Chinese ELECTRA
1.0.0
Descripción china | Inglés

Este proyecto se basa en el Electra oficial de la Universidad de Google y Stanford: https://github.com/google-research/electra
Lert chino | Inglés chino Pert | Macbert chino | Electra chino | Chino xlnet | Bert chino | Herramienta de destilación de conocimiento TextBrewer | Herramienta de corte de modelos Pruner de texto
Ver más recursos publicados por IFL del Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source chino Llama y Alpaca Big Model, que se puede implementar y experimentar rápidamente en PC, Ver: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Proponemos un modelo de modelo previamente capacitado que integra información lingüística. Ver: https://github.com/ymcui/lert
2022/3/30 Open Source Un nuevo modelo previamente capacitado PERT. Ver: https://github.com/ymcui/pert
2021/12/17 Iflytek Conjunto Laboratorio de comunicación lanza el modelo de herramienta de corte Textpruner. Ver: https://github.com/airaria/textpruner
2021/10/24 Laboratorio Conjunto de Iflytek liberó un modelo Cino previamente capacitado para idiomas minoritarios étnicos. Ver: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "Procesamiento del lenguaje natural: métodos basados en modelos de pre-entrenamiento" escritos por muchos académicos del Harbin Institute of Technology Scir, y todos pueden comprarlo.
2020/12/13 Basado en datos de documentos legales a gran escala, capacitamos a modelos chinos de la serie Electra para el campo judicial para ver las descargas de modelos y los efectos de tareas judiciales.
2020/9/15 Nuestro documento "Revisando modelos previamente capacitados para el procesamiento del lenguaje natural chino" fue contratado como un artículo largo por hallazgos de EMNLP.
2020/8/27 El laboratorio conjunto IFL encabezó la lista en la evaluación de comprensión del lenguaje natural del pegamento general, consulte la lista de pegamento, noticias.
2020/5/29 se ha lanzado el electra-Large/Small-EX chino. Consulte la descarga del modelo. Actualmente, solo la dirección de descarga de Google Drive está disponible, así que comprenda.
2020/4/7 Los usuarios de Pytorch pueden cargar el modelo a través de los transformadores para ver la carga rápida.
2020/3/31 Los modelos publicados en este directorio se han conectado a Paddlepaddlehub para ver y cargar rápidamente.
Se ha lanzado 2020/3/25 Electra-Small/Base chino, consulte la descarga del modelo.
| capítulo | describir |
|---|---|
| Introducción | Introducción a los principios básicos de Electra |
| Descargar modelo | Descargar el modelo de capacitación de electra chino |
| Carga rápida | Cómo usar transformadores y modelos de carga rápidamente de Paddlehub |
| Efectos del sistema de referencia | Efectos del sistema de referencia chino: comprensión de lectura, clasificación de texto, etc. |
| Cómo usar | Uso detallado del modelo |
| Preguntas frecuentes | Preguntas frecuentes y respuestas |
| Cita | Informes técnicos en este directorio |
Electra propone un nuevo marco de pre-entrenamiento que incluye dos partes: generador y discriminador .
Después de que termina la fase previa al entrenamiento, solo usamos discriminador como modelo base para tareas aguas abajo ajustadas.
Para obtener contenido más detallado, consulte el documento de electra: Electra: codificadores de texto previos a la capacitación como discriminadores en lugar de generadores
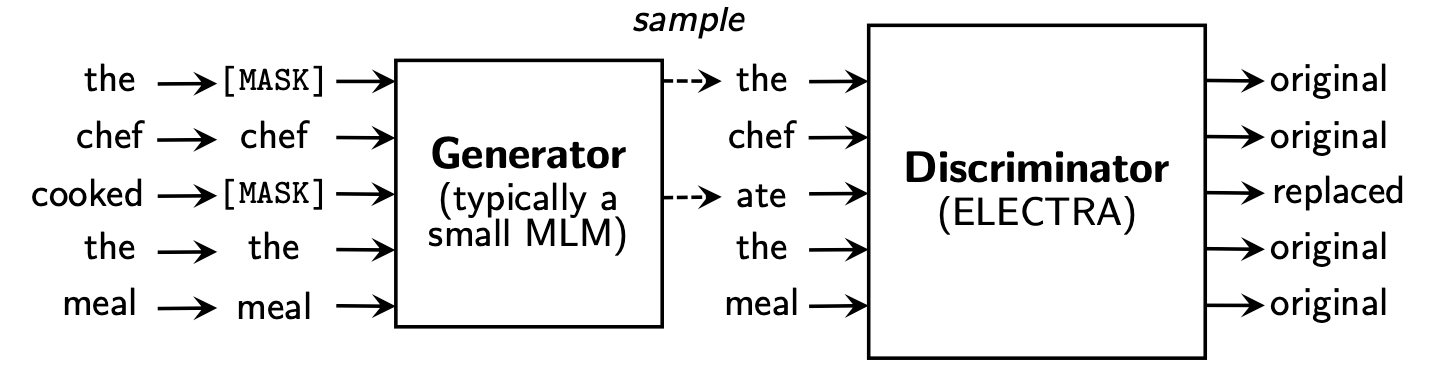
Este directorio contiene los siguientes modelos y actualmente solo proporciona pesos de versión TensorFlow.
ELECTRA-large, Chinese : 24 capas, 1024 escondidas, 16 cabezas, 324m parámetrosELECTRA-base, Chinese : 12 capas, 768 escondidas, 12 cabezas, 102 m parámetrosELECTRA-small-ex, Chinese : 24 capas, 256 escondidos, 4 cabezas, 25 m parámetrosELECTRA-small, Chinese : 12 capas, 256 escondidas, 4 cabezas, 12 m parámetros | Abreviatura del modelo | Descarga de Google | Descargar Baidu NetDisk | Tamaño del paquete comprimido |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Flujo tensor | TensorFlow (contraseña 2v5r) | 1G |
ELECTRA-180g-base, Chinese | Flujo tensor | TensorFlow (contraseña 3vg1) | 383m |
ELECTRA-180g-small-ex, Chinese | Flujo tensor | TensorFlow (contraseña 93n8) | 92m |
ELECTRA-180g-small, Chinese | Flujo tensor | TensorFlow (contraseña K9iu) | 46m |
| Abreviatura del modelo | Descarga de Google | Descargar Baidu NetDisk | Tamaño del paquete comprimido |
|---|---|---|---|
ELECTRA-large, Chinese | Flujo tensor | TensorFlow (contraseña 1e14) | 1G |
ELECTRA-base, Chinese | Flujo tensor | TensorFlow (contraseña F32J) | 383m |
ELECTRA-small-ex, Chinese | Flujo tensor | TensorFlow (contraseña GFB1) | 92m |
ELECTRA-small, Chinese | Flujo tensor | TensorFlow (contraseña 1R4R) | 46m |
| Abreviatura del modelo | Descarga de Google | Descargar Baidu NetDisk | Tamaño del paquete comprimido |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Flujo tensor | TensorFlow (contraseña Q4GV) | 1G |
legal-ELECTRA-base, Chinese | Flujo tensor | TensorFlow (contraseña 8GCV) | 383m |
legal-ELECTRA-small, Chinese | Flujo tensor | TensorFlow (Password KMRJ) | 46m |
Si necesita la versión de Pytorch, conviértela usted mismo a través del script de conversión convertido_electra_original_tf_checkpoint_to_pytorch.py proporcionado por Transformers. Si necesita archivos de configuración, puede ingresar la carpeta de configuración en este directorio para buscar.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorO descargue directamente Pytorch a través del sitio web oficial de Huggingface: https://huggingface.co/hfl
Método: haga clic en cualquier modelo que desee descargar → Tire de la parte inferior y haga clic en "Lista todos los archivos en el modelo" → Descargar archivos bin y json en el cuadro emergente.
Se recomienda utilizar puntos de descarga Baidu NetDisk en China continental, mientras que se recomienda usar puntos de descarga de Google en usuarios en el extranjero. Tomar la versión TensorFlow de ELECTRA-small, Chinese como ejemplo, después de descargar, descomprimiendo el archivo zip para obtener el siguiente archivo.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Utilizamos wikis chinos a gran escala y texto general para entrenar el modelo Electra, con el número de token total que alcanza 5.4b, lo que es consistente con el modelo de la Serie Roberta-WWM-EXT. En términos de la lista de vocabulario, utiliza la lista original de vocabulario de Wordsel de Word de Google, incluidas 21,128 tokens. Otros detalles e hiperparámetros son los siguientes (los parámetros no mencionados siguen siendo predeterminados):
ELECTRA-large : 24 capas, capa oculta 1024, 16 cabezas de atención, velocidad de aprendizaje 1e-4, lote96, longitud máxima 512, entrenamiento de 2 m pasosELECTRA-base : 12 capas, capa oculta 768, 12 cabezas de atención, velocidad de aprendizaje 2e-4, lote256, longitud máxima 512, entrenamiento 1 m pasoELECTRA-small-ex : 24 capas, capa oculta 256, 4 cabezas de atención, velocidad de aprendizaje 5E-4, lote384, longitud máxima 512, 2 m pasos de entrenamientoELECTRA-small : 12 capas, capa oculta 256, 4 cabezas de atención, velocidad de aprendizaje 5e-4, lotes1024, longitud máxima 512, entrenamiento 1 m paso Huggingface-Transformers versión 2.8.0 ha admitido oficialmente el modelo Electra y puede llamarse a través de los siguientes comandos.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) La lista correspondiente de MODEL_NAME es la siguiente:
| Nombre del modelo | Componentes | Model_name |
|---|---|---|
| Electra-180G-Large, chino | discriminado | HFL/chino-electra-180G-carge-discriminador |
| Electra-180G-Large, chino | Generador | HFL/chino-electra-180G-Generador-Large |
| Electra-180g-base, chino | discriminado | HFL/chino-electra-180G-Base-Discriminador |
| Electra-180g-base, chino | Generador | HFL/chino-electra-180G-generador-base |
| Electra-180G-Small-EX, chino | discriminado | HFL/chino-electra-180G-Small-Ex-Discriminator |
| Electra-180G-Small-EX, chino | Generador | HFL/chino-electra-180G-Small-Exgenerator |
| Electra-180G-Small, chino | discriminado | HFL/chino-electra-180G-Small-Discriminador |
| Electra-180G-Small, chino | Generador | HFL/Chino-Electra-180G-Small-Generator |
| Electra-Large, chino | discriminado | HFL/Discriminador de Electra-Electra-Discriminador |
| Electra-Large, chino | Generador | HFL/Generador de Electra-Large |
| Electra-base, chino | discriminado | HFL/chino-electra-base-discriminador |
| Electra-base, chino | Generador | HFL/Generador de base de electro chino |
| Electra-Small-EX, chino | discriminado | HFL/Chino-Electra-Small-Ex-Discriminator |
| Electra-Small-EX, chino | Generador | HFL/Chino-Electra-Small-Ex Generator |
| Electra-Small, chino | discriminado | HFL/chino-electra-pequeña-discriminador |
| Electra-Small, chino | Generador | HFL/Generador chino-electra-pequeño |
Versión de dominio judicial:
| Nombre del modelo | Componentes | Model_name |
|---|---|---|
| Legal-electra-grande, chino | discriminado | hfl/chino-legal-electra-cargue-discriminador |
| Legal-electra-grande, chino | Generador | HFL/Generador-Electra-Large-Generator chino-legal |
| Legal-electra-base, chino | discriminado | HFL/chino-legal-electra-base-discriminador |
| Legal-electra-base, chino | Generador | HFL/Generador-Base-Base-Base Chino-Legal |
| Electra legal-electro, chino | discriminado | HFL/Discriminador chino-legal-electra-llamativo |
| Electra legal-electro, chino | Generador | HFL/Generador chino-legal-electra-llamativo |
Confiando en PaddleHub, solo necesitamos una línea de código para completar la descarga e instalación del modelo, y más de diez líneas de código pueden completar las tareas de clasificación de texto, anotación de secuencia, comprensión lectora y otras tareas.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
La lista correspondiente de MODULE_NAME es la siguiente:
| Nombre del modelo | Módulo_name |
|---|---|
| Electra-base, chino | base de electro chino |
| Electra-Small, chino | Electra-Semall |
Comparamos los efectos de ELECTRA-small/base con BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext y RBT3 , incluidas las siguientes seis tareas:
Para el modelo electra-pequeña/base, utilizamos las tasas de aprendizaje predeterminadas de 3e-4 y 1e-4 en el documento original. Cabe señalar que no hemos realizado ajustes de parámetros para ninguna tarea, por lo que se pueden lograr mejoras de rendimiento adicionales ajustando hiperparámetros como la tasa de aprendizaje. Para garantizar la confiabilidad de los resultados, para el mismo modelo, entrenamos 10 veces utilizando diferentes semillas aleatorias para informar los valores máximos y promedio de rendimiento del modelo (los valores promedio en los soportes).
El conjunto de datos CMRC 2018 son los datos chinos de comprensión de lectura a máquina publicadas por el Laboratorio Conjunto del Instituto de Tecnología de Harbin. Según una pregunta dada, el sistema necesita extraer fragmentos del capítulo como la respuesta, en la misma forma que el escuadrón. Los indicadores de evaluación son: EM / F1
| Modelo | Conjunto de desarrollo | Set de prueba | Conjunto de desafío | Cantidad de parámetros |
|---|---|---|---|---|
| Base | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| Bert-wwm | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| Bert-wwm-ext | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| Roberta-wwm-ext | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Electro-pequeña | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12m |
| Electra-180G-Small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180G-Small-EX | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| Electra-base | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102m |
| Electra-180g-base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| Electra-grande | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180g-larga | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
El conjunto de datos DRCD fue publicado por Delta Research Institute, Taiwán, China. Su forma es la misma que el escuadrón y es un conjunto de datos de comprensión de lectura extraída basado en el chino tradicional. Los indicadores de evaluación son: EM / F1
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Base | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102m |
| Bert-wwm | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| Bert-wwm-ext | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102m |
| Roberta-wwm-ext | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| Electro-pequeña | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12m |
| Electra-180G-Small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180G-Small-EX | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| Electra-base | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102m |
| Electra-180g-base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| Electra-grande | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180g-larga | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
En la tarea de inferencia del lenguaje natural, adoptamos datos XNLI , que requieren que el texto se divide en tres categorías: entailment , neutral y contradictory . El indicador de evaluación es: precisión
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Base | 77.8 (77.4) | 77.8 (77.5) | 102m |
| Bert-wwm | 79.0 (78.4) | 78.2 (78.0) | 102m |
| Bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) | 102m |
| Roberta-wwm-ext | 80.0 (79.2) | 78.8 (78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| Electro-pequeña | 73.3 (72.5) | 73.1 (72.6) | 12m |
| Electra-180G-Small | 74.6 | 74.6 | 12m |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180G-Small-EX | 76.5 | 76.6 | 25m |
| Electra-base | 77.9 (77.0) | 78.4 (77.8) | 102m |
| Electra-180g-base | 79.6 | 79.5 | 102m |
| Electra-grande | 81.5 | 81.0 | 324m |
| Electra-180g-larga | 81.2 | 80.4 | 324m |
En la tarea de análisis de sentimientos, el conjunto de datos de clasificación de emoción binaria Chnsenticorp . El indicador de evaluación es: precisión
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Base | 94.7 (94.3) | 95.0 (94.7) | 102m |
| Bert-wwm | 95.1 (94.5) | 95.4 (95.0) | 102m |
| Bert-wwm-ext | 95.4 (94.6) | 95.3 (94.7) | 102m |
| Roberta-wwm-ext | 95.0 (94.6) | 95.6 (94.8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| Electro-pequeña | 92.8 (92.5) | 94.3 (93.5) | 12m |
| Electra-180G-Small | 94.1 | 93.6 | 12m |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180G-Small-EX | 92.8 | 93.4 | 25m |
| Electra-base | 93.8 (93.0) | 94.5 (93.5) | 102m |
| Electra-180g-base | 94.3 | 94.8 | 102m |
| Electra-grande | 95.2 | 95.3 | 324m |
| Electra-180g-larga | 94.8 | 95.2 | 324m |
Los siguientes dos conjuntos de datos deben clasificar un par de oraciones para determinar si la semántica de las dos oraciones es la misma (tarea de clasificación binaria).
LCQMC fue publicado por el Centro de Investigación de Computación Inteligente del Instituto Harbin de Tecnología Shenzhen Graduate School. El indicador de evaluación es: precisión
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) | 102m |
| Bert-wwm | 89.4 (89.2) | 87.0 (86.8) | 102m |
| Bert-wwm-ext | 89.6 (89.2) | 87.1 (86.6) | 102m |
| Roberta-wwm-ext | 89.0 (88.7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| Electro-pequeña | 86.7 (86.3) | 85.9 (85.6) | 12m |
| Electra-180G-Small | 86.6 | 85.8 | 12m |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180G-Small-EX | 87.6 | 86.3 | 25m |
| Electra-base | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180g-base | 90.2 | 87.1 | 102m |
| Electra-grande | 90.7 | 87.3 | 324m |
| Electra-180g-larga | 90.3 | 87.3 | 324m |
BQ Corpus es publicado por el Centro de Investigación de Computación Inteligente del Instituto Harbin de Tecnología Shenzhen Graduate School y es un conjunto de datos para el campo bancario. El indicador de evaluación es: precisión
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Bert | 86.0 (85.5) | 84.8 (84.6) | 102m |
| Bert-wwm | 86.1 (85.6) | 85.2 (84.9) | 102m |
| Bert-wwm-ext | 86.4 (85.5) | 85.3 (84.8) | 102m |
| Roberta-wwm-ext | 86.0 (85.4) | 85.0 (84.6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| Electro-pequeña | 83.5 (83.0) | 82.0 (81.7) | 12m |
| Electra-180G-Small | 83.3 | 82.1 | 12m |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180G-Small-EX | 84.6 | 83.4 | 25m |
| Electra-base | 84.8 (84.7) | 84.5 (84.0) | 102m |
| Electra-180g-base | 85.8 | 84.5 | 102m |
| Electra-grande | 86.7 | 85.1 | 324m |
| Electra-180g-larga | 86.4 | 85.4 | 324m |
Probamos el Electra judicial utilizando los datos de predicción del crimen de Cail 2018 Judicial Review. Las tasas de aprendizaje de pequeñas/base/grandes son: 5E-4/3E-4/1E-4 respectivamente. El indicador de evaluación es: precisión
| Modelo | Conjunto de desarrollo | Set de prueba | Cantidad de parámetros |
|---|---|---|---|
| Electro-pequeña | 78.84 | 76.35 | 12m |
| Electra legal | 79.60 | 77.03 | 12m |
| Electra-base | 80.94 | 78.41 | 102m |
| base de electra legal | 81.71 | 79.17 | 102m |
| Electra-grande | 81.53 | 78.97 | 324m |
| Legal-Electra-Large | 82.60 | 79.89 | 324m |
Los usuarios pueden realizar tareas aguas abajo ajustados en función del modelo previamente capacitado de Electra chino publicado anterior. Aquí solo presentaremos el uso más básico. Para un uso más detallado, consulte la introducción oficial de Electra.
En este ejemplo, utilizamos ELECTRA-small para ajustar la tarea CMRC 2018, y los pasos relevantes son los siguientes. Arrogante,
data-dir : el directorio raíz de trabajo se puede establecer de acuerdo con la situación real.model-name : nombre del modelo, en este caso electra-small .task-name : Nombre de la tarea, en este caso cmrc2018 . El código en este directorio se ha adaptado a las seis tareas chinas anteriores, y task-name son cmrc2018 , drcd , xnli , chnsenticorp , lcqmc y bqcorpus . En la sección de descarga del modelo, descargue el modelo Electra-Small y descomprima a ${data-dir}/models/${model-name} . Este directorio debe contener electra_model.* , vocab.txt , checkpoint y un total de 5 archivos.
Descargue el conjunto de capacitación y desarrollo de CMRC 2018 y cambie el nombre a train.json y dev.json . Coloque dos archivos en ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Entre ellos, data-dir y model-name se han introducido anteriormente. hparams es un diccionario JSON. En este ejemplo, params_cmrc2018.json contiene hiperparámetros relacionados con el ajuste fino, como:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}En el archivo JSON anterior, solo enumeramos algunos de los parámetros más importantes. Para obtener la lista completa de parámetros, consulte Conformure_finenetung.py.
Después de completar la operación,
cmrc2018_dev_preds.json se guarda en ${data-dir}/results/${task-name}_qa/ . Puede llamar a los scripts de evaluación externos para obtener los resultados de la evaluación final, por ejemplo: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 P: ¿Cómo establecer la tasa de aprendizaje del modelo Electra al ajustar las tareas aguas abajo?
R: Recomendamos usar la tasa de aprendizaje utilizada por el documento original como la línea de base inicial (pequeña es 3E-4, la base es 1e-4) y luego depuración con la adición y disminución adecuadas de la tasa de aprendizaje. Cabe señalar que en comparación con modelos como Bert y Roberta, la tasa de aprendizaje de Electra es relativamente grande.
P: ¿Hay algún copyright de Pytorch?
R: Sí, descargue el modelo.
P: ¿Se pueden compartir los datos de pre-entrenamiento?
A: Desafortunadamente, no.
P: ¿Planes futuros?
A: Por favor, estad atentos.
Si el contenido en este directorio es útil para su trabajo de investigación, no dude en citar el siguiente documento en el documento.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Bienvenido a seguir la cuenta oficial oficial de WeChat del Laboratorio Conjunto de Iflytek para conocer las últimas tendencias técnicas.

Antes de enviar un problema:


