Chinese ELECTRA
1.0.0
Chinesische Beschreibung | Englisch

Dieses Projekt basiert auf der offiziellen Electra der Google & Stanford University: https://github.com/google-research/electra
Chinesische LERT | Chinese Englisch Pert | Chinesischer Macbert | Chinesische Elektrik | Chinesische xlnet | Chinesische Bert | Knowledge Destillation Tool Textbrewer | Modellschneidwerkzeug Textpruner
Siehe weitere Ressourcen,
2023/3/28 Open Source Chinese Lama & Alpaca Big Model, das schnell auf dem PC eingesetzt und erfahren werden kann, https://github.com/ymcui/chinese-lama-alpaca
2022/10/29 Wir schlagen eine vorgebildete Modelllert vor, die sprachliche Informationen integriert. Ansicht: https://github.com/ymcui/lert
2022/3/30 Wir Open Source Ein neues vorgebildetes Modell Pert. Ansicht: https://github.com/ymcui/pert
2021/12/17 IFlytek Joint Laboratory startet das Modell Schneidetoolkit Textpruner. Anzeigen: https://github.com/airaria/textpruner
2021/10/24 IFlytek Joint Laboratory veröffentlichte ein vorgebildetes Modell CINO für ethnische Minderheitensprachen. Ansicht: https://github.com/ymcui/chinese-minority-plm
2021/7/21 "Natürliche Sprachverarbeitung: Methoden, die auf Voraussetzungsmodellen basieren", wurden von vielen Wissenschaftlern des Harbin Institute of Technology SCIR veröffentlicht, und jeder ist eingeladen, es zu kaufen.
2020/12/13 Basierend auf großen juristischen Dokumentendaten haben wir chinesische Elektralerien-Modelle für das Justizbereich geschult, um Modell-Downloads und Justizaufgabeneffekte anzuzeigen.
2020/9/15 Unser Papier "Revisiting vorgebildete Modelle für die chinesische Verarbeitung natürlicher Sprache" wurde als langer Artikel mit den Ergebnissen von EMNLP eingestellt.
2020/8/27 IFL Joint Laboratory hat die Liste in der Bewertung der allgemeinen natürlichen Sprachverständnis der Kleber an der Liste der Leim.
2020/5/29 Chinese Electra-Large/Small-EX wurde veröffentlicht. Bitte überprüfen Sie den Modell -Download. Derzeit ist nur Google Drive -Download -Adresse verfügbar, also verstehen Sie dies.
2020/4/7 PyTorch -Benutzer können das Modell durch das Transferatoren laden, um das schnelle Laden anzuzeigen.
2020/3/31 Die in diesem Verzeichnis veröffentlichten Modelle wurden mit PaddlepaddleHub zum schnellen Betrachten und Laden angeschlossen.
2020/3/25 Chinese Electra-Small/Base wurde veröffentlicht, bitte überprüfen Sie den Modell-Download.
| Kapitel | beschreiben |
|---|---|
| Einführung | Einführung in die Grundprinzipien von Electra |
| Modell Download | Laden Sie das chinesische Electra-Vorausgebildete Modell herunter |
| Schnelles Laden | So verwenden Sie Transformatoren und Paddlehub schnell laden Modelle |
| Basissystemeffekte | Auswirkungen des chinesischen Basissystems: Leseverständnis, Textklassifizierung usw. |
| Wie man benutzt | Detaillierte Verwendung des Modells |
| FAQ | FAQs und Antworten |
| Zitat | Technische Berichte in diesem Verzeichnis |
Electra schlägt ein neues Framework vor dem Training vor, das zwei Teile enthält: Generator und Diskriminator .
Nachdem die Phase vor dem Training vorbei ist, verwenden wir nur Diskriminator als Basismodell für nachgeschaltete Aufgaben, die fein abgestimmt sind.
