TurboTransformers
v0.5.1

turboTransformers แบบเปิดโล่ง WeChat AI ที่มีลักษณะดังต่อไปนี้
TurboTransformers ถูกนำไปใช้กับสถานการณ์บริการเบิร์กออนไลน์หลายรายการใน Tencent ตัวอย่างเช่นมันนำการเร่งความเร็ว 1.88x มาสู่บริการ WeChat FAQ การเร่งความเร็ว 2.11x ไปยังบริการการวิเคราะห์ความเชื่อมั่นของคลาวด์สาธารณะและการเร่งความเร็ว 13.6x ไปยังระบบแนะนำ QQ นอกจากนี้ยังมีการใช้งานเพื่อสร้างบริการเช่นการเรียกร้องการค้นหาและคำแนะนำ
ตารางต่อไปนี้คือการเปรียบเทียบ turboTransformers และงานที่เกี่ยวข้อง
| งานที่เกี่ยวข้อง | ผลงาน | ต้องการการประมวลผลล่วงหน้า | ความยาวตัวแปร | การใช้งาน |
|---|---|---|---|---|
| Pytorch Jit (CPU) | เร็ว | ใช่ | เลขที่ | แข็ง |
| Tensorrt (GPU) | เร็ว | ใช่ | เลขที่ | แข็ง |
| TF-Faster Transformers (GPU) | เร็ว | ใช่ | เลขที่ | แข็ง |
| ONNX-RUNTIME (CPU/GPU) | เร็ว/เร็ว | เลขที่ | ใช่ | ปานกลาง |
| tensorflow -1.x (CPU/GPU) | ช้า/ปานกลาง | ใช่ | เลขที่ | ง่าย |
| Pytorch (CPU/GPU) | ปานกลาง/กลาง | เลขที่ | ใช่ | ง่าย |
| Turbo-Transformers (CPU/GPU) | เร็ว/เร็วที่สุด | เลขที่ | ใช่ | ง่าย |
ขณะนี้เราสนับสนุนโมเดลหม้อแปลงต่อไปนี้
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]โปรดทราบว่าสคริปต์อาคารใช้กับระบบปฏิบัติการและซอฟต์แวร์เฉพาะ (Pytorch, OpenNMT, Transformers ฯลฯ ) เท่านั้น โปรดปรับตามความต้องการของคุณ
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
วิธีที่ 1: ฉันต้องการแยกส่วน
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
วิธีที่ 2: ฉันไม่ต้องการแยกส่วน
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
นอกจากนี้เรายังได้จัดทำอิมเมจนักเทียบท่าที่มี CPU เวอร์ชันของ turboTransformers รวมถึงผลงานอื่น ๆ ที่เกี่ยวข้องเช่น onnxrt v1.2.0 และ pytorch-jit บน Dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
นอกจากนี้เรายังเตรียมอิมเมจนักเทียบท่าที่มี TurboTransformers เวอร์ชัน GPU
docker pull thufeifeibear/turbo_transformers_gpu:latest
เทนเซอร์คอร์สามารถเร่งการคำนวณบน GPU มันถูกปิดใช้งานโดยค่าเริ่มต้นใน turboTransformers หากคุณต้องการเปิดใช้งานก่อนที่จะรวบรวมรหัสให้ตั้งค่าตัวเลือกด้วย _module_benchmakr ใน cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
TurboTransformers ให้อินเทอร์เฟซ C ++ / Python API เราหวังว่าจะทำให้ดีที่สุดเพื่อปรับให้เข้ากับสภาพแวดล้อมออนไลน์ที่หลากหลายเพื่อลดความยากลำบากในการพัฒนาสำหรับผู้ใช้
ขั้นตอนแรกในการใช้เทอร์โบคือการโหลดรุ่นที่ผ่านการฝึกอบรมมาก่อน เราให้วิธีการโหลดโมเดล Pytorch และ Tensorflow ที่ผ่านการฝึกอบรมล่วงหน้าใน HuggingFace/Transformers วิธีการแปลงเฉพาะคือการใช้สคริปต์ที่เกี่ยวข้องใน./tools เพื่อแปลงโมเดลที่ผ่านการฝึกอบรมมาก่อนเป็นไฟล์รูปแบบ NPZ และเทอร์โบใช้อินเตอร์เฟส C ++ หรือ Python เพื่อโหลดโมเดลรูปแบบ NPZ โดยเฉพาะอย่างยิ่งเราพิจารณาว่าโมเดลที่ผ่านการฝึกอบรมมาก่อนส่วนใหญ่อยู่ในรูปแบบ pytorch และใช้กับ Python เราให้ทางลัดสำหรับการโทรโดยตรงใน Python สำหรับโมเดล Pytorch ที่บันทึกไว้
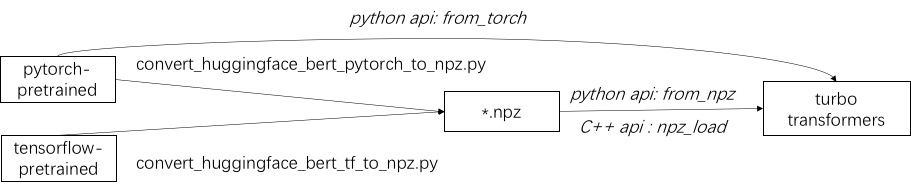
อ้างถึงตัวอย่างของโมเดลที่รองรับใน ./example/python Turbonlp/Translate-Demo แสดงตัวอย่างของการใช้ turboTransformer ในงานการแปล เนื่องจากผู้ใช้การเร่งความเร็วของเบิร์ตจำเป็นต้องใช้กระบวนการโพสต์การประมวลผลที่กำหนดเองเสมอสำหรับงานเราจึงให้ตัวอย่างของวิธีการเขียนแอปพลิเคชันการจำแนกลำดับ
อ้างถึง ./example/cpp สำหรับตัวอย่าง ตัวอย่างของเราให้วิธีการเรียก GPU และสอง CPU แบบหลายเธรด หนึ่งคือการอนุมาน Bert หนึ่งครั้งโดยใช้หลายเธรด อีกอย่างคือการอนุมาน Bert หลายครั้งซึ่งแต่ละอันใช้หนึ่งเธรด ผู้ใช้สามารถเชื่อมโยงผู้แปลงเทอร์โบกับรหัสของคุณผ่าน ADD_SUBDIRECTORY
โดยปกติแล้วการให้อาหารชุดของคำขอที่มีความยาวต่างกันเป็นแบบจำลอง Bert สำหรับการอนุมานจำเป็นต้องใช้การเสริมกำลังเป็นศูนย์เพื่อให้คำขอทั้งหมดมีความยาวเท่ากัน ตัวอย่างเช่นรายการคำขอความยาว (100, 10, 50) คุณต้องใช้ขั้นตอนการประมวลผลล่วงหน้าเพื่อเพิ่มความยาว (100, 100, 100) ด้วยวิธีนี้ 90% และ 50% ของการคำนวณลำดับสองครั้งสุดท้ายจะสูญเปล่า ตามที่ระบุไว้ในหม้อแปลงที่มีประสิทธิภาพไม่จำเป็นต้องใช้เทนเซอร์อินพุต อีกทางเลือกหนึ่งคุณเพียงแค่ต้องใช้การดำเนินการแบทช์ GEMM ภายในความสนใจหลายหัวซึ่งเป็นไปตามข้อเสนอเล็ก ๆ ของการคำนวณ BERT ทั้งหมด ดังนั้นการดำเนินการ GEMM ส่วนใหญ่จะถูกประมวลผลโดยไม่มีการเสริมกำลัง เทอร์โบจัดทำแบบจำลองเป็น BertModelSmartBatch รวมถึงเทคนิคการแบตช์อัจฉริยะ ตัวอย่างถูกนำเสนอใน ./example/python/bert_smart_pad.py
จะรู้ฮอตสปอตของรหัสของคุณได้อย่างไร?
จะเพิ่มเลเยอร์ใหม่ได้อย่างไร?
ปัจจุบัน (มิถุนายน 2020) ในอนาคตอันใกล้นี้เราจะเพิ่มการสนับสนุนสำหรับรุ่นที่มีความแม่นยำต่ำ (CPU INT8, GPU FP16) มองไปข้างหน้าเพื่อบริจาคของคุณ!
ใบอนุญาต BSD 3 ข้อ
อ้างถึงบทความนี้หากคุณใช้ turboTransformers ในสิ่งพิมพ์การวิจัยของคุณ
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
สิ่งประดิษฐ์ของกระดาษสามารถพบได้ที่สาขา ppopp21_artifact_centos
แม้ว่าเราจะแนะนำให้คุณโพสต์ปัญหาของคุณเกี่ยวกับปัญหา GitHub แต่คุณยังสามารถเข้าร่วมในกลุ่มผู้ใช้เทอร์โบของเรา


