TurboTransformers
v0.5.1

Los turbotransformadores de origen abierto WeChat AI con las siguientes características.
Turbotransformers se ha aplicado a múltiples escenarios de servicio Bert en línea en Tencent. Por ejemplo, aporta una aceleración de 1.88x al servicio WeChat Preguntas frecuentes, una aceleración de 2.11x al servicio de análisis de sentimientos de nube pública y una aceleración de 13.6x al sistema de recomendación QQ. Además, ya se ha aplicado para construir servicios tales como casco, búsqueda y recomendación.
La siguiente tabla es una comparación de turbotransformadores y trabajo relacionado.
| Obras relacionadas | Actuación | Necesita preprocesos | Longitud variable | Uso |
|---|---|---|---|---|
| Pytorch JIT (CPU) | Rápido | Sí | No | Duro |
| Tensorrt (GPU) | Rápido | Sí | No | Duro |
| TF Transformers más rápido (GPU) | Rápido | Sí | No | Duro |
| Onnx-Runtime (CPU/GPU) | Rápido/rápido | No | Sí | Medio |
| tensorflow-1.x (CPU/GPU) | Lento/medio | Sí | No | Fácil |
| Pytorch (CPU/GPU) | Medio/medio | No | Sí | Fácil |
| Turbo-transformadores (CPU/GPU) | Más rápido/más rápido | No | Sí | Fácil |
Actualmente admitimos los siguientes modelos de transformador.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Tenga en cuenta que los scripts de construcción solo se aplican a versiones específicas del sistema operativo y software (Pytorch, OpenNMT, Transformers, etc.). Por favor, ajústelos de acuerdo con sus necesidades.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Método 1: Quiero unir
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Método 2: No quiero unir
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
También preparamos una imagen de Docker que contiene la versión CPU de Turbotransformers, así como otros trabajos relacionados, es decir, Onnxrt V1.2.0 y Pytorch-Jit en Dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
También preparamos una imagen Docker que contiene la versión GPU de Turbotransformers.
docker pull thufeifeibear/turbo_transformers_gpu:latest
Tensor Core puede acelerar la computación en GPU. Está deshabilitado de forma predeterminada en turbotransformadores. Si desea encenderlo, antes de compilar el código, configure la opción con with_module_benchmakr en cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Turbotransformers proporciona interfaces API C ++ / Python. Esperamos hacer todo lo posible para adaptarnos a una variedad de entornos en línea para reducir la dificultad del desarrollo para los usuarios.
El primer paso para usar Turbo es cargar un modelo previamente capacitado. Proporcionamos una forma de cargar modelos previamente capacitados Pytorch y TensorFlow en Huggingface/Transformers. El método de conversión específico es usar el script correspondiente en ./Tools para convertir el modelo previamente capacitado en un archivo de formato NPZ, y Turbo usa la interfaz C ++ o Python para cargar el modelo de formato NPZ. En particular, consideramos que la mayoría de los modelos previamente capacitados están en formato de Pytorch y se usan con Python. Proporcionamos un atajo para llamar directamente a Python para el modelo guardado de Pytorch.
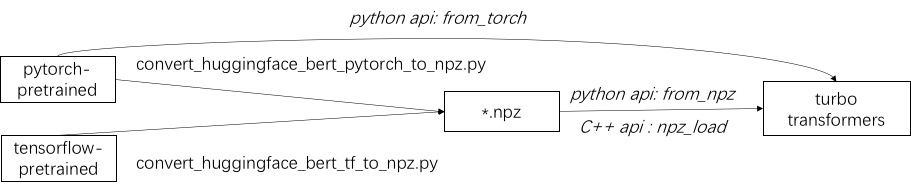
Consulte Ejemplos de modelos compatibles en ./example/python. TURBONLP/Translate-Demo muestra una demostración de aplicar turbotransformador en la tarea de traducción. Dado que el usuario de la aceleración de Bert siempre requiere un proceso de postprocesamiento personalizado para la tarea, proporcionamos un ejemplo de cómo escribir una aplicación de clasificación de secuencia.
Consulte ./example/cpp para un ejemplo. Nuestro ejemplo proporciona la GPU y dos métodos de llamadas de hilos múltiples CPU. Una es hacer una inferencia de Bert usando múltiples hilos; El otro es hacer múltiples inferencias de Bert, cada una de las cuales usa un hilo. Los usuarios pueden vincular turbo-transformadores a su código a través de add_subdirectory.
Por lo general, alimentando un lote de solicitudes de diferentes longitudes en un modelo Bert para inferencia, se requiere un salto cero para hacer que todas las solicitudes tengan la misma longitud. Por ejemplo, la lista de solicitudes de longitudes (100, 10, 50), necesita una etapa de preprocesamiento para encenderlas como longitudes (100, 100, 100). De esta manera, el 90% y el 50% del cálculo de las dos últimas secuencias se desperdician. Como se indica en un transformador efectivo, no es necesario encender los tensores de entrada. Como alternativa, solo tiene que rellenar las operaciones por lotes-gemm dentro de atenciones de varias cabezas, lo que se acumula a una pequeña propación de todo el cálculo de Bert. Por lo tanto, la mayoría de las operaciones de GEMM se procesan sin topes cero. Turbo proporciona un modelo como BertModelSmartBatch , incluida una técnica de lotes inteligentes. El ejemplo se presenta en ./example/python/bert_smart_pad.py.
¿Cómo saber los puntos de acceso de su código?
¿Cómo agregar una nueva capa?
Actualmente (junio de 2020), en el futuro cercano, agregaremos soporte para modelos de baja precisión (CPU INT8, GPU FP16). ¡Esperando su contribución!
Licencia de BSD 3 cláusula
Cite este documento, si usa turbotransformadores en su publicación de investigación.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Los artefactos del papel se pueden encontrar en Branch ppopp21_artifact_centos .
Aunque le recomendamos que publique su problema con los problemas de GitHub, también puede unirse a nuestro grupo de usuarios turbo.