Weitere detailliertere Inhalte finden Sie im Electra Paper: Electra: Pre-Training-Textcodierer als Diskriminatoren und nicht als Generatoren
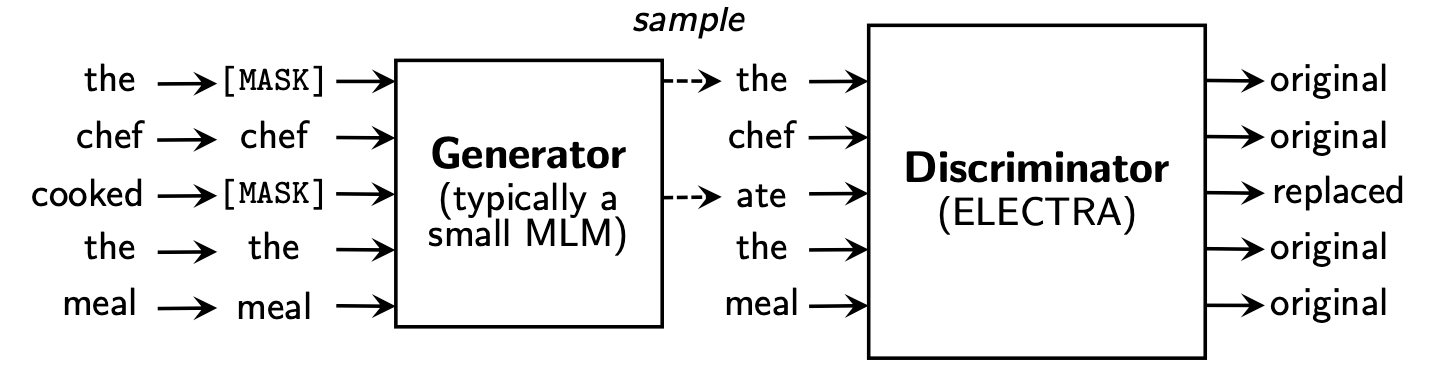
Dieses Verzeichnis enthält die folgenden Modelle und bietet derzeit nur TensorFlow -Versionsgewichte.
ELECTRA-large, Chinese : 24-Schicht, 1024 versteckte, 16-köpfige, 324m ParameterELECTRA-base, Chinese : 12-Schicht, 768 versteckte, 12-Heads, 102 m ParameterELECTRA-small-ex, Chinese : 24-Layer, 256 versteckte, 4-Köpfe, 25m ParameterELECTRA-small, Chinese : 12-Layer, 256 versteckte, 4-Köpfe, 12m Parameter | Modellabkürzung | Google Download | Baidu NetDisk -Download | Komprimierte Packungsgröße |
|---|---|---|---|
ELECTRA-180g-large, Chinese | Tensorflow | TensorFlow (Passwort 2v5r) | 1g |
ELECTRA-180g-base, Chinese | Tensorflow | TensorFlow (Passwort 3VG1) | 383 m |
ELECTRA-180g-small-ex, Chinese | Tensorflow | TensorFlow (Passwort 93N8) | 92 m |
ELECTRA-180g-small, Chinese | Tensorflow | TensorFlow (Passwort K9IU) | 46 m |
| Modellabkürzung | Google Download | Baidu NetDisk -Download | Komprimierte Packungsgröße |
|---|---|---|---|
ELECTRA-large, Chinese | Tensorflow | TensorFlow (Passwort 1E14) | 1g |
ELECTRA-base, Chinese | Tensorflow | TensorFlow (Passwort F32J) | 383 m |
ELECTRA-small-ex, Chinese | Tensorflow | TensorFlow (Passwort GFB1) | 92 m |
ELECTRA-small, Chinese | Tensorflow | TensorFlow (Passwort 1R4R) | 46 m |
| Modellabkürzung | Google Download | Baidu NetDisk -Download | Komprimierte Packungsgröße |
|---|---|---|---|
legal-ELECTRA-large, Chinese | Tensorflow | TensorFlow (Passwort Q4GV) | 1g |
legal-ELECTRA-base, Chinese | Tensorflow | TensorFlow (Passwort 8GCV) | 383 m |
legal-ELECTRA-small, Chinese | Tensorflow | TensorFlow (Passwort KMRJ) | 46 m |
Wenn Sie die Pytorch -Version benötigen, konvertieren Sie sie bitte selbst durch das Conversion -Skript Converted_Electra_original_tf_checkpoint_to_pytorch.py, das von Transformatoren bereitgestellt wird. Wenn Sie Konfigurationsdateien benötigen, können Sie den Konfigurationsordner in diesem Verzeichnis für die Suche eingeben.
python transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path ./path-to-large-model/
--config_file ./path-to-large-model/discriminator.json
--pytorch_dump_path ./path-to-output/model.bin
--discriminator_or_generator discriminatorOder laden Sie Pytorch direkt über die offizielle Website von Huggingface herunter: https://huggingface.co/hfl
Methode: Klicken Sie auf ein Modell, das Sie herunterladen → nach unten ziehen möchten und auf "Alle Dateien in Modelllisten auflisten" → Download Bin- und JSON-Dateien im Popup-Feld.
