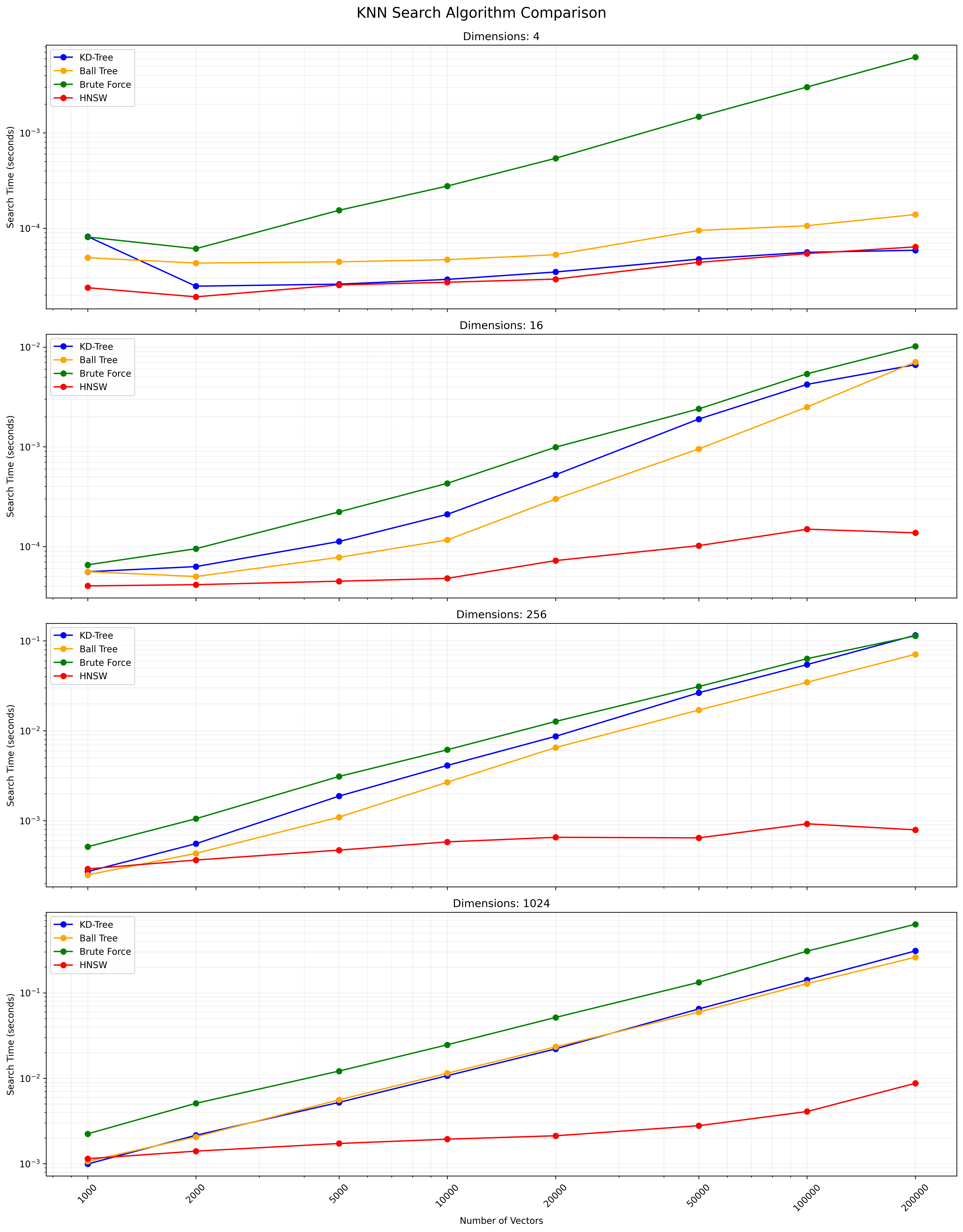
Pilihan antara algoritma ini tergantung pada ukuran dataset, dimensi, akurasi yang diperlukan, dan kecepatan kueri. Tree KD dan pohon bola memberikan hasil yang tepat dan efisien untuk dimensi rendah hingga sedang. Knn penuh sederhana tetapi menjadi lambat untuk kumpulan data besar. HNSW menawarkan keseimbangan yang baik antara kecepatan dan akurasi, terutama untuk data dimensi tinggi atau kumpulan data besar.
Klon Repositori ini:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Buat lingkungan virtual (opsional tetapi direkomendasikan):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Instal dependensi yang diperlukan:
pip install -r requirements.txt
Ini akan menginstal semua paket yang diperlukan yang tercantum dalam file requirements.txt , termasuk numpy, scipy, scikit-learn, hnswlib, tabulate, dan tqdm.
Untuk menjalankan tes perbandingan dengan parameter default:
python app.py
Anda juga dapat menyesuaikan parameter uji menggunakan argumen baris perintah:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Argumen yang tersedia:
--vectors : Daftar jumlah vektor untuk diuji (default: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : Daftar Dimensi yang akan diuji (default: 4 16 256 1024)--num-tests : Jumlah tes yang harus dijalankan untuk setiap kombinasi (default: 10)--k : Jumlah tetangga terdekat untuk dicari (default: 10)Skrip akan menampilkan bilah kemajuan selama eksekusi, memberi Anda perkiraan waktu yang tersisa.
Script dapat terganggu kapan saja dengan menekan Ctrl+C. Ini akan berusaha untuk keluar dengan anggun, bahkan selama operasi yang memakan waktu seperti membangun indeks HNSW.
Script akan menampilkan kemajuan dan menghasilkan konsol. Setelah selesai, Anda akan melihat:
Contoh output untuk kombinasi tunggal:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
Tabel hasil akhir dan file CSV akan mencakup waktu pembuatan dan waktu pencarian untuk setiap algoritma, memungkinkan perbandingan kinerja yang komprehensif di berbagai jumlah dan dimensi vektor.
Anda dapat memodifikasi variabel berikut di app.py untuk menyesuaikan parameter uji:
NUM_VECTORS_LIST : daftar jumlah vektor untuk diujiNUM_DIMENSIONS_LIST : Daftar dimensi yang akan diujiNUM_TESTS : Jumlah tes yang harus dijalankan untuk setiap kombinasiK : Jumlah tetangga terdekat yang ingin dicari Kontribusi dipersilakan! Silakan mengirimkan permintaan tarik.
Proyek ini adalah open source dan tersedia di bawah lisensi MIT.
Di bawah ini adalah grafik yang menunjukkan hasil pencarian KNN:
File CSV yang berisi hasil terperinci tersedia di sini.


