Chinese ELECTRA
1.0.0
Китайское описание | Английский

Этот проект основан на официальной Electra of Google & Stanford University: https://github.com/google-research/electra
Китайский Лерт | Китайский английский pert | Китайский Макберт | Китайская электро | Китайский Xlnet | Китайский берт | Инструмент для дистилляции знаний TextBrewer | Модельный режущий инструмент текст
См. Больше ресурсов, выпущенных IFL из Технологического института Харбина (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Китайская большая модель Llama & Alpaca, которая может быть быстро развернута и опыта на ПК, просмотр: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Мы предлагаем предварительно обученную модель LERT, которая интегрирует лингвистическую информацию. Просмотр: https://github.com/ymcui/lert
2022/3/30 Мы открываем новую предварительно обученную модель pert. Просмотр: https://github.com/ymcui/pert
2021/12/17 Совместная лаборатория Iflytek запускает модель резания инструментального инструмента Textpruner. Просмотр: https://github.com/airaria/textpruner
2021/10/24 Совместная лаборатория Iflytek выпустила предварительно обученную модель CINO для языков этнических меньшинств. Просмотр: https://github.com/ymcui/chinese-minority-plm
2021/7/21 «Обработка естественного языка: методы, основанные на моделях предварительных тренировок», написанные многими учеными из Харбинского технологического института Scir, и все могут его приобрести.
2020/12/13 На основании крупномасштабных данных правовых документов мы обучили модели китайских серий Electra для судебной области для просмотра загрузки моделей, и судебных эффектов задач.
2020/9/15 Наша статья «Пересмотр предварительно обученных моделей для китайской обработки естественного языка» была нанята в качестве длинной статьи по выводам EMNLP.
2020/8/27 IFL Совместная лаборатория возглавила список в клей, общий естественный язык Понимание оценки, проверьте список клей, новости.
2020/5/29 китайский электро-широкий/Small-EX был выпущен. Пожалуйста, проверьте загрузку модели. В настоящее время доступен только адрес загрузки Google Drive, так что, пожалуйста, поймите.
2020/4/7 Пользователи Pytorch могут загрузить модель через? Трансформаторы для просмотра быстрой загрузки.
2020/3/31 Модели, опубликованные в этом каталоге, были подключены к Paddlepaddlehub для быстрого просмотра и загрузки.
2020/3/25 Китайский Electra-Small/Base был выпущен, пожалуйста, проверьте загрузку модели.
| глава | описывать |
|---|---|
| Введение | Введение в основные принципы Electra |
| Модель скачать | Загрузите модель китайского электроэлектрой, предварительно обученную |
| Быстрая загрузка | Как использовать трансформаторы и паддлхуб быстро загружать модели |
| Базовые системы системы | Эффекты базовой системы Китая: понимание прочитанного, классификация текста и т. Д. |
| Как использовать | Подробное использование модели |
| Часто задаваемые вопросы | Часто задаваемые вопросы и ответы |
| Цитировать | Технические отчеты в этом каталоге |
Electra предлагает новую структуру предварительного обучения, которая включает две части: генератор и дискриминатор .
После того, как фаза предварительного тренировки закончилась, мы используем Discinator только в качестве базовой модели для выполненных вниз по течению задач.
Для получения более подробного содержания, пожалуйста, обратитесь к Electra Paper: Electra: Traving Text Encoders в виде дискриминаторов, а не генераторов
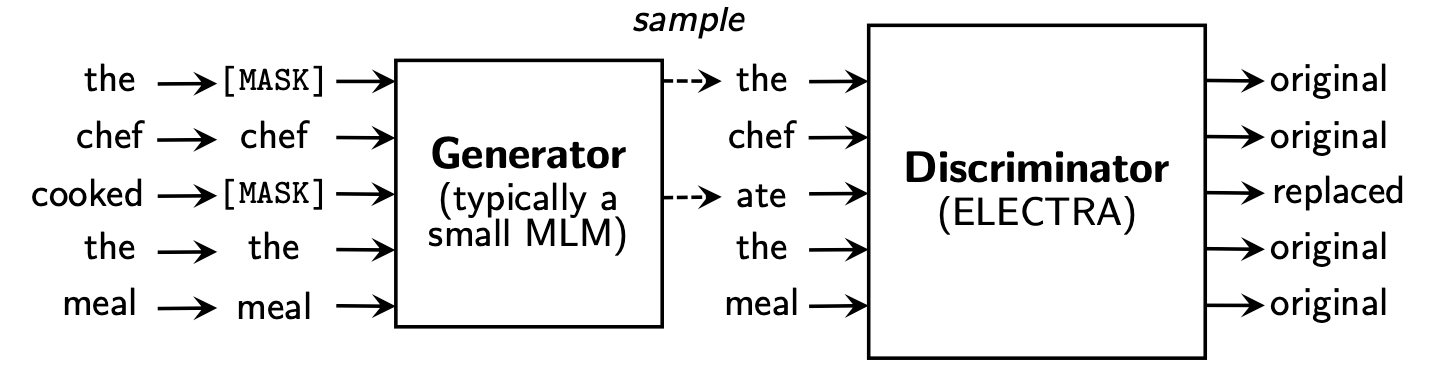
Этот каталог содержит следующие модели и в настоящее время обеспечивает только вес версии TensorFlow.
