TurboTransformers
v0.5.1

Les turbotransformateurs Open Open WECHAT AI avec les caractéristiques suivantes.
Les turbotransformateurs ont été appliqués à plusieurs scénarios de service Bert en ligne dans Tencent. Par exemple, il apporte une accélération de 1,88x au service WECHAT FAQ, une accélération 2.11x au service d'analyse des sentiments du cloud public et une accélération de 13,6x au système de recommandation QQ. De plus, il a déjà été appliqué à la création de services tels que l'obchange, la recherche et la recommandation.
Le tableau suivant est une comparaison des turbotransformateurs et des travaux connexes.
| Travaux connexes | Performance | Besoin de prétraitement | Longueur variable | Usage |
|---|---|---|---|---|
| pytorch jit (CPU) | Rapide | Oui | Non | Dur |
| Tensorrt (GPU) | Rapide | Oui | Non | Dur |
| Transformers TF-Faster (GPU) | Rapide | Oui | Non | Dur |
| Onnx-runtime (CPU / GPU) | Rapide / rapide | Non | Oui | Moyen |
| Tensorflow-1.x (CPU / GPU) | Lent / moyen | Oui | Non | Facile |
| pytorch (CPU / GPU) | Moyen / moyen | Non | Oui | Facile |
| turbo-transformateurs (CPU / GPU) | Le plus rapide / le plus rapide | Non | Oui | Facile |
Nous prenons actuellement en charge les modèles de transformateurs suivants.
import torch
import transformers
import turbo_transformers
if __name__ == "__main__" :
turbo_transformers . set_num_threads ( 4 )
torch . set_num_threads ( 4 )
model_id = "bert-base-uncased"
model = transformers . BertModel . from_pretrained ( model_id )
model . eval ()
cfg = model . config
input_ids = torch . tensor (
([ 12166 , 10699 , 16752 , 4454 ], [ 5342 , 16471 , 817 , 16022 ]),
dtype = torch . long )
position_ids = torch . tensor (([ 1 , 0 , 0 , 0 ], [ 1 , 1 , 1 , 0 ]), dtype = torch . long )
segment_ids = torch . tensor (([ 1 , 1 , 1 , 0 ], [ 1 , 0 , 0 , 0 ]), dtype = torch . long )
torch . set_grad_enabled ( False )
torch_res = model (
input_ids , position_ids = position_ids , token_type_ids = segment_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
torch_seqence_output = torch_res [ 0 ][:, 0 , :]
tt_model = turbo_transformers . BertModel . from_torch ( model )
res = tt_model (
input_ids , position_ids = position_ids ,
token_type_ids = segment_ids ) # pooled_output, sequence_output
tt_seqence_output = res [ 0 ]Notez que les scripts de construction ne s'appliquent qu'à des versions spécifiques du système d'exploitation et du logiciel (Pytorch, OpenNMT, Transformers, etc.). Veuillez les ajuster en fonction de vos besoins.
git clone https://github.com/Tencent/TurboTransformers --recursive
sh tools/build_docker_cpu.sh
# optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash
Méthode 1: Je veux
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF
# you can switch between Openblas and MKL by modifying this line in CMakeList.txt
# set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]")
Méthode 2: Je ne veux pas
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
make -j 4
pip install `find . -name *whl`
cd benchmark
bash run_benchmark.sh
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2
Nous avons également préparé une image Docker contenant la version CPU des turbotransformateurs, ainsi que d'autres œuvres connexes, c'est-à-dire ONNXRT V1.2.0 et Pytorch-jit sur dockerhub
docker pull thufeifeibear/turbo_transformers_cpu:latest
git clone https://github.com/Tencent/TurboTransformers --recursive
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
cd benchmark
bash gpu_run_benchmark.sh
Nous avons également préparé une image Docker contenant une version GPU de turbotransformateurs.
docker pull thufeifeibear/turbo_transformers_gpu:latest
Le noyau du tenseur peut accélérer l'informatique sur GPU. Il est désactivé par défaut dans les turbotransformateurs. Si vous souhaitez l'allumer, avant de compiler le code, définissez l'option avec_module_benchmakr sur cmakelists.txt
option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON)
Les turbotransformateurs fournissent des interfaces API C ++ / Python. Nous espérons faire de notre mieux pour nous adapter à une variété d'environnements en ligne afin de réduire la difficulté du développement pour les utilisateurs.
La première étape de l'utilisation de Turbo consiste à charger un modèle pré-formé. Nous fournissons un moyen de charger des modèles pré-formés Pytorch et TensorFlow dans HuggingFace / Transformers. La méthode de conversion spécifique consiste à utiliser le script correspondant dans ./tools pour convertir le modèle pré-formé en un fichier de format NPZ, et Turbo utilise l'interface C ++ ou Python pour charger le modèle de format NPZ. En particulier, nous considérons que la plupart des modèles pré-formés sont au format Pytorch et utilisés avec Python. Nous fournissons un raccourci pour appeler directement dans Python pour le modèle enregistré Pytorch.
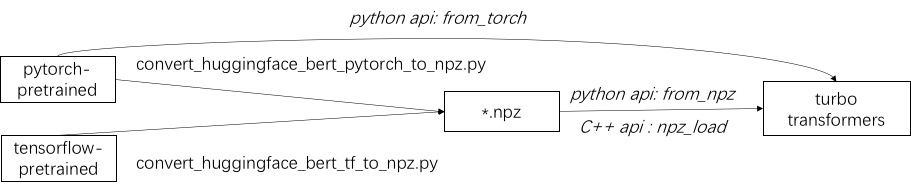
Reportez-vous à des exemples de modèles pris en charge dans ./example/python. TurbonLP / Translate-Demo montre une démo de l'application de turbotransformateur dans la tâche de traduction. Étant donné que l'utilisateur de l'accélération Bert nécessite toujours un processus de post-traitement personnalisé pour la tâche, nous fournissons un exemple de la façon d'écrire une application de classification de séquence.
Reportez-vous à ./example/cpp pour un exemple. Notre exemple fournit le GPU et deux méthodes d'appel multi-thread CPU. L'une consiste à faire une inférence Bert en utilisant plusieurs threads; L'autre consiste à faire plusieurs inférences Bert, chacune à l'aide d'un thread. Les utilisateurs peuvent lier des turbo-transformateurs à votre code via add_subdirectory.
Habituellement, l'alimentation d'un lot de demandes de longueurs différentes dans un modèle Bert pour l'inférence, un pading zéro est nécessaire pour faire que toutes les demandes ont la même longueur. Par exemple, des demandes de service de la liste des longueurs (100, 10, 50), vous avez besoin d'une étape de prétraitement pour les remplir en longueur (100, 100, 100). De cette façon, 90% et 50% des deux dernières séquences sont gaspillés. Comme indiqué dans le transformateur efficace, il n'est pas nécessaire de remplir les tenseurs d'entrée. En tant qu'alternative, il vous suffit de remplir les opérations par lot dans les attentions à plusieurs têtes, qui se présente à une petite réparation de l'ensemble du calcul Bert. Par conséquent, la plupart des opérations GEMM sont traitées sans pading zéro. Turbo fournit un modèle comme BertModelSmartBatch comprenant une technique de lots intelligents. L'exemple est présenté dans ./example/python/bert_smart_pad.py.
Comment connaître les points chauds de votre code?
Comment ajouter une nouvelle couche?
Actuellement (juin 2020), dans un avenir proche, nous ajouterons la prise en charge des modèles à faible précision (CPU INT8, GPU FP16). Dans l'attente de votre contribution!
Licence BSD 3-CLAUSE
Citez cet article, si vous utilisez des turbotransformateurs dans votre publication de recherche.
@inproceedings{fang2021turbotransformers,
title={TurboTransformers: an efficient GPU serving system for transformer models},
author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie},
booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages={389--402},
year={2021}
}
Les artefacts du papier se trouvent à Branch ppopp21_artifact_centos .
Bien que nous vous recommandons de publier votre problème avec les problèmes de GitHub, vous pouvez également vous joindre à notre groupe d'utilisateurs Turbo.


