knn search algorithm comparison
1.0.0
1951 년에 소개 된 K-NN (K-NEARSEST Neighbors) 알고리즘은 분류 및 회귀 작업 모두에 널리 사용되었습니다. 핵심 개념은 데이터 세트 내에서 주어진 쿼리 지점에 가장 유사한 인스턴스 (이웃)를 식별하고 이러한 이웃을 사용하여 예측 또는 분류를 수행하는 것입니다. 최근 몇 년 동안 벡터 데이터베이스 및 벡터 인덱스의 중요성은 특히 텍스트 및 기타 데이터의 광범위한 데이터 세트를 처리 할 때 큰 언어 모델 (LLM)을 지원하기위한 정보 검색을 위해 성장했습니다. 이 응용 프로그램의 두드러진 예는 검색된 세대 (RAG)입니다.
이 프로젝트는 다양한 데이터 세트 크기 및 차원에서 다양한 K-NN 검색 알고리즘의 성능을 비교합니다. 비교 된 알고리즘은 다음과 같습니다.
KD-Tree (K- 차원 트리) :
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
포인트 : A (1,3), B (3,1), C (4,3), d (3,3) 트리 구조 : 루트 (x = 2) -> 왼쪽 (y = 2) -> 오른쪽 (x = 3)
볼 트리 :
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
외부 원에는 모든 지점이 포함되어 있으며 내부 원은 서브 세트를 분할합니다.
전체 KNN (Brute Force) :
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
거리 계산 : QA = 1.41, QB = 1, QC = 2.24, QD = 1.41 결과 : 가장 가까운 2 이웃은 B 및 A (또는 D)입니다.
HNSW (계층 적 항해 가능한 작은 세계) :
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
검색은 상단 레이어의 임의의 지점에서 시작하여 내려 가서 하단에 도달 할 때까지 각 레벨의 이웃을 탐색합니다.
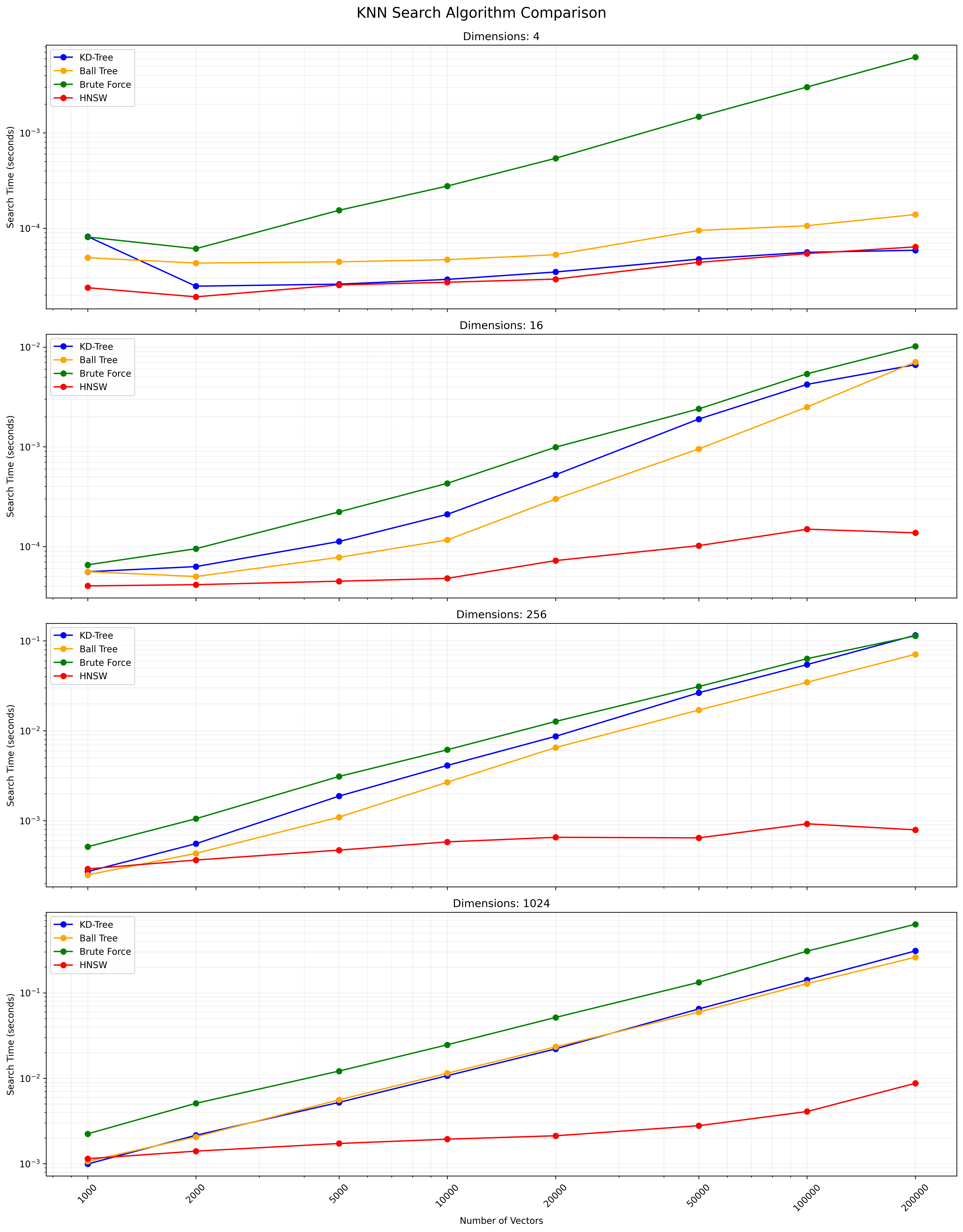
이러한 알고리즘 사이의 선택은 데이터 세트 크기, 치수, 필요한 정확도 및 쿼리 속도에 따라 다릅니다. KD-Tree 및 Ball Tree는 정확한 결과를 제공하며 낮거나 중간 정도의 치수에 효율적입니다. Full KNN은 간단하지만 대형 데이터 세트의 경우 느립니다. HNSW는 특히 고차원 데이터 또는 대규모 데이터 세트의 속도와 정확도 사이의 균형을 제공합니다.
이 저장소를 복제하십시오.
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
가상 환경을 만듭니다 (선택 사항이지만 권장) :
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
필요한 종속성 설치 :
pip install -r requirements.txt
Numpy, Scipy, Scikit-Learn, Hnswlib, Tabulate 및 TQDM을 포함하여 requirements.txt 에 나열된 모든 필요한 패키지를 설치합니다.
기본 매개 변수로 비교 테스트를 실행하려면 :
python app.py
명령 줄 인수를 사용하여 테스트 매개 변수를 사용자 정의 할 수도 있습니다.
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
사용 가능한 논쟁 :
--vectors : 테스트 할 벡터 카운트 목록 (기본값 : 1000, 2000, 5000, 100000, 20000, 50000, 100000, 200000)--dimensions : 테스트 할 차원 목록 (기본값 : 4 16 256 1024)--num-tests : 각 조합에 대해 실행할 테스트 수 (기본값 : 10)--k : 검색 할 가장 가까운 이웃 수 (기본값 : 10)스크립트는 실행 중에 진행률 표시 줄을 표시하여 나머지 시간을 추정합니다.
Ctrl+c를 눌러 스크립트를 언제든지 중단 할 수 있습니다. HNSW 인덱스 구축과 같은 시간이 많이 걸리는 작업 중에도 우아하게 종료하려고합니다.
스크립트는 진행 상황을 표시하고 콘솔에서 결과를 나타냅니다. 완료 후 다음을 볼 수 있습니다.
단일 조합의 예제 출력 :
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
최종 결과 테이블 및 CSV 파일에는 각 알고리즘에 대한 빌드 시간 및 검색 시간이 모두 포함되어있어 다양한 벡터 수와 치수에 대한 성능을 포괄적으로 비교할 수 있습니다.
app.py 에서 다음 변수를 수정하여 테스트 매개 변수를 조정할 수 있습니다.
NUM_VECTORS_LIST : 테스트 할 벡터 카운트 목록NUM_DIMENSIONS_LIST : 테스트 할 차원 목록NUM_TESTS : 각 조합에 대해 실행할 테스트 수K : 검색 할 가장 가까운 이웃 수 기부금을 환영합니다! 풀 요청을 제출하십시오.
이 프로젝트는 오픈 소스이며 MIT 라이센스에 따라 사용할 수 있습니다.
아래는 KNN 검색 결과를 보여주는 차트입니다.
자세한 결과가 포함 된 CSV 파일은 여기에서 확인할 수 있습니다.