ELECTRA-large, Chinese : 24-слойный, 1024 скрытый, 16 голов, параметры 324 мELECTRA-base, Chinese : 12-слойный, 768 скрытый, 12 голов, параметры 102 м.ELECTRA-small-ex, Chinese : 24-слойный, 256 скрытых, 4 голова, 25-метровые параметрыELECTRA-small, Chinese : 12-слойный, 256 скрытый, 4 головы, 12 м. Параметры | Модель аббревиатура | Google скачать | Baidu NetDisk скачать | Сжатый размер упаковки |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | Tensorflow (пароль 2v5r) | 1G |
ELECTRA-180g-base, Chinese | Tensorflow | Tensorflow (пароль 3vg1) | 383M |
ELECTRA-180g-small-ex, Chinese | Tensorflow | Tensorflow (пароль 93n8) | 92 м |
ELECTRA-180g-small, Chinese | Tensorflow | Tensorflow (пароль k9iu) | 46 м |
| Модель аббревиатура | Google скачать | Baidu NetDisk скачать | Сжатый размер упаковки |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | Tensorflow (пароль 1e14) | 1G |
ELECTRA-base, Chinese | Tensorflow | Tensorflow (пароль F32J) | 383M |
ELECTRA-small-ex, Chinese | Tensorflow | Tensorflow (пароль GFB1) | 92 м |
ELECTRA-small, Chinese | Tensorflow | Tensorflow (пароль 1r4r) | 46 м |
| Модель аббревиатура | Google скачать | Baidu NetDisk скачать | Сжатый размер упаковки |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | Tensorflow (пароль Q4GV) | 1G |
legal-ELECTRA-base, Chinese | Tensorflow | Tensorflow (пароль 8gcv) | 383M |
legal-ELECTRA-small, Chinese | Tensorflow | Tensorflow (пароль kmrj) | 46 м |
Если вам нужна версия Pytorch, пожалуйста, преобразуйте ее через скрипт преобразования конвертированной_алектрий_оригинал_TF_CHECKPOINT_TO_PYTORCH.PY, предоставленное трансформаторами. Если вам нужны файлы конфигурации, вы можете ввести папку конфигурации в этом каталоге для поиска.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorИли непосредственно скачать Pytorch через официальный сайт HuggingFace: https://huggingface.co/hfl
Метод: нажмите на любую модель, которую вы хотите загрузить → Вытянуть вниз и нажмите «Список всех файлов в модели» → Загрузите файлы бина и JSON в всплывающем окне.
Рекомендуется использовать точки загрузки Baidu NetDisk в материковом Китае, в то время как рекомендуется использовать точки загрузки Google у зарубежных пользователей. В качестве примера, принимая версию ELECTRA-small, Chinese Tensorflow, распаковка файла Zip для получения следующего файла.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Мы использовали крупномасштабные китайские вики и общий текст для обучения модели Electra, причем общее число токенов достигает 5,4B, что согласуется с моделью серии Roberta-WWM-EXT. С точки зрения списка словарного запаса, он использует оригинальный список словарных словарных слов Google Wordiece, в том числе 21 128 токенов. Другие детали и гиперпараметры заключаются в следующем (не упомянутые параметры остаются по умолчанию):
ELECTRA-large : 24 слоя, скрытый слой 1024, 16 головок внимания, скорость обучения 1E-4, BATCH96, максимальная длина 512, тренировка 2м шагаELECTRA-base : 12 слоев, Скрытый слой 768, 12 головок внимания, скорость обучения 2E-4, BATCH256, максимальная длина 512, тренировка 1м шагELECTRA-small-ex : 24 слоя, скрытый слой 256, 4 головы внимания, скорость обучения 5E-4, BATCH384, максимальная длина 512, 2-метровые шаги обученияELECTRA-small : 12 слоев, скрытый слой 256, 4 головы внимания, скорость обучения 5e-4, batch1024, максимальная длина 512, тренировка 1м шаг Guggingface-transformers версии 2.8.0 официально поддержала модель Electra и может быть вызвана следующими командами.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) Соответствующий список MODEL_NAME заключается в следующем:
| Название модели | Компоненты | Model_name |
|---|---|---|
| Electra-180g-Large, китайский | дискриминатор | HFL/Китайско-Электрой-180G-Дискриминатор |
| Electra-180g-Large, китайский | Генератор | HFL/Китайско-Электрой-180G-широкий генератор |
| Electra-180g-баз, китайский | дискриминатор | HFL/Китайско-Электрой-180G-база-дискриминатор |
| Electra-180g-баз, китайский | Генератор | HFL/Китайско-Электрой-180G-базовый генератор |
| Electra-180g-Small-Ex, китайский | дискриминатор | HFL/Китай-Электрой-180G-SMALL-EX-Дискриминатор |
| Electra-180g-Small-Ex, китайский | Генератор | HFL/Китай-Электрой-180G-SMALL-EXER-GENERATOR |
| Electra-180g-Small, китайский | дискриминатор | HFL/Китайско-Электрой-180G-SMALL-Дискриминатор |
| Electra-180g-Small, китайский | Генератор | HFL/Китайско-Электрой-180G-Смалл-Генератор |
| Электро-широкий, китайский | дискриминатор | HFL/Китайско-Электронный-Дискриминатор |
| Электро-широкий, китайский | Генератор | HFL/Китайско-Электронный Генератор |
| Электро-баз, китайский | дискриминатор | HFL/Китайско-Электро-База-Дискриминатор |
| Электро-баз, китайский | Генератор | HFL/Китайско-электро-базовый генератор |
| Electra-Small-Ex, китайский | дискриминатор | HFL/Китайско-Электрой-Смалл-Экс-Дискриминатор |
| Electra-Small-Ex, китайский | Генератор | HFL/Китайско-Электрой-Смалл-Экс-генератор |
| Электра-Смалл, китайский | дискриминатор | HFL/Китайско-Электра-См-Дискриминатор |
| Электра-Смалл, китайский | Генератор | HFL/Китайско-Электрой-Смейл-Генератор |
Версия судебной домены:
| Название модели | Компоненты | Model_name |
|---|---|---|
| легальный электро-электро, китайский | дискриминатор | HFL/китайский легал-электро-дискриминатор |
| легальный электро-электро, китайский | Генератор | HFL/Китайский легал-электро-генератор |
| легальная электроэлектрическая база, китайский | дискриминатор | HFL/китайский легал-электро-базовый дискриминатор |
| легальная электроэлектрическая база, китайский | Генератор | HFL/китайский легал-электро-базовый генератор |
| Легальная электроматлетка, китайский | дискриминатор | HFL/китайский легал-электро-дискриминатор |
| Легальная электроматлетка, китайский | Генератор | HFL/китайский легал-электро-мал-генератор |
Полагаясь на Paddlehub, нам нужна только одна строка кода для завершения загрузки и установки модели, и более десяти строк кода могут выполнить задачи классификации текста, аннотации последовательности, понимания прочитанного и других задач.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
Соответствующий список MODULE_NAME заключается в следующем:
| Название модели | Module_name |
|---|---|
| Электро-баз, китайский | Китайско-электрическая база |
| Электра-Смалл, китайский | Китайско-электрический-смалл |
Мы сравнили эффекты ELECTRA-small/base с BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext и RBT3 , включая следующие шесть задач:
Для модели Electra-Small/Base мы используем скорости обучения по умолчанию 3e-4 и 1e-4 в исходной статье. Следует отметить, что мы не выполняли корректировки параметров для любых задач, поэтому дальнейшие улучшения производительности могут быть достигнуты путем корректировки гиперпараметров, таких как скорость обучения. Чтобы обеспечить надежность результатов, для одной и той же модели мы тренировались 10 раз, используя различные случайные семена, чтобы сообщить о максимальных и средних значениях производительности модели (средние значения в скобках).
Набор данных CMRC 2018 - это китайские данные о понимании прочитанного машины, опубликованные Объединенной лабораторией Технологического института Харбина. Согласно данному вопросу, система должна извлечь фрагменты из главы в качестве ответа, в той же форме, что и команда. Индикаторы оценки: EM / F1
| Модель | Разработка набора | Тестовый набор | Вызов набор | Параметр Количество |
|---|---|---|---|---|
| Берт-баз | 65,5 (64,4) / 84,5 (84,0) | 70,0 (68,7) / 87,0 (86,3) | 18.6 (17,0) / 43,3 (41,3) | 102 м |
| Берт-УВМ | 66,3 (65,0) / 85,6 (84,7) | 70,5 (69,1) / 87,4 (86,7) | 21,0 (19,3) / 47,0 (43,9) | 102 м |
| Bert-WWM-Ext | 67,1 (65,6) / 85,7 (85,0) | 71,4 (70,0) / 87,7 (87,0) | 24.0 (20,0) / 47,3 (44,6) | 102 м |
| Роберта-Вум-Экс | 67,4 (66,5) / 87,2 (86,5) | 72,6 (71,4) / 89,4 (88,8) | 26,2 (24,6) / 51,0 (49,1) | 102 м |
| RBT3 | 57,0 / 79,0 | 62,2 / 81,8 | 14.7 / 36.2 | 38м |
| Электра-Смалл | 63,4 (62,9) / 80,8 (80,2) | 67,8 (67,4) / 83,4 (83,0) | 16,3 (15,4) / 37,2 (35,8) | 12 м |
| Electra-180g-Small | 63,8 / 82,7 | 68,5 / 85,2 | 15,1 / 35,8 | 12 м |
| Electra-Small-Ex | 66.4 / 82,2 | 71,3 / 85,3 | 18.1 / 38.3 | 25 м |
| Electra-180g-Small-Ex | 68,1 / 85,1 | 71.8 / 87.2 | 20,6 / 41,7 | 25 м |
| Электрабаза | 68,4 (68,0) / 84,8 (84,6) | 73.1 (72,7) / 87,1 (86,9) | 22,6 (21,7) / 45,0 (43,8) | 102 м |
| Electra-180g-база | 69,3 / 87,0 | 73,1 / 88,6 | 24.0 / 48.6 | 102 м |
| Электро-широкий | 69,1 / 85,2 | 73,9 / 87,1 | 23.0 / 44.2 | 324 м |
| Electra-180g-Large | 68,5 / 86,2 | 73,5 / 88,5 | 21,8 / 42,9 | 324 м |
Набор данных DRCD был выпущен Delta Research Institute, Тайвань, Китай. Его форма такая же, как команда, и является извлеченным набором данных по пониманию прочитанного, основанного на традиционном китайском языке. Индикаторы оценки: EM / F1
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| Берт-баз | 83,1 (82,7) / 89,9 (89,6) | 82,2 (81,6) / 89,2 (88,8) | 102 м |
| Берт-УВМ | 84,3 (83,4) / 90,5 (90,2) | 82,8 (81,8) / 89,7 (89,0) | 102 м |
| Bert-WWM-Ext | 85,0 (84,5) / 91,2 (90,9) | 83,6 (83,0) / 90,4 (89,9) | 102 м |
| Роберта-Вум-Экс | 86,6 (85,9) / 92,5 (92,2) | 85,6 (85,2) / 92,0 (91,7) | 102 м |
| RBT3 | 76,3 / 84,9 | 75,0 / 83,9 | 38м |
| Электра-Смалл | 79,8 (79,4) / 86,7 (86,4) | 79,0 (78,5) / 85,8 (85,6) | 12 м |
| Electra-180g-Small | 83,5 / 89,2 | 82,9 / 88,7 | 12 м |
| Electra-Small-Ex | 84,0 / 89,5 | 83,3 / 89,1 | 25 м |
| Electra-180g-Small-Ex | 87,3 / 92,3 | 86.5 / 91.3 | 25 м |
| Электрабаза | 87,5 (87,0) / 92,5 (92,3) | 86,9 (86,6) / 91,8 (91,7) | 102 м |
| Electra-180g-база | 89,6 / 94,2 | 88,9 / 93,7 | 102 м |
| Электро-широкий | 88,8 / 93,3 | 88,8 / 93,6 | 324 м |
| Electra-180g-Large | 90.1 / 94,8 | 90,5 / 94,7 | 324 м |
В задаче по выводу естественного языка мы принимаем данные XNLI , которые требуют, чтобы текст был разделен на три категории: entailment , neutral и contradictory . Индикатор оценки: точность
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| Берт-баз | 77,8 (77,4) | 77,8 (77,5) | 102 м |
| Берт-УВМ | 79,0 (78,4) | 78,2 (78,0) | 102 м |
| Bert-WWM-Ext | 79,4 (78,6) | 78,7 (78,3) | 102 м |
| Роберта-Вум-Экс | 80,0 (79,2) | 78,8 (78,3) | 102 м |
| RBT3 | 72,2 | 72,3 | 38м |
| Электра-Смалл | 73,3 (72,5) | 73,1 (72,6) | 12 м |
| Electra-180g-Small | 74,6 | 74,6 | 12 м |
| Electra-Small-Ex | 75,4 | 75,8 | 25 м |
| Electra-180g-Small-Ex | 76.5 | 76.6 | 25 м |
| Электрабаза | 77,9 (77,0) | 78,4 (77,8) | 102 м |
| Electra-180g-база | 79,6 | 79,5 | 102 м |
| Электро-широкий | 81.5 | 81.0 | 324 м |
| Electra-180g-Large | 81.2 | 80.4 | 324 м |
В задаче анализа настроений набор данных бинарной классификации эмоций Chnsenticorp . Индикатор оценки: точность
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| Берт-баз | 94,7 (94,3) | 95,0 (94,7) | 102 м |
| Берт-УВМ | 95,1 (94,5) | 95,4 (95,0) | 102 м |
| Bert-WWM-Ext | 95,4 (94,6) | 95,3 (94,7) | 102 м |
| Роберта-Вум-Экс | 95,0 (94,6) | 95,6 (94,8) | 102 м |
| RBT3 | 92,8 | 92,8 | 38м |
| Электра-Смалл | 92,8 (92,5) | 94,3 (93,5) | 12 м |
| Electra-180g-Small | 94.1 | 93,6 | 12 м |
| Electra-Small-Ex | 92.6 | 93,6 | 25 м |
| Electra-180g-Small-Ex | 92,8 | 93.4 | 25 м |
| Электрабаза | 93,8 (93,0) | 94,5 (93,5) | 102 м |
| Electra-180g-база | 94.3 | 94,8 | 102 м |
| Электро-широкий | 95.2 | 95.3 | 324 м |
| Electra-180g-Large | 94,8 | 95.2 | 324 м |
Следующие два набора данных должны классифицировать пару предложений, чтобы определить, одинакова ли семантика двух предложений (задача бинарной классификации).
LCQMC был выпущен Центром интеллектуальных компьютерных исследований Харбинского технологического института Технологической аспирантуры Шэньчжэнь. Индикатор оценки: точность
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| БЕРТ | 89,4 (88,4) | 86,9 (86,4) | 102 м |
| Берт-УВМ | 89,4 (89,2) | 87,0 (86,8) | 102 м |
| Bert-WWM-Ext | 89,6 (89,2) | 87,1 (86,6) | 102 м |
| Роберта-Вум-Экс | 89,0 (88,7) | 86,4 (86,1) | 102 м |
| RBT3 | 85,3 | 85,1 | 38м |
| Электра-Смалл | 86,7 (86,3) | 85,9 (85,6) | 12 м |
| Electra-180g-Small | 86.6 | 85,8 | 12 м |
| Electra-Small-Ex | 87.5 | 86.0 | 25 м |
| Electra-180g-Small-Ex | 87.6 | 86.3 | 25 м |
| Электрабаза | 90,2 (89,8) | 87,6 (87,3) | 102 м |
| Electra-180g-база | 90.2 | 87.1 | 102 м |
| Электро-широкий | 90.7 | 87.3 | 324 м |
| Electra-180g-Large | 90.3 | 87.3 | 324 м |
BQ Corpus выпускается в Центре интеллектуальных компьютерных исследований Харбинского технологического института в Шэньчжэне и является набором данных для банковской области. Индикатор оценки: точность
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| БЕРТ | 86,0 (85,5) | 84,8 (84,6) | 102 м |
| Берт-УВМ | 86,1 (85,6) | 85,2 (84,9) | 102 м |
| Bert-WWM-Ext | 86,4 (85,5) | 85,3 (84,8) | 102 м |
| Роберта-Вум-Экс | 86,0 (85,4) | 85,0 (84,6) | 102 м |
| RBT3 | 84.1 | 83,3 | 38м |
| Электра-Смалл | 83,5 (83,0) | 82,0 (81,7) | 12 м |
| Electra-180g-Small | 83,3 | 82.1 | 12 м |
| Electra-Small-Ex | 84,0 | 82,6 | 25 м |
| Electra-180g-Small-Ex | 84,6 | 83,4 | 25 м |
| Электрабаза | 84,8 (84,7) | 84,5 (84,0) | 102 м |
| Electra-180g-база | 85,8 | 84,5 | 102 м |
| Электро-широкий | 86.7 | 85,1 | 324 м |
| Electra-180g-Large | 86.4 | 85,4 | 324 м |
Мы проверили судебную Electra, используя данные судебного рассмотрения CAIL 2018 года. Скорость обучения малым/базовым/крупным: 5E-4/3E-4/1E-4 соответственно. Индикатор оценки: точность
| Модель | Разработка набора | Тестовый набор | Параметр Количество |
|---|---|---|---|
| Электра-Смалл | 78.84 | 76.35 | 12 м |
| Легальная электромагнитная | 79,60 | 77.03 | 12 м |
| Электрабаза | 80.94 | 78.41 | 102 м |
| легальная электроэлектронная база | 81.71 | 79.17 | 102 м |
| Электро-широкий | 81.53 | 78.97 | 324 м |
| легальный электроэлектровый | 82,60 | 79,89 | 324 м |
Пользователи могут выполнять более низкую настройку на основе опубликованной предварительно обученной модели китайской электро-электро. Здесь мы представим только самое основное использование. Для более подробного использования, пожалуйста, обратитесь к официальному введению Electra.
В этом примере мы использовали модель ELECTRA-small для точной настройки задачи CMRC 2018, и соответствующие шаги следующие. Предполагая,
data-dir : Рабочий корневой каталог может быть установлен в соответствии с фактической ситуацией.model-name : имя модели, в данном случае electra-small .task-name : имя задачи, в данном случае cmrc2018 . Код в этом каталоге адаптировался к шести вышеупомянутым китайским задачам, а task-name являются cmrc2018 , drcd , xnli , chnsenticorp , lcqmc и bqcorpus . В разделе загрузки модели загрузите модель Electra-Small и распаковните ее в ${data-dir}/models/${model-name} . Этот каталог должен содержать electra_model.* , vocab.txt , checkpoint и в общей сложности 5 файлов.
Загрузите набор обучения и разработки CMRC 2018 и переименовать его в train.json и dev.json . Поместите два файла в ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Среди них были представлены data-dir и model-name выше. hparams - это словарь JSON. В этом примере params_cmrc2018.json содержит гиперпараметры, связанные с тонкой настройкой, такие как:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}В приведенном выше файле JSON мы перечисляем только некоторые из наиболее важных параметров. Для полного списка параметров, пожалуйста, см. Configure_finenetung.py.
После завершения операции,
cmrc2018_dev_preds.json сохраняется в ${data-dir}/results/${task-name}_qa/ . Вы можете вызвать внешние сценарии оценки, чтобы получить окончательные результаты оценки, например: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 В: Как установить скорость обучения модели Electra при тонкой настройке нисходящих задач?
A: Мы рекомендуем использовать скорость обучения, используемую исходной статьей в качестве начальной базовой линии (Small IS 3E-4, база-1e-4), а затем отладка с соответствующим добавлением и снижением скорости обучения. Следует отметить, что по сравнению с такими моделями, как Bert и Roberta, скорость обучения Electra является относительно большой.
В: Есть ли авторские права Pytorch?
A: Да, скачать модель.
В: Можно ли обмен предварительно обучением данных?
A: К сожалению, нет.
В: Планы на будущее?
A: Пожалуйста, следите за обновлениями.
Если контент в этом каталоге полезен для вашей исследовательской работы, пожалуйста, не стесняйтесь цитировать следующую статью в статье.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Добро пожаловать, чтобы следить за официальным официальным отчетом WeChat об Объединенной лаборатории Iflytek, чтобы узнать о последних технических тенденциях.

Прежде чем отправить вопрос:


