Chinese ELECTRA
1.0.0
중국어 설명 | 영어

이 프로젝트는 Google & Stanford University의 공식 Electra를 기반으로합니다 : https://github.com/google-research/electra
중국어 | 중국 영어 pert | 중국 맥버트 | 중국 전자 | 중국어 xlnet | 중국 버트 | 지식 증류 도구 텍스트 브루어 | 모델 절단 도구 TextPruner
HARBIN Institute of Technology (HFL)의 IFL이 발표 한 자료를 더 많이보기 : https://github.com/ymcui/hfl-anthology
2023/3/28 오픈 소스 중국 라마 & 알파카 빅 모델.
2022/10/29 우리는 언어 정보를 통합하는 미리 훈련 된 모델 lert를 제안합니다. 보기 : https://github.com/ymcui/lert
2022/3/30 우리는 새로운 미리 훈련 된 모델 pert를 오픈 소스. 보기 : https://github.com/ymcui/pert
2021/12/17 Iflytek Joint Laboratory를 시작하여 모델 절단 툴킷 TextPruner를 시작합니다. 보기 : https://github.com/airaria/textpruner
2021/10/24 Iflytek Joint Laboratory는 소수 민족 언어를위한 미리 훈련 된 모델 Cino를 발표했습니다. 보기 : https://github.com/ymcui/chinese-minority-plm
2021/7/21 "자연 언어 처리 : Harbin Institute of Technology SCIR의 많은 학자들이 작성한 사전 훈련 모델을 기반으로하는 방법"이 출판되었으며 모든 사람들이 구매를 환영합니다.
2020/12/13 대규모 법적 문서 데이터를 기반으로, 우리는 사법 분야가 모델 다운로드를 볼 수 있도록 중국 전자 시리즈 모델을 훈련 시켰습니다.
2020/9/15 우리 논문 "중국 자연 언어 처리를위한 미리 훈련 된 모델 재검토"는 EMNLP의 발견에 의해 긴 기사로 고용되었습니다.
2020/8/27 IFL 공동 실험실은 접착제 일반 자연어 이해 평가에서 목록을 1 위, 접착제 목록, 뉴스를 확인하십시오.
2020/5/29 중국 전자-래지/스몰 엑스가 출시되었습니다. 모델 다운로드를 확인하십시오. 현재 Google 드라이브 다운로드 주소 만 사용할 수 있으므로 이해하십시오.
2020/4/7 Pytorch 사용자는 변압기를 통해 모델을로드하여 빠른 로딩을 볼 수 있습니다.
2020/3/31이 디렉토리에 게시 된 모델은 빠르게보고로드하기 위해 PaddlePaddleHub에 연결되었습니다.
2020/3/25 중국 Electra-Small/Base가 출시되었습니다. 모델 다운로드를 확인하십시오.
| 장 | 설명하다 |
|---|---|
| 소개 | Electra의 기본 원리 소개 |
| 모델 다운로드 | 중국 Electra 미리 훈련 된 모델을 다운로드하십시오 |
| 빠른 로딩 | 변압기와 패들 hub를 사용하는 방법 모델은 모델을 빠르게로드합니다 |
| 기준 시스템 효과 | 중국 기준 시스템의 영향 : 독해, 텍스트 분류 등 |
| 사용 방법 | 모델의 자세한 사용 |
| FAQ | FAQ와 답변 |
| 인용하다 | 이 디렉토리의 기술 보고서 |
Electra는 발전기 와 판별 자의 두 부분을 포함하는 새로운 사전 훈련 프레임 워크를 제안합니다.
사전 훈련 단계가 끝난 후에는 식별기를 다운 스트림 작업의 기본 모델로만 사용합니다.
자세한 내용은 Electra 용지를 참조하십시오 : Electra : 발전기가 아닌 판별 자로 사전 훈련 텍스트 인코더
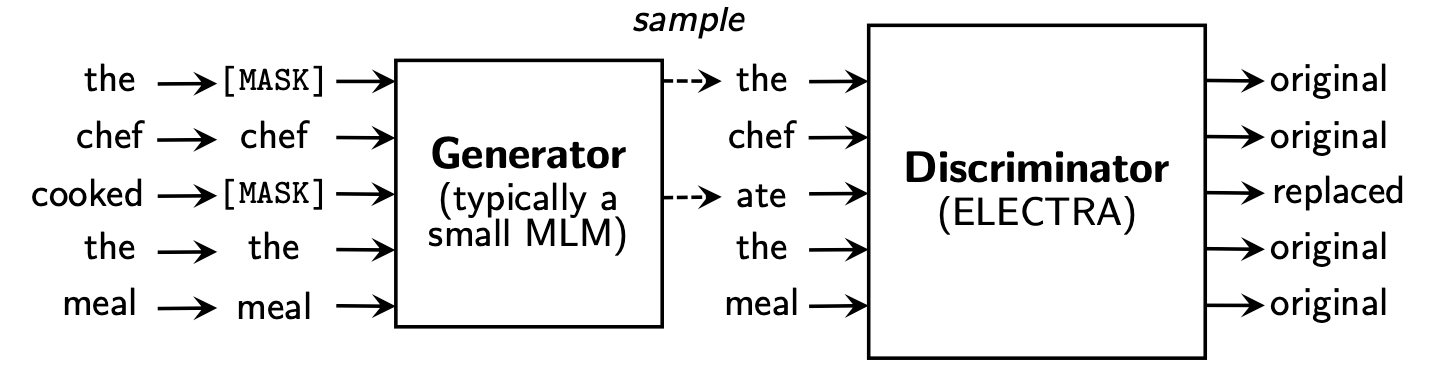
이 디렉토리에는 다음 모델이 포함되어 있으며 현재 Tensorflow 버전 가중치 만 제공합니다.
ELECTRA-large, Chinese : 24 계층, 1024- 히든, 16 개의 헤드, 324m 매개 변수ELECTRA-base, Chinese : 12 층, 768- 히든, 12- 헤드, 102m 매개 변수ELECTRA-small-ex, Chinese : 24 층, 256- 히든, 4 개의 헤드, 25m 매개 변수ELECTRA-small, Chinese : 12 층, 256- 숨겨진, 4 개의 헤드, 12m 매개 변수 | 모델 약어 | Google 다운로드 | Baidu NetDisk 다운로드 | 압축 패키지 크기 |
|---|---|---|---|
ELECTRA-180g-large, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 2v5r) | 1g |
ELECTRA-180g-base, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 3VG1) | 383m |
ELECTRA-180g-small-ex, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 93N8) | 92m |
ELECTRA-180g-small, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 k9iu) | 46m |
| 모델 약어 | Google 다운로드 | Baidu NetDisk 다운로드 | 압축 패키지 크기 |
|---|---|---|---|
ELECTRA-large, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 1E14) | 1g |
ELECTRA-base, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 F32J) | 383m |
ELECTRA-small-ex, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 GFB1) | 92m |
ELECTRA-small, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 1R4R) | 46m |
| 모델 약어 | Google 다운로드 | Baidu NetDisk 다운로드 | 압축 패키지 크기 |
|---|---|---|---|
legal-ELECTRA-large, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 Q4GV) | 1g |
legal-ELECTRA-base, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 8GCV) | 383m |
legal-ELECTRA-small, Chinese | 텐서 플로 | 텐서 플로우 (비밀번호 kmrj) | 46m |
Pytorch 버전이 필요한 경우 변환 스크립트 변환 스크립트를 통해 직접 변환하십시오. 변환기에서 제공 한 Converted_Electra_original_tf_checkpoint_to_pytorch.py. 구성 파일이 필요한 경우이 디렉토리의 구성 폴더를 입력하여 검색 할 수 있습니다.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminator또는 huggingface의 공식 웹 사이트를 통해 Pytorch를 직접 다운로드하십시오 : https://huggingface.co/hfl
방법 : 다운로드하려는 모든 모델을 클릭하십시오 → 하단으로 당기고 "모델의 모든 파일 나열"→ 팝업 상자에서 Bin 및 JSON 파일을 다운로드하십시오.
중국 본토에서 Baidu NetDisk 다운로드 포인트를 사용하는 것이 좋습니다. 해외 사용자의 Google 다운로드 포인트를 사용하는 것이 좋습니다. ELECTRA-small, Chinese 의 TensorFlow 버전을 예로 들어, 다운로드 한 후 ZIP 파일을 압축하여 다음 파일을 얻습니다.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
우리는 대규모 중국 위키와 일반 텍스트를 사용하여 Electra 모델을 훈련 시켰으며, 총 토큰 수는 5.4b에 도달했으며 이는 Roberta-WWM-EXT 시리즈 모델과 일치합니다. 어휘 목록과 관련하여 21,128 개의 토큰을 포함하여 Google의 Original Bert Word Piece Vocabulary List를 사용합니다. 다른 세부 사항 및 하이퍼 파라미터는 다음과 같습니다 (언급되지 않은 매개 변수는 기본적으로 유지됨).
ELECTRA-large : 24 개의 층, 숨겨진 층 1024, 16주의 헤드, 학습 속도 1e-4, Batch96, 최대 길이 512, 훈련 2m 단계ELECTRA-base : 12 개의 층, 숨겨진 층 768, 12주의 헤드, 학습 속도 2E-4, Batch256, 최대 길이 512, 훈련 1m 단계ELECTRA-small-ex : 24 층, 숨겨진 층 256, 4 개의주의 헤드, 학습 속도 5E-4, Batch384, 최대 길이 512, 2m 교육 단계ELECTRA-small : 12 층, 숨겨진 층 256, 4 개의주의 헤드, 학습 속도 5E-4, Batch1024, 최대 길이 512, 훈련 1m 단계 Huggingface-Transformers 버전 2.8.0은 공식적으로 Electra 모델을 지원했으며 다음 명령을 통해 호출 할 수 있습니다.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) MODEL_NAME 의 해당 목록은 다음과 같습니다.
| 모델 이름 | 구성 요소 | model_name |
|---|---|---|
| Electra-180G-Large, 중국어 | 판별 자 | HFL/중국-전자 -180G-large-discriminator |
| Electra-180G-Large, 중국어 | 발전기 | HFL/중국-전자 -180G-LARGE-Generator |
| Electra-180G-Base, 중국어 | 판별 자 | HFL/중국-전자 -180G- 염기-분류기 |
| Electra-180G-Base, 중국어 | 발전기 | HFL/중국-전자 -180G-베이스 생성기 |
| Electra-180g-small-ex, 중국어 | 판별 자 | HFL/중국-전자 -180G-SMALL-EX-DISCRIMINATOR |
| Electra-180g-small-ex, 중국어 | 발전기 | HFL/중국-전자 -180G-Small-Ex-Generator |
| Electra-180G-Small, 중국어 | 판별 자 | HFL/중국-전자 -180G-Small-Discriminator |
| Electra-180G-Small, 중국어 | 발전기 | HFL/중국-전자 -180G-Small-Generator |
| 전자-대단한, 중국어 | 판별 자 | HFL/중국-전자-레이지-범죄자 |
| 전자-대단한, 중국어 | 발전기 | HFL/중국-전자-레이지 제너레이터 |
| 전기 기반, 중국어 | 판별 자 | HFL/중국-전자-염기-범죄자 |
| 전기 기반, 중국어 | 발전기 | HFL/중국-전자-베이스-제너레이터 |
| Electra-Small-Ex, 중국어 | 판별 자 | HFL/중국-전자-스몰-엑스 스 크리 미네이터 |
| Electra-Small-Ex, 중국어 | 발전기 | HFL/중국-전자-스몰 엑스 제너레이터 |
| 전자식, 중국어 | 판별 자 | HFL/중국-전자-스몰-스 크리 미네이터 |
| 전자식, 중국어 | 발전기 | HFL/중국-전자-매소 제너레이터 |
사법 영역 버전 :
| 모델 이름 | 구성 요소 | model_name |
|---|---|---|
| 법적 전자-선반, 중국어 | 판별 자 | HFL/중국-전자-전자-레이지-감소기 |
| 법적 전자-선반, 중국어 | 발전기 | HFL/중국-레게-전자-래지-제너레이터 |
| 법적 전자 기반, 중국어 | 판별 자 | HFL/중국-전자-전자-염기-감소기 |
| 법적 전자 기반, 중국어 | 발전기 | HFL/중국-레게-전자-베이스-제너레이터 |
| 법적 전자, 중국어 | 판별 자 | HFL/중국-레게-전자-스몰-크리 미네이터 |
| 법적 전자, 중국어 | 발전기 | HFL/중국-레그 전자-스몰-제너레이터 |
PaddleHub에 의존하여 모델의 다운로드 및 설치를 완료하기 위해 하나의 코드 줄만 있으면 10 개 이상의 코드 라인이 텍스트 분류, 시퀀스 주석, 읽기 이해 및 기타 작업의 작업을 완료 할 수 있습니다.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
MODULE_NAME 의 해당 목록은 다음과 같습니다.
| 모델 이름 | module_name |
|---|---|
| 전기 기반, 중국어 | 중국-전자 기반 |
| 전자식, 중국어 | 중국-전자-스몰 |
우리는 ELECTRA-small/base 의 영향을 BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext 및 RBT3 과 비교했습니다.
Electra-Small/Base 모델의 경우 원래 논문에서 3e-4 및 1e-4 의 기본 학습 속도를 사용합니다. 우리는 모든 작업에 대한 매개 변수 조정을 수행하지 않았으므로 학습 속도와 같은 하이퍼 파라미터를 조정하여 추가 성능 향상을 달성 할 수 있습니다. 결과의 신뢰성을 보장하기 위해 동일한 모델에 대해 다른 임의의 씨앗을 사용하여 10 번 훈련하여 모델 성능의 최대 및 평균값 (괄호의 평균값)을보고했습니다.
CMRC 2018 데이터 세트는 Harbin Institute of Technology의 공동 실험실에서 발표 한 중국 기계 판독 이해 데이터입니다. 주어진 질문에 따르면, 시스템은 분대와 동일한 형태로 챕터에서 답으로 조각을 추출해야합니다. 평가 지표는 다음과 같습니다. EM / F1
| 모델 | 개발 세트 | 테스트 세트 | 도전 세트 | 매개 변수 수량 |
|---|---|---|---|---|
| 버트베이스 | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| Bert-WWM | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| Bert-WWM-EXT | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| Roberta-WWM-EXT | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| 전자식 | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12m |
| Electra-180G-Small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180G-Small-Ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| 전자 기반 | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102m |
| Electra-180G-Base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| 전기 | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180G-LARGE | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
DRCD 데이터 세트는 중국 대만 델타 리서치 인스티튜트 (Delta Research Institute)가 발표했습니다. 그 형태는 분대와 동일하며 전통적인 중국어를 기반으로 한 추출 된 독해 이해 데이터 세트입니다. 평가 지표는 다음과 같습니다. EM / F1
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 버트베이스 | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102m |
| Bert-WWM | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| Bert-WWM-EXT | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102m |
| Roberta-WWM-EXT | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102m |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| 전자식 | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12m |
| Electra-180G-Small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180G-Small-Ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| 전자 기반 | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102m |
| Electra-180G-Base | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| 전기 | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180G-LARGE | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
자연 언어 추론 작업에서 XNLI 데이터를 채택합니다. XNLI 데이터는 텍스트를 세 가지 범주의 entailment , neutral 및 contradictory 로 나누어야합니다. 평가 표시기는 다음과 같습니다. 정확도
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 버트베이스 | 77.8 (77.4) | 77.8 (77.5) | 102m |
| Bert-WWM | 79.0 (78.4) | 78.2 (78.0) | 102m |
| Bert-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) | 102m |
| Roberta-WWM-EXT | 80.0 (79.2) | 78.8 (78.3) | 102m |
| RBT3 | 72.2 | 72.3 | 38m |
| 전자식 | 73.3 (72.5) | 73.1 (72.6) | 12m |
| Electra-180G-Small | 74.6 | 74.6 | 12m |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180G-Small-Ex | 76.5 | 76.6 | 25m |
| 전자 기반 | 77.9 (77.0) | 78.4 (77.8) | 102m |
| Electra-180G-Base | 79.6 | 79.5 | 102m |
| 전기 | 81.5 | 81.0 | 324m |
| Electra-180G-LARGE | 81.2 | 80.4 | 324m |
감정 분석 작업에서 이진 감정 분류 데이터 세트 chnsenticorp . 평가 표시기는 다음과 같습니다. 정확도
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 버트베이스 | 94.7 (94.3) | 95.0 (94.7) | 102m |
| Bert-WWM | 95.1 (94.5) | 95.4 (95.0) | 102m |
| Bert-WWM-EXT | 95.4 (94.6) | 95.3 (94.7) | 102m |
| Roberta-WWM-EXT | 95.0 (94.6) | 95.6 (94.8) | 102m |
| RBT3 | 92.8 | 92.8 | 38m |
| 전자식 | 92.8 (92.5) | 94.3 (93.5) | 12m |
| Electra-180G-Small | 94.1 | 93.6 | 12m |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180G-Small-Ex | 92.8 | 93.4 | 25m |
| 전자 기반 | 93.8 (93.0) | 94.5 (93.5) | 102m |
| Electra-180G-Base | 94.3 | 94.8 | 102m |
| 전기 | 95.2 | 95.3 | 324m |
| Electra-180G-LARGE | 94.8 | 95.2 | 324m |
다음 두 데이터 세트는 두 문장의 의미론이 동일한 지 여부를 결정하기 위해 문장 쌍을 분류해야합니다 (이진 분류 작업).
LCQMC는 Harbin Technology Institute of Technology Shenzhen 대학원의 지능형 컴퓨팅 연구 센터에서 발표했습니다. 평가 표시기는 다음과 같습니다. 정확도
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 버트 | 89.4 (88.4) | 86.9 (86.4) | 102m |
| Bert-WWM | 89.4 (89.2) | 87.0 (86.8) | 102m |
| Bert-WWM-EXT | 89.6 (89.2) | 87.1 (86.6) | 102m |
| Roberta-WWM-EXT | 89.0 (88.7) | 86.4 (86.1) | 102m |
| RBT3 | 85.3 | 85.1 | 38m |
| 전자식 | 86.7 (86.3) | 85.9 (85.6) | 12m |
| Electra-180G-Small | 86.6 | 85.8 | 12m |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180G-Small-Ex | 87.6 | 86.3 | 25m |
| 전자 기반 | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180G-Base | 90.2 | 87.1 | 102m |
| 전기 | 90.7 | 87.3 | 324m |
| Electra-180G-LARGE | 90.3 | 87.3 | 324m |
BQ 코퍼스는 Harbin Technology Institute of Technology Shenzhen 대학원의 지능형 컴퓨팅 연구 센터에서 발표되며 은행 분야의 데이터 세트입니다. 평가 표시기는 다음과 같습니다. 정확도
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 버트 | 86.0 (85.5) | 84.8 (84.6) | 102m |
| Bert-WWM | 86.1 (85.6) | 85.2 (84.9) | 102m |
| Bert-WWM-EXT | 86.4 (85.5) | 85.3 (84.8) | 102m |
| Roberta-WWM-EXT | 86.0 (85.4) | 85.0 (84.6) | 102m |
| RBT3 | 84.1 | 83.3 | 38m |
| 전자식 | 83.5 (83.0) | 82.0 (81.7) | 12m |
| Electra-180G-Small | 83.3 | 82.1 | 12m |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180G-Small-Ex | 84.6 | 83.4 | 25m |
| 전자 기반 | 84.8 (84.7) | 84.5 (84.0) | 102m |
| Electra-180G-Base | 85.8 | 84.5 | 102m |
| 전기 | 86.7 | 85.1 | 324m |
| Electra-180G-LARGE | 86.4 | 85.4 | 324m |
우리는 Cail 2018 사법 심사의 범죄 예측 데이터를 사용하여 사법 전기를 테스트했습니다. 소규모/기본/큰 학습 속도는 각각 5E-4/3E-4/1E-4입니다. 평가 표시기는 다음과 같습니다. 정확도
| 모델 | 개발 세트 | 테스트 세트 | 매개 변수 수량 |
|---|---|---|---|
| 전자식 | 78.84 | 76.35 | 12m |
| 법적-전자-금속 | 79.60 | 77.03 | 12m |
| 전자 기반 | 80.94 | 78.41 | 102m |
| 법적 전자 기반 | 81.71 | 79.17 | 102m |
| 전기 | 81.53 | 78.97 | 324m |
| 법적 전자-배출 | 82.60 | 79.89 | 324m |
사용자는 위의 게시 된 중국 Electra 사전 훈련 된 모델을 기반으로 다운 스트림 작업 미세 조정을 수행 할 수 있습니다. 여기서 우리는 가장 기본적인 사용법 만 소개합니다. 보다 자세한 사용은 Electra의 공식 소개를 참조하십시오.
이 예에서는 ELECTRA-small 모델을 사용하여 CMRC 2018 작업을 미세 조정했으며 관련 단계는 다음과 같습니다. 가정,
data-dir : 실제 상황에 따라 작동 루트 디렉토리를 설정할 수 있습니다.model-name : 모델 이름,이 경우 electra-small .task-name : 작업 이름,이 경우 cmrc2018 . 이 디렉토리의 코드는 위의 6 가지 중국 작업에 적합했으며 task-name cmrc2018 , drcd , xnli , chnsenticorp , lcqmc 및 bqcorpus 입니다. 모델 다운로드 섹션에서 Electra-Small 모델을 다운로드하여 ${data-dir}/models/${model-name} 으로 압축 해제하십시오. 이 디렉토리에는 electra_model.* , vocab.txt , checkpoint 및 총 5 개의 파일이 포함되어야합니다.
CMRC 2018 교육 및 개발 세트를 다운로드하여 train.json 및 dev.json 으로 이름을 바꿉니다. ${data-dir}/finetuning_data/${task-name} 에 두 개의 파일을 넣습니다.
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json 그 중에서도 data-dir 및 model-name 위에 소개되었습니다. hparams 는 JSON 사전입니다. 이 예에서, params_cmrc2018.json 다음과 같은 미세 조정 관련 초반미터를 포함합니다.
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}위의 JSON 파일에는 가장 중요한 매개 변수 만 나열합니다. 전체 매개 변수 목록은 configure_finenetung.py를 참조하십시오.
작업이 완료된 후
cmrc2018_dev_preds.json ${data-dir}/results/${task-name}_qa/ 에 저장됩니다. 외부 평가 스크립트에 전화하여 최종 평가 결과를 얻을 수 있습니다 (예 : python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 Q : 다운 스트림 작업을 미세 조정할 때 Electra 모델의 학습 속도를 설정하는 방법은 무엇입니까?
A : 원래 논문에서 사용한 학습 속도를 초기 기준선 (작은 IS 3E-4,베이스는 1E-4)으로 사용한 다음 학습 속도의 적절한 추가 및 감소로 디버깅하는 것이 좋습니다. Bert 및 Roberta와 같은 모델과 비교하여 Electra의 학습 속도는 비교적 큽니다.
Q : Pytorch 저작권이 있습니까?
A : 그렇습니다. 모델을 다운로드하십시오.
Q : 사전 훈련 데이터를 공유 할 수 있습니까?
A : 불행히도 아니요.
Q : 향후 계획?
A : 계속 지켜봐주세요.
이 디렉토리의 내용이 귀하의 연구 작업에 도움이된다면 논문에서 다음 논문을 자유롭게 인용하십시오.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Iflytek Joint Laboratory의 공식 WeChat 공식 계정을 따라 최신 기술 트렌드에 대해 알아보십시오.

문제를 제출하기 전에 :


