knn search algorithm comparison
1.0.0
El algoritmo de vecinos K-Nears (K-NN), introducido en 1951, se ha utilizado ampliamente para tareas de clasificación y regresión. El concepto central implica identificar las K más similares (vecinos) a un punto de consulta dado dentro de un conjunto de datos y usar estos vecinos para hacer predicciones o clasificaciones. En los últimos años, la importancia de las bases de datos vectoriales e índices de vectores ha crecido, particularmente para la recuperación de la información para admitir modelos de idiomas grandes (LLM) en el procesamiento de conjuntos de datos extensos de texto y otros datos. Un ejemplo destacado de esta aplicación es la generación de recuperación de la generación (RAG).
Este proyecto compara el rendimiento de diferentes algoritmos de búsqueda de K-NN en varios tamaños de datos y dimensiones. Los algoritmos comparados son:
Kd-tree (árbol k-dimensional):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Puntos: A (1,3), B (3,1), C (4,3), D (3,3) Estructura del árbol: Raíz (x = 2) -> Izquierda (y = 2) -> Derecha (x = 3)
Árbol de pelota:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
El círculo exterior contiene todos los puntos, los círculos internos dividen subconjuntos.
KNN completo (fuerza bruta):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Calcule distancias: Qa = 1.41, QB = 1, Qc = 2.24, QD = 1.41 Resultado: los 2 vecinos más cercanos son B y A (o D)
HNSW (mundo pequeño jerárquico navegable):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
La búsqueda comienza en un punto aleatorio en la capa superior y desciende, explorando a los vecinos en cada nivel hasta llegar a la parte inferior.
La elección entre estos algoritmos depende del tamaño del conjunto de datos, la dimensionalidad, la precisión requerida y la velocidad de consulta. El árbol KD y el árbol de la pelota proporcionan resultados exactos y son eficientes para dimensiones bajas a moderadas. KNN completo es simple pero se vuelve lento para conjuntos de datos grandes. HNSW ofrece un buen equilibrio entre la velocidad y la precisión, especialmente para datos de alta dimensión o grandes conjuntos de datos.
Clon este repositorio:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Crear un entorno virtual (opcional pero recomendado):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Instale las dependencias requeridas:
pip install -r requirements.txt
Esto instalará todos los paquetes necesarios enumerados en el archivo requirements.txt .
Para ejecutar las pruebas de comparación con parámetros predeterminados:
python app.py
También puede personalizar los parámetros de prueba utilizando argumentos de línea de comandos:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Argumentos disponibles:
--vectors : lista de recuentos de vectores para probar (predeterminado: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : Lista de dimensiones para probar (predeterminada: 4 16 256 1024)--num-tests : número de pruebas para ejecutarse para cada combinación (predeterminada: 10)--k : número de vecinos más cercanos para buscar (predeterminado: 10)El script mostrará una barra de progreso durante la ejecución, dándole una estimación del tiempo restante.
El script se puede interrumpir en cualquier momento presionando Ctrl+c. Intentará salir con gracia, incluso durante las operaciones que requieren mucho tiempo como construir el índice HNSW.
El script mostrará progreso y resulta en la consola. Después de la finalización, verá:
Salida de ejemplo para una sola combinación:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
La tabla de resultados finales y el archivo CSV incluirán tiempos de compilación y tiempos de búsqueda para cada algoritmo, lo que permite una comparación integral del rendimiento en diferentes recuentos de vectores y dimensiones.
Puede modificar las siguientes variables en app.py para ajustar los parámetros de prueba:
NUM_VECTORS_LIST : lista de recuentos de vectores para probarNUM_DIMENSIONS_LIST : lista de dimensiones para probarNUM_TESTS : número de pruebas para ejecutarse para cada combinaciónK : Número de vecinos más cercanos para buscar ¡Las contribuciones son bienvenidas! No dude en enviar una solicitud de extracción.
Este proyecto es de código abierto y está disponible bajo la licencia MIT.
A continuación se muestra un gráfico que muestra los resultados de búsqueda de KNN:
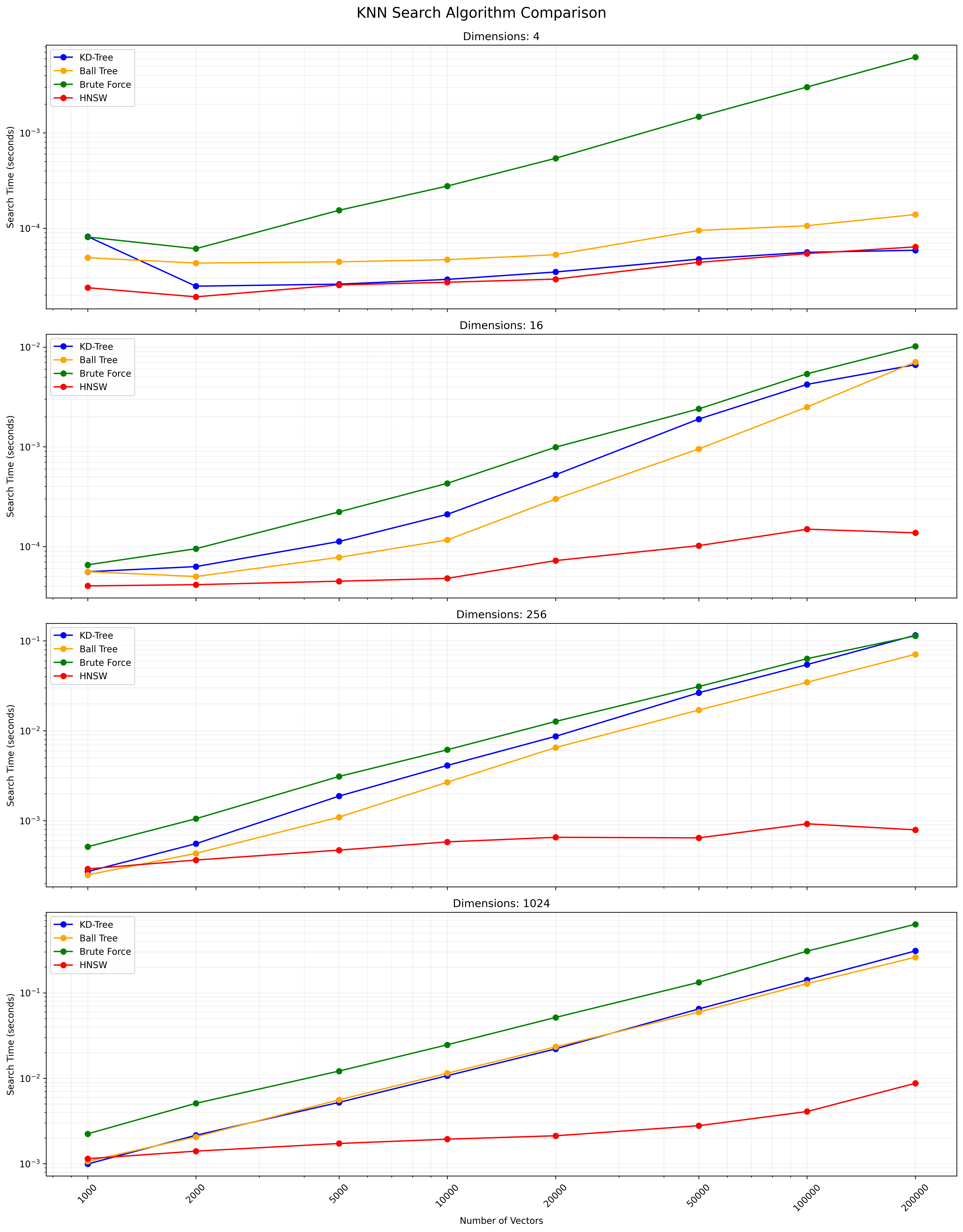
Un archivo CSV que contiene los resultados detallados está disponible aquí.


