TurboTransformers
v0.5.1

محولات WeChat AI المفتوحة المصدر مع الخصائص التالية.
تم تطبيق محولات التوربينات على سيناريوهات خدمة BERT متعددة عبر الإنترنت في Tencent. على سبيل المثال ، يجلب تسارع 1.88x إلى خدمة WeChat FAQ ، وتسريع 2.11x إلى خدمة تحليل المعنويات السحابية العامة ، وتسارع 13.6x إلى نظام التوصية QQ. علاوة على ذلك ، تم تطبيقه بالفعل لبناء خدمات مثل chitchating والبحث والتوصية.
الجدول التالي هو مقارنة بين المحولات التوربينية والأعمال ذات الصلة.
| الأعمال ذات الصلة | أداء | بحاجة إلى المعالجة المسبقة | طول متغير | الاستخدام |
|---|---|---|---|---|
| Pytorch jit (وحدة المعالجة المركزية) | سريع | نعم | لا | صعب |
| Tensorrt (GPU) | سريع | نعم | لا | صعب |
| TF Faster Transformers (GPU) | سريع | نعم | لا | صعب |
| Onnx-Runtime (CPU/GPU) | سريع/سريع | لا | نعم | واسطة |
| Tensorflow-1.x (وحدة المعالجة المركزية/GPU) | بطيئة/متوسطة | نعم | لا | سهل |
| Pytorch (وحدة المعالجة المركزية/GPU) | متوسطة/متوسطة | لا | نعم | سهل |
| محولات توربو (وحدة المعالجة المركزية/GPU) | أسرع/أسرع | لا | نعم | سهل |
نحن ندعم حاليًا نماذج المحولات التالية.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]لاحظ أن البرامج النصية المبنية تنطبق فقط على إصدارات نظام التشغيل والبرامج (Pytorch ، OpenNMT ، المحولات ، إلخ). يرجى ضبطها وفقًا لاحتياجاتك.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
الطريقة 1: أريد أن أونجست
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
الطريقة 2: لا أريد أن تونست
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
قمنا أيضًا بإعداد صورة Docker التي تحتوي على إصدار وحدة المعالجة المركزية من محولات التوربينات ، بالإضافة إلى الأعمال الأخرى ذات الصلة ، أي onnxrt v1.2.0 و pytorch-jit على dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
قمنا أيضًا بإعداد صورة Docker التي تحتوي على إصدار GPU من محولات التوربينات.
docker pull thufeifeibear/turbo_transformers_gpu:latest
يمكن لـ Tensor Core تسريع الحوسبة على GPU. يتم تعطيله افتراضيًا في التحويلات التوربينية. إذا كنت ترغب في تشغيله ، قبل تجميع الرمز ، قم بتعيين الخيار مع _module_benchmakr في cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
يوفر TurboTransformers واجهات API C ++ / Python. نأمل أن نبذل قصارى جهدنا للتكيف مع مجموعة متنوعة من البيئات عبر الإنترنت لتقليل صعوبة التطوير للمستخدمين.
الخطوة الأولى في استخدام Turbo هي تحميل نموذج تم تدريبه مسبقًا. نحن نقدم وسيلة لتحميل النماذج Pytorch و TensorFlow مسبقًا في Luggingface/Transformers. تتمثل طريقة التحويل المحددة في استخدام البرنامج النصي المقابل. على وجه الخصوص ، نعتبر أن معظم النماذج المدربة مسبقًا في تنسيق Pytorch وتستخدم مع Python. نحن نقدم اختصار للاتصال مباشرة في بيثون لنموذج Pytorch المحفوظ.
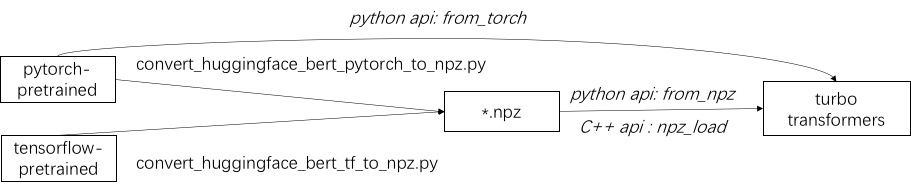
ارجع إلى أمثلة من النماذج المدعومة في ./example/python. يُظهر TurbonLP/Translate-Demo عرضًا لتطبيق التحول التوربيني في مهمة الترجمة. نظرًا لأن مستخدم Bert Acceleration يتطلب دائمًا عملية معالجة ما بعد المعالجة المخصصة للمهمة ، فإننا نقدم مثالًا على كيفية كتابة تطبيق تصنيف التسلسل.
الرجوع إلى ./example/cpp للحصول على مثال. يوفر مثالنا GPU وطرق الاتصال متعددة الخيوط. واحد هو القيام باستنتاج واحد بيرت باستخدام مؤشرات ترابط متعددة ؛ والآخر هو القيام باستدلال متعددة Bert ، كل منها باستخدام مؤشر ترابط واحد. يمكن للمستخدمين ربط محولات توربو إلى الكود الخاص بك من خلال add_subdirectory.
عادةً ما يتم تغذية مجموعة من طلبات الأطوال المختلفة في نموذج BERT للاستدلال ، يلزم وجود صفر لاتخاذ جميع الطلبات بنفس الطول. على سبيل المثال ، قائمة طلبات التقديم بالأطوال (100 ، 10 ، 50) ، تحتاج إلى مرحلة معالجة مسبقة لتسخينها كطوال (100 ، 100 ، 100). وبهذه الطريقة ، يضيع 90 ٪ و 50 ٪ من حساب التسلسل الأخيرتين. كما هو موضح في المحول الفعال ، ليس من الضروري وضع موترات الإدخال. كبديل ، عليك فقط أن تقوم بتجميع عمليات الدُفعات داخل الاهتمامات متعددة الرؤوس ، والتي تمتد إلى دعوى صغيرة من حساب BERT بأكمله. لذلك تتم معالجة معظم عمليات GEMM دون صفر. يوفر Turbo نموذجًا كـ BertModelSmartBatch بما في ذلك تقنية الدفع الذكية. يتم تقديم المثال في ./example/python/bert_smart_pad.py.
كيف تعرف النقاط الساخنة للرمز الخاص بك؟
كيف تضيف طبقة جديدة؟
حاليًا (يونيو 2020) ، في المستقبل القريب ، سنضيف دعمًا للنماذج ذات الدقة المنخفضة (CPU Int8 ، GPU FP16). نتطلع إلى مساهمتك!
ترخيص BSD 3-طبقة
استشهد بهذه الورقة ، إذا كنت تستخدم محولات التوربينات في منشور البحث الخاص بك.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
يمكن العثور على القطع الأثرية للورقة في فرع ppopp21_artifact_centos .
على الرغم من أننا نوصيك بنشر مشكلتك في مشكلات GitHub ، إلا أنه يمكنك أيضًا الانضمام إلى مجموعة مستخدمي Turbo الخاصة بنا.