Es wird empfohlen, Baidu NetDisk -Download -Punkte auf dem chinesischen Festland zu verwenden, während es empfohlen wird, Google -Download -Punkte in Übersee -Benutzern zu verwenden. Nehmen Sie die TensorFlow-Version von ELECTRA-small, Chinese als Beispiel nach dem Herunterladen der Zip-Datei, um die folgende Datei zu erhalten.
chinese_electra_small_L-12_H-256_A-4.zip
|- electra_small.data-00000-of-00001 # 模型权重
|- electra_small.meta # 模型meta信息
|- electra_small.index # 模型index信息
|- vocab.txt # 词表
|- discriminator.json # 配置文件:discriminator(若没有可从本repo中的config目录获取)
|- generator.json # 配置文件:generator(若没有可从本repo中的config目录获取)
Wir haben groß angelegte chinesische Wikis und allgemeine Text verwendet, um das Electra-Modell auszubilden, wobei die Gesamt-Token-Zahl 5,4B erreicht, was mit dem Modell von Roberta-Wwm-EXT-Serien übereinstimmt. In Bezug auf die Liste der Vokabeln verwendet es Googles ursprüngliches Bert -Wortstück -Vokabularliste, einschließlich 21.128 Token. Weitere Details und Hyperparameter sind wie folgt (die nicht erwähnten Parameter bleiben standardmäßig):
ELECTRA-large : 24 Schichten, versteckte Schicht 1024, 16 Aufmerksamkeitsköpfe, Lernrate 1E-4, Batch96, Maximale Länge 512, Training 2m SchritteELECTRA-base : 12 Schichten, versteckte Schicht 768, 12 Aufmerksamkeitsköpfe, Lernrate 2E-4, Batch256, Maximale Länge 512, Training 1m SchrittELECTRA-small-ex : 24 Schichten, versteckte Schicht 256, 4 Aufmerksamkeitsköpfe, Lernrate 5E-4, Batch384, Maximale Länge 512, 2 m-TrainingsschritteELECTRA-small : 12 Schichten, versteckte Schicht 256, 4 Aufmerksamkeitsköpfe, Lernrate 5E-4, Batch1024, Maximale Länge 512, Training 1M Schritt Die Huggingface-Transformatoren Version 2.8.0 hat das Electra-Modell offiziell unterstützt und kann durch die folgenden Befehle aufgerufen werden.
tokenizer = AutoTokenizer . from_pretrained ( MODEL_NAME )
model = AutoModel . from_pretrained ( MODEL_NAME ) Die entsprechende Liste von MODEL_NAME lautet wie folgt:
| Modellname | Komponenten | Model_name |
|---|---|---|
| Electra-180g-Large, Chinesisch | Diskriminator | HFL/Chinese-Electra-180G-Large-Discriminator |
| Electra-180g-Large, Chinesisch | Generator | HFL/Chinese-Electra-180G-Large-Generator |
| Electra-180g-Base, Chinesisch | Diskriminator | HFL/Chinese-Electra-180G-Base-Discriminator |
| Electra-180g-Base, Chinesisch | Generator | HFL/Chinese-Electra-180G-Basis-Generator |
| Electra-180g-Small-EX, Chinesisch | Diskriminator | HFL/Chinese-Electra-180G-Small-Ex-Diskriminator |
| Electra-180g-Small-EX, Chinesisch | Generator | HFL/Chinese-Electra-180G-Small-Ex-Generator |
| Electra-180g-Small, Chinesisch | Diskriminator | HFL/Chinese-Electra-180G-Small-Discriminator |
| Electra-180g-Small, Chinesisch | Generator | HFL/Chinese-Electra-180G-Small-Generator |
| Electra-Large, Chinese | Diskriminator | HFL/chinesisch-elektra-large-diskriminator |
| Electra-Large, Chinese | Generator | HFL/Chinese-Electra-Large-Generator |
| Electra-Base, Chinese | Diskriminator | HFL/Chinese-Electra-Base-Discriminator |
| Electra-Base, Chinese | Generator | HFL/Chinese-Electra-Base-Generator |
| Electra-Small-EX, Chinese | Diskriminator | HFL/Chinese-Electra-Small-Ex-Diskriminator |
| Electra-Small-EX, Chinese | Generator | HFL/Chinese-Electra-Small-Ex-Generator |
| Electra-Small, Chinese | Diskriminator | HFL/Chinese-Electra-Small-Discriminator |
| Electra-Small, Chinese | Generator | HFL/Chinese-Electra-Small-Generator |
Justizdomänenversion:
| Modellname | Komponenten | Model_name |
|---|---|---|
| Legal-Electra-Large, Chinesisch | Diskriminator | HFL/chinesisch-legal-elektra-large-diskriminator |
| Legal-Electra-Large, Chinesisch | Generator | HFL/Chinese-Legal-Electra-Large-Generator |
| Legal-Electra-Base, Chinese | Diskriminator | HFL/chinesisch-legal-elektra-basediskriminator |
| Legal-Electra-Base, Chinese | Generator | HFL/Chinese-Legal-Electra-Base-Generator |
| Legal-Electra-Small, Chinese | Diskriminator | HFL/chinesisch-legal-elektra-malldiskriminator |
| Legal-Electra-Small, Chinese | Generator | HFL/Chinese-Legal-Electra-Small-Generator |
Wenn wir uns auf Paddlehub verlassen, benötigen wir nur eine Codezeile, um den Download und die Installation des Modells zu vervollständigen, und mehr als zehn Codezeilen können die Aufgaben der Textklassifizierung, Sequenzanmerkungen, Leseverständnis und anderen Aufgaben erledigen.
import paddlehub as hub
module = hub.Module(name=MODULE_NAME)
Die entsprechende Liste von MODULE_NAME lautet wie folgt:
| Modellname | Module_Name |
|---|---|
| Electra-Base, Chinese | Chinese-Elektra-Basis |
| Electra-Small, Chinese | chinesisch-elektra-small |
Wir verglichen die Auswirkungen von ELECTRA-small/base mit BERT-base , BERT-wwm , BERT-wwm-ext , RoBERTa-wwm-ext und RBT3 , einschließlich der folgenden sechs Aufgaben:
Für das Electra-Small/Base-Modell verwenden wir die Standard-Lernraten von 3e-4 und 1e-4 im Originalpapier. Es ist zu beachten, dass wir keine Parameteranpassungen für Aufgaben vorgenommen haben, sodass weitere Leistungsverbesserungen durch Anpassung von Hyperparametern wie der Lernrate erreicht werden können. Um die Zuverlässigkeit der Ergebnisse zu gewährleisten, haben wir für dasselbe Modell zehnmal mit verschiedenen zufälligen Seeds geschult, um die maximalen und durchschnittlichen Werte der Modellleistung zu melden (die Durchschnittswerte in Klammern).
Der CMRC 2018 -Datensatz sind die vom Joint Laboratory of Harbin Institute of Technology veröffentlichten chinesischen Daten des Maschinenlesung. Laut einer bestimmten Frage muss das System Fragmente aus dem Kapitel als Antwort in der gleichen Form wie Kader extrahieren. Bewertungsindikatoren sind: EM / F1
| Modell | Entwicklungsset | Testset | Herausforderungssatz | Parametermenge |
|---|---|---|---|---|
| Bert-Base | 65,5 (64,4) / 84,5 (84,0) | 70,0 (68,7) / 87,0 (86,3) | 18,6 (17.0) / 43,3 (41,3) | 102 m |
| Bert-wwm | 66,3 (65,0) / 85,6 (84,7) | 70,5 (69,1) / 87,4 (86,7) | 21.0 (19.3) / 47.0 (43,9) | 102 m |
| Bert-wwm-ot | 67,1 (65,6) / 85,7 (85,0) | 71,4 (70,0) / 87,7 (87,0) | 24.0 (20.0) / 47,3 (44,6) | 102 m |
| Roberta-wwm-text | 67,4 (66,5) / 87,2 (86,5) | 72,6 (71,4) / 89,4 (88,8) | 26,2 (24,6) / 51,0 (49,1) | 102 m |
| RBT3 | 57.0 / 79.0 | 62.2 / 81.8 | 14.7 / 36.2 | 38m |
| Electra-Small | 63,4 (62,9) / 80,8 (80,2) | 67,8 (67,4) / 83,4 (83,0) | 16.3 (15.4) / 37,2 (35,8) | 12 m |
| Electra-180g-Small | 63,8 / 82.7 | 68,5 / 85.2 | 15.1 / 35.8 | 12 m |
| Electra-Small-ex | 66,4 / 82.2 | 71.3 / 85.3 | 18.1 / 38.3 | 25m |
| ELECTRA-180G-SMALL-EX | 68.1 / 85.1 | 71.8 / 87.2 | 20.6 / 41.7 | 25m |
