knn search algorithm comparison
1.0.0
L'algorithme K-Dearest Neighbors (K-NN), introduit en 1951, a été largement utilisé pour les tâches de classification et de régression. Le concept de base consiste à identifier les K les plus similaires (voisins) à un point de requête donné dans un ensemble de données et à utiliser ces voisins pour faire des prédictions ou des classifications. Ces dernières années, l'importance des bases de données vectorielles et des indices vectorielles a augmenté, en particulier pour la récupération d'informations pour prendre en charge les modèles de grands langues (LLM) dans le traitement des ensembles de données approfondis de texte et d'autres données. Un exemple important de cette application est la génération (RAG) (RAG) de la récupération.
Ce projet compare les performances de différents algorithmes de recherche K-NN à travers différentes tailles et dimensions de l'ensemble de données. Les algorithmes comparés sont:
KD-arche (arbre K-Dimension):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Points: A (1,3), B (3,1), C (4,3), D (3,3) Structure des arbres: racine (x = 2) -> gauche (y = 2) -> droite (x = 3)
Arbre à balle:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
Le cercle extérieur contient tous les points, les cercles intérieurs divisent les sous-ensembles.
Full Knn (force brute):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Calculer les distances: QA = 1,41, QB = 1, QC = 2,24, QD = 1,41 Résultat: 2 voisins les plus proches sont B et A (ou D)
HNSW (petit monde navigable hiérarchique):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
La recherche commence à un point aléatoire dans la couche supérieure et descend, explorant les voisins à chaque niveau jusqu'à atteindre le fond.
Le choix entre ces algorithmes dépend de la taille de l'ensemble de données, de la dimensionnalité, de la précision requise et de la vitesse de requête. L'arbre KD et l'arbre à balle fournissent des résultats exacts et sont efficaces pour des dimensions faibles à modérées. Full KNN est simple mais devient lent pour les grands ensembles de données. HNSW offre un bon équilibre entre la vitesse et la précision, en particulier pour les données de grande dimension ou les grands ensembles de données.
Cloner ce référentiel:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Créez un environnement virtuel (facultatif mais recommandé):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Installez les dépendances requises:
pip install -r requirements.txt
Cela installera tous les packages nécessaires répertoriés dans le fichier requirements.txt , y compris Numpy, Scipy, Scikit-Learn, Hnswlib, Tabulate et TQDM.
Pour exécuter les tests de comparaison avec les paramètres par défaut:
python app.py
Vous pouvez également personnaliser les paramètres de test à l'aide d'arguments de ligne de commande:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Arguments disponibles:
--vectors : Liste des comptes de vecteurs à tester (par défaut: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : liste des dimensions à tester (par défaut: 4 16 256 1024)--num-tests : Nombre de tests à exécuter pour chaque combinaison (par défaut: 10)--k : Nombre de voisins les plus proches à rechercher (par défaut: 10)Le script affichera une barre de progression pendant l'exécution, vous donnant une estimation du temps restant.
Le script peut être interrompu à tout moment en appuyant sur Ctrl + c. Il tentera de quitter gracieusement, même pendant des opérations longues comme la construction de l'indice HNSW.
Le script affichera les progrès et les résultats dans la console. Une fois terminé, vous verrez:
Exemple de sortie pour une seule combinaison:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
Le tableau des résultats finaux et le fichier CSV incluront à la fois les temps de construction et les temps de recherche pour chaque algorithme, permettant une comparaison complète des performances à travers différents dénombrements et dimensions de vecteurs.
Vous pouvez modifier les variables suivantes dans app.py pour ajuster les paramètres de test:
NUM_VECTORS_LIST : la liste des comptes de vecteurs à testerNUM_DIMENSIONS_LIST : liste des dimensions à testerNUM_TESTS : nombre de tests à exécuter pour chaque combinaisonK : nombre de voisins les plus proches à rechercher Les contributions sont les bienvenues! N'hésitez pas à soumettre une demande de traction.
Ce projet est open source et disponible sous la licence du MIT.
Vous trouverez ci-dessous un graphique montrant les résultats de recherche KNN:
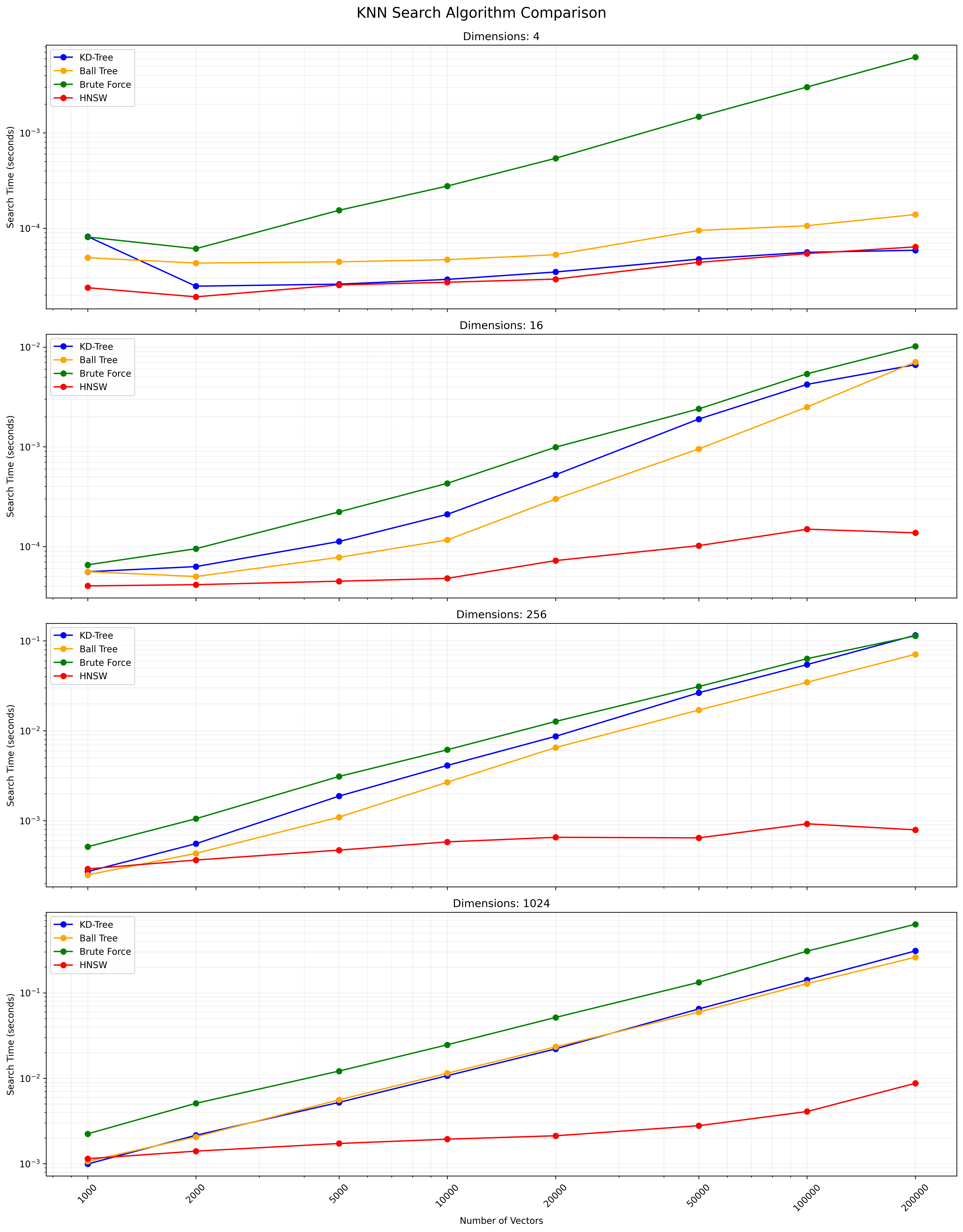
Un fichier CSV contenant les résultats détaillés est disponible ici.


