TurboTransformers
v0.5.1

WeChat AI с открытым исходным кодом турботрансформаторы со следующими характеристиками.
Turbotransformers были применены к нескольким онлайн -сценариям сервиса Bert в Tencent. Например, он привносит 1,88x ускорение в службу FAQ WeChat, ускорение 2.11X в службу анализа настроения общего облака и ускорение 13,6x в систему рекомендаций QQ. Более того, он уже применялся для создания таких услуг, как кнопка, поиск и рекомендации.
Следующая таблица представляет собой сравнение турботрансформатора и связанных с ними работы.
| Связанные работы | Производительность | Нужна предварительная обработка | Переменная длина | Использование |
|---|---|---|---|---|
| Pytorch JIT (процессор) | Быстрый | Да | Нет | Жесткий |
| Tensorrt (GPU) | Быстрый | Да | Нет | Жесткий |
| ТВС-ТВС-Трансформеры (GPU) | Быстрый | Да | Нет | Жесткий |
| Onnx-runtime (процессор/графический процессор) | Быстро/быстро | Нет | Да | Середина |
| tensorflow-1.x (процессор/графический процессор) | Медленный/средний | Да | Нет | Легкий |
| Pytorch (процессор/графический процессор) | Средний/средний | Нет | Да | Легкий |
| турбо-трансформаторы (процессор/графический процессор) | Самый быстрый/быстрый | Нет | Да | Легкий |
В настоящее время мы поддерживаем следующие модели трансформатора.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Обратите внимание, что строительные сценарии применимы только к конкретной ОС и версиях программного обеспечения (Pytorch, OpenNMT, Transformers и т. Д.). Пожалуйста, отрегулируйте их в соответствии с вашими потребностями.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Метод 1: я хочу подразделять
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Метод 2: Я не хочу единой инициативы
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
Мы также подготовили изображение Docker, содержащее версию турботрансформатора CPU, а также другие связанные работы, то есть Onnxrt v1.2.0 и pytorch-jit на Dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
Мы также подготовили изображение Docker, содержащее версию GPU турботрансформаторов.
docker pull thufeifeibear/turbo_transformers_gpu:latest
Тенсорное ядро может ускорить вычисления на графическом процессоре. Он отключен по умолчанию в турботрансформаторах. Если вы хотите включить его, перед сбором кода, установите опцию с помощью_module_benchmakr на cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Turbotransformers обеспечивает интерфейсы C ++ / Python API. Мы надеемся сделать все возможное, чтобы адаптироваться к различным онлайн -средам, чтобы уменьшить сложность разработки для пользователей.
Первым шагом в использовании Turbo является загрузка предварительно обученной модели. Мы предоставляем способ загрузить предварительно обученные модели Pytorch и Tensorflow в HuggingFace/Transformers. Конкретный метод преобразования состоит в том, чтобы использовать соответствующий скрипт в ./Tools для преобразования предварительно обученной модели в файл формата NPZ, а Turbo использует интерфейс C ++ или Python для загрузки модели формата NPZ. В частности, мы считаем, что большинство предварительно обученных моделей находятся в формате Pytorch и используются с Python. Мы предоставляем ярлык для вызова прямо в Python для сохраненной модели Pytorch.
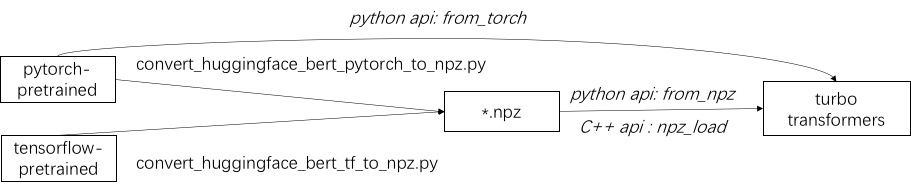
См. Примеры поддерживаемых моделей в ./example/python. Turbonlp/Translate-Demo показывает демонстрацию применения турботрансформатора в задаче перевода. Поскольку пользователь BERT Acceleration всегда требуется настраиваемый процесс пост-обработки для задачи, мы приводим пример того, как написать приложение классификации последовательностей.
Обратитесь к ./example/cpp для примера. Наш пример содержит графический процессор и два метода многопоточных вызовов CPU. Один из них - сделать один вывод BRET, используя несколько потоков; Другой - сделать несколько выводов BERT, каждый из которых использует один поток. Пользователи могут ссылаться на турбо-трансформаторы с вашим кодом через add_subdirectory.
Обычно, для подачи партии запросов различной длины в модель BERT для вывода, необходим нулевой бабол. Например, обслуживание запросов списка длины (100, 10, 50), вам нужна стадия предварительной обработки, чтобы подумать об их длине (100, 100, 100). Таким образом, 90% и 50% из двух последних вычислений последовательности потрачены впустую. Как указано в эффективном трансформаторе, нет необходимости заполнять входные тензоры. В качестве альтернативы, вам просто нужно подумать о операциях с пакетированием GEMM внутри многоголовного внимания, которое приводит к небольшому распространению всего вычисления BERT. Поэтому большая часть операций GEMM обрабатывается без нулевой бабочки. Turbo предоставляет модель в качестве BertModelSmartBatch , включая умную технику пакетирования. Пример представлен в ./example/python/bert_smart_pad.py.
Как узнать горячие точки вашего кода?
Как добавить новый слой?
В настоящее время (июнь 2020 года) в ближайшем будущем мы добавим поддержку моделей с низким уровнем определения (CPU Int8, GPU FP16). С нетерпением жду вашего вклада!
BSD 3-rack License
Приведите эту статью, если вы используете турботрансформаторы в своей исследовательской публикации.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Артефакты бумаги можно найти в Branch ppopp21_artifact_centos .
Хотя мы рекомендуем вам опубликовать вашу проблему с проблемами GitHub, вы также можете присоединиться к нашей группе Turbo пользователей.


