Chinese ELECTRA
1.0.0
Deskripsi Cina | Bahasa inggris

Proyek ini didasarkan pada elektra resmi Universitas Google & Stanford: https://github.com/google-research/electra
Lert Cina | Bahasa Inggris Tiongkok PERT | Macbert Cina | China Electra | Xlnet Cina | Bert Cina | Alat Distilasi Pengetahuan TextBrewer | Model Cutting Tool TextPruner
Lihat lebih banyak sumber daya yang dirilis oleh IFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model, yang dapat dengan cepat digunakan dan dialami di PC, Lihat: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Kami mengusulkan model pra-terlatih yang mengintegrasikan informasi linguistik. Lihat: https://github.com/ymcui/lert
2022/3/30 Kami membuka sumber model pra-terlatih baru. Lihat: https://github.com/ymcui/pert
2021/12/17 Laboratorium Joint IFLYTEK Meluncurkan Model Cutting Toolkit TextPruner. Lihat: https://github.com/airaria/textpruner
2021/10/24 Laboratorium Gabungan IFLYTEK merilis model cino pra-terlatih untuk bahasa etnis minoritas. Lihat: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "Pemrosesan Bahasa Alami: Metode Berdasarkan Model Pra-Pelatihan" yang ditulis oleh banyak sarjana dari Harbin Institute of Technology SCIR telah diterbitkan, dan semua orang dipersilakan untuk membelinya.
2020/12/13 Berdasarkan data dokumen hukum berskala besar, kami melatih model seri Electra China untuk bidang peradilan untuk melihat unduhan model, dan efek tugas yudisial.
2020/9/15 Makalah kami "Meninjau kembali model pra-terlatih untuk pemrosesan bahasa alami Cina" dipekerjakan sebagai artikel panjang dengan temuan EMNLP.
2020/8/27 IFL Joint Laboratory menduduki puncak daftar dalam evaluasi pemahaman bahasa alami umum, periksa daftar lem, berita.
2020/5/29 China Electra-Large/Small-Ex telah dirilis. Silakan periksa unduhan model. Saat ini, hanya alamat unduhan Google Drive yang tersedia, jadi harap dipahami.
2020/4/7 Pengguna Pytorch dapat memuat model melalui? Transformers untuk melihat pemuatan cepat.
2020/3/31 Model yang diterbitkan dalam direktori ini telah terhubung ke Paddlepaddlehub untuk dilihat dan dimuat dengan cepat.
2020/3/25 China Electra-Small/Base telah dirilis, silakan periksa model unduhan.
| bab | menggambarkan |
|---|---|
| Perkenalan | Pengantar Prinsip -Prinsip Dasar Electra |
| Download model | Unduh Model Pra-Latihan China Electra |
| Pemuatan cepat | Cara menggunakan transformator dan paddlehub dengan cepat memuat model |
| Efek sistem dasar | Efek sistem dasar Cina: pemahaman membaca, klasifikasi teks, dll. |
| Cara menggunakan | Penggunaan model terperinci |
| FAQ | FAQ dan Jawaban |
| Mengutip | Laporan Teknis di Direktori Ini |
Electra mengusulkan kerangka kerja pra-pelatihan baru yang mencakup dua bagian: generator dan diskriminator .
Setelah fase pra-pelatihan selesai, kami hanya menggunakan diskriminator sebagai model dasar untuk tugas hilir disempurnakan.
Untuk konten yang lebih rinci, silakan merujuk ke kertas electra: Electra: pra-pelatihan teks enkoder sebagai diskriminator daripada generator
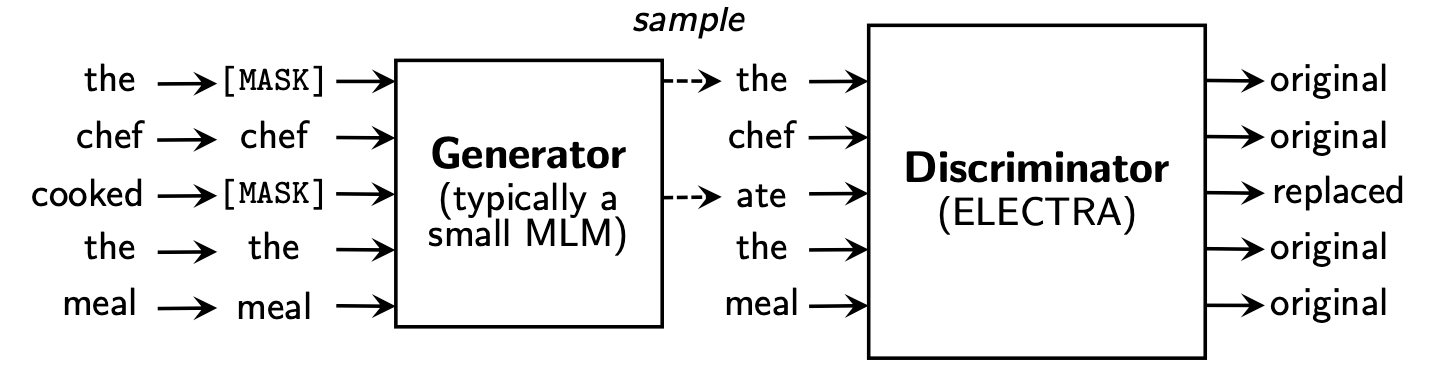
Direktori ini berisi model -model berikut dan saat ini hanya menyediakan bobot versi TensorFlow.
ELECTRA-large, Chinese : 24-lapis, 1024-tersembunyi, 16-heads, 324m parameterELECTRA-base, Chinese : 12-layer, 768 tersembunyi, 12-head, parameter 102mELECTRA-small-ex, Chinese : 24-lapis, 256-tersembunyi, 4-head, parameter 25mELECTRA-small, Chinese : 12-layer, 256 tersembunyi, 4-head, parameter 12m | Singkatan model | Download Google | Unduh Baidu Netdisk | Ukuran paket terkompresi |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | TensorFlow (Kata Sandi 2V5R) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | TensorFlow (Kata Sandi 3VG1) | 383m |
ELECTRA-180g-small-ex, Chinese | Tensorflow | TensorFlow (Kata Sandi 93N8) | 92m |
ELECTRA-180g-small, Chinese | Tensorflow | TensorFlow (Kata Sandi K9IU) | 46m |
| Singkatan model | Download Google | Unduh Baidu Netdisk | Ukuran paket terkompresi |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | TensorFlow (Kata Sandi 1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | TensorFlow (Kata Sandi F32J) | 383m |
ELECTRA-small-ex, Chinese | Tensorflow | TensorFlow (Kata Sandi GFB1) | 92m |
ELECTRA-small, Chinese | Tensorflow | TensorFlow (Kata Sandi 1R4R) | 46m |
| Singkatan model | Download Google | Unduh Baidu Netdisk | Ukuran paket terkompresi |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | TensorFlow (Kata Sandi Q4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | TensorFlow (Kata Sandi 8GCV) | 383m |
legal-ELECTRA-small, Chinese | Tensorflow | TensorFlow (Kata sandi kmrj) | 46m |
Jika Anda memerlukan versi Pytorch, harap konversinya sendiri melalui skrip konversi Converted_electra_original_tf_checkpoint_to_pytorch.py disediakan oleh Transformers. Jika Anda memerlukan file konfigurasi, Anda dapat memasukkan folder konfigurasi di direktori ini untuk mencari.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorAtau langsung mengunduh pytorch melalui situs web resmi Huggingface: https://huggingface.co/hfl
Metode: Klik model apa pun yang ingin Anda unduh → Tarik ke bawah dan klik "Daftar semua file dalam model" → Unduh file bin dan json di kotak pop-up.
Disarankan untuk menggunakan poin unduhan Baidu Netdisk di daratan Cina, sementara disarankan untuk menggunakan poin unduhan Google pada pengguna luar negeri. Mengambil versi TensorFlow dari ELECTRA-small, Chinese sebagai contoh, setelah mengunduh, mendekompresi file zip untuk mendapatkan file berikut.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Kami menggunakan wiki Cina berskala besar dan teks umum untuk melatih model electra, dengan jumlah token total mencapai 5.4B, yang konsisten dengan model seri Roberta-WWM-EXT. Dalam hal daftar kosakata, ia menggunakan daftar kosakata Bert Wordpiece asli Google, termasuk 21.128 token. Detail dan hyperparameter lainnya adalah sebagai berikut (parameter yang tidak disebutkan tetap default):
ELECTRA-large : 24 Lapisan, Lapisan Tersembunyi 1024, 16 Kepala Perhatian, Tingkat Pembelajaran 1E-4, Batch96, Panjang Maksimum 512, Pelatihan Langkah 2mELECTRA-base : 12 Lapisan, Lapisan Tersembunyi 768, 12 Kepala Perhatian, Tingkat Pembelajaran 2E-4, Batch256, Panjang Maksimum 512, Pelatihan 1m LangkahELECTRA-small-ex : 24 Lapisan, Lapisan Tersembunyi 256, 4 Kepala Perhatian, Tingkat Pembelajaran 5E-4, Batch384, Panjang Maksimum 512, 2M Langkah PelatihanELECTRA-small : 12 Lapisan, Lapisan Tersembunyi 256, 4 Kepala Perhatian, Tingkat Pembelajaran 5E-4, Batch1024, Panjang Maksimum 512, Pelatihan 1m Langkah HuggingFace-Transformers Versi 2.8.0 telah secara resmi mendukung model Electra dan dapat dipanggil melalui perintah berikut.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) Daftar MODEL_NAME yang sesuai adalah sebagai berikut:
| Nama model | Komponen | Model_name |
|---|---|---|
| Electra-180G-Large, Cina | Diskriminator | HFL/China-electra-180g-Large-Discriminator |
| Electra-180G-Large, Cina | Generator | HFL/China-electra-180g-Large-generator |
| Electra-180g-base, Cina | Diskriminator | HFL/China-electra-180g-base-diskriminator |
| Electra-180g-base, Cina | Generator | HFL/China-electra-180g-base-generator |
| Electra-180g-Small-Ex, Cina | Diskriminator | HFL/China-electra-180g-small-ex-disriminator |
| Electra-180g-Small-Ex, Cina | Generator | HFL/China-electra-180g-small-ex-generator |
| Electra-180g-Small, Cina | Diskriminator | HFL/China-electra-180g-small-diskriminator |
| Electra-180g-Small, Cina | Generator | HFL/China-electra-180g-small-generator |
| Electra-Large, Cina | Diskriminator | HFL/China-Electra-Large-Discriminator |
| Electra-Large, Cina | Generator | HFL/China-Electra-Large-Generator |
| Electra-base, Cina | Diskriminator | HFL/China-electra-Base-Discriminator |
| Electra-base, Cina | Generator | HFL/China-ELECTRA-BASE-generator |
| Electra-Small-Ex, Cina | Diskriminator | HFL/China-Electra-Small-Ex-Discriminator |
| Electra-Small-Ex, Cina | Generator | HFL/China-Electra-Small-Ex-Generator |
| Electra-Small, Cina | Diskriminator | HFL/China-Electra-Small-Discriminator |
| Electra-Small, Cina | Generator | HFL/China-Electra-Small-Generator |
Versi domain yudisial:
| Nama model | Komponen | Model_name |
|---|---|---|
| Legal-Electra-Large, Cina | Diskriminator | HFL/Cina-legal-electra-large-diskriminator |
| Legal-Electra-Large, Cina | Generator | HFL/China-legal-electra-large-generator |
| Legal-Electra-Base, Cina | Diskriminator | HFL/Cina-legal-electra-base-diskriminator |
| Legal-Electra-Base, Cina | Generator | HFL/China-legal-electra-base-generator |
| Legal-Electra-Small, Cina | Diskriminator | HFL/Cina-Legal-Electra-Small-Discriminator |
| Legal-Electra-Small, Cina | Generator | HFL/China-Legal-Electra-Small-Generator |
Mengandalkan paddlehub, kami hanya perlu satu baris kode untuk menyelesaikan unduhan dan instalasi model, dan lebih dari sepuluh baris kode dapat menyelesaikan tugas klasifikasi teks, anotasi urutan, pemahaman membaca dan tugas lainnya.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
Daftar MODULE_NAME yang sesuai adalah sebagai berikut:
| Nama model | Module_name |
|---|---|
| Electra-base, Cina | BASA-ELECTRA-BASA |
| Electra-Small, Cina | China-Electra-Small |
Kami membandingkan efek ELECTRA-small/base dengan BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext , dan RBT3 , termasuk enam tugas berikut:
Untuk model Electra-Small/Base, kami menggunakan tingkat pembelajaran default 3e-4 dan 1e-4 di kertas asli. Perlu dicatat bahwa kami belum melakukan penyesuaian parameter untuk setiap tugas, sehingga peningkatan kinerja lebih lanjut dapat dicapai dengan menyesuaikan hiperparameter seperti tingkat pembelajaran. Untuk memastikan keandalan hasil, untuk model yang sama, kami berlatih 10 kali menggunakan benih acak yang berbeda untuk melaporkan nilai maksimum dan rata -rata kinerja model (nilai rata -rata dalam kurung).
Kumpulan data CMRC 2018 adalah data pemahaman pembacaan mesin Cina yang dirilis oleh laboratorium bersama Institut Teknologi Harbin. Menurut pertanyaan yang diberikan, sistem perlu mengekstrak fragmen dari bab sebagai jawaban, dalam bentuk yang sama dengan skuad. Indikator evaluasi adalah: EM / F1
| Model | Set pengembangan | Set tes | Set Tantangan | Kuantitas parameter |
|---|---|---|---|---|
| Bert-base | 65.5 (64.4) / 84.5 (84.0) | 70.0 (68.7) / 87.0 (86.3) | 18.6 (17.0) / 43.3 (41.3) | 102m |
| Bert-WWM | 66.3 (65.0) / 85.6 (84.7) | 70.5 (69.1) / 87.4 (86.7) | 21.0 (19.3) / 47.0 (43.9) | 102m |
| BERT-WWM-EXT | 67.1 (65.6) / 85.7 (85.0) | 71.4 (70.0) / 87.7 (87.0) | 24.0 (20.0) / 47.3 (44.6) | 102m |
| Roberta-WWM-EXT | 67.4 (66.5) / 87.2 (86.5) | 72.6 (71.4) / 89.4 (88.8) | 26.2 (24.6) / 51.0 (49.1) | 102m |
| Rbt3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Electra-Small | 63.4 (62.9) / 80.8 (80.2) | 67.8 (67.4) / 83.4 (83.0) | 16.3 (15.4) / 37.2 (35.8) | 12m |
| Electra-180g-Small | 63.8 / 82.7 | 68.5 / 85.2 | 15.1 / 35.8 | 12m |
| Electra-Small-Ex | 66.4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| Electra-180g-small-ex | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| Basis elektra | 68.4 (68.0) / 84.8 (84.6) | 73.1 (72.7) / 87.1 (86.9) | 22.6 (21.7) / 45.0 (43.8) | 102m |
| Electra-180G-BASE | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102m |
| Electra-Large | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324m |
| Electra-180G-Large | 68.5 / 86.2 | 73.5 / 88.5 | 21.8 / 42.9 | 324m |
Dataset DRCD dirilis oleh Delta Research Institute, Taiwan, Cina. Bentuknya sama dengan skuad dan merupakan dataset pemahaman membaca yang diekstraksi berdasarkan bahasa Cina tradisional. Indikator evaluasi adalah: EM / F1
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Bert-base | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) | 102m |
| Bert-WWM | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) | 102m |
| BERT-WWM-EXT | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) | 102m |
| Roberta-WWM-EXT | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) | 102m |
| Rbt3 | 76.3 / 84.9 | 75.0 / 83.9 | 38m |
| Electra-Small | 79.8 (79.4) / 86.7 (86.4) | 79.0 (78.5) / 85.8 (85.6) | 12m |
| Electra-180g-Small | 83.5 / 89.2 | 82.9 / 88.7 | 12m |
| Electra-Small-Ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| Electra-180g-small-ex | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| Basis elektra | 87.5 (87.0) / 92.5 (92.3) | 86.9 (86.6) / 91.8 (91.7) | 102m |
| Electra-180G-BASE | 89.6 / 94.2 | 88.9 / 93.7 | 102m |
| Electra-Large | 88.8 / 93.3 | 88.8 / 93.6 | 324m |
| Electra-180G-Large | 90.1 / 94.8 | 90.5 / 94.7 | 324m |
Dalam tugas inferensi bahasa alami, kami mengadopsi data XNLI , yang mengharuskan teks dibagi menjadi tiga kategori: entailment , neutral , dan contradictory . Indikator evaluasi adalah: akurasi
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Bert-base | 77.8 (77.4) | 77.8 (77.5) | 102m |
| Bert-WWM | 79.0 (78.4) | 78.2 (78.0) | 102m |
| BERT-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) | 102m |
| Roberta-WWM-EXT | 80.0 (79.2) | 78.8 (78.3) | 102m |
| Rbt3 | 72.2 | 72.3 | 38m |
| Electra-Small | 73.3 (72.5) | 73.1 (72.6) | 12m |
| Electra-180g-Small | 74.6 | 74.6 | 12m |
| Electra-Small-Ex | 75.4 | 75.8 | 25m |
| Electra-180g-small-ex | 76.5 | 76.6 | 25m |
| Basis elektra | 77.9 (77.0) | 78.4 (77.8) | 102m |
| Electra-180G-BASE | 79.6 | 79.5 | 102m |
| Electra-Large | 81.5 | 81.0 | 324m |
| Electra-180G-Large | 81.2 | 80.4 | 324m |
Dalam tugas analisis sentimen, dataset klasifikasi emosi biner chnsenticorp . Indikator evaluasi adalah: akurasi
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Bert-base | 94.7 (94.3) | 95.0 (94.7) | 102m |
| Bert-WWM | 95.1 (94.5) | 95.4 (95.0) | 102m |
| BERT-WWM-EXT | 95.4 (94.6) | 95.3 (94.7) | 102m |
| Roberta-WWM-EXT | 95.0 (94.6) | 95.6 (94.8) | 102m |
| Rbt3 | 92.8 | 92.8 | 38m |
| Electra-Small | 92.8 (92.5) | 94.3 (93.5) | 12m |
| Electra-180g-Small | 94.1 | 93.6 | 12m |
| Electra-Small-Ex | 92.6 | 93.6 | 25m |
| Electra-180g-small-ex | 92.8 | 93.4 | 25m |
| Basis elektra | 93.8 (93.0) | 94.5 (93.5) | 102m |
| Electra-180G-BASE | 94.3 | 94.8 | 102m |
| Electra-Large | 95.2 | 95.3 | 324m |
| Electra-180G-Large | 94.8 | 95.2 | 324m |
Dua set data berikut perlu mengklasifikasikan pasangan kalimat untuk menentukan apakah semantik dari kedua kalimat tersebut sama (tugas klasifikasi biner).
LCQMC dirilis oleh Pusat Penelitian Komputasi Intelyur dari Harbin Institute of Technology Shenzhen Graduate School. Indikator evaluasi adalah: akurasi
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) | 102m |
| Bert-WWM | 89.4 (89.2) | 87.0 (86.8) | 102m |
| BERT-WWM-EXT | 89.6 (89.2) | 87.1 (86.6) | 102m |
| Roberta-WWM-EXT | 89.0 (88.7) | 86.4 (86.1) | 102m |
| Rbt3 | 85.3 | 85.1 | 38m |
| Electra-Small | 86.7 (86.3) | 85.9 (85.6) | 12m |
| Electra-180g-Small | 86.6 | 85.8 | 12m |
| Electra-Small-Ex | 87.5 | 86.0 | 25m |
| Electra-180g-small-ex | 87.6 | 86.3 | 25m |
| Basis elektra | 90.2 (89.8) | 87.6 (87.3) | 102m |
| Electra-180G-BASE | 90.2 | 87.1 | 102m |
| Electra-Large | 90.7 | 87.3 | 324m |
| Electra-180G-Large | 90.3 | 87.3 | 324m |
BQ Corpus dirilis oleh Pusat Penelitian Komputasi Cerdas dari Harbin Institute of Technology Shenzhen Graduate School dan merupakan kumpulan data untuk bidang perbankan. Indikator evaluasi adalah: akurasi
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Bert | 86.0 (85.5) | 84.8 (84.6) | 102m |
| Bert-WWM | 86.1 (85.6) | 85.2 (84.9) | 102m |
| BERT-WWM-EXT | 86.4 (85.5) | 85.3 (84.8) | 102m |
| Roberta-WWM-EXT | 86.0 (85.4) | 85.0 (84.6) | 102m |
| Rbt3 | 84.1 | 83.3 | 38m |
| Electra-Small | 83.5 (83.0) | 82.0 (81.7) | 12m |
| Electra-180g-Small | 83.3 | 82.1 | 12m |
| Electra-Small-Ex | 84.0 | 82.6 | 25m |
| Electra-180g-small-ex | 84.6 | 83.4 | 25m |
| Basis elektra | 84.8 (84.7) | 84.5 (84.0) | 102m |
| Electra-180G-BASE | 85.8 | 84.5 | 102m |
| Electra-Large | 86.7 | 85.1 | 324m |
| Electra-180G-Large | 86.4 | 85.4 | 324m |
Kami menguji data prediksi kejahatan Yudisial Cail 2018. Tingkat pembelajaran kecil/basis/besar adalah: masing-masing 5E-4/3E-4/1E-4. Indikator evaluasi adalah: akurasi
| Model | Set pengembangan | Set tes | Kuantitas parameter |
|---|---|---|---|
| Electra-Small | 78.84 | 76.35 | 12m |
| Legal-Electra-Small | 79.60 | 77.03 | 12m |
| Basis elektra | 80.94 | 78.41 | 102m |
| Legal-Electra-Base | 81.71 | 79.17 | 102m |
| Electra-Large | 81.53 | 78.97 | 324m |
| Legal-Electra-Large | 82.60 | 79.89 | 324m |
Pengguna dapat melakukan fine-tuning tugas hilir berdasarkan model pra-terlatih China Electra yang diterbitkan di atas. Di sini kami hanya akan memperkenalkan penggunaan paling dasar. Untuk penggunaan yang lebih terperinci, silakan merujuk pada pengenalan resmi Electra.
Dalam contoh ini, kami menggunakan model ELECTRA-small untuk menyempurnakan tugas CMRC 2018, dan langkah-langkah yang relevan adalah sebagai berikut. Dengan asumsi,
data-dir : Direktori root kerja dapat ditetapkan sesuai dengan situasi aktual.model-name : Nama model, dalam hal ini electra-small .task-name : Nama tugas, dalam hal ini cmrc2018 . Kode dalam direktori ini telah beradaptasi dengan enam tugas Cina di atas, dan task-name adalah cmrc2018 , drcd , xnli , chnsenticorp , lcqmc , dan bqcorpus . Di bagian Download Model, unduh model electra-small dan mendekompres ke ${data-dir}/models/${model-name} . Direktori ini harus berisi electra_model.* , vocab.txt , checkpoint , dan total 5 file.
Unduh set pelatihan dan pengembangan CMRC 2018 dan ganti nama menjadi train.json dan dev.json . Masukkan dua file di ${data-dir}/finetuning_data/${task-name} .
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Di antara mereka, data-dir dan model-name telah diperkenalkan di atas. hparams adalah kamus JSON. Dalam contoh ini, params_cmrc2018.json berisi fine-tuning hyperparameters terkait, seperti:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}Dalam file JSON di atas, kami hanya mencantumkan beberapa parameter terpenting. Untuk daftar parameter lengkap, silakan merujuk ke configure_finenetung.py.
Setelah operasi selesai,
cmrc2018_dev_preds.json disimpan dalam ${data-dir}/results/${task-name}_qa/ . Anda dapat memanggil skrip evaluasi eksternal untuk mendapatkan hasil evaluasi akhir, misalnya: python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.jsonxnli: accuracy: 72.5 - loss: 0.67 T: Bagaimana cara mengatur laju pembelajaran model electra saat melakukan fine-tuning tugas hilir?
A: Kami merekomendasikan menggunakan tingkat pembelajaran yang digunakan oleh kertas asli sebagai baseline awal (kecil adalah 3E-4, basis adalah 1E-4) dan kemudian men-debug dengan penambahan yang tepat dan penurunan tingkat pembelajaran. Perlu dicatat bahwa dibandingkan dengan model seperti Bert dan Roberta, tingkat pembelajaran Electra relatif besar.
T: Apakah ada hak cipta Pytorch?
A: Ya, unduh modelnya.
T: Dapatkah data pra-pelatihan dibagikan?
A: Sayangnya, tidak.
T: Rencana masa depan?
A: Silakan tetap disini.
Jika konten di direktori ini bermanfaat untuk pekerjaan penelitian Anda, jangan ragu untuk mengutip makalah berikut di koran.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Selamat datang untuk mengikuti akun resmi WeChat resmi Laboratorium Gabungan IFLYTEK untuk mempelajari tentang tren teknis terbaru.

Sebelum Anda mengirimkan masalah:


