Chinese ELECTRA
1.0.0
Descrição chinesa | Inglês

Este projeto é baseado no electra oficial da Universidade Google & Stanford: https://github.com/google-research/electra
Lert chinês | Pert inglesa chinesa | MacBert chinês | Electra chinês | Xlnet chinês | Bert chinês | Ferramenta de destilação do conhecimento Textbrewer | Ferramenta de corte de modelos Princinente de texto
Veja mais recursos divulgados pela IFL do Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Llama chinesa de código aberto e modelo Alpaca, que pode ser rapidamente implantado e experimentado no PC, View: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Propomos um modelo pré-treinado Lert que integra informações linguísticas. View: https://github.com/ymcui/lert
2022/3/30 Nós abrimos um novo modelo pré-treinado pert. View: https://github.com/ymcui/pert
2021/12/17 O Laboratório Conjunto IFLYTEK lança o Model Cutting Toolkit TextPruner. View: https://github.com/airaria/textpruner
2021/10/24 O Laboratório Conjunto Iflytek divulgou um modelo pré-treinado Cino para idiomas minoritários étnicos. View: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "Processamento de linguagem natural: métodos baseados em modelos de pré-treinamento" escritos por muitos estudiosos do Instituto de Tecnologia da Harbin foram publicados, e todos podem comprá-lo.
2020/12/13 Com base em dados de documentos legais em larga escala, treinamos modelos chineses da série Electra para o campo judicial para visualizar downloads de modelos e efeitos de tarefas judiciais.
2020/9/15 Nosso artigo "Revisitando modelos pré-treinados para processamento de linguagem natural chinês" foi contratado como um longo artigo por descobertas da EMNLP.
2020/8/27 O Laboratório Conjunto da IFL liderou a lista na avaliação da Entendendo da Linguagem Natural Geral de cola, verifique a lista de cola, notícias.
2020/5/29 Electra-Large/Small-Ex foi lançado. Por favor, verifique o download do modelo. Atualmente, apenas o endereço de download do Google Drive está disponível, então entenda.
2020/4/7 Os usuários do Pytorch podem carregar o modelo através de transformadores para visualizar o carregamento rápido.
2020/3/31 Os modelos publicados neste diretório foram conectados ao PaddlepaddleHub para visualização e carregamento rapidamente.
2020/3/25 O electra-small/base chinês foi lançado, verifique o download do modelo.
| capítulo | descrever |
|---|---|
| Introdução | Introdução aos princípios básicos de Electra |
| Download do modelo | Baixe o modelo chinês Electra pré-treinado |
| Carregamento rápido | Como usar transformadores e paddlehub carregando rapidamente modelos |
| Efeitos da linha de base do sistema | Efeitos do sistema de linha de base chinesa: compreensão de leitura, classificação de texto, etc. |
| Como usar | Uso detalhado do modelo |
| Perguntas frequentes | Perguntas frequentes e respostas |
| Citar | Relatórios técnicos neste diretório |
Electra propõe uma nova estrutura de pré-treinamento que inclui duas partes: gerador e discriminador .
Após o término da fase de pré-treinamento, usamos apenas o discriminador como modelo básico para tarefas a jusante.
Para um conteúdo mais detalhado, consulte o papel Electra: Electra: os codificadores de texto pré-treinamento como discriminadores em vez de geradores
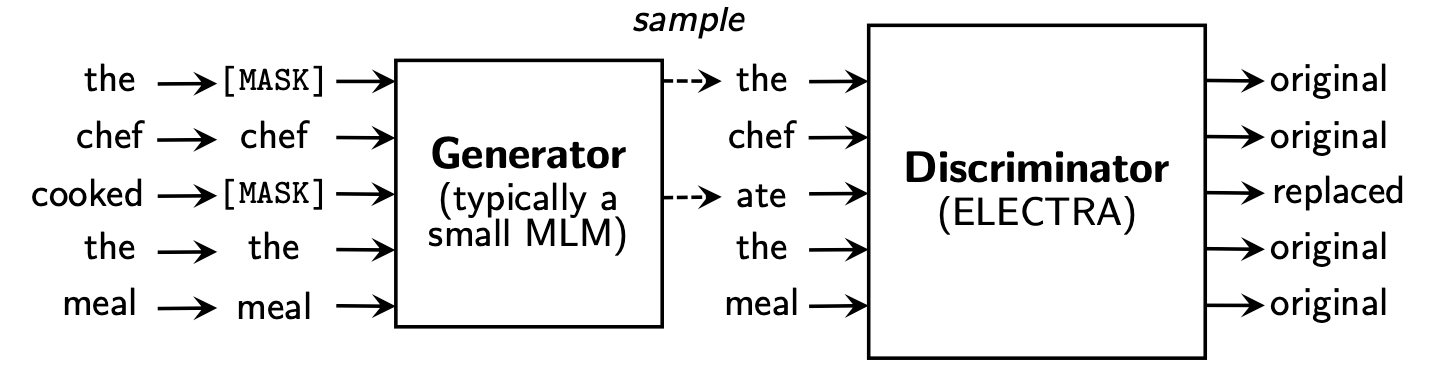
Este diretório contém os seguintes modelos e atualmente fornece apenas pesos da versão TensorFlow.
ELECTRA-large, Chinese : parâmetros de 24 camadas, 1024-ocultos, 16 cabeças, 324mELECTRA-base, Chinese : 12 camadas, 768 ocultas, 12 cabeças, 102m parâmetrosELECTRA-small-ex, Chinese : parâmetros de 24 camadas, 256 ocultos, 4 cabeças, 25mELECTRA-small, Chinese : parâmetros de 12 camadas, 256 ocultos, 4 cabeças, 12m | Abreviação de modelo | Download do Google | Download do Baidu NetDisk | Tamanho do pacote comprimido |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | Tensorflow (senha 2V5R) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | Tensorflow (senha 3VG1) | 383m |
ELECTRA-180g-small-ex, Chinese | Tensorflow | Tensorflow (senha 93N8) | 92m |
ELECTRA-180g-small, Chinese | Tensorflow | Tensorflow (senha k9iu) | 46m |
| Abreviação de modelo | Download do Google | Download do Baidu NetDisk | Tamanho do pacote comprimido |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | Tensorflow (senha 1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | Tensorflow (senha F32J) | 383m |
ELECTRA-small-ex, Chinese | Tensorflow | Tensorflow (senha gfb1) | 92m |
ELECTRA-small, Chinese | Tensorflow | Tensorflow (senha 1R4R) | 46m |
| Abreviação de modelo | Download do Google | Download do Baidu NetDisk | Tamanho do pacote comprimido |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | Tensorflow (senha Q4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | Tensorflow (senha 8GCV) | 383m |
legal-ELECTRA-small, Chinese | Tensorflow | Tensorflow (senha KMRJ) | 46m |
Se você precisar da versão Pytorch, converta -a por conta de conversão convertida_electra_original_tf_checkpoint_to_pytorch.py fornecida pelos Transformers. Se você precisar de arquivos de configuração, poderá inserir a pasta de configuração neste diretório para pesquisar.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorOu faça o download diretamente de Pytorch através do site oficial do HuggingFace: https://huggingface.co/hfl
Método: Clique em qualquer modelo que você deseja baixar → Puxe para a parte inferior e clique em "Liste todos os arquivos no modelo" → Baixar arquivos JSON e JSON na caixa pop-up.
Recomenda -se usar pontos de download do Baidu NetDisk na China continental, embora seja recomendável usar pontos de download do Google em usuários estrangeiros. Tomando a versão Tensorflow do ELECTRA-small, Chinese como exemplo, após o download, descomprimindo o arquivo zip para obter o seguinte arquivo.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Utilizamos wikis chineses em larga escala e texto geral para treinar o modelo Electra, com o número total de token atingindo 5,4b, o que é consistente com o modelo da série Roberta-Wwm-EXT. Em termos de lista de vocabulário, ele usa a lista original de vocabulário de palavras do Google, incluindo 21.128 tokens. Outros detalhes e hiperparâmetros são os seguintes (os parâmetros não mencionados permanecem padrão):
ELECTRA-large : 24 camadas, camada oculta 1024, 16 cabeças de atenção, taxa de aprendizado 1e-4, lote96, comprimento máximo 512, treinamento de 2m de etapasELECTRA-base : 12 camadas, camada oculta 768, 12 cabeças de atenção, taxa de aprendizado 2e-4, loteELECTRA-small-ex : 24 camadas, camada oculta 256, 4 cabeças de atenção, taxa de aprendizado 5E-4, Batch384, comprimento máximo 512, 2M Etapas de treinamentoELECTRA-small : 12 camadas, camada oculta 256, 4 cabeças de atenção, taxa de aprendizado 5E-4, Batch1024, comprimento máximo 512, Treinamento 1m Etapa A HuggingFace-Transformers versão 2.8.0 apoiou oficialmente o modelo Electra e pode ser chamado através dos seguintes comandos.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) A lista correspondente de MODEL_NAME é a seguinte:
| Nome do modelo | Componentes | Model_name |
|---|---|---|
| Electra-180G-Large, chinês | discriminador | HFL/Chinês-Elecre-180G-Large-Discriminador |
| Electra-180G-Large, chinês | Gerador | HFL/Chinês-Elecre-180G-Gerget-Generator |
| Electra-180G-Base, chinês | discriminador | HFL/Chinês-Elecre-180G-BASE Discriminador |
| Electra-180G-Base, chinês | Gerador | HFL/Chinês-Elecre-180G-Base-Generator |
| Electra-180g-small-ex, chinês | discriminador | HFL/Chinês-Electra-180G-Small-Ex-Discriminador |
| Electra-180g-small-ex, chinês | Gerador | HFL/Chinês-Electra-180G-Small-Ex-Generator |
| Electra-180G-Small, chinês | discriminador | HFL/Chinês-Electra-180G-Discriminador |
| Electra-180G-Small, chinês | Gerador | HFL/Chinês-Elecre-180G-Generador |
| Electra-grande, chinês | discriminador | HFL/Chinês-Electra-Large-Discriminador |
| Electra-grande, chinês | Gerador | HFL/Chinês-Electra-Large-Generator |
| Electra-Base, chinês | discriminador | HFL/Chinês-Eletra-Base-Discriminador |
| Electra-Base, chinês | Gerador | HFL/Chinês-Elecre-Base-Generator |
| Electra-small-ex, chinês | discriminador | HFL/Chinês-Electra-Small-Ex-Discriminador |
| Electra-small-ex, chinês | Gerador | HFL/Chinês-Electra-Small-Ex-Generator |
| Electra-pequeno, chinês | discriminador | HFL/Chinês-Electra-Discriminador |
| Electra-pequeno, chinês | Gerador | HFL/Chinês-Electra-Generator |
Versão de domínio judicial:
| Nome do modelo | Componentes | Model_name |
|---|---|---|
| Legal-Electra-Large, chinês | discriminador | HFL/Chinês-Electra-Large-Discriminador |
| Legal-Electra-Large, chinês | Gerador | HFL/chinês-generador-general-eletrica-largada |
| Electra-Base Legal, chinês | discriminador | HFL/Chinês-Elecretra-Base-Discriminador |
| Electra-Base Legal, chinês | Gerador | HFL/Chinês-Electra-Base-Generator |
| Elecretra-de-elecira, chinês | discriminador | HFL/Chinês-Electra-Muml-Discriminador |
| Elecretra-de-elecira, chinês | Gerador | HFL/Chinês-Elecret-Generator |
Contando no PaddleHub, precisamos apenas de uma linha de código para concluir o download e a instalação do modelo, e mais de dez linhas de código podem concluir as tarefas de classificação de texto, anotação de sequência, compreensão de leitura e outras tarefas.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
A lista correspondente de MODULE_NAME é a seguinte:
| Nome do modelo | Module_name |
|---|---|
| Electra-Base, chinês | Base chinesa-eletrica |
| Electra-pequeno, chinês | Chinês-Electra-Small |
Comparamos os efeitos do ELECTRA-small/base com BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext e RBT3 , incluindo as seis tarefas a seguir:
Para o modelo Electra-Small/Base, usamos as taxas de aprendizado padrão de 3e-4 e 1e-4 no artigo original. Deve -se notar que não executamos ajustes de parâmetros para nenhuma tarefa; portanto, mais melhorias de desempenho podem ser alcançadas ajustando os hiperparâmetros, como a taxa de aprendizado. Para garantir a confiabilidade dos resultados, para o mesmo modelo, treinamos 10 vezes usando sementes aleatórias diferentes para relatar os valores máximos e médios do desempenho do modelo (os valores médios entre colchetes).
O conjunto de dados do CMRC 2018 são os dados de compreensão de leitura de máquina chinesa divulgados pelo Laboratório Conjunto do Instituto de Tecnologia Harbin. De acordo com uma determinada pergunta, o sistema precisa extrair fragmentos do capítulo como a resposta, da mesma forma que o esquadrão. Os indicadores de avaliação são: em / f1
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Conjunto de desafios | Quantidade de parâmetro |
|---|---|---|---|---|
| Bert-base | 65,5 (64,4) / 84.5 (84,0) | 70.0 (68.7) / 87.0 (86,3) | 18.6 (17.0) / 43.3 (41,3) | 102m |
| Bert-wwm | 66,3 (65,0) / 85.6 (84,7) | 70,5 (69.1) / 87,4 (86,7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| Bert-wwm-ext | 67.1 (65.6) / 85.7 (85,0) | 71.4 (70.0) / 87,7 (87,0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| Roberta-wwm-ext | 67.4 (66,5) / 87.2 (86,5) | 72.6 (71.4) / 89.4 (88,8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Electra-small | 63.4 (62,9) / 80,8 (80,2) | 67,8 (67.4) / 83.4 (83,0) | 16.3 (15.4) / 37.2 (35,8) | 12m |
| Electra-180g-small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-small-ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180g-small-ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| Electra-Base | 68.4 (68.0) / 84.8 (84,6) | 73.1 (72.7) / 87.1 (86,9) | 22.6 (21.7) / 45.0 (43,8) | 102m |
| Electra-180g-Base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| Electra-grande | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180G-Large | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
O conjunto de dados DRCD foi lançado pelo Delta Research Institute, Taiwan, China. Sua forma é a mesma do esquadrão e é um conjunto de dados de compreensão de leitura extraído baseado no chinês tradicional. Os indicadores de avaliação são: em / f1
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Bert-base | 83.1 (82.7) / 89,9 (89,6) | 82.2 (81,6) / 89.2 (88,8) | 102m |
| Bert-wwm | 84,3 (83,4) / 90,5 (90,2) | 82,8 (81,8) / 89,7 (89,0) | 102m |
| Bert-wwm-ext | 85,0 (84,5) / 91.2 (90,9) | 83.6 (83,0) / 90,4 (89,9) | 102m |
| Roberta-wwm-ext | 86,6 (85,9) / 92,5 (92.2) | 85,6 (85.2) / 92.0 (91,7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| Electra-small | 79,8 (79.4) / 86,7 (86,4) | 79,0 (78,5) / 85,8 (85,6) | 12m |
| Electra-180g-small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-small-ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180g-small-ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| Electra-Base | 87,5 (87,0) / 92,5 (92,3) | 86,9 (86,6) / 91,8 (91,7) | 102m |
| Electra-180g-Base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| Electra-grande | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180G-Large | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
Na tarefa de inferência de linguagem natural, adotamos dados XNLI , que exigem que o texto seja dividido em três categorias: entailment , neutral e contradictory . O indicador de avaliação é: precisão
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Bert-base | 77,8 (77.4) | 77,8 (77,5) | 102m |
| Bert-wwm | 79,0 (78.4) | 78.2 (78.0) | 102m |
| Bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) | 102m |
| Roberta-wwm-ext | 80.0 (79.2) | 78,8 (78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| Electra-small | 73.3 (72,5) | 73.1 (72.6) | 12m |
| Electra-180g-small | 74.6 | 74.6 | 12m |
| Electra-small-ex | 75.4 | 75.8 | 25m |
| Electra-180g-small-ex | 76.5 | 76.6 | 25m |
| Electra-Base | 77.9 (77.0) | 78.4 (77,8) | 102m |
| Electra-180g-Base | 79.6 | 79.5 | 102m |
| Electra-grande | 81.5 | 81.0 | 324m |
| Electra-180G-Large | 81.2 | 80.4 | 324m |
Na tarefa de análise de sentimentos, o conjunto de dados de classificação de emoção binária ChnsEnticorp . O indicador de avaliação é: precisão
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Bert-base | 94,7 (94,3) | 95,0 (94,7) | 102m |
| Bert-wwm | 95.1 (94,5) | 95.4 (95.0) | 102m |
| Bert-wwm-ext | 95.4 (94.6) | 95.3 (94.7) | 102m |
| Roberta-wwm-ext | 95.0 (94,6) | 95.6 (94,8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| Electra-small | 92.8 (92,5) | 94.3 (93,5) | 12m |
| Electra-180g-small | 94.1 | 93.6 | 12m |
| Electra-small-ex | 92.6 | 93.6 | 25m |
| Electra-180g-small-ex | 92.8 | 93.4 | 25m |
| Electra-Base | 93.8 (93.0) | 94,5 (93,5) | 102m |
| Electra-180g-Base | 94.3 | 94.8 | 102m |
| Electra-grande | 95.2 | 95.3 | 324m |
| Electra-180G-Large | 94.8 | 95.2 | 324m |
Os dois conjuntos de dados a seguir precisam classificar um par de frases para determinar se a semântica das duas frases são as mesmas (tarefa de classificação binária).
O LCQMC foi lançado pelo Centro de Pesquisa de Computação Inteligente do Instituto de Tecnologia de Harbin, Shenzhen Graduate School. O indicador de avaliação é: precisão
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Bert | 89,4 (88,4) | 86,9 (86,4) | 102m |
| Bert-wwm | 89.4 (89,2) | 87.0 (86,8) | 102m |
| Bert-wwm-ext | 89,6 (89,2) | 87.1 (86,6) | 102m |
| Roberta-wwm-ext | 89,0 (88,7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| Electra-small | 86,7 (86,3) | 85,9 (85,6) | 12m |
| Electra-180g-small | 86.6 | 85.8 | 12m |
| Electra-small-ex | 87.5 | 86.0 | 25m |
| Electra-180g-small-ex | 87.6 | 86.3 | 25m |
| Electra-Base | 90.2 (89,8) | 87,6 (87,3) | 102m |
| Electra-180g-Base | 90.2 | 87.1 | 102m |
| Electra-grande | 90.7 | 87.3 | 324m |
| Electra-180G-Large | 90.3 | 87.3 | 324m |
O BQ Corpus é divulgado pelo Centro de Pesquisa de Computação Inteligente do Instituto de Tecnologia Harbin Shenzhen Graduate School e é um conjunto de dados para o campo bancário. O indicador de avaliação é: precisão
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Bert | 86.0 (85,5) | 84,8 (84,6) | 102m |
| Bert-wwm | 86.1 (85.6) | 85,2 (84,9) | 102m |
| Bert-wwm-ext | 86,4 (85,5) | 85,3 (84,8) | 102m |
| Roberta-wwm-ext | 86.0 (85,4) | 85,0 (84,6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| Electra-small | 83,5 (83.0) | 82.0 (81,7) | 12m |
| Electra-180g-small | 83.3 | 82.1 | 12m |
| Electra-small-ex | 84.0 | 82.6 | 25m |
| Electra-180g-small-ex | 84.6 | 83.4 | 25m |
| Electra-Base | 84,8 (84,7) | 84,5 (84,0) | 102m |
| Electra-180g-Base | 85.8 | 84.5 | 102m |
| Electra-grande | 86.7 | 85.1 | 324m |
| Electra-180G-Large | 86.4 | 85.4 | 324m |
Testamos o Electra Judicial usando os dados de previsão de crimes da CAIL 2018 Review Crime. As taxas de aprendizado de pequenas/base/grandes são: 5E-4/3E-4/1E-4, respectivamente. O indicador de avaliação é: precisão
| Modelo | Conjunto de desenvolvimento | Conjunto de testes | Quantidade de parâmetro |
|---|---|---|---|
| Electra-small | 78.84 | 76.35 | 12m |
| Elecretra legal-small | 79.60 | 77.03 | 12m |
| Electra-Base | 80,94 | 78.41 | 102m |
| Electra-Base Legal | 81.71 | 79.17 | 102m |
| Electra-grande | 81.53 | 78.97 | 324m |
| Legal-Electra-Large | 82.60 | 79.89 | 324m |
Os usuários podem executar tarefas a jusante de ajuste fino com base no modelo de pré-treinado electra-treinado chinês publicado acima. Aqui, apenas apresentaremos o uso mais básico. Para um uso mais detalhado, consulte a introdução oficial da Electra.
Neste exemplo, usamos ELECTRA-small para ajustar a tarefa CMRC 2018, e as etapas relevantes são as seguintes. Assumindo,
data-dir : O diretório raiz de trabalho pode ser definido de acordo com a situação real.model-name : nome do modelo, neste caso electra-small .task-name : nome da tarefa, neste caso cmrc2018 . O código deste diretório se adaptou às seis tarefas chinesas acima, e task-name são cmrc2018 , drcd , xnli , chnsenticorp , lcqmc e bqcorpus . Na seção de download do modelo, faça o download do modelo Electra-Small e descompacte-o para ${data-dir}/models/${model-name} . Este diretório deve conter electra_model.* , vocab.txt , checkpoint e um total de 5 arquivos.
Faça o download do conjunto de treinamento e desenvolvimento do CMRC 2018 e renomeie -o para train.json e dev.json . Coloque dois arquivos em ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Entre eles, data-dir e model-name foram introduzidos acima. hparams é um dicionário JSON. Neste exemplo, params_cmrc2018.json contém hiperparâmetros relacionados ao ajuste fino, como:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}No arquivo JSON acima, listamos apenas alguns dos parâmetros mais importantes. Para a lista completa de parâmetros, consulte Configure_fineNenetung.py.
Após a conclusão da operação,
cmrc2018_dev_preds.json são salvos em ${data-dir}/results/${task-name}_qa/ . Você pode chamar scripts de avaliação externa para obter os resultados da avaliação final, por exemplo: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 P: Como definir a taxa de aprendizado do modelo Electra ao ajustar as tarefas a jusante?
R: Recomendamos o uso da taxa de aprendizado usada pelo artigo original como linha de base inicial (Small Is 3e-4, base é 1e-4) e, em seguida, depuração com adição e diminuição apropriadas da taxa de aprendizado. Deve -se notar que, em comparação com modelos como Bert e Roberta, a taxa de aprendizado do Electra é relativamente grande.
P: Existem direitos autorais Pytorch?
A: Sim, faça o download do modelo.
P: Os dados de pré-treinamento podem ser compartilhados?
A: Infelizmente, não.
P: Planos futuros?
A: Por favor, fique atento.
Se o conteúdo deste diretório for útil para o seu trabalho de pesquisa, sinta -se à vontade para citar o seguinte artigo no artigo.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Bem -vindo a seguir o relato oficial oficial do WeChat do Laboratório Conjunto de Iflytek para aprender sobre as mais recentes tendências técnicas.

Antes de enviar um problema:


