Chinese ELECTRA
1.0.0
الوصف الصيني | إنجليزي

يعتمد هذا المشروع على Electra الرسمي لجامعة Google & Stanford: https://github.com/google-research/electra
ليرت الصينية | اللغة الإنجليزية الصينية بيرت | صينية ماكبرت | إلكترا الصينية | صينية XLNET | بيرت الصينية | أداة التقطير المعرفة TextBrewer | أداة قطع النموذج TextPruner
شاهد المزيد من الموارد التي أصدرها IFL من معهد Harbin للتكنولوجيا (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model ، والذي يمكن نشره بسرعة وتجربته على الكمبيوتر الشخصي ، عرض: https://github.com/ymcui/Chinese-llama-alpaca
2022/10/29 نقترح LERT النموذج الذي تم تدريبه مسبقًا يدمج المعلومات اللغوية. عرض: https://github.com/ymcui/lert
2022/3/30 نحن نفتح المصدر بنموذج جديد تم تدريبه مسبقًا. عرض: https://github.com/ymcui/pert
2021/12/17 يقوم Iflytek المشترك بإطلاق مجموعة أدوات قطع النموذج TextPruner. عرض: https://github.com/airaria/textpruner
2021/10/24 أصدر مختبر Iflytek المشترك نموذج CINO مسبقًا للغات الأقلية العرقية. عرض: https://github.com/ymcui/Chinese-Minority-plm
2021/7/21 "معالجة اللغة الطبيعية: الأساليب القائمة على نماذج ما قبل التدريب" التي كتبها العديد من العلماء من معهد هاربين للتكنولوجيا SCIR تم نشرها ، وكل شخص مرحب به لشرائه.
2020/12/13 استنادًا إلى بيانات الوثائق القانونية الواسعة النطاق ، قمنا بتدريب نماذج سلسلة Electra الصينية على المجال القضائي لعرض التنزيلات النموذجية ، وتأثيرات المهمة القضائية.
2020/9/15 تم توظيف ورقة "إعادة النظر في النماذج التي تم تدريبها قبل التدريب لمعالجة اللغة الطبيعية الصينية" كمقال طويل من خلال نتائج EMNLP.
2020/8/27 تصدرت مختبر IFL المشترك القائمة في تقييم Glue General Natural Language Thating ، تحقق من قائمة الغراء ، الأخبار.
2020/5/29 تم إصدار Electra-Large/Small-EX. يرجى التحقق من تنزيل النموذج. حاليًا ، يتوفر عنوان تنزيل Google Drive فقط ، لذا يرجى الفهم.
2020/4/7 يمكن لمستخدمي Pytorch تحميل النموذج من خلال المحولات لعرض التحميل السريع.
2020/3/31 تم توصيل النماذج المنشورة في هذا الدليل بـ PaddlePaddleHub لعرضها وتحميلها بسرعة.
2020/3/25 تم إصدار Electra-Small الصيني/القاعدة ، يرجى التحقق من تنزيل النموذج.
| الفصل | يصف |
|---|---|
| مقدمة | مقدمة للمبادئ الأساسية للكانتيرا |
| تنزيل النموذج | قم بتنزيل النموذج الصيني Electra مسبقًا |
| تحميل سريع | كيفية استخدام المحولات و Paddlehub بسرعة تحميل نماذج |
| تأثيرات نظام الأساس | آثار نظام خط الأساس الصيني: فهم القراءة ، تصنيف النص ، إلخ. |
| كيفية استخدام | استخدام مفصل للنموذج |
| التعليمات | الأسئلة الشائعة والإجابات |
| يقتبس | التقارير الفنية في هذا الدليل |
يقترح Electra إطارًا جديدًا قبل التدريب يتضمن جزأين: المولد والمميّز .
بعد انتهاء مرحلة ما قبل التدريب ، نستخدم فقط التمييز كنموذج أساسي للمهام المصب التي تم ضبطها.
لمزيد من المحتوى التفصيلي ، يرجى الرجوع إلى ورقة Electra: Electra: ترميز النصوص قبل التدريب على أنها تمييزات بدلاً من المولدات
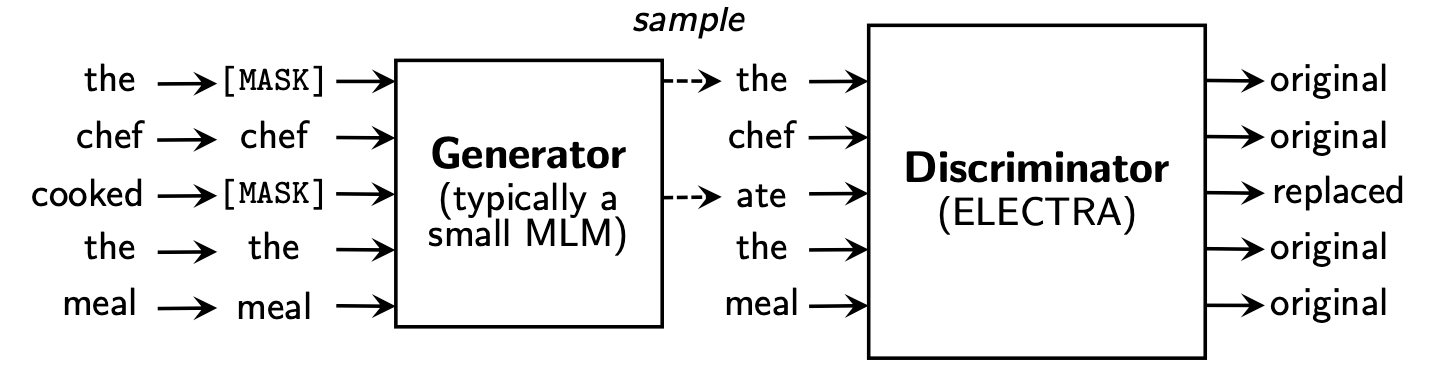
يحتوي هذا الدليل على النماذج التالية ويوفر حاليًا فقط أوزان إصدار TensorFlow.
ELECTRA-large, Chinese : 24 طبقة ، 1024-Hidden ، 16 رأس ، 324 متر معلماتELECTRA-base, Chinese : 12 طبقة ، 768-Hidden ، 12 رأس ، 102 متر معلماتELECTRA-small-ex, Chinese : 24 طبقة ، 256-Hidden ، 4 رؤوس ، 25 متر معلماتELECTRA-small, Chinese : 12 طبقة ، 256-Hidden ، 4 رؤوس ، 12M المعلمات | نموذج الاختصار | تنزيل Google | Baidu NetDisk تنزيل | حجم الحزمة المضغوطة |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | TensorFlow (كلمة المرور 2V5R) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | TensorFlow (كلمة المرور 3VG1) | 383M |
ELECTRA-180g-small-ex, Chinese | Tensorflow | TensorFlow (كلمة المرور 93N8) | 92 متر |
ELECTRA-180g-small, Chinese | Tensorflow | TensorFlow (كلمة المرور K9IU) | 46 م |
| نموذج الاختصار | تنزيل Google | Baidu NetDisk تنزيل | حجم الحزمة المضغوطة |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | TensorFlow (كلمة المرور 1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | TensorFlow (كلمة المرور F32J) | 383M |
ELECTRA-small-ex, Chinese | Tensorflow | TensorFlow (كلمة المرور GFB1) | 92 متر |
ELECTRA-small, Chinese | Tensorflow | TensorFlow (كلمة المرور 1R4R) | 46 م |
| نموذج الاختصار | تنزيل Google | Baidu NetDisk تنزيل | حجم الحزمة المضغوطة |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | TensorFlow (كلمة المرور Q4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | TensorFlow (كلمة المرور 8GCV) | 383M |
legal-ELECTRA-small, Chinese | Tensorflow | TensorFlow (كلمة المرور KMRJ) | 46 م |
إذا كنت بحاجة إلى إصدار Pytorch ، فيرجى تحويله بنفسك من خلال برنامج التحويل المحول enterted_electra_original_tf_checkpoint_to_pytorch.py المقدم بواسطة Transformers. إذا كنت بحاجة إلى ملفات التكوين ، فيمكنك إدخال مجلد التكوين في هذا الدليل للبحث.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorأو قم بتنزيل Pytorch مباشرة من خلال الموقع الرسمي لـ Huggingface: https://huggingface.co/HFL
الطريقة: انقر فوق أي نموذج تريد تنزيله → اسحب إلى أسفل وانقر فوق "قائمة جميع الملفات في الطراز" → تنزيل ملفات Bin و JSON في المربع المنبثق.
يوصى باستخدام نقاط تنزيل Baidu NetDisk في الصين البر الرئيسي ، بينما يوصى باستخدام نقاط تنزيل Google في المستخدمين في الخارج. أخذ نسخة TensorFlow من ELECTRA-small, Chinese كمثال ، بعد تنزيل ، فك ضغط ملف zip للحصول على الملف التالي.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
استخدمنا الويكي الصيني على نطاق واسع والنص العام لتدريب نموذج Electra ، حيث بلغ إجمالي عدد الرمز المميز 5.4b ، وهو ما يتوافق مع نموذج سلسلة Roberta-WWM-Ext. فيما يتعلق بقائمة المفردات ، فإنه يستخدم قائمة المفردات الأصلية لـ Bert Wordpiece ، بما في ذلك 21،128 رمزًا. التفاصيل الأخرى وفرط الأبراميرات هي كما يلي (تبقى المعلمات غير المذكورة افتراضية):
ELECTRA-large : 24 طبقة ، طبقة مخفية 1024 ، 16 رؤساء انتباه ، معدل التعلم 1E-4 ، Batch96 ، الحد الأقصى للطول 512 ، تدريب 2M خطواتELECTRA-base : 12 طبقة ، طبقة مخفية 768 ، 12 رؤساء انتباه ، معدل التعلم 2E-4 ، Batch256 ، الحد الأقصى للطول 512 ، تدريب 1M خطوةELECTRA-small-ex : 24 طبقة ، طبقة مخفية 256 ، 4 رؤوس انتباه ، معدل التعلم 5E-4 ، Batch384 ، الحد الأقصى للطول 512 ، 2M خطوات التدريبELECTRA-small : 12 طبقة ، طبقة مخفية 256 ، 4 رؤوس انتباه ، معدل التعلم 5E-4 ، Batch1024 ، الحد الأقصى للطول 512 ، تدريب 1M خطوة لقد دعم الإصدار 2.8.0 من Huggingface Transformers نموذج Electra رسميًا ويمكن استدعاؤه من خلال الأوامر التالية.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) القائمة المقابلة لـ MODEL_NAME هي كما يلي:
| اسم النموذج | عناصر | model_name |
|---|---|---|
| Electra-180g-large ، الصينية | تمييز | HFL/الصينية-Electra-180g-large-discriminator |
| Electra-180g-large ، الصينية | مولد | HFL/الصينية-Electra-180g-large-generator |
| Electra-180g-base ، الصينية | تمييز | HFL/الصينية-Electra-180g-base-discriminator |
| Electra-180g-base ، الصينية | مولد | HFL/الصينية-Electra-180G القاعدية |
| Electra-180g-Small-EX ، الصينية | تمييز | HFL/الصينية-Electra-180g-small-Excriminator |
| Electra-180g-Small-EX ، الصينية | مولد | HFL/الصينية-Electra-180g-Small-Ex-Cenerator |
| Electra-180g-Small ، الصينية | تمييز | HFL/الصينية-Electra-180g-Small-Discriminator |
| Electra-180g-Small ، الصينية | مولد | HFL/الصينية-Electra-180g-Small-Generator |
| Electra-Large ، الصينية | تمييز | HFL/الصينية-Electra-large-discriminator |
| Electra-Large ، الصينية | مولد | HFL/الصينية-إكرا-لارجي المولد |
| Electra-Base ، الصينية | تمييز | HFL/صينية-Electra-base-discriminator |
| Electra-Base ، الصينية | مولد | HFL/الصينية الإلكترونية القاعدية |
| Electra-Small-EX ، الصينية | تمييز | HFL/الصينية-Electra-Small-Excriminator |
| Electra-Small-EX ، الصينية | مولد | HFL/الصينية-Electra-Small-Ex-Cenerator |
| Electra-Small ، الصينية | تمييز | HFL/الصينية-Electra-Small-Discriminator |
| Electra-Small ، الصينية | مولد | HFL/الصينية-Electra-Small-Generator |
نسخة المجال القضائي:
| اسم النموذج | عناصر | model_name |
|---|---|---|
| القانوني electra-large ، الصينية | تمييز | HFL/الصينية-القانوني-Electra-large-discriminator |
| القانوني electra-large ، الصينية | مولد | HFL/الصينية-القانوني-إركرا لارجة |
| القاعدة القانونية ، الصينية | تمييز | HFL/صينية-قاعدية قاعدية القاعدة |
| القاعدة القانونية ، الصينية | مولد | HFL/الصينية-القاعدة القاعدية القاعدية |
| القانوني electra-small ، الصينية | تمييز | HFL/الصينية-القانوني-Electra-Small-Discriminator |
| القانوني electra-small ، الصينية | مولد | HFL/الصينية-القانوني-إلكترا سميليرات |
بالاعتماد على Paddlehub ، نحتاج فقط إلى سطر واحد من التعليمات البرمجية لإكمال تنزيل وتثبيت النموذج ، ويمكن لأكثر من عشرة أسطر من التعليمات البرمجية إكمال مهام تصنيف النص ، وتوضيح التسلسل ، وفهم القراءة والمهام الأخرى.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
القائمة المقابلة لـ MODULE_NAME هي كما يلي:
| اسم النموذج | module_name |
|---|---|
| Electra-Base ، الصينية | القاعدة الصينية الإلكترونية |
| Electra-Small ، الصينية | الصينية الإركان Small |
قارنا آثار ELECTRA-small/base مع BERT-base و BERT-wwm و BERT-wwm-ext و RoBERTa-wwm-ext و RBT3 ، بما في ذلك المهام الست التالية:
بالنسبة لنموذج Electra-Small/Base ، نستخدم معدلات التعلم الافتراضية لـ 3e-4 و 1e-4 في الورقة الأصلية. تجدر الإشارة إلى أننا لم نقم بإجراء تعديلات معلمات لأي مهام ، لذلك قد يتم تحقيق المزيد من تحسينات الأداء من خلال ضبط المقاييس البارزة مثل معدل التعلم. من أجل ضمان موثوقية النتائج ، لنفس النموذج ، قمنا بتدريب 10 مرات باستخدام بذور عشوائية مختلفة للإبلاغ عن أقصى ومتوسط قيم أداء النموذج (متوسط القيم بين قوسين).
مجموعة بيانات CMRC 2018 هي بيانات فهم القراءة الصينية التي تصدرها المختبر المشترك لمعهد هاربين للتكنولوجيا. وفقًا لسؤال معين ، يحتاج النظام إلى استخراج أجزاء من الفصل مثل الإجابة ، في نفس الشكل مثل Squad. مؤشرات التقييم هي: EM / F1
| نموذج | مجموعة التنمية | مجموعة الاختبار | مجموعة التحدي | كمية المعلمة |
|---|---|---|---|---|
| bert-base | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| بيرت وود | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| بيرت-WWM-EXT | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| روبرتا-ووي إم | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38 م |
| Electra-Small | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12 م |
| Electra-180g-small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12 م |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180g-Small-Ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| القاعدة الكهربائية | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102m |
| Electra-180g-base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| Electra-large | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324 م |
| Electra-180g-large | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324 م |
تم إصدار مجموعة بيانات DRCD من قبل معهد دلتا للأبحاث ، تايوان ، الصين. شكله هو نفس المجموعة وهي عبارة عن مجموعة بيانات لفهم القراءة المستخرجة على أساس الصينيين التقليديين. مؤشرات التقييم هي: EM / F1
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| bert-base | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102m |
| بيرت وود | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| بيرت-WWM-EXT | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102m |
| روبرتا-ووي إم | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38 م |
| Electra-Small | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12 م |
| Electra-180g-small | 83.5 / 89.2 | 82.9 / 88.7 | 12 م |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180g-Small-Ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| القاعدة الكهربائية | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102m |
| Electra-180g-base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| Electra-large | 88.8 / 93.3 | 88.8 / 93.6 | 324 م |
| Electra-180g-large | 90.1 / 94.8 | 90.5 / 94.7 | 324 م |
في مهمة الاستدلال للغة الطبيعية ، نعتمد بيانات Xnli ، والتي تتطلب تقسيم النص إلى ثلاث فئات: entailment ، neutral ، contradictory . مؤشر التقييم هو: الدقة
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| bert-base | 77.8 (77.4) | 77.8 (77.5) | 102m |
| بيرت وود | 79.0 (78.4) | 78.2 (78.0) | 102m |
| بيرت-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) | 102m |
| روبرتا-ووي إم | 80.0 (79.2) | 78.8 (78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38 م |
| Electra-Small | 73.3 (72.5) | 73.1 (72.6) | 12 م |
| Electra-180g-small | 74.6 | 74.6 | 12 م |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180g-Small-Ex | 76.5 | 76.6 | 25m |
| القاعدة الكهربائية | 77.9 (77.0) | 78.4 (77.8) | 102m |
| Electra-180g-base | 79.6 | 79.5 | 102m |
| Electra-large | 81.5 | 81.0 | 324 م |
| Electra-180g-large | 81.2 | 80.4 | 324 م |
في مهمة تحليل المشاعر ، مجموعة بيانات تصنيف العاطفة الثنائية ChnsentIcorp . مؤشر التقييم هو: الدقة
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| bert-base | 94.7 (94.3) | 95.0 (94.7) | 102m |
| بيرت وود | 95.1 (94.5) | 95.4 (95.0) | 102m |
| بيرت-WWM-EXT | 95.4 (94.6) | 95.3 (94.7) | 102m |
| روبرتا-ووي إم | 95.0 (94.6) | 95.6 (94.8) | 102m |
| RBT3 | 92.8 | 92.8 | 38 م |
| Electra-Small | 92.8 (92.5) | 94.3 (93.5) | 12 م |
| Electra-180g-small | 94.1 | 93.6 | 12 م |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180g-Small-Ex | 92.8 | 93.4 | 25m |
| القاعدة الكهربائية | 93.8 (93.0) | 94.5 (93.5) | 102m |
| Electra-180g-base | 94.3 | 94.8 | 102m |
| Electra-large | 95.2 | 95.3 | 324 م |
| Electra-180g-large | 94.8 | 95.2 | 324 م |
تحتاج مجموعتي البيانات التالية إلى تصنيف زوج الجملة لتحديد ما إذا كانت دلالات الجملتين متماثلة (مهمة التصنيف الثنائي).
تم إصدار LCQMC من قبل مركز أبحاث الحوسبة الذكي في معهد هاربين للتكنولوجيا شنتشن الدراسات العليا. مؤشر التقييم هو: الدقة
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| بيرت | 89.4 (88.4) | 86.9 (86.4) | 102m |
| بيرت وود | 89.4 (89.2) | 87.0 (86.8) | 102m |
| بيرت-WWM-EXT | 89.6 (89.2) | 87.1 (86.6) | 102m |
| روبرتا-ووي إم | 89.0 (88.7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38 م |
| Electra-Small | 86.7 (86.3) | 85.9 (85.6) | 12 م |
| Electra-180g-small | 86.6 | 85.8 | 12 م |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180g-Small-Ex | 87.6 | 86.3 | 25m |
| القاعدة الكهربائية | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180g-base | 90.2 | 87.1 | 102m |
| Electra-large | 90.7 | 87.3 | 324 م |
| Electra-180g-large | 90.3 | 87.3 | 324 م |
يتم إصدار BQ Corpus من قبل مركز أبحاث الحوسبة الذكية لمعهد هاربين للتكنولوجيا شنتشن الدراسات العليا وهي مجموعة بيانات للمجال المصرفي. مؤشر التقييم هو: الدقة
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| بيرت | 86.0 (85.5) | 84.8 (84.6) | 102m |
| بيرت وود | 86.1 (85.6) | 85.2 (84.9) | 102m |
| بيرت-WWM-EXT | 86.4 (85.5) | 85.3 (84.8) | 102m |
| روبرتا-ووي إم | 86.0 (85.4) | 85.0 (84.6) | 102m |
| RBT3 | 84.1 | 83.3 | 38 م |
| Electra-Small | 83.5 (83.0) | 82.0 (81.7) | 12 م |
| Electra-180g-small | 83.3 | 82.1 | 12 م |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180g-Small-Ex | 84.6 | 83.4 | 25m |
| القاعدة الكهربائية | 84.8 (84.7) | 84.5 (84.0) | 102m |
| Electra-180g-base | 85.8 | 84.5 | 102m |
| Electra-large | 86.7 | 85.1 | 324 م |
| Electra-180g-large | 86.4 | 85.4 | 324 م |
لقد اختبرنا Electra القضائي باستخدام بيانات التنبؤ بجريمة CAIL 2018 للمراجعة القضائية. معدلات تعلم الصغيرة/القاعدة/الكبيرة هي: 5E-4/3E-4/1E-4 على التوالي. مؤشر التقييم هو: الدقة
| نموذج | مجموعة التنمية | مجموعة الاختبار | كمية المعلمة |
|---|---|---|---|
| Electra-Small | 78.84 | 76.35 | 12 م |
| القانوني electra-small | 79.60 | 77.03 | 12 م |
| القاعدة الكهربائية | 80.94 | 78.41 | 102m |
| القاعدة القانونية | 81.71 | 79.17 | 102m |
| Electra-large | 81.53 | 78.97 | 324 م |
| قانوني electra-large | 82.60 | 79.89 | 324 م |
يمكن للمستخدمين أداء مهام المصب المتصاعدة استنادًا إلى النموذج الصيني Electra المنشور مسبقًا أعلاه. هنا سنقدم فقط الاستخدام الأساسي. لمزيد من الاستخدام التفصيلي ، يرجى الرجوع إلى المقدمة الرسمية لـ Electra.
في هذا المثال ، استخدمنا نموذج ELECTRA-small لضبط مهمة CMRC 2018 ، والخطوات ذات الصلة هي كما يلي. على افتراض ،
data-dir : يمكن تعيين دليل جذر العمل وفقًا للوضع الفعلي.model-name : اسم النموذج ، في هذه الحالة electra-small .task-name : اسم المهمة ، في هذه الحالة cmrc2018 . تكيف الكود في هذا الدليل مع المهام الصينية الستة المذكورة أعلاه ، task-name هي cmrc2018 و drcd xnli و chnsenticorp و lcqmc و bqcorpus . في قسم تنزيل النموذج ، قم بتنزيل نموذج Electra-Small وقم بإلغاء ضغطه إلى ${data-dir}/models/${model-name} . يجب أن يحتوي هذا الدليل على electra_model.* ، vocab.txt ، checkpoint ، وما مجموعه 5 ملفات.
قم بتنزيل مجموعة التدريب والتطوير CMRC 2018 وإعادة تسميتها إلى train.json و dev.json . ضع ملفين في ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json من بينها ، تم تقديم data-dir واسم model-name أعلاه. hparams هو قاموس JSON. في هذا المثال ، يحتوي params_cmrc2018.json على أجهزة التثبيت ذات الصلة الفائقة ذات الصلة ، مثل:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}في ملف JSON أعلاه ، ندرج فقط بعض المعلمات الأكثر أهمية. للحصول على قائمة المعلمات الكاملة ، يرجى الرجوع إلى configure_finenetung.py.
بعد اكتمال العملية ،
cmrc2018_dev_preds.json في ${data-dir}/results/${task-name}_qa/ . يمكنك استدعاء البرامج النصية للتقييم الخارجي للحصول على نتائج التقييم النهائي ، على سبيل المثال: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 س: كيفية ضبط معدل التعلم لنموذج Electra عند صياغة مهام المصب؟
ج: نوصي باستخدام معدل التعلم الذي تستخدمه الورقة الأصلية كخط الأساس الأولي (صغير هو 3E-4 ، القاعدة هي 1E-4) ثم تصحيح الأخطاء مع الإضافة المناسبة وانخفاض معدل التعلم. تجدر الإشارة إلى أنه بالمقارنة مع نماذج مثل Bert و Roberta ، فإن معدل تعلم Electra كبير نسبيًا.
س: هل هناك أي حقوق حقوق النشر Pytorch؟
ج: نعم ، قم بتنزيل النموذج.
س: هل يمكن مشاركة بيانات التدريب المسبق؟
ج: لسوء الحظ ، لا.
س: خطط مستقبلية؟
ج: يرجى ترقب.
إذا كان المحتوى الموجود في هذا الدليل مفيدًا لعمل البحث الخاص بك ، فلا تتردد في اقتباس الورقة التالية في الورقة.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
مرحبًا بك لمتابعة الحساب الرسمي الرسمي لـ WeChat لمختبر Iflytek المشترك للتعرف على أحدث الاتجاهات الفنية.

قبل تقديم مشكلة:


