TurboTransformers
v0.5.1

Os turbotransformadores de código aberto do WeChat AI com as seguintes características.
Os Turbotransformers foram aplicados a vários cenários de serviço BERT on -line em Tencent. Por exemplo, ele traz aceleração de 1,88x ao serviço WECHAT FAQ, aceleração 2.11X para o serviço de análise de sentimentos de nuvem pública e aceleração 13.6x para o sistema de recomendação QQ. Além disso, ele já foi aplicado para criar serviços como encantamento, pesquisa e recomendação.
A tabela a seguir é uma comparação de turbotransformadores e trabalhos relacionados.
| Trabalhos relacionados | Desempenho | Precisa de pré -processamento | Comprimento variável | Uso |
|---|---|---|---|---|
| Pytorch JIT (CPU) | Rápido | Sim | Não | Duro |
| Tensorrt (GPU) | Rápido | Sim | Não | Duro |
| TF Transformers-Fast-Rasthers (GPU) | Rápido | Sim | Não | Duro |
| Onnx-Runtime (CPU/GPU) | Rápido/rápido | Não | Sim | Médio |
| tensorflow-1.x (CPU/GPU) | Lento/médio | Sim | Não | Fácil |
| pytorch (CPU/GPU) | Médio/médio | Não | Sim | Fácil |
| Turbo-transformadores (CPU/GPU) | O mais rápido/mais rápido | Não | Sim | Fácil |
Atualmente, apoiamos os seguintes modelos de transformador.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Observe que os scripts de construção se aplicam apenas a SO e software específicos (Pytorch, OpenNMT, Transformers etc.). Por favor, ajuste -os de acordo com suas necessidades.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Método 1: eu quero unirest
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Método 2: Eu não quero mais unidade
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
Também preparamos uma imagem do docker contendo versão da CPU dos turbotransformers, bem como outros trabalhos relacionados, ou seja, Onnxrt v1.2.0 e Pytorch-Jit no DockerHub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
Também preparamos uma imagem do Docker contendo a versão GPU de turbotransformadores.
docker pull thufeifeibear/turbo_transformers_gpu:latest
O núcleo do tensor pode acelerar a computação na GPU. É desativado por padrão em turbotransformadores. Se você quiser ativá -lo, antes de compilar o código, defina a opção com_module_benchmakr em cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Os Turbotransformers fornecem interfaces de API C ++ / Python. Esperamos fazer o possível para se adaptar a uma variedade de ambientes on -line para reduzir a dificuldade de desenvolvimento para os usuários.
O primeiro passo no uso do Turbo é carregar um modelo pré-treinado. Fornecemos uma maneira de carregar modelos pré-treinados Pytorch e TensorFlow em Huggingface/Transformers. O método de conversão específico é usar o script correspondente em ./tools para converter o modelo pré-treinado em um arquivo de formato NPZ, e o Turbo usa a interface C ++ ou Python para carregar o modelo de formato NPZ. Em particular, consideramos que a maioria dos modelos pré-treinados está em formato Pytorch e usada com Python. Fornecemos um atalho para ligar diretamente no Python para o modelo salvo Pytorch.
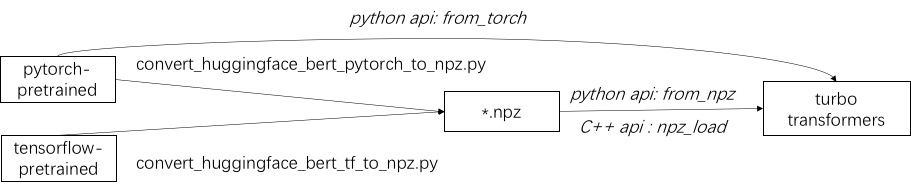
Consulte exemplos de modelos suportados em ./example/python. Turbonlp/tradutor-Demo mostra uma demonstração de aplicar o Turbotransformer na tarefa de tradução. Como o usuário da aceleração do BERT sempre requer um processo de pós-processamento personalizado para a tarefa, fornecemos um exemplo de como escrever um aplicativo de classificação de sequência.
Consulte ./example/cpp para um exemplo. Nosso exemplo fornece a GPU e dois métodos de chamada com vários threads da CPU. Um é fazer uma inferência Bert usando vários threads; O outro é fazer inferência de múltiplas bert, cada uma das quais usando um thread. Os usuários podem vincular turbo-transformadores ao seu código através do add_subdirectory.
Geralmente, alimentando um lote de solicitações de diferentes comprimentos em um modelo BERT para inferência, é necessário o acidente zero para fazer com que todas as solicitações tenham o mesmo comprimento. Por exemplo, atendendo a lista de solicitações de comprimentos (100, 10, 50), você precisa de um estágio de pré -processamento para prendê -los como comprimentos (100, 100, 100). Dessa forma, 90% e 50% dos dois últimos dois sequeceções são desperdiçados. Conforme indicado no transformador eficaz, não é necessário preencher os tensores de entrada. Como alternativa, você só precisa adquirir as operações em lote-gemm dentro de atenções de várias cabeças, que se acumulam em uma pequena propação de todo o cálculo da BERT. Portanto, a maioria das operações da GEMM é processada sem acalmar zero. O Turbo fornece um modelo como BertModelSmartBatch , incluindo uma técnica de lotes inteligentes. O exemplo é apresentado em ./example/python/bert_smart_pad.py.
Como saber os pontos de acesso do seu código?
Como adicionar uma nova camada?
Atualmente (junho de 2020), em um futuro próximo, adicionaremos suporte para modelos de baixa precisão (CPU INT8, GPU FP16). Aguardando sua contribuição!
Licença de 3 cláusulas BSD
Cite este artigo, se você usar turbotransformadores em sua publicação de pesquisa.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Os artefatos do papel podem ser encontrados na filial ppopp21_artifact_centos .
Embora recomendemos que você publique seu problema com problemas do GitHub, você também pode participar do nosso grupo de usuários do Turbo.


