Chinese ELECTRA
1.0.0
Description chinoise | Anglais

Ce projet est basé sur l'Electra officiel de Google & Stanford University: https://github.com/google-research/electra
Lert chinois | Pert anglais chinois | Macbert chinois | Electra chinois | Xlnet chinois | Chinois Bert | Outil de distillation de connaissances TextBrewer | Modèle de coupe TextPruner
Voir plus de ressources publiées par l'IFL de Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model, qui peut être rapidement déployé et expérimenté sur PC, Voir: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Nous proposons un modèle Lert pré-formé qui intègre des informations linguistiques. Voir: https://github.com/ymcui/lert
2022/3/30 Nous avons open source un nouveau modèle pré-formé Pert. Voir: https://github.com/ymcui/pert
2021/12/17 Iflytek Joint Laboratory lance le modèle de TextPruner de la boîte à outils de coupe du modèle. Voir: https://github.com/airaria/textpruner
2021/10/24 IFLYTEK JOINT LABORATORY a publié un modèle de cino pré-entraîné pour les langues minoritaires ethniques. Voir: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "Traitement du langage naturel: des méthodes basées sur des modèles de pré-formation" écrites par de nombreux chercheurs du Harbin Institute of Technology SCIR ont été publiés, et tout le monde est invité à l'acheter.
2020/12/13 Sur la base des données de documents juridiques à grande échelle, nous avons formé des modèles chinois de la série Electra pour le champ judiciaire pour afficher les téléchargements du modèle et les effets des tâches judiciaires.
2020/9/15 Notre article "Revisiter les modèles pré-formés pour le traitement du langage naturel chinois" a été embauché comme un long article par les résultats de l'EMNLP.
2020/8/27 Laboratoire conjoint IFL en tête de liste dans l'évaluation générale de la compréhension du langage naturel général, vérifiez la liste des collectes, les nouvelles.
2020/5/29 Chinois Electra-Large / Small-EX a été libéré. Veuillez vérifier le téléchargement du modèle. Actuellement, seule l'adresse de téléchargement de Google Drive est disponible, alors veuillez comprendre.
2020/4/7 Les utilisateurs de Pytorch peuvent charger le modèle via les transformateurs pour afficher le chargement rapide.
2020/3/31 Les modèles publiés dans ce répertoire ont été connectés à PaddlePaddlehub pour la visualisation et le chargement rapidement.
2020/3/25 Electra-Small / base chinois a été publié, veuillez vérifier le téléchargement du modèle.
| chapitre | décrire |
|---|---|
| Introduction | Introduction aux principes de base de l'électra |
| Téléchargement du modèle | Télécharger le modèle chinois Electra pré-formé |
| Chargement rapide | Comment utiliser les transformateurs et Paddlehub à charger rapidement les modèles |
| Effets du système de base | Effets du système de base chinois: compréhension de la lecture, classification du texte, etc. |
| Comment utiliser | Utilisation détaillée du modèle |
| FAQ | FAQ et réponses |
| Citation | Rapports techniques dans ce répertoire |
Electra propose un nouveau cadre pré-formation qui comprend deux parties: générateur et discriminateur .
Une fois la phase de pré-formation terminée, nous n'utilisons que le discriminateur comme modèle de base pour les tâches en aval.
Pour un contenu plus détaillé, veuillez consulter le papier Electra: Electra: Encodeurs de texte pré-formation comme discriminateurs plutôt que générateurs
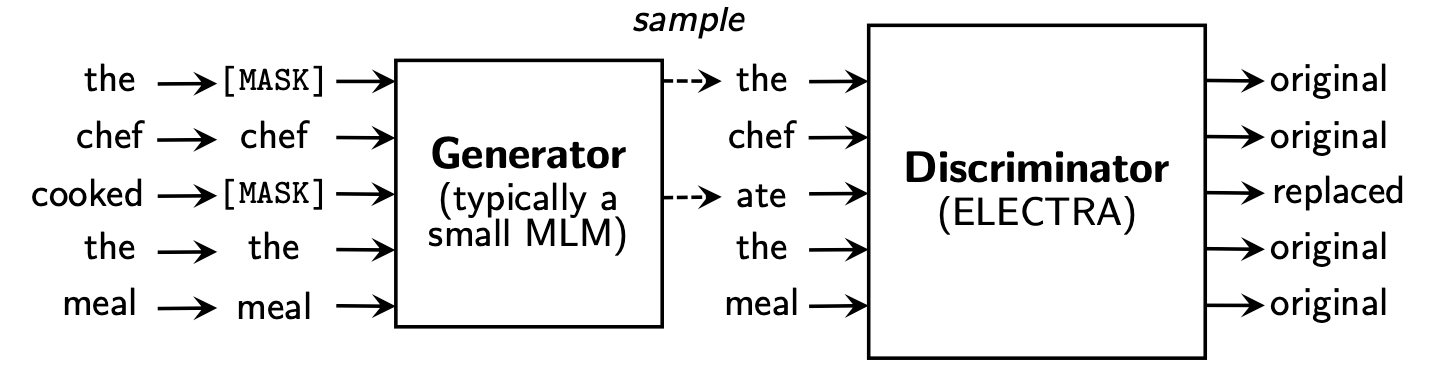
Ce répertoire contient les modèles suivants et ne fournit actuellement que des poids de version TensorFlow.
ELECTRA-large, Chinese : 24 couches, 1024, 16 têtes, 324 m de paramètresELECTRA-base, Chinese : 12 couches, 768, 12 têtes, 102 m de paramètresELECTRA-small-ex, Chinese : 24 couches, 256, 4 mètres, 25m paramètresELECTRA-small, Chinese : 12 couches, 256, 4 mètres, paramètres 12M | Abréviation du modèle | Google Download | Baidu Netdisk Download | Taille du package comprimé |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | TensorFlow (mot de passe 2v5r) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | TensorFlow (mot de passe 3vg1) | 383m |
ELECTRA-180g-small-ex, Chinese | Tensorflow | TensorFlow (mot de passe 93N8) | 92m |
ELECTRA-180g-small, Chinese | Tensorflow | TensorFlow (mot de passe k9iu) | 46m |
| Abréviation du modèle | Google Download | Baidu Netdisk Download | Taille du package comprimé |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | TensorFlow (mot de passe 1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | TensorFlow (mot de passe f32j) | 383m |
ELECTRA-small-ex, Chinese | Tensorflow | TensorFlow (mot de passe gfb1) | 92m |
ELECTRA-small, Chinese | Tensorflow | TensorFlow (mot de passe 1R4R) | 46m |
| Abréviation du modèle | Google Download | Baidu Netdisk Download | Taille du package comprimé |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | TensorFlow (mot de passe Q4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | TensorFlow (mot de passe 8GCV) | 383m |
legal-ELECTRA-small, Chinese | Tensorflow | TensorFlow (mot de passe KMRJ) | 46m |
Si vous avez besoin de la version Pytorch, veuillez la convertir vous-même via le script de conversion converti_electra_original_tf_checkpoint_to_pytorch.py fourni par les transformateurs. Si vous avez besoin de fichiers de configuration, vous pouvez saisir le dossier de configuration de ce répertoire pour rechercher.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorOu téléchargez directement Pytorch via le site officiel de HuggingFace: https://huggingface.co/hfl
Méthode: cliquez sur n'importe quel modèle que vous souhaitez télécharger → Pulpurez en bas et cliquez sur "Lister tous les fichiers dans le modèle" → Télécharger les fichiers bac et json dans la zone contextuelle.
Il est recommandé d'utiliser des points de téléchargement Baidu Netdisk en Chine continentale, alors qu'il est recommandé d'utiliser des points de téléchargement Google chez les utilisateurs étrangers. Prendre la version TensorFlow de ELECTRA-small, Chinese comme exemple, après téléchargement, décompressant le fichier zip pour obtenir le fichier suivant.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Nous avons utilisé des wikis chinois à grande échelle et du texte général pour former le modèle Electra, le nombre total de jetons atteignant 5,4b, ce qui est conforme au modèle de série Roberta-WWM-EXT. En termes de liste de vocabulaire, il utilise la liste de vocabulaire Bert Word-Piece originale de Google, y compris 21 128 jetons. Les autres détails et hyperparamètres sont les suivants (les paramètres non mentionnés restent par défaut):
ELECTRA-large : 24 couches, couche cachée 1024, 16 têtes d'attention, taux d'apprentissage 1E-4, Batch96, longueur maximale 512, formation 2M étapesELECTRA-base : 12 couches, couche cachée 768, 12 têtes d'attention, taux d'apprentissage 2E-4, Batch256, longueur maximale 512, format 1M de formationELECTRA-small-ex : 24 couches, couche cachée 256, 4 têtes d'attention, taux d'apprentissage 5E-4, Batch384, longueur maximale 512, 2m étapes de la formationELECTRA-small : 12 couches, couche cachée 256, 4 têtes d'attention, taux d'apprentissage 5E-4, Batch1024, longueur maximale 512, étape de formation 1M HuggingFace-Transformateurs La version 2.8.0 a officiellement pris en charge le modèle Electra et peut être appelé via les commandes suivantes.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) La liste correspondante de MODEL_NAME est la suivante:
| Nom du modèle | Composants | Model_name |
|---|---|---|
| Electra-180g-grand, chinois | discriminateur | HFL / Chinese-Electra-180g-Garn-Discriminateur |
| Electra-180g-grand, chinois | Générateur | HFL / chinois-électra-180G-Generator |
| Electra-180G-base, chinois | discriminateur | HFL / Chinese-Electra-180G-Base-Discriminateur |
| Electra-180G-base, chinois | Générateur | HFL / Chinese-Electra-180G-Base-Generator |
| Electra-180G-Small-Ex, chinois | discriminateur | HFL / Chinese-Electra-180G-Small-Excriminator |
| Electra-180G-Small-Ex, chinois | Générateur | HFL / Chinese-Electra-180G-Small-Ex-Generator |
| Electra-180G-Small, chinois | discriminateur | HFL / Chinese-Electra-180G-Small-Discriminateur |
| Electra-180G-Small, chinois | Générateur | HFL / Chinese-Electra-180G-Small-Generator |
| Électra-grand, chinois | discriminateur | HFL / Chine-Electra-Large-Discriminator |
| Électra-grand, chinois | Générateur | HFL / Générateur de chinois-électra |
| Electra-base, chinois | discriminateur | HFL / Chine-Electra-Base-Discriminator |
| Electra-base, chinois | Générateur | HFL / Générateur de base de la Chine-Electra |
| Electra-Small-Ex, chinois | discriminateur | HFL / Chine-Electra-Small-Excriminator |
| Electra-Small-Ex, chinois | Générateur | HFL / chinois-électra-small-ex-générateur |
| Electra-Small, chinois | discriminateur | HFL / Chine-Electra-Small-Discriminator |
| Electra-Small, chinois | Générateur | HFL / chinois-électra-générateur |
Version du domaine judiciaire:
| Nom du modèle | Composants | Model_name |
|---|---|---|
| Electra-Electra, chinois | discriminateur | HFL / chinois-legal-Electra-Large-Discriminateur |
| Electra-Electra, chinois | Générateur | HFL / Génératrice chinoise-legal-Electra-Large |
| base légale-électra, chinois | discriminateur | HFL / chinois-legal-Electra-Base-Discriminateur |
| base légale-électra, chinois | Générateur | HFL / chinois-légal-electra-base-générateur |
| Électra juridique, chinois | discriminateur | HFL / chinois-legal-Electra-Small-Discriminateur |
| Électra juridique, chinois | Générateur | HFL / chinois-legal-Electra-Small-Generator |
S'appuyant sur Paddlehub, nous n'avons besoin que d'une seule ligne de code pour terminer le téléchargement et l'installation du modèle, et plus de dix lignes de code peuvent effectuer les tâches de classification de texte, d'annotation de séquence, de compréhension en lecture et d'autres tâches.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
La liste correspondante de MODULE_NAME est la suivante:
| Nom du modèle | Module_name |
|---|---|
| Electra-base, chinois | chinois-électra-base |
| Electra-Small, chinois | chinois-électra-petit |
Nous avons comparé les effets de ELECTRA-small/base avec BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext et RBT3 , y compris les six tâches suivantes:
Pour le modèle Electra-Small / Base, nous utilisons les taux d'apprentissage par défaut de 3e-4 et 1e-4 dans le papier d'origine. Il convient de noter que nous n'avons pas effectué des ajustements de paramètres pour aucune tâche, de sorte que de nouvelles améliorations de performances peuvent être réalisées en ajustant les hyperparamètres tels que le taux d'apprentissage. Afin d'assurer la fiabilité des résultats, pour le même modèle, nous avons entraîné 10 fois en utilisant différentes graines aléatoires pour signaler les valeurs maximales et moyennes de performance du modèle (les valeurs moyennes entre parenthèses).
L'ensemble de données CMRC 2018 est les données chinoises de compréhension de la lecture des machines publiées par le Laboratoire conjoint de Harbin Institute of Technology. Selon une question donnée, le système doit extraire des fragments du chapitre comme réponse, sous la même forme que Squad. Les indicateurs d'évaluation sont: EM / F1
| Modèle | Ensemble de développement | Test de test | Défi | Quantité de paramètre |
|---|---|---|---|---|
| Bascule | 65,5 (64,4) / 84,5 (84,0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| Bert-wwm | 66.3 (65.0) / 85.6 (84,7) | 70,5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43,9) | 102m |
| Bert-wwm- | 67.1 (65.6) / 85.7 (85,0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44,6) | 102m |
| Roberta-wwm-ext | 67,4 (66,5) / 87,2 (86,5) | 72.6 (71.4) / 89.4 (88,8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Électra-petit | 63.4 (62.9) / 80.8 (80,2) | 67.8 (67.4) / 83.4 (83,0) | 16.3 (15.4) / 37.2 (35,8) | 12m |
| Electra-180G-Small | 63.8 / 82.7 | 68,5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180G-Small-Ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| Base électra | 68.4 (68.0) / 84.8 (84,6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21,7) / 45.0 (43,8) | 102m |
| Electra-180G-base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| Électra-grand | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180g-Garm | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
L'ensemble de données DRCD a été publié par le Delta Research Institute, Taiwan, Chine. Sa forme est la même que l'escouade et est un ensemble de données de compréhension en lecture extrait basé sur le chinois traditionnel. Les indicateurs d'évaluation sont: EM / F1
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Bascule | 83.1 (82.7) / 89.9 (89,6) | 82.2 (81.6) / 89.2 (88,8) | 102m |
| Bert-wwm | 84.3 (83.4) / 90,5 (90,2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| Bert-wwm- | 85.0 (84,5) / 91.2 (90,9) | 83.6 (83,0) / 90,4 (89,9) | 102m |
| Roberta-wwm-ext | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91,7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| Électra-petit | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78,5) / 85.8 (85,6) | 12m |
| Electra-180G-Small | 83,5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180G-Small-Ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| Base électra | 87,5 (87,0) / 92,5 (92,3) | 86.9 (86.6) / 91.8 (91,7) | 102m |
| Electra-180G-base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| Électra-grand | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180g-Garm | 90.1 / 94.8 | 90,5 / 94.7 | 324m |
Dans la tâche d'inférence du langage naturel, nous adoptons les données XNLI , qui nécessite que le texte soit divisé en trois catégories: entailment , neutral et contradictory . L'indicateur d'évaluation est: précision
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Bascule | 77.8 (77,4) | 77,8 (77,5) | 102m |
| Bert-wwm | 79.0 (78.4) | 78.2 (78.0) | 102m |
| Bert-wwm- | 79.4 (78,6) | 78.7 (78,3) | 102m |
| Roberta-wwm-ext | 80.0 (79.2) | 78.8 (78,3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| Électra-petit | 73.3 (72,5) | 73.1 (72.6) | 12m |
| Electra-180G-Small | 74.6 | 74.6 | 12m |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180G-Small-Ex | 76.5 | 76.6 | 25m |
| Base électra | 77.9 (77.0) | 78,4 (77,8) | 102m |
| Electra-180G-base | 79.6 | 79.5 | 102m |
| Électra-grand | 81.5 | 81.0 | 324m |
| Electra-180g-Garm | 81.2 | 80.4 | 324m |
Dans la tâche d'analyse des sentiments, l'ensemble de données de classification des émotions binaires Chnsenticorp . L'indicateur d'évaluation est: précision
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Bascule | 94.7 (94.3) | 95.0 (94,7) | 102m |
| Bert-wwm | 95.1 (94,5) | 95,4 (95,0) | 102m |
| Bert-wwm- | 95,4 (94,6) | 95,3 (94,7) | 102m |
| Roberta-wwm-ext | 95.0 (94,6) | 95,6 (94,8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| Électra-petit | 92.8 (92,5) | 94.3 (93,5) | 12m |
| Electra-180G-Small | 94.1 | 93.6 | 12m |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180G-Small-Ex | 92.8 | 93.4 | 25m |
| Base électra | 93.8 (93.0) | 94,5 (93,5) | 102m |
| Electra-180G-base | 94.3 | 94.8 | 102m |
| Électra-grand | 95.2 | 95.3 | 324m |
| Electra-180g-Garm | 94.8 | 95.2 | 324m |
Les deux ensembles de données suivants doivent classer une paire de phrases pour déterminer si la sémantique des deux phrases est la même (tâche de classification binaire).
LCQMC a été publié par le Intelligent Computing Research Center de la Harbin Institute of Technology Shenzhen Graduate School. L'indicateur d'évaluation est: précision
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) | 102m |
| Bert-wwm | 89.4 (89.2) | 87.0 (86.8) | 102m |
| Bert-wwm- | 89.6 (89.2) | 87.1 (86.6) | 102m |
| Roberta-wwm-ext | 89,0 (88,7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| Électra-petit | 86.7 (86.3) | 85,9 (85,6) | 12m |
| Electra-180G-Small | 86.6 | 85.8 | 12m |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180G-Small-Ex | 87.6 | 86.3 | 25m |
| Base électra | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180G-base | 90.2 | 87.1 | 102m |
| Électra-grand | 90.7 | 87.3 | 324m |
| Electra-180g-Garm | 90.3 | 87.3 | 324m |
BQ Corpus est publié par le Intelligent Computing Research Center de la Harbin Institute of Technology Shenzhen Graduate School et est un ensemble de données pour le domaine bancaire. L'indicateur d'évaluation est: précision
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Bert | 86.0 (85,5) | 84,8 (84,6) | 102m |
| Bert-wwm | 86.1 (85.6) | 85.2 (84.9) | 102m |
| Bert-wwm- | 86.4 (85,5) | 85,3 (84,8) | 102m |
| Roberta-wwm-ext | 86.0 (85,4) | 85,0 (84,6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| Électra-petit | 83,5 (83,0) | 82.0 (81.7) | 12m |
| Electra-180G-Small | 83.3 | 82.1 | 12m |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180G-Small-Ex | 84.6 | 83.4 | 25m |
| Base électra | 84.8 (84,7) | 84,5 (84,0) | 102m |
| Electra-180G-base | 85.8 | 84.5 | 102m |
| Électra-grand | 86.7 | 85.1 | 324m |
| Electra-180g-Garm | 86.4 | 85.4 | 324m |
Nous avons testé l'Electra judiciaire en utilisant les données de prédiction de la criminalité de la Cail 2018 Judicial Review. Les taux d'apprentissage des petits / bases / grands sont: 5E-4 / 3E-4 / 1E-4 respectivement. L'indicateur d'évaluation est: précision
| Modèle | Ensemble de développement | Test de test | Quantité de paramètre |
|---|---|---|---|
| Électra-petit | 78,84 | 76.35 | 12m |
| électra-électra | 79.60 | 77.03 | 12m |
| Base électra | 80.94 | 78.41 | 102m |
| base légale | 81.71 | 79.17 | 102m |
| Électra-grand | 81,53 | 78,97 | 324m |
| électra-électra | 82.60 | 79.89 | 324m |
Les utilisateurs peuvent effectuer des tâches en aval fini en fonction du modèle pré-formé Chinois Electra ci-dessus. Ici, nous ne présenterons que l'utilisation la plus élémentaire. Pour une utilisation plus détaillée, veuillez vous référer à l'introduction officielle d'Electra.
Dans cet exemple, nous avons utilisé ELECTRA-small pour affiner la tâche CMRC 2018, et les étapes pertinentes sont les suivantes. Supposant,
data-dir : Le répertoire racine de travail peut être défini en fonction de la situation réelle.model-name : nom du modèle, dans ce cas, electra-small .task-name : Nom de la tâche, dans ce cas cmrc2018 . Le code de ce répertoire s'est adapté aux six tâches chinoises ci-dessus, et task-name sont cmrc2018 , drcd , xnli , chnsenticorp , lcqmc et bqcorpus . Dans la section de téléchargement du modèle, téléchargez le modèle Electra-Small et décompressez-les sur ${data-dir}/models/${model-name} . Ce répertoire doit contenir electra_model.* , vocab.txt , checkpoint et un total de 5 fichiers.
Téléchargez l'ensemble de formation et de développement CMRC 2018 et renommez-le pour train.json et dev.json . Mettez deux fichiers dans ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Parmi eux, data-dir et model-name ont été introduits ci-dessus. hparams est un dictionnaire JSON. Dans cet exemple, params_cmrc2018.json contient des hyperparamètres liés à un réglage fin, tels que:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}Dans le fichier JSON ci-dessus, nous énumérons uniquement certains des paramètres les plus importants. Pour la liste complète des paramètres, veuillez vous référer à configure_finenetung.py.
Une fois l'opération terminée,
cmrc2018_dev_preds.json sont enregistrées dans ${data-dir}/results/${task-name}_qa/ . Vous pouvez appeler des scripts d'évaluation externes pour obtenir les résultats de l'évaluation finale, par exemple: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 Q: Comment définir le taux d'apprentissage du modèle Electra lorsqu'il a affiné les tâches en aval?
R: Nous vous recommandons d'utiliser le taux d'apprentissage utilisé par l'article d'origine comme base initiale (petit est 3E-4, la base est 1E-4) puis le débogage avec l'ajout et la diminution appropriés du taux d'apprentissage. Il convient de noter que par rapport à des modèles tels que Bert et Roberta, le taux d'apprentissage de l'électra est relativement important.
Q: Y a-t-il des droits d'auteur de pytorch?
R: Oui, téléchargez le modèle.
Q: Les données pré-formation peuvent-elles être partagées?
R: Malheureusement, non.
Q: Plans futurs?
R: Veuillez rester à l'écoute.
Si le contenu de ce répertoire est utile à vos travaux de recherche, n'hésitez pas à citer le document suivant dans le document.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Bienvenue à suivre le compte officiel officiel de WECHAT de Iflytek Joint Laboratory pour en savoir plus sur les dernières tendances techniques.

Avant de soumettre un problème:


