knn search algorithm comparison
1.0.0
تم استخدام خوارزمية K-Nearest Neighbors (K-NN) ، التي تم تقديمها في عام 1951 ، على نطاق واسع في كل من مهام التصنيف والانحدار. يتضمن المفهوم الأساسي تحديد الحالات الأكثر مماثلة (الجيران) إلى نقطة استعلام معينة داخل مجموعة بيانات واستخدام هؤلاء الجيران لإجراء تنبؤات أو تصنيفات. في السنوات الأخيرة ، نمت أهمية قواعد بيانات المتجهات وفهارس المتجهات ، لا سيما لاسترجاع المعلومات لدعم نماذج اللغة الكبيرة (LLMs) في معالجة مجموعات بيانات واسعة من النصوص والبيانات الأخرى. مثال بارز على هذا التطبيق هو جيل Recoveral-Augmented (RAG).
يقارن هذا المشروع أداء خوارزميات البحث K-NN المختلفة عبر مختلف أحجام مجموعات البيانات والأبعاد. الخوارزميات المقارنة هي:
KD Tree (شجرة الأبعاد k):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
النقاط: A (1،3) ، B (3،1) ، C (4،3) ، D (3،3) هيكل الشجرة: الجذر (x = 2) -> اليسار (y = 2) -> اليمين (x = 3)
شجرة الكرة:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
تحتوي الدائرة الخارجية على جميع النقاط ، والدوائر الداخلية تقسيم مجموعات فرعية.
KNN الكامل (القوة الغاشمة):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
حساب المسافات: QA = 1.41 ، QB = 1 ، QC = 2.24 ، QD = 1.41 النتيجة: أقرب جيران 2 و A (أو D)
HNSW (عالم صغير قابل للملاحة):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
يبدأ البحث عند نقطة عشوائية في الطبقة العليا وينحدر ، واستكشاف الجيران في كل مستوى حتى الوصول إلى القاع.
يعتمد الاختيار بين هذه الخوارزميات على حجم مجموعة البيانات ، والأبعاد ، والدقة المطلوبة ، وسرعة الاستعلام. توفر شجرة KD وشجرة الكرة نتائج دقيقة وفعالة للأبعاد المنخفضة إلى المعتدلة. KNN الكامل بسيط ولكنه يصبح بطيئًا لمجموعات البيانات الكبيرة. يوفر HNSW توازنًا جيدًا بين السرعة والدقة ، خاصة بالنسبة للبيانات ذات الأبعاد العالية أو مجموعات البيانات الكبيرة.
استنساخ هذا المستودع:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
إنشاء بيئة افتراضية (اختياري ولكن موصى بها):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
تثبيت التبعيات المطلوبة:
pip install -r requirements.txt
سيؤدي ذلك إلى تثبيت جميع الحزم الضرورية المدرجة في ملف requirements.txt txt ، بما في ذلك Numpy و Scipy و Scikit-Learn و Hnswlib و Tabulate و TQDM.
لتشغيل اختبارات المقارنة مع المعلمات الافتراضية:
python app.py
يمكنك أيضًا تخصيص معلمات الاختبار باستخدام وسيطات سطر الأوامر:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
الحجج المتاحة:
--vectors : قائمة التهم المتجهات للاختبار (الافتراضي: 1000 ، 2000 ، 5000 ، 10000 ، 20000 ، 50000 ، 100000 ، 200000)--dimensions : قائمة الأبعاد للاختبار (الافتراضي: 4 16 256 1024)--num-tests : عدد الاختبارات التي سيتم تشغيلها لكل مجموعة (افتراضي: 10)--k : عدد من أقرب الجيران للبحث عن (الافتراضي: 10)سيعرض البرنامج النصي شريط تقدم أثناء التنفيذ ، مما يمنحك تقديرًا للوقت المتبقي.
يمكن مقاطعة البرنامج النصي في أي وقت عن طريق الضغط على Ctrl+C. ستحاول الخروج بأمان ، حتى أثناء عمليات تستغرق وقتًا طويلاً مثل بناء مؤشر HNSW.
سيعرض البرنامج النصي تقدمًا ويؤدي إلى وحدة التحكم. بعد الانتهاء ، سترى:
مثال على الإخراج لمجموعة واحدة:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
سيتضمن جدول النتائج النهائي وملف CSV كل من أوقات البناء وأوقات البحث لكل خوارزمية ، مما يسمح بمقارنة شاملة للأداء عبر تعداد مختلف المتجهات والأبعاد.
يمكنك تعديل المتغيرات التالية في app.py لضبط معلمات الاختبار:
NUM_VECTORS_LIST : قائمة تعداد المتجهات للاختبارNUM_DIMENSIONS_LIST : قائمة الأبعاد للاختبارNUM_TESTS : عدد الاختبارات المراد تشغيلها لكل مجموعةK : عدد من أقرب الجيران للبحث عن المساهمات مرحب بها! لا تتردد في تقديم طلب سحب.
هذا المشروع مفتوح المصدر ومتوفر بموجب ترخيص معهد ماساتشوستس للتكنولوجيا.
فيما يلي مخطط يوضح نتائج بحث KNN:
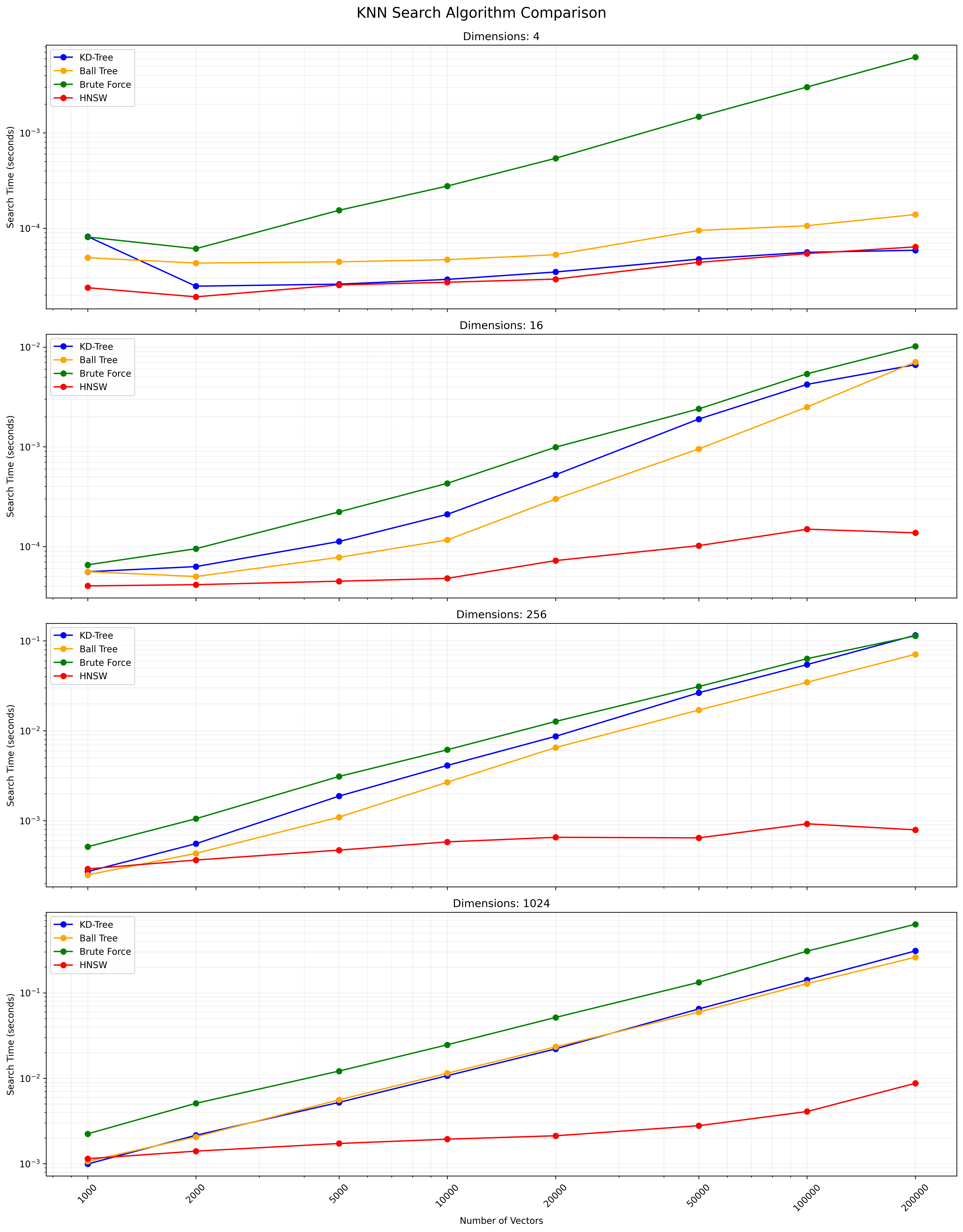
يتوفر ملف CSV الذي يحتوي على النتائج التفصيلية هنا.


