Chinese ELECTRA
1.0.0
คำอธิบายภาษาจีน ภาษาอังกฤษ

โครงการนี้มีพื้นฐานมาจาก Electra อย่างเป็นทางการของ Google & Stanford University: https://github.com/google-research/electra
Lert จีน ภาษาอังกฤษภาษาอังกฤษ Pert | Macbert จีน Electra จีน XLNET จีน | เบิร์ตจีน เครื่องมือกลั่นความรู้ TextBrewer | เครื่องมือตัดแบบจำลอง TextPruner
ดูแหล่งข้อมูลเพิ่มเติมที่เผยแพร่โดย IFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 โอเพ่นซอร์ส Llama & Alpaca Big Model ซึ่งสามารถนำไปใช้อย่างรวดเร็วและมีประสบการณ์บนพีซีดู: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 เราเสนอรูปแบบที่ได้รับการฝึกอบรมล่วงหน้าซึ่งรวมข้อมูลภาษาศาสตร์ ดู: https://github.com/ymcui/lert
2022/3/30 เราเปิดแหล่งข้อมูลรุ่นใหม่ที่ผ่านการฝึกอบรมมาก่อน ดู: https://github.com/ymcui/pert
2021/12/17 ห้องปฏิบัติการร่วม IFLYTEK เปิดตัว TextPruner TextPruner แบบจำลอง ดู: https://github.com/airaria/textpruner
2021/10/24 ห้องปฏิบัติการร่วม IFLYTEK เปิดตัว CINO แบบจำลองที่ผ่านการฝึกอบรมมาก่อนสำหรับภาษาชนกลุ่มน้อย ดู: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "การประมวลผลภาษาธรรมชาติ: วิธีการตามรูปแบบการฝึกอบรมก่อนการฝึกอบรม" ที่เขียนโดยนักวิชาการหลายคนจาก Harbin Institute of Technology Scir ได้รับการเผยแพร่และทุกคนยินดีที่จะซื้อ
2020/12/13 จากข้อมูลเอกสารทางกฎหมายขนาดใหญ่เราได้รับการฝึกอบรมแบบจำลอง Electra Series จีนสำหรับหน่วยตุลาการเพื่อดูการดาวน์โหลดแบบจำลองและผลงานของศาล
2020/9/15 บทความของเรา "ทบทวนแบบจำลองที่ผ่านการฝึกอบรมมาก่อนสำหรับการประมวลผลภาษาธรรมชาติจีน" ได้รับการว่าจ้างเป็นบทความยาวโดยการค้นพบของ EMNLP
2020/8/27 ห้องปฏิบัติการร่วม IFL ติดอันดับในการประเมินความเข้าใจภาษาธรรมชาติทั่วไปของกาวทั่วไปตรวจสอบรายการกาวข่าว
2020/5/29 Electra-Large/Small-EX ของจีนได้รับการปล่อยตัวแล้ว โปรดตรวจสอบการดาวน์โหลดรุ่น ปัจจุบันมีที่อยู่ดาวน์โหลด Google ไดรฟ์เท่านั้นดังนั้นโปรดเข้าใจ
2020/4/7 ผู้ใช้ Pytorch สามารถโหลดโมเดลผ่านหม้อแปลงเพื่อดูการโหลดที่รวดเร็ว
2020/3/31 โมเดลที่เผยแพร่ในไดเรกทอรีนี้ได้เชื่อมต่อกับ PaddlePaddleHub สำหรับการดูและการโหลดอย่างรวดเร็ว
2020/3/25 Electra-Small/Base จีนได้รับการปล่อยตัวโปรดตรวจสอบการดาวน์โหลดรุ่น
| บท | อธิบาย |
|---|---|
| การแนะนำ | รู้เบื้องต้นเกี่ยวกับหลักการพื้นฐานของ Electra |
| ดาวน์โหลดรุ่น | ดาวน์โหลดรุ่น Electra Electra ที่ผ่านการฝึกอบรมล่วงหน้า |
| การโหลดอย่างรวดเร็ว | วิธีใช้หม้อแปลงและ PaddleHub โหลดรุ่นอย่างรวดเร็ว |
| เอฟเฟกต์ระบบพื้นฐาน | ผลกระทบของระบบพื้นฐานของจีน: การอ่านความเข้าใจการจำแนกประเภทข้อความ ฯลฯ |
| วิธีใช้ | การใช้แบบจำลองโดยละเอียด |
| คำถามที่พบบ่อย | คำถามที่พบบ่อยและคำตอบ |
| อ้าง | รายงานทางเทคนิคในไดเรกทอรีนี้ |
Electra เสนอกรอบการฝึกอบรมล่วงหน้าใหม่ซึ่งมีสองส่วน: เครื่องกำเนิดไฟฟ้า และ discriminator
หลังจากขั้นตอนการฝึกอบรมก่อนสิ้นสุดลงเราจะใช้ discriminator เป็นแบบจำลองพื้นฐานสำหรับงานดาวน์สตรีมที่ปรับแต่งอย่างละเอียด
สำหรับเนื้อหาที่มีรายละเอียดเพิ่มเติมโปรดดูที่กระดาษ Electra: Electra: การเข้ารหัสข้อความก่อนการฝึกอบรมเป็นตัวเลือกจำเพาะมากกว่าเครื่องกำเนิดไฟฟ้า
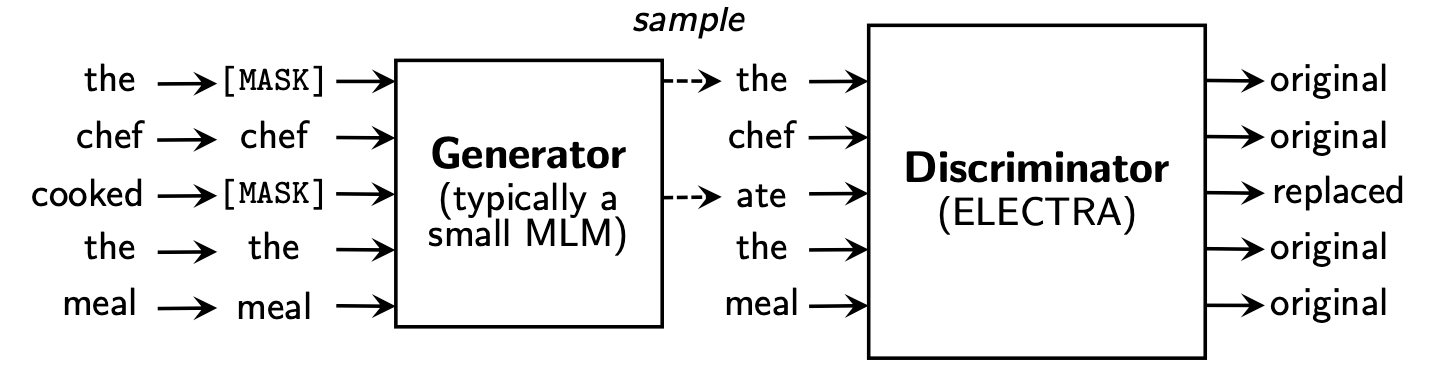
ไดเรกทอรีนี้มีรุ่นต่อไปนี้และปัจจุบันให้น้ำหนักรุ่น Tensorflow เท่านั้น
ELECTRA-large, Chinese : 24 ชั้น, 1024 ซ่อน, 16 หัว, พารามิเตอร์ 324mELECTRA-base, Chinese : 12-layer, 768 ซ่อน, 12 หัว, พารามิเตอร์ 102mELECTRA-small-ex, Chinese : 24 ชั้น, 256 ซ่อน, 4 หัว, พารามิเตอร์ 25mELECTRA-small, Chinese : 12 ชั้น, 256 ซ่อน, 4 หัว, พารามิเตอร์ 12m | ตัวย่อแบบจำลอง | ดาวน์โหลด Google | Baidu Netdisk ดาวน์โหลด | ขนาดแพ็คเกจบีบอัด |
|---|---|---|---|
ELECTRA-180g-large, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน 2v5r) | 1G |
ELECTRA-180g-base, Chinese | เทนเซอร์โฟลว์ | TensorFlow (รหัสผ่าน 3VG1) | 383m |
ELECTRA-180g-small-ex, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน 93n8) | 92m |
ELECTRA-180g-small, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน k9iu) | 46m |
| ตัวย่อแบบจำลอง | ดาวน์โหลด Google | Baidu Netdisk ดาวน์โหลด | ขนาดแพ็คเกจบีบอัด |
|---|---|---|---|
ELECTRA-large, Chinese | เทนเซอร์โฟลว์ | TensorFlow (รหัสผ่าน 1E14) | 1G |
ELECTRA-base, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน F32J) | 383m |
ELECTRA-small-ex, Chinese | เทนเซอร์โฟลว์ | TensorFlow (รหัสผ่าน GFB1) | 92m |
ELECTRA-small, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน 1R4R) | 46m |
| ตัวย่อแบบจำลอง | ดาวน์โหลด Google | Baidu Netdisk ดาวน์โหลด | ขนาดแพ็คเกจบีบอัด |
|---|---|---|---|
legal-ELECTRA-large, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน Q4GV) | 1G |
legal-ELECTRA-base, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน 8GCV) | 383m |
legal-ELECTRA-small, Chinese | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน kmrj) | 46m |
หากคุณต้องการเวอร์ชัน pytorch โปรดแปลงด้วยตัวคุณเองผ่านสคริปต์แปลง Converted_electra_original_tf_checkpoint_to_pytorch.py จัดหาโดยหม้อแปลง หากคุณต้องการไฟล์การกำหนดค่าคุณสามารถป้อนโฟลเดอร์ config ในไดเรกทอรีนี้เพื่อค้นหา
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorหรือดาวน์โหลด pytorch โดยตรงผ่านเว็บไซต์ทางการของ HuggingFace: https://huggingface.co/hfl
วิธี: คลิกรุ่นใด ๆ ที่คุณต้องการดาวน์โหลด→ดึงไปที่ด้านล่างและคลิก "แสดงรายการไฟล์ทั้งหมดในรุ่น" →ดาวน์โหลดไฟล์ bin และ json ในกล่องป๊อปอัพ
ขอแนะนำให้ใช้คะแนนดาวน์โหลด Baidu Netdisk ในจีนแผ่นดินใหญ่ในขณะที่ขอแนะนำให้ใช้จุดดาวน์โหลด Google ในผู้ใช้ในต่างประเทศ การใช้ ELECTRA-small, Chinese เป็นตัวอย่างหลังจากดาวน์โหลดแล้วการบีบอัดไฟล์ ZIP เพื่อรับไฟล์ต่อไปนี้
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
เราใช้วิกิจีนขนาดใหญ่และข้อความทั่วไปเพื่อฝึกอบรมรุ่น Electra โดยมีจำนวนโทเค็นรวมถึง 5.4B ซึ่งสอดคล้องกับรุ่น Roberta-WWM-Ext ในแง่ของรายการคำศัพท์จะใช้รายการคำศัพท์ Bert Wordpiece ดั้งเดิมของ Google รวมถึงโทเค็น 21,128 รายละเอียดอื่น ๆ และไฮเปอร์พารามิเตอร์มีดังนี้ (พารามิเตอร์ที่ไม่ได้กล่าวถึงยังคงเป็นค่าเริ่มต้น):
ELECTRA-large : 24 ชั้น, ชั้นที่ซ่อน 1024, 16 หัวความสนใจ, อัตราการเรียนรู้ 1E-4, Batch96, ความยาวสูงสุด 512, การฝึกอบรม 2m ขั้นตอนELECTRA-base : 12 ชั้น, ชั้นที่ซ่อน 768, 12 หัวความสนใจ, อัตราการเรียนรู้ 2E-4, batch256, ความยาวสูงสุด 512, การฝึกอบรม 1m ขั้นตอนELECTRA-small-ex : 24 เลเยอร์, เลเยอร์ที่ซ่อนอยู่ 256, 4 หัวความสนใจ, อัตราการเรียนรู้ 5E-4, Batch384, ความยาวสูงสุด 512, ขั้นตอนการฝึกอบรม 2m 2mELECTRA-small : 12 ชั้น, เลเยอร์ที่ซ่อน 256, 4 หัวความสนใจ, อัตราการเรียนรู้ 5E-4, Batch1024, ความยาวสูงสุด 512, การฝึกอบรม 1m ขั้นตอน HuggingFace-Transformers เวอร์ชัน 2.8.0 ได้สนับสนุนรุ่น Electra อย่างเป็นทางการและสามารถเรียกผ่านคำสั่งต่อไปนี้
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) รายการที่สอดคล้องกันของ MODEL_NAME มีดังนี้:
| ชื่อนางแบบ | ส่วนประกอบ | model_name |
|---|---|---|
| Electra-180g- ใหญ่จีน | การเลือกปฏิบัติ | HFL/ภาษาจีน-อิเล็กทรอนิกส์ -180G- ใหญ่ |
| Electra-180g- ใหญ่จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-180G-Large-Generator |
| Electra-180g-base, จีน | การเลือกปฏิบัติ | HFL/Chinese-Electra-180g-base-discriminator |
| Electra-180g-base, จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-180g-base-generator |
| Electra-180g-small-ex, จีน | การเลือกปฏิบัติ | HFL/Chinese-Electra-180G-Small-Ex-Discriminator |
| Electra-180g-small-ex, จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-180G-Small-Ex-Generator |
| Electra-180g-small, จีน | การเลือกปฏิบัติ | HFL/Chinese-Electra-180G-Small-Discriminator |
| Electra-180g-small, จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-180G-Small-Generator |
| Electra-large, จีน | การเลือกปฏิบัติ | HFL/ภาษาจีน-อิเล็กตรอนขนาดใหญ่ |
| Electra-large, จีน | เครื่องกำเนิดไฟฟ้า | HFL/จีน-อิเล็กตรอนขนาดใหญ่ |
| Electra-base, จีน | การเลือกปฏิบัติ | HFL/จีน-อิเล็กตร้าเบส |
| Electra-base, จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-base-base-base-base-base-base-base-base-base |
| Electra-small-ex, จีน | การเลือกปฏิบัติ | HFL/ภาษาจีน-อิเล็กตรอน-small-ex-discriminator |
| Electra-small-ex, จีน | เครื่องกำเนิดไฟฟ้า | HFL/ภาษาจีน-อิเล็กตรอน-small-ex-generator |
| Electra-small, จีน | การเลือกปฏิบัติ | HFL/ภาษาจีน-อิเล็กตรอน-ขนาดเล็ก |
| Electra-small, จีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Electra-Small-Generator |
เวอร์ชันโดเมนตุลาการ:
| ชื่อนางแบบ | ส่วนประกอบ | model_name |
|---|---|---|
| ภาษาจีน | การเลือกปฏิบัติ | HFL/จีน-กฎหมาย-อิเล็กตร้าขนาดใหญ่ |
| ภาษาจีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Legal-Electra-Large-Generator |
| ตามกฎหมาย-อิเล็กตร้าเบสจีน | การเลือกปฏิบัติ | HFL/Chinese-Legal-electra-base-discriminator |
| ตามกฎหมาย-อิเล็กตร้าเบสจีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Legal-Electra-Base-Generator |
| กฎหมาย-อิเล็กตร้าขนาดเล็กจีน | การเลือกปฏิบัติ | HFL/Chinese-Legal-Electra-Small-Discriminator |
| กฎหมาย-อิเล็กตร้าขนาดเล็กจีน | เครื่องกำเนิดไฟฟ้า | HFL/Chinese-Legal-Electra-Small-Generator |
พึ่งพา PaddleHub เราต้องใช้รหัสเดียวเพียงบรรทัดเดียวเพื่อให้การดาวน์โหลดและติดตั้งโมเดลเสร็จสมบูรณ์และรหัสมากกว่าสิบบรรทัดสามารถทำให้งานของการจำแนกประเภทข้อความเสร็จสิ้นคำอธิบายประกอบลำดับการอ่านความเข้าใจและงานอื่น ๆ
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
รายการที่สอดคล้องกันของ MODULE_NAME มีดังนี้:
| ชื่อนางแบบ | module_name |
|---|---|
| Electra-base, จีน | เบสจีน |
| Electra-small, จีน | ลวก ๆ |
เราเปรียบเทียบผลกระทบของ ELECTRA-small/base กับ BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext และ RBT3 รวมถึงงานหกงานต่อไปนี้:
สำหรับรุ่น Electra-Small/Base เราใช้อัตราการเรียนรู้เริ่มต้นของ 3e-4 และ 1e-4 ในกระดาษต้นฉบับ ควรสังเกตว่าเรายังไม่ได้ทำการปรับพารามิเตอร์สำหรับงานใด ๆ ดังนั้นการปรับปรุงประสิทธิภาพเพิ่มเติมอาจทำได้โดยการปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์เช่นอัตราการเรียนรู้ เพื่อให้แน่ใจว่าความน่าเชื่อถือของผลลัพธ์สำหรับโมเดลเดียวกันเราได้ฝึกอบรม 10 ครั้งโดยใช้เมล็ดสุ่มที่แตกต่างกันเพื่อรายงานค่าสูงสุดและค่าเฉลี่ยของประสิทธิภาพของโมเดล (ค่าเฉลี่ยในวงเล็บ)
ชุดข้อมูล CMRC 2018 เป็นข้อมูลความเข้าใจในการอ่านของเครื่องจีนที่เผยแพร่โดยห้องปฏิบัติการร่วมของสถาบันเทคโนโลยีฮาร์บิน ตามคำถามที่กำหนดระบบจะต้องแยกชิ้นส่วนออกจากบทเป็นคำตอบในรูปแบบเดียวกับทีม ตัวชี้วัดการประเมินคือ: EM / F1
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ชุดท้าทาย | ปริมาณพารามิเตอร์ |
|---|---|---|---|---|
| เบิร์ตเบส | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| bert-wwm | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| bert-wwm-ext | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| Roberta-wwm-ext | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| ควันเล็ก ๆ | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12m |
| Electra-180g-small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-small-ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180g-small-ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| เบสอิเลคตร้า | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102m |
| Electra-180g-base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| ขนาดใหญ่ | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180g มีขนาดใหญ่ | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
ชุดข้อมูล DRCD ได้รับการเผยแพร่โดย Delta Research Institute, ไต้หวัน, จีน รูปแบบของมันเหมือนกับทีมและเป็นชุดข้อมูลความเข้าใจในการอ่านที่แยกออกมาจากภาษาจีนดั้งเดิม ตัวชี้วัดการประเมินคือ: EM / F1
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| เบิร์ตเบส | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102m |
| bert-wwm | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| bert-wwm-ext | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102m |
| Roberta-wwm-ext | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| ควันเล็ก ๆ | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12m |
| Electra-180g-small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-small-ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180g-small-ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| เบสอิเลคตร้า | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102m |
| Electra-180g-base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| ขนาดใหญ่ | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180g มีขนาดใหญ่ | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
ในงานการอนุมานภาษาธรรมชาติเราใช้ข้อมูล XNLI ซึ่งต้องการข้อความที่จะแบ่งออกเป็นสามประเภท: entailment , neutral และ contradictory ตัวบ่งชี้การประเมินคือ: ความแม่นยำ
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| เบิร์ตเบส | 77.8 (77.4) | 77.8 (77.5) | 102m |
| bert-wwm | 79.0 (78.4) | 78.2 (78.0) | 102m |
| bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) | 102m |
| Roberta-wwm-ext | 80.0 (79.2) | 78.8 (78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| ควันเล็ก ๆ | 73.3 (72.5) | 73.1 (72.6) | 12m |
| Electra-180g-small | 74.6 | 74.6 | 12m |
| Electra-small-ex | 75.4 | 75.8 | 25m |
| Electra-180g-small-ex | 76.5 | 76.6 | 25m |
| เบสอิเลคตร้า | 77.9 (77.0) | 78.4 (77.8) | 102m |
| Electra-180g-base | 79.6 | 79.5 | 102m |
| ขนาดใหญ่ | 81.5 | 81.0 | 324m |
| Electra-180g มีขนาดใหญ่ | 81.2 | 80.4 | 324m |
ในงานการวิเคราะห์ความเชื่อมั่นชุดข้อมูลการจำแนกอารมณ์ไบนารี Chnsenticorp ตัวบ่งชี้การประเมินคือ: ความแม่นยำ
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| เบิร์ตเบส | 94.7 (94.3) | 95.0 (94.7) | 102m |
| bert-wwm | 95.1 (94.5) | 95.4 (95.0) | 102m |
| bert-wwm-ext | 95.4 (94.6) | 95.3 (94.7) | 102m |
| Roberta-wwm-ext | 95.0 (94.6) | 95.6 (94.8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| ควันเล็ก ๆ | 92.8 (92.5) | 94.3 (93.5) | 12m |
| Electra-180g-small | 94.1 | 93.6 | 12m |
| Electra-small-ex | 92.6 | 93.6 | 25m |
| Electra-180g-small-ex | 92.8 | 93.4 | 25m |
| เบสอิเลคตร้า | 93.8 (93.0) | 94.5 (93.5) | 102m |
| Electra-180g-base | 94.3 | 94.8 | 102m |
| ขนาดใหญ่ | 95.2 | 95.3 | 324m |
| Electra-180g มีขนาดใหญ่ | 94.8 | 95.2 | 324m |
ชุดข้อมูลสองชุดต่อไปนี้จำเป็นต้องจำแนกคู่ประโยคเพื่อพิจารณาว่าความหมายของประโยคทั้งสองนั้นเหมือนกัน (งานการจำแนกประเภทไบนารี) หรือไม่
LCQMC ได้รับการปล่อยตัวโดยศูนย์วิจัยคอมพิวเตอร์อัจฉริยะของสถาบันเทคโนโลยีฮาร์บินเซินเจิ้นบัณฑิตวิทยาลัย ตัวบ่งชี้การประเมินคือ: ความแม่นยำ
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| เบิร์ต | 89.4 (88.4) | 86.9 (86.4) | 102m |
| bert-wwm | 89.4 (89.2) | 87.0 (86.8) | 102m |
| bert-wwm-ext | 89.6 (89.2) | 87.1 (86.6) | 102m |
| Roberta-wwm-ext | 89.0 (88.7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| ควันเล็ก ๆ | 86.7 (86.3) | 85.9 (85.6) | 12m |
| Electra-180g-small | 86.6 | 85.8 | 12m |
| Electra-small-ex | 87.5 | 86.0 | 25m |
| Electra-180g-small-ex | 87.6 | 86.3 | 25m |
| เบสอิเลคตร้า | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180g-base | 90.2 | 87.1 | 102m |
| ขนาดใหญ่ | 90.7 | 87.3 | 324m |
| Electra-180g มีขนาดใหญ่ | 90.3 | 87.3 | 324m |
BQ Corpus ได้รับการปล่อยตัวโดยศูนย์วิจัยคอมพิวเตอร์อัจฉริยะของสถาบันเทคโนโลยีฮาร์บินเซินเจิ้นบัณฑิตวิทยาลัยและเป็นข้อมูลที่ตั้งไว้สำหรับสาขาธนาคาร ตัวบ่งชี้การประเมินคือ: ความแม่นยำ
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| เบิร์ต | 86.0 (85.5) | 84.8 (84.6) | 102m |
| bert-wwm | 86.1 (85.6) | 85.2 (84.9) | 102m |
| bert-wwm-ext | 86.4 (85.5) | 85.3 (84.8) | 102m |
| Roberta-wwm-ext | 86.0 (85.4) | 85.0 (84.6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| ควันเล็ก ๆ | 83.5 (83.0) | 82.0 (81.7) | 12m |
| Electra-180g-small | 83.3 | 82.1 | 12m |
| Electra-small-ex | 84.0 | 82.6 | 25m |
| Electra-180g-small-ex | 84.6 | 83.4 | 25m |
| เบสอิเลคตร้า | 84.8 (84.7) | 84.5 (84.0) | 102m |
| Electra-180g-base | 85.8 | 84.5 | 102m |
| ขนาดใหญ่ | 86.7 | 85.1 | 324m |
| Electra-180g มีขนาดใหญ่ | 86.4 | 85.4 | 324m |
เราทดสอบ Electra ตุลาการโดยใช้ข้อมูลการทำนายอาชญากรรมของ Cail 2018 อัตราการเรียนรู้ของขนาดเล็ก/ฐาน/ใหญ่คือ: 5E-4/3E-4/1E-4 ตามลำดับ ตัวบ่งชี้การประเมินคือ: ความแม่นยำ
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ | ปริมาณพารามิเตอร์ |
|---|---|---|---|
| ควันเล็ก ๆ | 78.84 | 76.35 | 12m |
| ตามกฎหมาย | 79.60 | 77.03 | 12m |
| เบสอิเลคตร้า | 80.94 | 78.41 | 102m |
| เบสตามกฎหมาย | 81.71 | 79.17 | 102m |
| ขนาดใหญ่ | 81.53 | 78.97 | 324m |
| มีขนาดใหญ่ตามกฎหมาย | 82.60 | 79.89 | 324m |
ผู้ใช้สามารถดำเนินการปรับแต่งการปรับแต่งตามรุ่นที่ได้รับการฝึกฝนมาก่อนภาษาจีนที่ได้รับการฝึกฝนด้านบน ที่นี่เราจะแนะนำการใช้งานขั้นพื้นฐานที่สุดเท่านั้น สำหรับการใช้งานโดยละเอียดเพิ่มเติมโปรดดูการแนะนำอย่างเป็นทางการของ Electra
ในตัวอย่างนี้เราใช้แบบจำลอง ELECTRA-small เพื่อปรับแต่งงาน CMRC 2018 และขั้นตอนที่เกี่ยวข้องมีดังนี้ สมมติว่า
data-dir : ไดเรกทอรีรากที่ทำงานสามารถตั้งค่าตามสถานการณ์จริงmodel-name : ชื่อรุ่นในกรณีนี้ electra-smalltask-name : ชื่องานในกรณีนี้ cmrc2018 รหัสในไดเรกทอรีนี้ได้ปรับให้เข้ากับงานภาษาจีนหกฉบับข้างต้นและ task-name คือ cmrc2018 , drcd , xnli , chnsenticorp , lcqmc และ bqcorpus ในส่วนดาวน์โหลดรุ่นให้ดาวน์โหลดรุ่น Electra-Small และคลายการบีบอัดเป็น ${data-dir}/models/${model-name} ไดเรกทอรีนี้ควรมี electra_model.* , vocab.txt , checkpoint และทั้งหมด 5 ไฟล์
ดาวน์โหลดชุดฝึกอบรมและพัฒนา CMRC 2018 และเปลี่ยนชื่อเป็น train.json และ dev.json ใส่สองไฟล์ใน ${data-dir}/finetuning_data/${task-name}
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json ในหมู่พวกเขา data-dir และ model-name ได้รับการแนะนำข้างต้น hparams เป็นพจนานุกรม JSON ในตัวอย่างนี้ params_cmrc2018.json มี hyperparameters ที่เกี่ยวข้องกับการปรับแต่งอย่างละเอียดเช่น:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}ในไฟล์ JSON ด้านบนเราแสดงเฉพาะพารามิเตอร์ที่สำคัญที่สุดเท่านั้น สำหรับรายการพารามิเตอร์ที่สมบูรณ์โปรดดูที่ configure_finenetung.py
หลังจากการดำเนินการเสร็จสมบูรณ์
cmrc2018_dev_preds.json จะถูกบันทึกไว้ใน ${data-dir}/results/${task-name}_qa/ คุณสามารถโทรหาสคริปต์การประเมินผลภายนอกเพื่อรับผลการประเมินขั้นสุดท้ายตัวอย่างเช่น: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 ถาม: วิธีการตั้งค่าอัตราการเรียนรู้ของรุ่น Electra เมื่อปรับแต่งงานดาวน์สตรีมได้ดี?
ตอบ: เราขอแนะนำให้ใช้อัตราการเรียนรู้ที่ใช้โดยกระดาษต้นฉบับเป็นพื้นฐานเริ่มต้น (ขนาดเล็กคือ 3E-4, ฐานคือ 1E-4) จากนั้นทำการดีบักด้วยการเพิ่มและลดอัตราการเรียนรู้ที่เหมาะสม ควรสังเกตว่าเมื่อเทียบกับแบบจำลองเช่น Bert และ Roberta อัตราการเรียนรู้ของ Electra นั้นค่อนข้างใหญ่
ถาม: มีลิขสิทธิ์ Pytorch หรือไม่?
ตอบ: ใช่ดาวน์โหลดรุ่น
ถาม: ข้อมูลการฝึกอบรมล่วงหน้าสามารถแบ่งปันได้หรือไม่?
ตอบ: น่าเสียดายที่ไม่
ถาม: แผนการในอนาคต?
ตอบ: โปรดติดตามความคืบหน้า
หากเนื้อหาในไดเรกทอรีนี้เป็นประโยชน์กับงานวิจัยของคุณโปรดอย่าลังเลที่จะอ้างถึงกระดาษต่อไปนี้ในกระดาษ
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
ยินดีต้อนรับสู่การติดตามบัญชีอย่างเป็นทางการของ WeChat อย่างเป็นทางการ ของห้องปฏิบัติการร่วม IFLYTEK เพื่อเรียนรู้เกี่ยวกับแนวโน้มทางเทคนิคล่าสุด

ก่อนที่คุณจะส่งปัญหา:


