Chinese ELECTRA
1.0.0
中国語の説明|英語

このプロジェクトは、Google&Stanford Universityの公式エレクトラに基づいています:https://github.com/google-research/electra
中国語のレート|中国の英語のパート|中国のマッバート|中国のエレクトラ|中国のxlnet |中国のバート|知識蒸留ツールTextBrewer |モデル切削工具TextPruner
Harbin Institute of Technology(HFL)のIFLがリリースするリソースをご覧ください:https://github.com/ymcui/hfl-anthology
2023/3/28オープンソースチャイニーズラマ&アルパカビッグモデルは、PCで迅速に展開および経験することができます。
2022/10/29言語情報を統合する事前に訓練されたモデルLERTを提案します。表示:https://github.com/ymcui/lert
2022/3/30新しい事前訓練を受けたモデルPERTをオープンソース。表示:https://github.com/ymcui/pert
2021/12/17 Iflytek共同研究所は、モデル切削工具キットTextPrunerを起動します。表示:https://github.com/iararia/textpruner
2021/10/24 Iflytek共同研究所は、少数民族の言語向けに事前に訓練されたモデルCINOをリリースしました。ビュー:https://github.com/ymcui/chinese-minority-plm
2021/7/21「自然言語処理:トレーニング前モデルに基づく方法」Harbin Institute of Technology Scirの多くの学者によって書かれた方法が公開されており、誰もがそれを購入できます。
2020/12/13大規模な法的文書データに基づいて、司法分野の中国のエレクトラシリーズモデルを訓練して、モデルのダウンロードと司法のタスク効果を確認しました。
2020/9/15私たちの論文「中国の自然言語処理の事前に訓練されたモデルの再訪」は、EMNLPの調査結果によって長い記事として雇われました。
2020/8/27 IFL共同研究所は、General Natural Language Understanting評価の接着剤のリストのトップになりました。
2020/5/29中国のエレクトラ - ラージ/スモールエックスがリリースされました。モデルのダウンロードを確認してください。現在、Googleドライブのダウンロードアドレスのみが利用可能ですので、理解してください。
2020/4/7 Pytorchユーザーは、モデルを介してモデルをロードして、高速負荷を表示できます。
2020/3/31このディレクトリに公開されているモデルは、迅速に表示およびロードするためにPaddlePaddlehubに接続されています。
2020/3/25中国のエレクトラスマール/ベースがリリースされました。モデルのダウンロードを確認してください。
| 章 | 説明する |
|---|---|
| 導入 | エレクトラの基本原則の紹介 |
| モデルダウンロード | 中国のエレクトラ事前訓練モデルをダウンロードします |
| クイックロード | トランスとパドルハブの使用方法モデルをすばやく読み込みます |
| ベースラインシステム効果 | 中国のベースラインシステムの効果:読解、テキスト分類など。 |
| 使い方 | モデルの詳細な使用 |
| よくある質問 | FAQと回答 |
| 引用 | このディレクトリの技術レポート |
Electraは、ジェネレーターと判別器の2つの部分を含む新しいトレーニング前のフレームワークを提案しています。
トレーニング前の段階が終了した後、Down Stream Taskの基本モデルとして微調整されたベースモデルとしてのみ識別子を使用します。
より詳細なコンテンツについては、Electra Paper:Electra:Pre-Training Text Encodersを発電機ではなく判別器として参照してください。
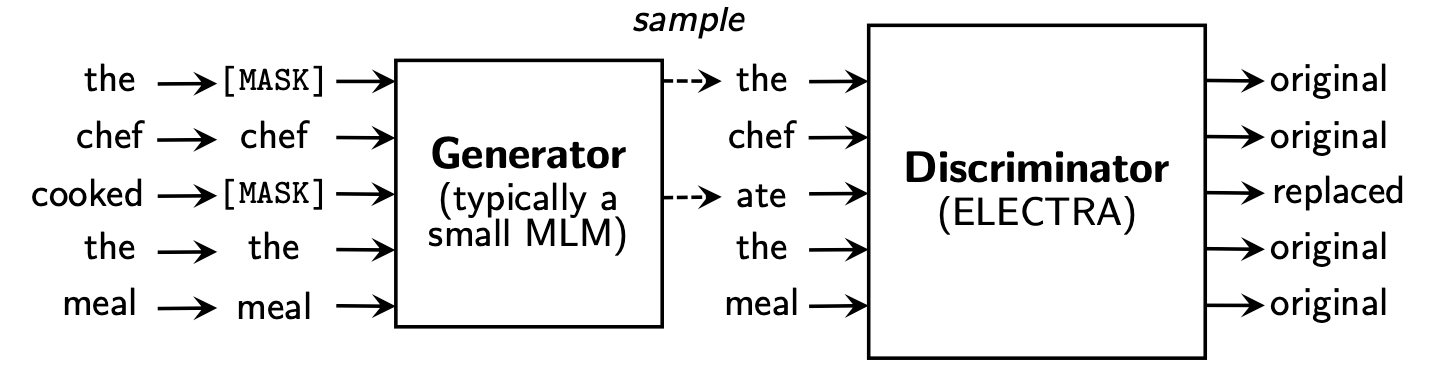
このディレクトリには次のモデルが含まれており、現在はTensorflowバージョンの重みのみを提供しています。
ELECTRA-large, Chinese :24層、1024層、16頭、324mパラメーターELECTRA-base, Chinese :12層、768層、12頭、102mパラメーターELECTRA-small-ex, Chinese :24層、256距離、4頭、25mパラメーターELECTRA-small, Chinese :12層、256層、4頭、12mパラメーター| モデルの略語 | Googleダウンロード | Baidu Netdiskダウンロード | 圧縮パッケージサイズ |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | Tensorflow(パスワード2v5r) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | Tensorflow(パスワード3VG1) | 383m |
ELECTRA-180g-small-ex, Chinese | Tensorflow | Tensorflow(パスワード93n8) | 92m |
ELECTRA-180g-small, Chinese | Tensorflow | Tensorflow(パスワードK9IU) | 46m |
| モデルの略語 | Googleダウンロード | Baidu Netdiskダウンロード | 圧縮パッケージサイズ |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | Tensorflow(パスワード1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | Tensorflow(パスワードF32J) | 383m |
ELECTRA-small-ex, Chinese | Tensorflow | Tensorflow(パスワードGFB1) | 92m |
ELECTRA-small, Chinese | Tensorflow | Tensorflow(パスワード1R4R) | 46m |
| モデルの略語 | Googleダウンロード | Baidu Netdiskダウンロード | 圧縮パッケージサイズ |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | Tensorflow(パスワードQ4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | Tensorflow(パスワード8GCV) | 383m |
legal-ELECTRA-small, Chinese | Tensorflow | Tensorflow(パスワードkmrj) | 46m |
Pytorchバージョンが必要な場合は、変換型converectra_original_tf_checkpoint_to_pytorch.pyから変換された変換スクリプトを介して自分で変換してください。構成ファイルが必要な場合は、このディレクトリに構成フォルダーを入力して検索できます。
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorまたは、Huggingface:https://huggingface.co/hflの公式WebサイトからPytorchを直接ダウンロードしてください
方法:ダウンロードするモデルをクリックします
中国本土でバイドゥNetDiskダウンロードポイントを使用することをお勧めしますが、海外のユーザーでGoogleダウンロードポイントを使用することをお勧めします。 TensorflowバージョンのELECTRA-small, Chineseを例として、ダウンロードした後、ZIPファイルを減圧して次のファイルを取得します。
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
大規模な中国のウィキと一般的なテキストを使用してElectraモデルを訓練しました。これは、Roberta-WWM-Extシリーズモデルと一致する5.4Bに達します。語彙リストに関しては、21,128トークンを含むGoogleのオリジナルのBert Wordpiece語彙リストを使用しています。その他の詳細とハイパーパラメーターは次のとおりです(問題のないパラメーターはデフォルトのままです):
ELECTRA-large :24レイヤー、隠れレイヤー1024、16の注意ヘッド、学習レート1E-4、Batch96、最大長512、トレーニング2mステップELECTRA-base :12レイヤー、隠れレイヤー768、12の注意ヘッド、学習レート2E-4、バッチ256、最大長512、トレーニング1MステップELECTRA-small-ex :24レイヤー、隠れレイヤー256、4注意ヘッド、学習率5E-4、Batch384、最大長512、2mトレーニングのステップELECTRA-small :12層、隠れレイヤー256、4注意ヘッド、学習レート5E-4、Batch1024、最大長512、トレーニング1MステップHuggingface-Transformersバージョン2.8.0は、Electraモデルを正式にサポートしており、次のコマンドを通じて呼び出すことができます。
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) MODEL_NAMEの対応するリストは次のとおりです。
| モデル名 | コンポーネント | model_name |
|---|---|---|
| Electra-180g-Large、中国語 | 判別器 | HFL/中国 - 電気 - 180G-Large-Discriminator |
| Electra-180g-Large、中国語 | ジェネレータ | HFL/中国電気 - 180g-grege-generator |
| エレクトラ-180gベース、中国語 | 判別器 | HFL/中国 - 電気-180Gベース微小化装置 |
| エレクトラ-180gベース、中国語 | ジェネレータ | HFL/中国電気 - 180Gベース生成器 |
| Electra-180g-Small-Ex、中国語 | 判別器 | HFL/中国 - 電気-180G-Small-Ex-Discriminator |
| Electra-180g-Small-Ex、中国語 | ジェネレータ | HFL/中国 - 電気-180G-Small-Ex-Generator |
| Electra-180g-Small、中国語 | 判別器 | HFL/中国 - 電気-180G-Small-Discriminator |
| Electra-180g-Small、中国語 | ジェネレータ | HFL/中国電気 - 180Gスマルジェネレーター |
| エレクトラ・ラージ、中国語 | 判別器 | HFL/中国 - 電気 - ゆるい微小化装置 |
| エレクトラ・ラージ、中国語 | ジェネレータ | HFL/中国 - 電気 - - ゆっくりした生成器 |
| エレクトラベース、中国語 | 判別器 | HFL/中国電気 - 底微小化装置 |
| エレクトラベース、中国語 | ジェネレータ | HFL/中国 - 電気 - ベース生成器 |
| Electra-Small-Ex、中国語 | 判別器 | HFL/中国 - 電気 - スモール - ex-discriminator |
| Electra-Small-Ex、中国語 | ジェネレータ | HFL/中国 - 電気 - スモール - エクスジェネレーター |
| エレクトラスマール、中国語 | 判別器 | HFL/中国 - 電気 - スモールディスクリミネーター |
| エレクトラスマール、中国語 | ジェネレータ | HFL/中国 - 電気 - スモールジェネレーター |
司法ドメインバージョン:
| モデル名 | コンポーネント | model_name |
|---|---|---|
| Legal-Electra-Large、中国語 | 判別器 | HFL/中国 - リーガル - 電気 - ゆるいディスクリミネーター |
| Legal-Electra-Large、中国語 | ジェネレータ | HFL/中国 - リーガル - 電気 - ゆっくりした生成器 |
| Legal-Electra-Base、中国語 | 判別器 | HFL/中国 - リーガル電気 - ベース - ディスクリミネーター |
| Legal-Electra-Base、中国語 | ジェネレータ | HFL/中国 - リーガル電気 - ベース生成器 |
| Legal-Electra-Small、中国語 | 判別器 | HFL/中国 - リーガル - 電気 - スモール - ディスクリミネーター |
| Legal-Electra-Small、中国語 | ジェネレータ | HFL/中国 - リーガル - 電気 - スマルジェネレーター |
Paddlehubに依存すると、モデルのダウンロードとインストールを完了するには1行のコードのみが必要です。10行以上のコードがテキスト分類、シーケンス注釈、読解、その他のタスクのタスクを完了することができます。
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
MODULE_NAMEの対応するリストは次のとおりです。
| モデル名 | module_name |
|---|---|
| エレクトラベース、中国語 | 中国 - 電気ベース |
| エレクトラスマール、中国語 | 中国 - 電気帯 |
ELECTRA-small/baseの効果を、 BERT-base 、 BERT-wwm 、 BERT-wwm-ext 、 RoBERTa-wwm-ext 、およびRBT3と比較しました。
Electra-Small/Baseモデルでは、元の論文で3e-4および1e-4のデフォルト学習率を使用します。タスクのパラメーター調整を実行していないことに注意する必要があるため、学習率などのハイパーパラメーターを調整することで、さらなるパフォーマンスの改善が実現される可能性があります。結果の信頼性を確保するために、同じモデルで、異なるランダムシードを使用して10回トレーニングして、モデルパフォーマンスの最大値と平均値(ブラケットの平均値)を報告しました。
CMRC 2018データセットは、ハルビン工科大学の合同研究所によってリリースされた中国の機械読解データです。特定の質問によると、システムは、章から章から断片を答えとして抽出する必要があります。評価指標は次のとおりです。EM / F1
| モデル | 開発セット | テストセット | チャレンジセット | パラメーター数 |
|---|---|---|---|---|
| バートベース | 65.5(64.4) / 84.5(84.0) | 70.0(68.7) / 87.0(86.3) | 18.6(17.0) / 43.3(41.3) | 102m |
| bert-wwm | 66.3(65.0) / 85.6(84.7) | 70.5(69.1) / 87.4(86.7) | 21.0(19.3) / 47.0(43.9) | 102m |
| bert-wwm-ext | 67.1(65.6) / 85.7(85.0) | 71.4(70.0) / 87.7(87.0) | 24.0(20.0) / 47.3(44.6) | 102m |
| roberta-wwm-ext | 67.4(66.5) / 87.2(86.5) | 72.6(71.4) / 89.4(88.8) | 26.2(24.6) / 51.0(49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Electra-Small | 63.4(62.9) / 80.8(80.2) | 67.8(67.4) / 83.4(83.0) | 16.3(15.4) / 37.2(35.8) | 12m |
| Electra-180g-Small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180g-Small-Ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| エレクトラベース | 68.4(68.0) / 84.8(84.6) | 73.1(72.7) / 87.1(86.9) | 22.6(21.7) / 45.0(43.8) | 102m |
| Electra-180gベース | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| エレクトラ・ラージ | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180g-Large | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
DRCDデータセットは、中国の台湾にあるデルタ研究所によってリリースされました。そのフォームは分隊と同じであり、伝統的な中国語に基づいた抽出された読解データセットです。評価指標は次のとおりです。EM / F1
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| バートベース | 83.1(82.7) / 89.9(89.6) | 82.2(81.6) / 89.2(88.8) | 102m |
| bert-wwm | 84.3(83.4) / 90.5(90.2) | 82.8(81.8) / 89.7(89.0) | 102m |
| bert-wwm-ext | 85.0(84.5) / 91.2(90.9) | 83.6(83.0) / 90.4(89.9) | 102m |
| roberta-wwm-ext | 86.6(85.9) / 92.5(92.2) | 85.6(85.2) / 92.0(91.7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| Electra-Small | 79.8(79.4) / 86.7(86.4) | 79.0(78.5) / 85.8(85.6) | 12m |
| Electra-180g-Small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180g-Small-Ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| エレクトラベース | 87.5(87.0) / 92.5(92.3) | 86.9(86.6) / 91.8(91.7) | 102m |
| Electra-180gベース | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| エレクトラ・ラージ | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180g-Large | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
自然言語の推論タスクでは、 XNLIデータを採用します。これcontradictoryは、テキストを3つのカテゴリにentailmentする必要がありますneutral評価インジケーターは次のとおりです。精度
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| バートベース | 77.8(77.4) | 77.8(77.5) | 102m |
| bert-wwm | 79.0(78.4) | 78.2(78.0) | 102m |
| bert-wwm-ext | 79.4(78.6) | 78.7(78.3) | 102m |
| roberta-wwm-ext | 80.0(79.2) | 78.8(78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| Electra-Small | 73.3(72.5) | 73.1(72.6) | 12m |
| Electra-180g-Small | 74.6 | 74.6 | 12m |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180g-Small-Ex | 76.5 | 76.6 | 25m |
| エレクトラベース | 77.9(77.0) | 78.4(77.8) | 102m |
| Electra-180gベース | 79.6 | 79.5 | 102m |
| エレクトラ・ラージ | 81.5 | 81.0 | 324m |
| Electra-180g-Large | 81.2 | 80.4 | 324m |
センチメント分析タスクでは、バイナリ感情分類データセットchnsenticorp 。評価インジケーターは次のとおりです。精度
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| バートベース | 94.7(94.3) | 95.0(94.7) | 102m |
| bert-wwm | 95.1(94.5) | 95.4(95.0) | 102m |
| bert-wwm-ext | 95.4(94.6) | 95.3(94.7) | 102m |
| roberta-wwm-ext | 95.0(94.6) | 95.6(94.8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| Electra-Small | 92.8(92.5) | 94.3(93.5) | 12m |
| Electra-180g-Small | 94.1 | 93.6 | 12m |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180g-Small-Ex | 92.8 | 93.4 | 25m |
| エレクトラベース | 93.8(93.0) | 94.5(93.5) | 102m |
| Electra-180gベース | 94.3 | 94.8 | 102m |
| エレクトラ・ラージ | 95.2 | 95.3 | 324m |
| Electra-180g-Large | 94.8 | 95.2 | 324m |
次の2つのデータセットでは、文のペアを分類して、2つの文のセマンティクスが同じかどうかを判断する必要があります(バイナリ分類タスク)。
LCQMCは、Harbin Technology Institute of Shenzhen大学院のインテリジェントコンピューティングリサーチセンターによってリリースされました。評価インジケーターは次のとおりです。精度
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| バート | 89.4(88.4) | 86.9(86.4) | 102m |
| bert-wwm | 89.4(89.2) | 87.0(86.8) | 102m |
| bert-wwm-ext | 89.6(89.2) | 87.1(86.6) | 102m |
| roberta-wwm-ext | 89.0(88.7) | 86.4(86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| Electra-Small | 86.7(86.3) | 85.9(85.6) | 12m |
| Electra-180g-Small | 86.6 | 85.8 | 12m |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180g-Small-Ex | 87.6 | 86.3 | 25m |
| エレクトラベース | 90.2(89.8) | 87.6(87.3) | 102m |
| Electra-180gベース | 90.2 | 87.1 | 102m |
| エレクトラ・ラージ | 90.7 | 87.3 | 324m |
| Electra-180g-Large | 90.3 | 87.3 | 324m |
BQ Corpusは、Harbin Technology Institute of Shenzhen大学院のインテリジェントコンピューティングリサーチセンターによってリリースされ、銀行分野のデータセットです。評価インジケーターは次のとおりです。精度
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| バート | 86.0(85.5) | 84.8(84.6) | 102m |
| bert-wwm | 86.1(85.6) | 85.2(84.9) | 102m |
| bert-wwm-ext | 86.4(85.5) | 85.3(84.8) | 102m |
| roberta-wwm-ext | 86.0(85.4) | 85.0(84.6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| Electra-Small | 83.5(83.0) | 82.0(81.7) | 12m |
| Electra-180g-Small | 83.3 | 82.1 | 12m |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180g-Small-Ex | 84.6 | 83.4 | 25m |
| エレクトラベース | 84.8(84.7) | 84.5(84.0) | 102m |
| Electra-180gベース | 85.8 | 84.5 | 102m |
| エレクトラ・ラージ | 86.7 | 85.1 | 324m |
| Electra-180g-Large | 86.4 | 85.4 | 324m |
Cail 2018 Judicial Reviewの犯罪予測データを使用して、司法エレクトラをテストしました。小/ベース/大部分の学習率は、それぞれ5E-4/3E-4/1E-4です。評価インジケーターは次のとおりです。精度
| モデル | 開発セット | テストセット | パラメーター数 |
|---|---|---|---|
| Electra-Small | 78.84 | 76.35 | 12m |
| Legal-Electra-Small | 79.60 | 77.03 | 12m |
| エレクトラベース | 80.94 | 78.41 | 102m |
| Legal-Electra-Base | 81.71 | 79.17 | 102m |
| エレクトラ・ラージ | 81.53 | 78.97 | 324m |
| Legal-Electra-Large | 82.60 | 79.89 | 324m |
ユーザーは、上記の公開されている中国のエレクトラ事前訓練モデルに基づいて、ダウンストリームタスクを微調整できます。ここでは、最も基本的な使用法のみを紹介します。より詳細な使用については、Electraの公式紹介を参照してください。
この例では、 ELECTRA-smallモデルを使用してCMRC 2018タスクを微調整し、関連する手順は次のとおりです。仮定して、
data-dir :作業ルートディレクトリは、実際の状況に応じて設定できます。model-name :モデル名、この場合はelectra-small 。task-name :タスク名、この場合はcmrc2018 。このディレクトリのコードは、上記の6つの中国のタスクに適合しており、 task-nameはcmrc2018 、 drcd 、 xnli 、 chnsenticorp 、 lcqmc 、およびbqcorpusです。モデルのダウンロードセクションで、Electra-Smallモデルをダウンロードし、 ${data-dir}/models/${model-name}に解凍します。このディレクトリにはelectra_model.* 、 vocab.txt 、 checkpoint 、および合計5つのファイルが含まれている必要があります。
CMRC 2018トレーニングと開発セットをダウンロードして、 train.jsonとdev.jsonに変更します。 2つのファイルを${data-dir}/finetuning_data/${task-name}に配置します。
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.jsonその中で、 data-dirとmodel-name上記で紹介されています。 hparamsはJSON辞書です。この例では、 params_cmrc2018.jsonには、次のような微調整に関連するハイパーパラメーターが含まれています。
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}上記のJSONファイルには、最も重要なパラメーターの一部のみがリストされています。完全なパラメーターリストについては、configure_finenetung.pyを参照してください。
操作が完了した後、
cmrc2018_dev_preds.jsonは${data-dir}/results/${task-name}_qa/に保存されます。外部評価スクリプトを呼び出して最終的な評価結果を取得できます。たとえば、 python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 Q:ダウンストリームタスクを微調整するときに、エレクトラモデルの学習率を設定する方法は?
A:元の論文で使用されている学習率を初期ベースラインとして使用することをお勧めします(Small is 3E-4、Base is 1E-4)。次に、適切な追加と学習率の低下でデバッグすることをお勧めします。 BertやRobertaなどのモデルと比較して、Electraの学習率は比較的大きいことに注意してください。
Q:Pytorchの著作権はありますか?
A:はい、モデルをダウンロードします。
Q:トレーニング前のデータを共有できますか?
A:残念ながら、いいえ。
Q:将来の計画?
A:ご期待ください。
このディレクトリのコンテンツが研究作業に役立つ場合は、論文の次の論文をお気軽に引用してください。
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
イフィーテク共同研究所の公式WeChat公式アカウントをフォローして、最新の技術動向について学びます。

問題を提出する前に:


