TurboTransformers
v0.5.1

Die WeChat AI Open-Sourcing-Turbotransformatoren mit den folgenden Eigenschaften.
Turbotransformers wurden auf mehrere Online -Bert -Service -Szenarien in Tencent angewendet. Zum Beispiel bringt es 1,88x Beschleunigung in den WeChat -FAQ -Dienst, die Beschleunigung von 2.11x in den öffentlichen Cloud Sentiment Analysis Service und die 13,6 -fache Beschleunigung des QQ -Empfehlungssystems. Darüber hinaus wurde es bereits angewendet, um Dienste wie das Schleifen, die Suche und die Empfehlung zu erstellen.
Die folgende Tabelle ist ein Vergleich von Turbotransformatoren und verwandten Arbeiten.
| Verwandte Werke | Leistung | Brauchen Vorverarbeitung | Variable Länge | Verwendung |
|---|---|---|---|---|
| Pytorch JIT (CPU) | Schnell | Ja | NEIN | Hart |
| Tensorrt (GPU) | Schnell | Ja | NEIN | Hart |
| TF-Faste-Transformers (GPU) | Schnell | Ja | NEIN | Hart |
| Onnx-Runtime (CPU/GPU) | Schnell/schnell | NEIN | Ja | Medium |
| Tensorflow-1.x (CPU/GPU) | Langsam/mittel | Ja | NEIN | Einfach |
| Pytorch (CPU/GPU) | Mittel/mittel | NEIN | Ja | Einfach |
| Turbo-Transformatoren (CPU/GPU) | Am schnellsten/schnellsten | NEIN | Ja | Einfach |
Wir unterstützen derzeit die folgenden Transformatormodelle.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Beachten Sie, dass die Gebäudeskripte nur für bestimmte OS und Software (Pytorch, OpenNMT, Transformers usw.) gelten. Bitte passen Sie sie an Ihre Bedürfnisse an.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Methode 1: Ich möchte Unitesterest
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Methode 2: Ich möchte nicht einst
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
Wir haben auch ein Docker-Image vorbereitet, das die CPU-Version von Turbotransformern sowie andere verwandte Arbeiten, dh Onnxrt v1.2.0 und Pytorch-Jit auf DockerHub, enthält
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
Wir haben auch ein Docker -Image vorbereitet, das eine GPU -Version von Turbotransformern enthält.
docker pull thufeifeibear/turbo_transformers_gpu:latest
Der Tensor -Kern kann das Computing an der GPU beschleunigen. Es ist standardmäßig in Turbotransformatoren deaktiviert. Wenn Sie es einschalten möchten, stellen Sie vor dem Kompilieren der Code die Option mit_Module_Benchmakr in cmakelists.txt fest
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Turbotransformer liefert C ++ / Python -API -Schnittstellen. Wir hoffen, unser Bestes zu geben, um uns an eine Vielzahl von Online -Umgebungen anzupassen, um die Schwierigkeit der Entwicklung für Benutzer zu verringern.
Der erste Schritt bei der Verwendung von Turbo besteht darin, ein vorgebildetes Modell zu laden. Wir bieten eine Möglichkeit, Pytorch- und Tensorflow-Vor-ausgebildete Modelle in Huggingface/Transformers zu laden. Die spezifische Konvertierungsmethode besteht darin, das entsprechende Skript in ./Tools zu verwenden, um das vorgebildete Modell in eine NPZ-Formatdatei umzuwandeln, und Turbo verwendet die C ++-oder die Python-Schnittstelle, um das NPZ-Formatmodell zu laden. Insbesondere sind wir der Ansicht, dass die meisten vorgeborenen Modelle im Pytorch-Format und mit Python verwendet werden. Wir bieten eine Abkürzung für das direkte Anrufen in Python für das Pytorch -Speichermodell.
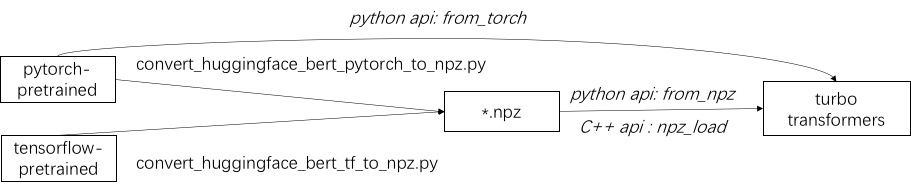
Siehe Beispiele für unterstützte Modelle in ./example/python. Turbonlp/Translate-Demo zeigt eine Demo der Anwendung von Turbotransformator in der Übersetzungsaufgabe. Da der Benutzer der Bert-Beschleunigung immer einen angepassten Nachbearbeitungsprozess für die Aufgabe benötigt, geben wir ein Beispiel für das Schreiben einer Sequenzklassifizierungsanwendung.
Ein Beispiel finden Sie in ./example/cpp. Unser Beispiel liefert die GPU und zwei CPU-Multi-Thread-Aufrufmethoden. Eine davon ist, eine Bert -Inferenz mit mehreren Threads durchzuführen. Der andere ist, mehrere Bert -Inferenz zu machen, von denen jede mit einem Thread verwendet wird. Benutzer können Turbo-Transformatoren über add_subdirectory mit Ihrem Code verknüpfen.
Normalerweise ist das Fütterung einer Charge von Anforderungen unterschiedlicher Längen in ein Bert-Modell für Inferenz, damit alle Anforderungen die gleiche Länge haben. Wenn Sie beispielsweise Anforderungen Liste der Längen servieren (100, 10, 50), benötigen Sie eine Vorverarbeitungsstufe, um sie als Längen (100, 100, 100) zu padeln. Auf diese Weise werden 90% und 50% der letzten beiden Sequenzberechnung verschwendet. Wie in einem effektiven Transformator angegeben, ist es nicht erforderlich, die Eingangsprüfungen zu padeln. Alternative müssen Sie nur die Batch-GEMM-Operationen in mehrköpfigen Aufmerksamkeiten padeln, die auf eine kleine Anregung der gesamten Bert-Berechnung entsprechen. Daher werden die meisten GEMM-Operationen ohne Nullpadding verarbeitet. Turbo bietet ein Modell als BertModelSmartBatch , einschließlich einer intelligenten Batching -Technik. Das Beispiel wird in ./example/python/bert_smart_pad.py dargestellt.
Woher kennt ich Hotspots Ihres Code?
Wie füge ich eine neue Ebene hinzu?
Derzeit (Juni 2020) werden wir in naher Zukunft Unterstützung für Modelle mit niedriger Präzision (CPU INT8, GPU FP16) hinzufügen. Ich freue mich auf Ihren Beitrag!
BSD 3-Klausel-Lizenz
Zitieren Sie dieses Papier, wenn Sie Turbotransformatoren in Ihrer Forschungsveröffentlichung verwenden.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Die Artefakte des Papiers finden Sie am Zweig ppopp21_artifact_centos .
Obwohl wir empfehlen, Ihr Problem mit GitHub -Problemen zu veröffentlichen, können Sie auch in unserer Turbo -Benutzergruppe teilnehmen.


