knn search algorithm comparison
1.0.0
Der 1951 eingeführte K-Nearest-Nachbarn (K-NN) -Algorithmus wurde sowohl für die Klassifizierung als auch für die Regressionsaufgaben häufig verwendet. Das Kernkonzept beinhaltet die Identifizierung der K -ähnlichen Instanzen (Nachbarn) zu einem bestimmten Abfragepunkt innerhalb eines Datensatzes und die Verwendung dieser Nachbarn, um Vorhersagen oder Klassifizierungen vorzunehmen. In den letzten Jahren hat die Bedeutung von Vektordatenbanken und Vektorindizes gewachsen, insbesondere für das Abrufen von Informationen zur Unterstützung großer Sprachmodelle (LLMs) bei der Verarbeitung umfangreicher Datensätze von Text und anderen Daten. Ein herausragendes Beispiel für diese Anwendung ist die ARRAVEAL-AUGmented Generation (RAG).
Dieses Projekt vergleicht die Leistung verschiedener K-NN-Suchalgorithmen über verschiedene Datensatzgrößen und -abmessungen. Die verglichenen Algorithmen sind:
KD-Tree (k-dimensionaler Baum):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Punkte: a (1,3), b (3,1), c (4,3), d (3,3) Baumstruktur: Wurzel (x = 2) -> links (y = 2) -> rechts (x = 3)
Ballbaum:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
Der äußere Kreis enthält alle Punkte, innere Kreise teilen Untergruppen.
Full Knn (Brute Force):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Berechnen Sie Abstände: QA = 1,41, QB = 1, QC = 2,24, QD = 1,41 Ergebnis: Nächste 2 Nachbarn sind b und a (oder d)
HNSW (hierarchische schiffbare kleine Welt):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
Die Suche beginnt an einem zufälligen Punkt in der oberen Schicht und steigt ab und erkundet die Nachbarn auf jeder Ebene, bis er den Boden erreicht.
Die Auswahl zwischen diesen Algorithmen hängt von der Datensatzgröße, der Dimensionalität, der erforderlichen Genauigkeit und der Abfragegeschwindigkeit ab. KD-Baum und Ballbaum liefern genaue Ergebnisse und sind für niedrige bis mittelschwere Abmessungen effizient. Full KNN ist einfach, wird aber für große Datensätze langsam. HNSW bietet ein gutes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit, insbesondere für hochdimensionale Daten oder große Datensätze.
Klonen Sie dieses Repository:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Erstellen Sie eine virtuelle Umgebung (optional, aber empfohlen):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Installieren Sie die erforderlichen Abhängigkeiten:
pip install -r requirements.txt
Dadurch werden alle erforderlichen Pakete installiert, die in der Datei requirements.txt aufgeführt sind, einschließlich Numpy, Scipy, Scikit-Learn, HNSWLIB, Tabulat und TQDM.
So führen Sie die Vergleichstests mit Standardparametern aus:
python app.py
Sie können die Testparameter auch anhand von Befehlszeilenargumenten anpassen:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Verfügbare Argumente:
--vectors : Liste der zu testenden Vektorzahlen (Standardeinstellung: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : Liste der zu testenden Abmessungen (Standardeinstellung: 4 16 256 1024)--num-tests : Anzahl der für jede Kombination ausgeführten Tests (Standard: 10)--k : Anzahl der nächsten Nachbarn, nach denen sie suchen sollten (Standard: 10)Das Skript zeigt während der Ausführung eine Fortschrittsleiste an und gibt Ihnen einen Schätzung der verbleibenden Zeit.
Das Skript kann jederzeit durch Drücken von Strg+c unterbrochen werden. Es wird versuchen, anmutig zu gehen, auch bei zeitaufwändigen Operationen wie dem Aufbau des HNSW-Index.
Das Skript zeigt den Fortschritt an und führt in der Konsole. Nach Abschluss sehen Sie:
Beispielausgabe für eine einzelne Kombination:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
Die endgültige Ergebnistabelle und die CSV -Datei umfassen sowohl Erstellungszeiten als auch Suchzeiten für jeden Algorithmus, der einen umfassenden Vergleich der Leistung über verschiedene Vektorzahlen und -abmessungen hinweg ermöglicht.
Sie können die folgenden Variablen in app.py ändern, um die Testparameter anzupassen:
NUM_VECTORS_LIST : Liste der Vektorzahlen zum TestenNUM_DIMENSIONS_LIST : Liste der zu testenden DimensionenNUM_TESTS : Anzahl der Tests, die für jede Kombination ausgeführt werden sollenK : Anzahl der nächsten Nachbarn, nach denen sie suchen sollten Beiträge sind willkommen! Bitte zögern Sie nicht, eine Pull -Anfrage einzureichen.
Dieses Projekt ist Open Source und erhältlich unter der MIT -Lizenz.
Im Folgenden finden Sie ein Diagramm, das die KNN -Suchergebnisse zeigt:
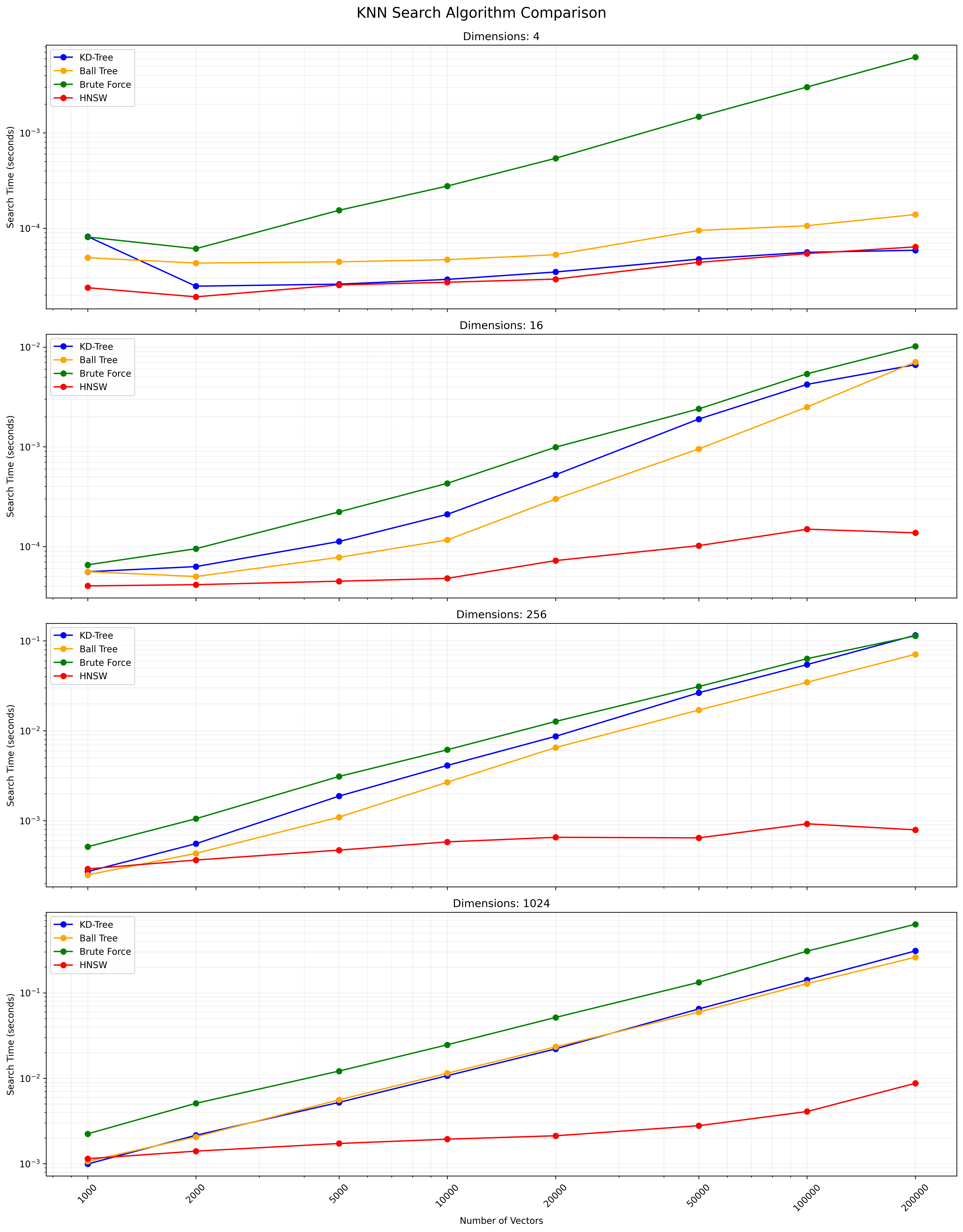
Hier finden Sie eine CSV -Datei, die die detaillierten Ergebnisse enthält.


