Chinese ELECTRA
1.0.0
Chinese Description | English

This project is based on the official ELECTRA of Google & Stanford University: https://github.com/google-research/electra
Chinese LERT | Chinese English PERT | Chinese MacBERT | Chinese ELECTRA | Chinese XLNet | Chinese BERT | Knowledge distillation tool TextBrewer | Model cutting tool TextPruner
See more resources released by iFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/HFL-Anthology
2023/3/28 Open source Chinese LLaMA&Alpaca big model, which can be quickly deployed and experienced on PC, view: https://github.com/ymcui/Chinese-LLaMA-Alpaca
2022/10/29 We propose a pre-trained model LERT that integrates linguistic information. View: https://github.com/ymcui/LERT
2022/3/30 We open source a new pre-trained model PERT. View: https://github.com/ymcui/PERT
2021/12/17 IFLYTEK Joint Laboratory launches the model cutting toolkit TextPruner. View: https://github.com/airaria/TextPruner
2021/10/24 IFLYTEK Joint Laboratory released a pre-trained model CINO for ethnic minority languages. View: https://github.com/ymcui/Chinese-Minority-PLM
2021/7/21 "Natural Language Processing: Methods based on Pre-training Models" written by many scholars from Harbin Institute of Technology SCIR has been published, and everyone is welcome to purchase it.
2020/12/13 Based on large-scale legal document data, we trained Chinese ELECTRA series models for the judicial field to view model downloads, and judicial task effects.
2020/9/15 Our paper "Revisiting Pre-Trained Models for Chinese Natural Language Processing" was hired as a long article by Findings of EMNLP.
2020/8/27 IFL Joint Laboratory topped the list in the GLUE general natural language understanding evaluation, check the GLUE list, news.
2020/5/29 Chinese ELECTRA-large/small-ex has been released. Please check the model download. Currently, only Google Drive download address is available, so please understand.
2020/4/7 PyTorch users can load the model through ?Transformers to view the fast loading.
2020/3/31 The models published in this directory have been connected to PaddlePaddleHub for viewing and loading quickly.
2020/3/25 Chinese ELECTRA-small/base has been released, please check the model download.
| chapter | describe |
|---|---|
| Introduction | Introduction to the basic principles of ELECTRA |
| Model download | Download Chinese ELECTRA pre-trained model |
| Quick loading | How to use Transformers and PaddleHub quickly loading models |
| Baseline system effects | Effects of Chinese baseline system: reading comprehension, text classification, etc. |
| How to use | Detailed usage of the model |
| FAQ | FAQs and Answers |
| Quote | Technical Reports in this directory |
ELECTRA proposes a new pre-training framework that includes two parts: Generator and Discriminator .
After the pre-training phase is over, we only use Discriminator as the base model for downstream tasks fine-tuned.
For more detailed content, please refer to the ELECTRA paper: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
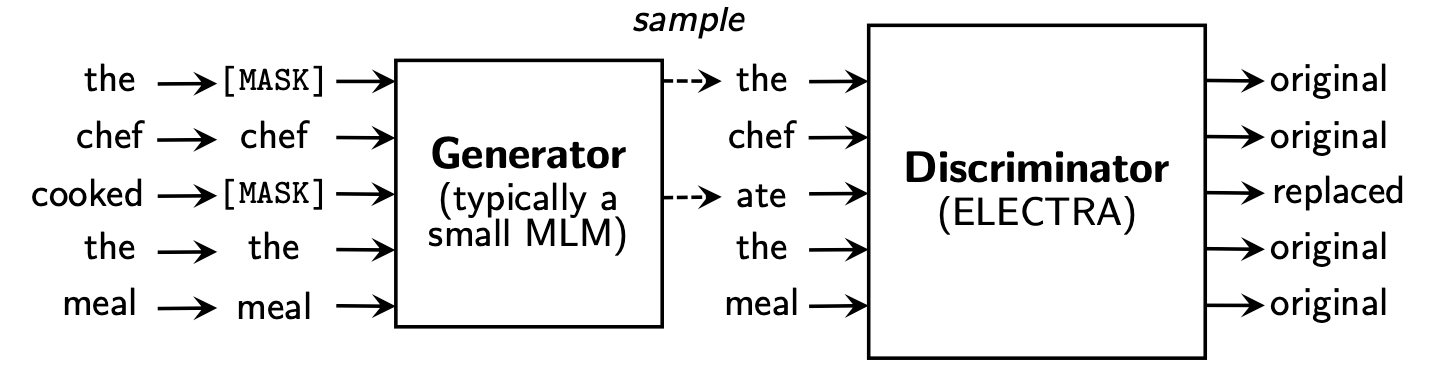
This directory contains the following models and currently only provides TensorFlow version weights.
ELECTRA-large, Chinese : 24-layer, 1024-hidden, 16-heads, 324M parametersELECTRA-base, Chinese : 12-layer, 768-hidden, 12-heads, 102M parametersELECTRA-small-ex, Chinese : 24-layer, 256-hidden, 4-heads, 25M parametersELECTRA-small, Chinese : 12-layer, 256-hidden, 4-heads, 12M parameters | Model abbreviation | Google Download | Baidu Netdisk download | Compressed package size |
|---|---|---|---|
ELECTRA-180g-large, Chinese | TensorFlow | TensorFlow (password 2v5r) | 1G |
ELECTRA-180g-base, Chinese | TensorFlow | TensorFlow (password 3vg1) | 383M |
ELECTRA-180g-small-ex, Chinese | TensorFlow | TensorFlow (password 93n8) | 92M |
ELECTRA-180g-small, Chinese | TensorFlow | TensorFlow (password k9iu) | 46M |
| Model abbreviation | Google Download | Baidu Netdisk download | Compressed package size |
|---|---|---|---|
ELECTRA-large, Chinese | TensorFlow | TensorFlow (password 1e14) | 1G |
ELECTRA-base, Chinese | TensorFlow | TensorFlow (password f32j) | 383M |
ELECTRA-small-ex, Chinese | TensorFlow | TensorFlow (password gfb1) | 92M |
ELECTRA-small, Chinese | TensorFlow | TensorFlow (password 1r4r) | 46M |
| Model abbreviation | Google Download | Baidu Netdisk download | Compressed package size |
|---|---|---|---|
legal-ELECTRA-large, Chinese | TensorFlow | TensorFlow (password q4gv) | 1G |
legal-ELECTRA-base, Chinese | TensorFlow | TensorFlow (password 8gcv) | 383M |
legal-ELECTRA-small, Chinese | TensorFlow | TensorFlow (password kmrj) | 46M |
If you need the PyTorch version, please convert it yourself through the conversion script converted_electra_original_tf_checkpoint_to_pytorch.py provided by Transformers. If you need configuration files, you can enter the config folder in this directory to search.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorOr directly download PyTorch through the official website of huggingface: https://huggingface.co/hfl
Method: Click any model you want to download → Pull to the bottom and click "List all files in model" → Download bin and json files in the pop-up box.
It is recommended to use Baidu Netdisk download points in mainland China, while it is recommended to use Google download points in overseas users. Taking the TensorFlow version of ELECTRA-small, Chinese as an example, after downloading, decompressing the zip file to obtain the following file.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
We used large-scale Chinese wikis and general text to train the ELECTRA model, with the total token number reaching 5.4B, which is consistent with the RoBERTa-wwm-ext series model. In terms of vocabulary list, it uses Google's original BERT WordPiece vocabulary list, including 21,128 tokens. Other details and hyperparameters are as follows (the unmentioned parameters remain default):
ELECTRA-large : 24 layers, hidden layer 1024, 16 attention heads, learning rate 1e-4, batch96, maximum length 512, training 2M stepsELECTRA-base : 12 layers, hidden layer 768, 12 attention heads, learning rate 2e-4, batch256, maximum length 512, training 1M stepELECTRA-small-ex : 24 layers, hidden layer 256, 4 attention heads, learning rate 5e-4, batch384, maximum length 512, 2M steps of trainingELECTRA-small : 12 layers, hidden layer 256, 4 attention heads, learning rate 5e-4, batch1024, maximum length 512, training 1M step Huggingface-Transformers version 2.8.0 has officially supported the ELECTRA model and can be called through the following commands.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) The corresponding list of MODEL_NAME is as follows:
| Model name | Components | MODEL_NAME |
|---|---|---|
| ELECTRA-180g-large, Chinese | discriminator | hfl/chinese-electra-180g-large-discriminator |
| ELECTRA-180g-large, Chinese | Generator | hfl/chinese-electra-180g-large-generator |
| ELECTRA-180g-base, Chinese | discriminator | hfl/chinese-electra-180g-base-discriminator |
| ELECTRA-180g-base, Chinese | Generator | hfl/chinese-electra-180g-base-generator |
| ELECTRA-180g-small-ex, Chinese | discriminator | hfl/chinese-electra-180g-small-ex-discriminator |
| ELECTRA-180g-small-ex, Chinese | Generator | hfl/chinese-electra-180g-small-ex-generator |
| ELECTRA-180g-small, Chinese | discriminator | hfl/chinese-electra-180g-small-discriminator |
| ELECTRA-180g-small, Chinese | Generator | hfl/chinese-electra-180g-small-generator |
| ELECTRA-large, Chinese | discriminator | hfl/chinese-electra-large-discriminator |
| ELECTRA-large, Chinese | Generator | hfl/chinese-electra-large-generator |
| ELECTRA-base, Chinese | discriminator | hfl/chinese-electra-base-discriminator |
| ELECTRA-base, Chinese | Generator | hfl/chinese-electra-base-generator |
| ELECTRA-small-ex, Chinese | discriminator | hfl/chinese-electra-small-ex-discriminator |
| ELECTRA-small-ex, Chinese | Generator | hfl/chinese-electra-small-ex-generator |
| ELECTRA-small, Chinese | discriminator | hfl/chinese-electra-small-discriminator |
| ELECTRA-small, Chinese | Generator | hfl/chinese-electra-small-generator |
Judicial Domain Version:
| Model name | Components | MODEL_NAME |
|---|---|---|
| legal-ELECTRA-large, Chinese | discriminator | hfl/chinese-legal-electra-large-discriminator |
| legal-ELECTRA-large, Chinese | Generator | hfl/chinese-legal-electra-large-generator |
| legal-ELECTRA-base, Chinese | discriminator | hfl/chinese-legal-electra-base-discriminator |
| legal-ELECTRA-base, Chinese | Generator | hfl/chinese-legal-electra-base-generator |
| legal-ELECTRA-small, Chinese | discriminator | hfl/chinese-legal-electra-small-discriminator |
| legal-ELECTRA-small, Chinese | Generator | hfl/chinese-legal-electra-small-generator |
Relying on PaddleHub, we only need one line of code to complete the download and installation of the model, and more than ten lines of code can complete the tasks of text classification, sequence annotation, reading comprehension and other tasks.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
The corresponding list of MODULE_NAME is as follows:
| Model name | MODULE_NAME |
|---|---|
| ELECTRA-base, Chinese | chinese-electra-base |
| ELECTRA-small, Chinese | chinese-electra-small |
We compared the effects of ELECTRA-small/base with BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext , and RBT3 , including the following six tasks:
For the ELECTRA-small/base model, we use the default learning rates of 3e-4 and 1e-4 in the original paper. It should be noted that we have not performed parameter adjustments for any tasks, so further performance improvements may be achieved by adjusting hyperparameters such as learning rate. In order to ensure the reliability of the results, for the same model, we trained 10 times using different random seeds to report the maximum and average values of model performance (the average values in brackets).
The CMRC 2018 data set is Chinese machine reading comprehension data released by the joint laboratory of Harbin Institute of Technology. According to a given question, the system needs to extract fragments from the chapter as the answer, in the same form as SQuAD. Evaluation indicators are: EM / F1
| Model | Development Set | Test set | Challenge Set | Parameter quantity |
|---|---|---|---|---|
| BERT-base | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102M |
| BERT-wwm | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102M |
| BERT-wwm-ext | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102M |
| RoBERTa-wwm-ext | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102M |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38M |
| ELECTRA-small | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12M |
| ELECTRA-180g-small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12M |
| ELECTRA-small-ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25M |
| ELECTRA-180g-small-ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25M |
| ELECTRA-base | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102M |
| ELECTRA-180g-base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102M |
| ELECTRA-large | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324M |
| ELECTRA-180g-large | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324M |
The DRCD dataset was released by Delta Research Institute, Taiwan, China. Its form is the same as SQuAD and is an extracted reading comprehension dataset based on traditional Chinese. Evaluation indicators are: EM / F1
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| BERT-base | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102M |
| BERT-wwm | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102M |
| BERT-wwm-ext | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102M |
| RoBERTa-wwm-ext | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102M |
| RBT3 | 76.3 / 84.9 | 75.0 / 83.9 | 38M |
| ELECTRA-small | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12M |
| ELECTRA-180g-small | 83.5 / 89.2 | 82.9 / 88.7 | 12M |
| ELECTRA-small-ex | 84.0 / 89.5 | 83.3 / 89.1 | 25M |
| ELECTRA-180g-small-ex | 87.3 / 92.3 | 86.5 / 91.3 | 25M |
| ELECTRA-base | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102M |
| ELECTRA-180g-base | 89.6 / 94.2 | 88.9 / 93.7 | 102M |
| ELECTRA-large | 88.8 / 93.3 | 88.8 / 93.6 | 324M |
| ELECTRA-180g-large | 90.1 / 94.8 | 90.5 / 94.7 | 324M |
In the natural language inference task, we adopt XNLI data, which requires the text to be divided into three categories: entailment , neutral , and contradictory . Evaluation indicator is: Accuracy
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| BERT-base | 77.8 (77.4) | 77.8 (77.5) | 102M |
| BERT-wwm | 79.0 (78.4) | 78.2 (78.0) | 102M |
| BERT-wwm-ext | 79.4 (78.6) | 78.7 (78.3) | 102M |
| RoBERTa-wwm-ext | 80.0 (79.2) | 78.8 (78.3) | 102M |
| RBT3 | 72.2 | 72.3 | 38M |
| ELECTRA-small | 73.3 (72.5) | 73.1 (72.6) | 12M |
| ELECTRA-180g-small | 74.6 | 74.6 | 12M |
| ELECTRA-small-ex | 75.4 | 75.8 | 25M |
| ELECTRA-180g-small-ex | 76.5 | 76.6 | 25M |
| ELECTRA-base | 77.9 (77.0) | 78.4 (77.8) | 102M |
| ELECTRA-180g-base | 79.6 | 79.5 | 102M |
| ELECTRA-large | 81.5 | 81.0 | 324M |
| ELECTRA-180g-large | 81.2 | 80.4 | 324M |
In the sentiment analysis task, the binary emotion classification dataset ChnSentiCorp . Evaluation indicator is: Accuracy
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| BERT-base | 94.7 (94.3) | 95.0 (94.7) | 102M |
| BERT-wwm | 95.1 (94.5) | 95.4 (95.0) | 102M |
| BERT-wwm-ext | 95.4 (94.6) | 95.3 (94.7) | 102M |
| RoBERTa-wwm-ext | 95.0 (94.6) | 95.6 (94.8) | 102M |
| RBT3 | 92.8 | 92.8 | 38M |
| ELECTRA-small | 92.8 (92.5) | 94.3 (93.5) | 12M |
| ELECTRA-180g-small | 94.1 | 93.6 | 12M |
| ELECTRA-small-ex | 92.6 | 93.6 | 25M |
| ELECTRA-180g-small-ex | 92.8 | 93.4 | 25M |
| ELECTRA-base | 93.8 (93.0) | 94.5 (93.5) | 102M |
| ELECTRA-180g-base | 94.3 | 94.8 | 102M |
| ELECTRA-large | 95.2 | 95.3 | 324M |
| ELECTRA-180g-large | 94.8 | 95.2 | 324M |
The following two data sets need to classify a sentence pair to determine whether the semantics of the two sentences are the same (binary classification task).
LCQMC was released by the Intelligent Computing Research Center of Harbin Institute of Technology Shenzhen Graduate School. Evaluation indicator is: Accuracy
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| BERT | 89.4 (88.4) | 86.9 (86.4) | 102M |
| BERT-wwm | 89.4 (89.2) | 87.0 (86.8) | 102M |
| BERT-wwm-ext | 89.6 (89.2) | 87.1 (86.6) | 102M |
| RoBERTa-wwm-ext | 89.0 (88.7) | 86.4 (86.1) | 102M |
| RBT3 | 85.3 | 85.1 | 38M |
| ELECTRA-small | 86.7 (86.3) | 85.9 (85.6) | 12M |
| ELECTRA-180g-small | 86.6 | 85.8 | 12M |
| ELECTRA-small-ex | 87.5 | 86.0 | 25M |
| ELECTRA-180g-small-ex | 87.6 | 86.3 | 25M |
| ELECTRA-base | 90.2 (89.8) | 87.6 (87.3) | 102M |
| ELECTRA-180g-base | 90.2 | 87.1 | 102M |
| ELECTRA-large | 90.7 | 87.3 | 324M |
| ELECTRA-180g-large | 90.3 | 87.3 | 324M |
BQ Corpus is released by the Intelligent Computing Research Center of Harbin Institute of Technology Shenzhen Graduate School and is a data set for the banking field. Evaluation indicator is: Accuracy
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| BERT | 86.0 (85.5) | 84.8 (84.6) | 102M |
| BERT-wwm | 86.1 (85.6) | 85.2 (84.9) | 102M |
| BERT-wwm-ext | 86.4 (85.5) | 85.3 (84.8) | 102M |
| RoBERTa-wwm-ext | 86.0 (85.4) | 85.0 (84.6) | 102M |
| RBT3 | 84.1 | 83.3 | 38M |
| ELECTRA-small | 83.5 (83.0) | 82.0 (81.7) | 12M |
| ELECTRA-180g-small | 83.3 | 82.1 | 12M |
| ELECTRA-small-ex | 84.0 | 82.6 | 25M |
| ELECTRA-180g-small-ex | 84.6 | 83.4 | 25M |
| ELECTRA-base | 84.8 (84.7) | 84.5 (84.0) | 102M |
| ELECTRA-180g-base | 85.8 | 84.5 | 102M |
| ELECTRA-large | 86.7 | 85.1 | 324M |
| ELECTRA-180g-large | 86.4 | 85.4 | 324M |
We tested the judicial ELECTRA using the CAIL 2018 Judicial Review’s crime prediction data. The learning rates of small/base/large are: 5e-4/3e-4/1e-4 respectively. Evaluation indicator is: Accuracy
| Model | Development Set | Test set | Parameter quantity |
|---|---|---|---|
| ELECTRA-small | 78.84 | 76.35 | 12M |
| legal-ELECTRA-small | 79.60 | 77.03 | 12M |
| ELECTRA-base | 80.94 | 78.41 | 102M |
| legal-ELECTRA-base | 81.71 | 79.17 | 102M |
| ELECTRA-large | 81.53 | 78.97 | 324M |
| legal-ELECTRA-large | 82.60 | 79.89 | 324M |
Users can perform downstream tasks fine-tuning based on the published Chinese ELECTRA pre-trained model above. Here we will only introduce the most basic usage. For more detailed usage, please refer to the official introduction of ELECTRA.
In this example, we used ELECTRA-small model to fine-tune on the CMRC 2018 task, and the relevant steps are as follows. Assuming,
data-dir : The working root directory can be set according to actual situation.model-name : model name, in this case electra-small .task-name : task name, in this case cmrc2018 . The code in this directory has adapted to the above six Chinese tasks, and task-name are cmrc2018 , drcd , xnli , chnsenticorp , lcqmc , and bqcorpus . In the Model Download section, download the ELECTRA-small model and decompress it to ${data-dir}/models/${model-name} . This directory should contain electra_model.* , vocab.txt , checkpoint , and a total of 5 files.
Download the CMRC 2018 training and development set and rename it to train.json and dev.json . Put two files in ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Among them, data-dir and model-name have been introduced above. hparams is a JSON dictionary. In this example, params_cmrc2018.json contains fine-tuning related hyperparameters, such as:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}In the above JSON file, we only list some of the most important parameters. For the complete parameter list, please refer to configure_finenetung.py.
After the operation is completed,
cmrc2018_dev_preds.json is saved in ${data-dir}/results/${task-name}_qa/ . You can call external evaluation scripts to get the final evaluation results, for example: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 Q: How to set the learning rate of the ELECTRA model when fine-tuning downstream tasks?
A: We recommend using the learning rate used by the original paper as the initial baseline (small is 3e-4, base is 1e-4) and then debugging with appropriate addition and decrease of the learning rate. It should be noted that compared with models such as BERT and RoBERTa, the learning rate of ELECTRA is relatively large.
Q: Are there any PyTorch copyrights?
A: Yes, download the model.
Q: Can pre-training data be shared?
A: Unfortunately, no.
Q: Future plans?
A: Please stay tuned.
If the content in this directory is helpful to your research work, please feel free to quote the following paper in the paper.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Welcome to follow the official WeChat official account of IFLYTEK Joint Laboratory to learn about the latest technical trends.

Before you submit an issue:


