TurboTransformers
v0.5.1

Turbotransformer bersumber terbuka WeChat AI dengan karakteristik berikut.
Turbotransformers telah diterapkan pada beberapa skenario layanan BerT online di Tencent. Misalnya, ini membawa akselerasi 1,88x ke layanan FAQ WeChat, percepatan 2.11x ke layanan analisis sentimen cloud publik, dan akselerasi 13,6x ke sistem rekomendasi QQ. Selain itu, telah diterapkan untuk membangun layanan seperti mengejek, mencari, dan rekomendasi.
Tabel berikut adalah perbandingan turbotransformers dan pekerjaan terkait.
| Karya terkait | Pertunjukan | Butuh preprocess | Panjang variabel | Penggunaan |
|---|---|---|---|---|
| Pytorch Jit (CPU) | Cepat | Ya | TIDAK | Keras |
| Tensorrt (GPU) | Cepat | Ya | TIDAK | Keras |
| TF-Faster Transformers (GPU) | Cepat | Ya | TIDAK | Keras |
| Onnx-Runtime (CPU/GPU) | Cepat/cepat | TIDAK | Ya | Sedang |
| TensorFlow-1.x (CPU/GPU) | Lambat/sedang | Ya | TIDAK | Mudah |
| Pytorch (CPU/GPU) | Medium/Medium | TIDAK | Ya | Mudah |
| Turbo-Transformers (CPU/GPU) | Tercepat/tercepat | TIDAK | Ya | Mudah |
Kami saat ini mendukung model transformator berikut.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Perhatikan bahwa skrip bangunan hanya berlaku untuk OS dan perangkat lunak tertentu (Pytorch, OpenNMT, Transformers, dll.) Versi. Harap sesuaikan sesuai kebutuhan Anda.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Metode 1: Saya ingin unitest
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Metode 2: Saya tidak ingin unitest
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
Kami juga menyiapkan gambar Docker yang berisi versi CPU dari Turbotransformers, serta karya terkait lainnya, yaitu Onnxrt v1.2.0 dan Pytorch-Jit di Dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
Kami juga menyiapkan gambar Docker yang berisi versi GPU dari Turbotransformers.
docker pull thufeifeibear/turbo_transformers_gpu:latest
Inti tensor dapat mempercepat komputasi pada GPU. Ini dinonaktifkan secara default di turbotransformers. Jika Anda ingin menyalakannya, sebelum menyusun kode, atur opsi dengan_module_benchmakr di cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Turbotransformers menyediakan antarmuka API C ++ / Python. Kami berharap dapat melakukan yang terbaik untuk beradaptasi dengan berbagai lingkungan online untuk mengurangi kesulitan pengembangan bagi pengguna.
Langkah pertama dalam menggunakan Turbo adalah memuat model pra-terlatih. Kami menyediakan cara untuk memuat model Pytorch dan TensorFlow pra-terlatih dalam permukaan pelukan/transformer. Metode konversi spesifik adalah dengan menggunakan skrip yang sesuai di ./tools untuk mengubah model pra-terlatih menjadi file format NPZ, dan Turbo menggunakan antarmuka C ++ atau Python untuk memuat model format NPZ. Secara khusus, kami menganggap bahwa sebagian besar model pra-terlatih berada dalam format Pytorch dan digunakan dengan Python. Kami menyediakan jalan pintas untuk menelepon langsung di Python untuk model yang disimpan Pytorch.
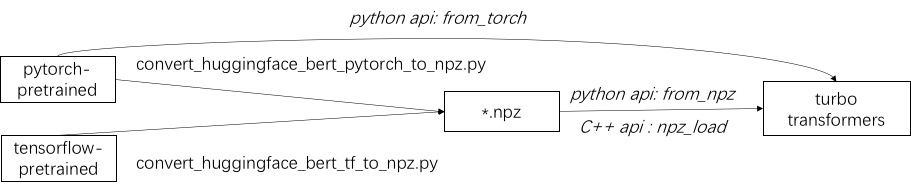
Lihat contoh model yang didukung di ./example/python. TurbonLP/Translate-Demo menunjukkan demo menerapkan turbotransformer dalam tugas terjemahan. Karena pengguna akselerasi Bert selalu membutuhkan proses pasca pemrosesan yang disesuaikan untuk tugas tersebut, kami memberikan contoh cara menulis aplikasi klasifikasi urutan.
Lihat ./example/cpp sebagai contoh. Contoh kami memberikan GPU dan dua metode panggilan multi-thread CPU. Salah satunya adalah melakukan satu inferensi Bert menggunakan banyak utas; Yang lainnya adalah melakukan beberapa inferensi Bert, yang masing -masing menggunakan satu utas. Pengguna dapat menautkan turbo-transformer ke kode Anda melalui Add_subdirectory.
Biasanya, memberi makan sejumlah permintaan yang berbeda ke dalam model Bert untuk inferensi, nol-padding diperlukan untuk membuat semua permintaan memiliki panjang yang sama. Misalnya, menyajikan daftar panjang panjang (100, 10, 50), Anda memerlukan tahap preprocessing untuk membawanya sebagai panjang (100, 100, 100). Dengan cara ini, 90% dan 50% dari komputasi dua urutan terakhir terbuang sia -sia. Seperti yang ditunjukkan dalam transformator yang efektif, tidak perlu untuk menempatkan tensor input. Sebagai alternatif, Anda hanya perlu memasukkan operasi Batch-Gemm di dalam perhatian multi-berkepala, yang diperuntukkan bagi sejumlah kecil dari seluruh perhitungan Bert. Oleh karena itu sebagian besar operasi GEMM diproses tanpa nol-padding. Turbo memberikan model sebagai BertModelSmartBatch termasuk teknik batching pintar. Contohnya disajikan dalam ./example/python/bert_smart_pad.py.
Bagaimana cara mengetahui hotspot kode Anda?
Bagaimana cara menambahkan lapisan baru?
Saat ini (Juni 2020), dalam waktu dekat, kami akan menambahkan dukungan untuk model presisi rendah (CPU INT8, GPU FP16). Melihat ke depan untuk kontribusi Anda!
Lisensi BSD 3 Clause
Kutip makalah ini, jika Anda menggunakan turbotransformers dalam publikasi penelitian Anda.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Artefak kertas dapat ditemukan di cabang ppopp21_artifact_centos .
Meskipun kami menyarankan Anda memposting masalah Anda dengan masalah gitub, Anda juga dapat bergabung dalam grup pengguna turbo kami.