| Elektrikbasis | 68,4 (68,0) / 84,8 (84,6) | 73,1 (72,7) / 87,1 (86,9) | 22,6 (21,7) / 45.0 (43,8) | 102 m |
| Electra-180g-Base | 69.3 / 87.0 | 73.1 / 88.6 | 24.0 / 48.6 | 102 m |
| Elektrafarge | 69.1 / 85.2 | 73.9 / 87.1 | 23.0 / 44.2 | 324 m |
| Electra-180g-Large | 68,5 / 86.2 | 73,5 / 88.5 | 21.8 / 42.9 | 324 m |
Der DRCD -Datensatz wurde vom Delta Research Institute in Taiwan, China, veröffentlicht. Seine Form ist die gleiche wie der Kader und ein extrahierter Leseverständnis -Datensatz, der auf traditionellen Chinesen basiert. Bewertungsindikatoren sind: EM / F1
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Bert-Base | 83.1 (82,7) / 89,9 (89,6) | 82,2 (81,6) / 89,2 (88,8) | 102 m |
| Bert-wwm | 84,3 (83,4) / 90,5 (90,2) | 82,8 (81,8) / 89,7 (89,0) | 102 m |
| Bert-wwm-ot | 85,0 (84,5) / 91,2 (90,9) | 83,6 (83,0) / 90,4 (89,9) | 102 m |
| Roberta-wwm-text | 86,6 (85,9) / 92,5 (92,2) | 85,6 (85,2) / 92.0 (91,7) | 102 m |
| RBT3 | 76,3 / 84.9 | 75,0 / 83.9 | 38m |
| Electra-Small | 79,8 (79,4) / 86,7 (86,4) | 79,0 (78,5) / 85,8 (85,6) | 12 m |
| Electra-180g-Small | 83,5 / 89.2 | 82.9 / 88.7 | 12 m |
| Electra-Small-ex | 84.0 / 89.5 | 83.3 / 89.1 | 25m |
| ELECTRA-180G-SMALL-EX | 87.3 / 92.3 | 86.5 / 91.3 | 25m |
| Elektrikbasis | 87,5 (87,0) / 92,5 (92,3) | 86,9 (86,6) / 91,8 (91,7) | 102 m |
| Electra-180g-Base | 89.6 / 94.2 | 88.9 / 93.7 | 102 m |
| Elektrafarge | 88.8 / 93.3 | 88.8 / 93.6 | 324 m |
| Electra-180g-Large | 90.1 / 94.8 | 90.5 / 94.7 | 324 m |
In der Aufgabe der natürlichen Sprache inferenzieren wir XNLI -Daten, wodurch der Text in drei Kategorien unterteilt werden muss: entailment , neutral und contradictory . Bewertungsindikator ist: Genauigkeit
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Bert-Base | 77,8 (77,4) | 77,8 (77,5) | 102 m |
| Bert-wwm | 79,0 (78,4) | 78,2 (78,0) | 102 m |
| Bert-wwm-ot | 79,4 (78,6) | 78,7 (78,3) | 102 m |
| Roberta-wwm-text | 80.0 (79,2) | 78,8 (78,3) | 102 m |
| RBT3 | 72.2 | 72.3 | 38m |
| Electra-Small | 73,3 (72,5) | 73,1 (72,6) | 12 m |
| Electra-180g-Small | 74,6 | 74,6 | 12 m |
| Electra-Small-ex | 75,4 | 75,8 | 25m |
| ELECTRA-180G-SMALL-EX | 76,5 | 76,6 | 25m |
| Elektrikbasis | 77,9 (77,0) | 78,4 (77,8) | 102 m |
| Electra-180g-Base | 79,6 | 79,5 | 102 m |
| Elektrafarge | 81,5 | 81.0 | 324 m |
| Electra-180g-Large | 81.2 | 80.4 | 324 m |
In der Aufgabe der Sentiment -Analyse ist der Datensatz der binären Emotionsklassifizierung chnSenticorp . Bewertungsindikator ist: Genauigkeit
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Bert-Base | 94.7 (94,3) | 95.0 (94,7) | 102 m |
| Bert-wwm | 95.1 (94,5) | 95.4 (95.0) | 102 m |
| Bert-wwm-ot | 95,4 (94,6) | 95.3 (94.7) | 102 m |
| Roberta-wwm-text | 95.0 (94,6) | 95,6 (94,8) | 102 m |
| RBT3 | 92.8 | 92.8 | 38m |
| Electra-Small | 92,8 (92,5) | 94.3 (93,5) | 12 m |
| Electra-180g-Small | 94.1 | 93.6 | 12 m |
| Electra-Small-ex | 92.6 | 93.6 | 25m |
| ELECTRA-180G-SMALL-EX | 92.8 | 93.4 | 25m |
| Elektrikbasis | 93,8 (93,0) | 94,5 (93,5) | 102 m |
| Electra-180g-Base | 94.3 | 94.8 | 102 m |
| Elektrafarge | 95.2 | 95.3 | 324 m |
| Electra-180g-Large | 94.8 | 95.2 | 324 m |
Die folgenden beiden Datensätze müssen ein Satzpaar klassifizieren, um festzustellen, ob die Semantik der beiden Sätze gleich sind (Binärklassifizierungsaufgabe).
LCQMC wurde vom Intelligent Computing Research Center der Harbin Institute of Technology Shenzhen Graduate School veröffentlicht. Bewertungsindikator ist: Genauigkeit
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Bert | 89,4 (88,4) | 86,9 (86,4) | 102 m |
| Bert-wwm | 89,4 (89,2) | 87,0 (86,8) | 102 m |
| Bert-wwm-ot | 89,6 (89,2) | 87,1 (86,6) | 102 m |
| Roberta-wwm-text | 89,0 (88,7) | 86,4 (86,1) | 102 m |
| RBT3 | 85.3 | 85.1 | 38m |
| Electra-Small | 86,7 (86,3) | 85,9 (85,6) | 12 m |
| Electra-180g-Small | 86.6 | 85,8 | 12 m |
| Electra-Small-ex | 87,5 | 86.0 | 25m |
| ELECTRA-180G-SMALL-EX | 87.6 | 86,3 | 25m |
| Elektrikbasis | 90,2 (89,8) | 87,6 (87,3) | 102 m |
| Electra-180g-Base | 90.2 | 87.1 | 102 m |
| Elektrafarge | 90.7 | 87,3 | 324 m |
| Electra-180g-Large | 90.3 | 87,3 | 324 m |
BQ Corpus wird vom Intelligent Computing Research Center des Harbin Institute of Technology Shenzhen Graduate School veröffentlicht und ist ein Datensatz für das Bankenbereich. Bewertungsindikator ist: Genauigkeit
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Bert | 86,0 (85,5) | 84,8 (84,6) | 102 m |
| Bert-wwm | 86,1 (85,6) | 85,2 (84,9) | 102 m |
| Bert-wwm-ot | 86,4 (85,5) | 85,3 (84,8) | 102 m |
| Roberta-wwm-text | 86,0 (85,4) | 85,0 (84,6) | 102 m |
| RBT3 | 84.1 | 83.3 | 38m |
| Electra-Small | 83,5 (83,0) | 82.0 (81,7) | 12 m |
| Electra-180g-Small | 83.3 | 82.1 | 12 m |
| Electra-Small-ex | 84.0 | 82.6 | 25m |
| ELECTRA-180G-SMALL-EX | 84.6 | 83.4 | 25m |
| Elektrikbasis | 84,8 (84,7) | 84,5 (84,0) | 102 m |
| Electra-180g-Base | 85,8 | 84,5 | 102 m |
| Elektrafarge | 86,7 | 85.1 | 324 m |
| Electra-180g-Large | 86,4 | 85.4 | 324 m |
Wir haben die Justizelektra mit den Daten der Gerichtsvorhersage der Justizüberprüfung von CAIL 2018 getestet. Die Lernraten von kleinen/basischen/groß sind: 5E-4/3E-4/1E-4. Bewertungsindikator ist: Genauigkeit
| Modell | Entwicklungsset | Testset | Parametermenge |
|---|---|---|---|
| Electra-Small | 78,84 | 76,35 | 12 m |
| legal-elektra-small | 79,60 | 77.03 | 12 m |
| Elektrikbasis | 80.94 | 78,41 | 102 m |
| legalelektra Basis | 81.71 | 79.17 | 102 m |
| Elektrafarge | 81.53 | 78,97 | 324 m |
| legalelektra-large | 82.60 | 79,89 | 324 m |
Benutzer können nachgelagerte Aufgaben basierend auf dem oben veröffentlichten chinesischen Electra-Modell oben ausführen. Hier werden wir nur die grundlegendste Verwendung einführen. Eine detailliertere Verwendung finden Sie in der offiziellen Einführung von Electra.
In diesem Beispiel haben wir ELECTRA-small Modell verwendet, um die CMRC 2018-Aufgabe zu optimieren, und die entsprechenden Schritte sind wie folgt. Annahme,
data-dir : Das Arbeitsstammverzeichnis kann gemäß der tatsächlichen Situation festgelegt werden.model-name : Modellname, in diesem Fall electra-small .task-name : Aufgabename, in diesem Fall cmrc2018 . Der Code in diesem Verzeichnis hat sich an die oben genannten sechs chinesischen Aufgaben angepasst, und task-name sind cmrc2018 , drcd , xnli , chnsenticorp , lcqmc und bqcorpus . Laden Sie im Abschnitt "Modell Download das Electra-Small-Modell" herunter und dekomprimieren Sie es auf ${data-dir}/models/${model-name} . Dieses Verzeichnis sollte electra_model.* , vocab.txt , checkpoint und insgesamt 5 Dateien.
Laden Sie das CMRC 2018 Training and Development Set herunter und benennen Sie ihn in train.json und dev.json um. Fügen Sie zwei Dateien in ${data-dir}/finetuning_data/${task-name} ein.
python run_finetuning.py
--data-dir ${data-dir}
--model-name ${model-name}
--hparams params_cmrc2018.json Unter ihnen wurden oben data-dir und model-name vorgestellt. hparams ist ein JSON -Wörterbuch. In diesem Beispiel enthält params_cmrc2018.json feinabstimmungsbezogene Hyperparameter wie:
{
"task_names" : [ " cmrc2018 " ],
"max_seq_length" : 512 ,
"vocab_size" : 21128 ,
"model_size" : " small " ,
"do_train" : true ,
"do_eval" : true ,
"write_test_outputs" : true ,
"num_train_epochs" : 2 ,
"learning_rate" : 3e-4 ,
"train_batch_size" : 32 ,
"eval_batch_size" : 32 ,
}In der obigen JSON -Datei listen wir nur einige der wichtigsten Parameter auf. Die vollständige Parameterliste finden Sie unter configure_finenetung.py.
Nach Abschluss des Betriebs,
cmrc2018_dev_preds.json in ${data-dir}/results/${task-name}_qa/ gespeichert. Sie können externe Bewertungsskripte aufrufen python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.json um die endgültigen Bewertungsergebnisse zu erhalten, z.xnli: accuracy: 72.5 - loss: 0.67 F: Wie setzen Sie die Lernrate des Electra-Modells bei Feinabstimmungsaufgaben fest?
A: Wir empfehlen die Verwendung der vom Originalpapier als anfänglichen Basislinie verwendeten Lernrate (klein ist 3E-4, Basis 1E-4) und debuggen dann mit geeigneter Addition und Verringerung der Lernrate. Es ist zu beachten, dass im Vergleich zu Modellen wie Bert und Roberta die Lernrate von Elektra relativ groß ist.
F: Gibt es Pytorch -Urheberrechte?
A: Ja, laden Sie das Modell herunter.
F: Können Daten vor dem Training freigegeben werden?
A: Leider nein.
F: Zukunftspläne?
A: Bitte bleiben Sie dran.
Wenn der Inhalt in diesem Verzeichnis für Ihre Forschungsarbeiten hilfreich ist, zitieren Sie bitte das folgende Papier im Papier.
@journal{cui-etal-2021-pretrain,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing},
journal={IEEE Transactions on Audio, Speech and Language Processing},
year={2021},
url={https://ieeexplore.ieee.org/document/9599397},
doi={10.1109/TASLP.2021.3124365},
}
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
Willkommen, um dem offiziellen WeChat Offiziellen Bericht des gemeinsamen Labors Iflytek zu folgen, um mehr über die neuesten technischen Trends zu erfahren.

Bevor Sie ein Problem einreichen:


