knn search algorithm comparison
1.0.0
O algoritmo de vizinhos mais antigos (K-NN), introduzido em 1951, tem sido amplamente utilizado para tarefas de classificação e regressão. O conceito principal envolve a identificação dos K instâncias mais semelhantes (vizinhos) a um determinado ponto de consulta dentro de um conjunto de dados e usando esses vizinhos para fazer previsões ou classificações. Nos últimos anos, a importância dos bancos de dados de vetores e índices vetoriais cresceu, principalmente para a recuperação de informações para apoiar grandes modelos de idiomas (LLMS) no processamento de conjuntos de dados extensos de texto e outros dados. Um exemplo proeminente deste aplicativo é a geração de recuperação de recuperação (RAG).
Este projeto compara o desempenho de diferentes algoritmos de pesquisa K-NN em vários tamanhos e dimensões do conjunto de dados. Os algoritmos comparados são:
KD-Tree (árvore K-dimensional):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Pontos: A (1,3), B (3,1), C (4,3), D (3,3) Estrutura da árvore: raiz (x = 2) -> esquerda (y = 2) -> direita (x = 3)
Árvore de bola:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
O círculo externo contém todos os pontos, círculos internos dividem subconjuntos.
KNN completo (força bruta):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Calcule distâncias: QA = 1,41, QB = 1, QC = 2,24, QD = 1,41 Resultado: Os 2 vizinhos mais próximos são B e A (ou D)
HNSW (mundo pequeno hierárquico navegável):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
A pesquisa começa em um ponto aleatório na camada superior e desce, explorando os vizinhos em cada nível até chegar ao fundo.
A escolha entre esses algoritmos depende do tamanho do conjunto de dados, dimensionalidade, precisão necessária e velocidade de consulta. A árvore de KD e a árvore da bola fornece resultados exatos e são eficientes para dimensões baixas a moderadas. O KNN completo é simples, mas fica lento para conjuntos de dados grandes. A HNSW oferece um bom equilíbrio entre velocidade e precisão, especialmente para dados de alta dimensão ou grandes conjuntos de dados.
Clone este repositório:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Crie um ambiente virtual (opcional, mas recomendado):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Instale as dependências necessárias:
pip install -r requirements.txt
Isso instalará todos os pacotes necessários listados no arquivo requirements.txt .
Para executar os testes de comparação com os parâmetros padrão:
python app.py
Você também pode personalizar os parâmetros de teste usando argumentos da linha de comando:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Argumentos disponíveis:
--vectors : Lista de contagens de vetores para testar (padrão: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : Lista de dimensões a serem testadas (Padrão: 4 16 256 1024)--num-tests : Número de testes a serem executados para cada combinação (Padrão: 10)--k : número de vizinhos mais próximos a procurar (padrão: 10)O script exibirá uma barra de progresso durante a execução, fornecendo uma estimativa do tempo restante.
O script pode ser interrompido a qualquer momento, pressionando Ctrl+c. Ele tentará sair graciosamente, mesmo durante operações que consomem tempo, como a construção do índice HNSW.
O script exibirá progresso e resultará no console. Após a conclusão, você verá:
Exemplo de saída para uma única combinação:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
A tabela de resultados finais e o arquivo CSV incluirão os tempos de construção e os tempos de pesquisa para cada algoritmo, permitindo uma comparação abrangente do desempenho em diferentes contagens e dimensões de vetores.
Você pode modificar as seguintes variáveis em app.py para ajustar os parâmetros de teste:
NUM_VECTORS_LIST : Lista de contagens de vetores para testarNUM_DIMENSIONS_LIST : Lista de dimensões para testarNUM_TESTS : Número de testes para executar para cada combinaçãoK : Número de vizinhos mais próximos para procurar As contribuições são bem -vindas! Sinta -se à vontade para enviar uma solicitação de tração.
Este projeto é de código aberto e está disponível sob a licença do MIT.
Abaixo está um gráfico mostrando os resultados de pesquisa do KNN:
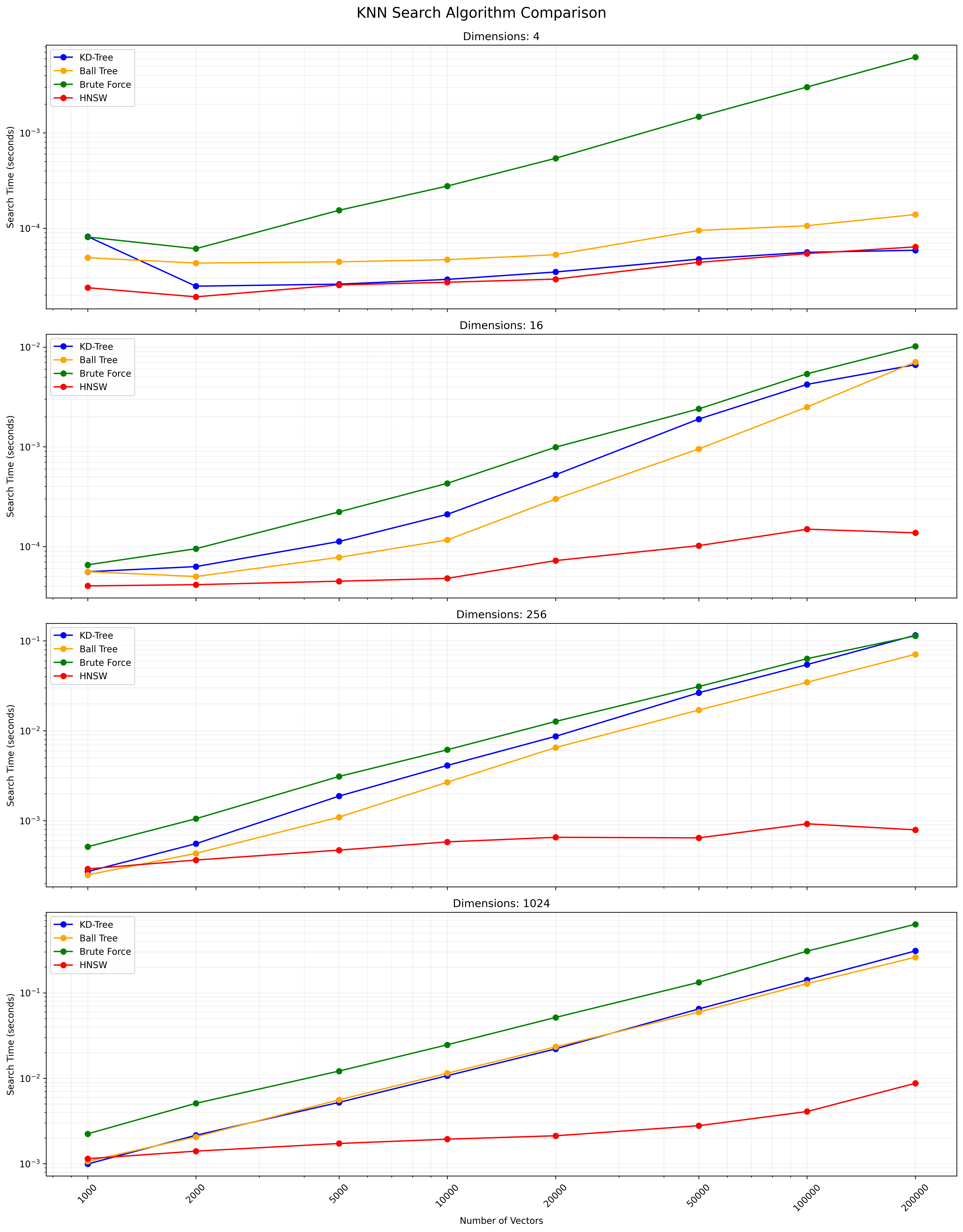
Um arquivo CSV que contém os resultados detalhados está disponível aqui.


