Chinese Mixtral
v1.2
?? จีน | ภาษาอังกฤษ | เอกสาร/เอกสาร | ❓คำถาม/ปัญหา | การอภิปราย/การอภิปราย | ⚔ Arena/Arena

โครงการนี้ได้รับการพัฒนาขึ้นอยู่กับโมเดล Mixtral ที่เผยแพร่โดย Mistral.ai ซึ่งใช้สถาปัตยกรรม Moe Sparse โครงการนี้ใช้ข้อมูลปราศจากฉลากจีนขนาดใหญ่เพื่อดำเนินการฝึกอบรมที่เพิ่มขึ้นของจีนเพื่อให้ได้โมเดลพื้นฐาน Mixtral ของจีน และใช้การเรียนการสอนเพิ่มเติมเพื่อให้ได้รูปแบบการเรียนการสอนแบบ ผสมผสานระหว่างจีน แบบจำลองนี้รองรับ บริบท 32K (ทดสอบสูงสุด 128K) ซึ่งสามารถประมวลผลข้อความยาวได้อย่างมีประสิทธิภาพและในเวลาเดียวกันได้รับการปรับปรุงประสิทธิภาพที่สำคัญในการใช้เหตุผลทางคณิตศาสตร์การสร้างรหัส ฯลฯ เมื่อใช้ LLAMA.CPP เพื่อการใช้เหตุผลเชิงปริมาณ
รายงานทางเทคนิค : [Cui และ Yao, 2024] ทบทวนการปรับภาษา LLM: กรณีศึกษาเกี่ยวกับการผสมผสานของจีน [การตีความกระดาษ]
LLAMA LLAMA-2 & Alpaca-2 Mockup | Llama Llama & Alpaca Mockup | Llama จีนหลายรูปแบบและ Alpaca Mockup | Multimodal VLE | MINIRBT จีน Lert จีน ภาษาอังกฤษภาษาอังกฤษ Pert | Macbert จีน Electra จีน XLNET จีน | เบิร์ตจีน เครื่องมือกลั่นความรู้ TextBrewer | เครื่องมือตัดแบบจำลอง TextPruner | การกลั่นและการตัดธัญพืช
[2024/04/30] Chinese-Llama-Alpaca-3 ได้รับการปล่อยตัวอย่างเป็นทางการโอเพ่นซอร์ส Llama-3-Chinese-8b และ Llama-3-Chinese-8b-Instruct ตาม Llama-3 โปรดอ้างถึง: https://github.com/ymcui
[2024/03/27] เพิ่มรุ่น 1 บิต/2 บิต/3 บิตของรุ่น GGUF: [? HF]; ในเวลาเดียวกันโครงการนี้ได้ถูกนำไปใช้ในใจกลางของเครื่อง Sota! แพลตฟอร์มโมเดลยินดีต้อนรับสู่การติดตาม: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] เพิ่มโหมดการปรับใช้ OpenAI API เลียนแบบ ดูรายละเอียด: บันทึกการเปิดตัว v1.2 เวอร์ชัน
[2024/03/05] การฝึกอบรมแบบจำลองโอเพนซอร์สและรหัสการปรับแต่งเผยแพร่รายงานทางเทคนิค ดูรายละเอียด: บันทึกการเปิดตัว v1.1 เวอร์ชัน
[2024/01/29] เปิดตัวอย่างเป็นทางการกับจีน-มิกซ์ทราล (รุ่นฐาน) และภาษาจีน-มิกซ์ทรัล-Instruct (รุ่นคำแนะนำ/แชท) ดูรายละเอียด: บันทึกการเปิดตัว v1.0 เวอร์ชัน
| บท | อธิบาย |
|---|---|
| ?? ♂ การแนะนำแบบจำลอง | แนะนำลักษณะทางเทคนิคของโมเดลที่เกี่ยวข้องสั้น ๆ ของโครงการนี้ |
| ⏬โมเดลดาวน์โหลด | ที่อยู่ดาวน์โหลดรุ่น Mixtral จีน |
| การใช้เหตุผลและการปรับใช้ | แนะนำวิธีการหาปริมาณแบบจำลองและปรับใช้และสัมผัสกับรุ่นขนาดใหญ่โดยใช้คอมพิวเตอร์ส่วนบุคคล |
| เอฟเฟกต์โมเดล | มีการแนะนำผลกระทบของโมเดลในบางงาน |
| การฝึกอบรมและปรับแต่ง | แนะนำวิธีการฝึกอบรมและปรับแต่งโมเดล Mixtral ของจีน |
| ❓faq | ตอบคำถามที่พบบ่อย |
โครงการโอเพ่นซอร์สของจีน Mixtral และ Mixtral-Instruct รุ่นที่พัฒนาขึ้นตามแบบจำลอง Mixtral และคุณสมบัติหลักของมันมีดังนี้:
Mixtral เป็นแบบจำลองผู้เชี่ยวชาญไฮบริดแบบเบาบาง รุ่นนี้มีความแตกต่างอย่างมีนัยสำคัญจากรุ่นใหญ่รุ่นก่อนหน้านี้เช่น Llama ซึ่งส่วนใหญ่สะท้อนให้เห็นในจุดต่อไปนี้:
ต่อไปนี้เป็นแผนภาพโครงสร้างในกระดาษผสม:
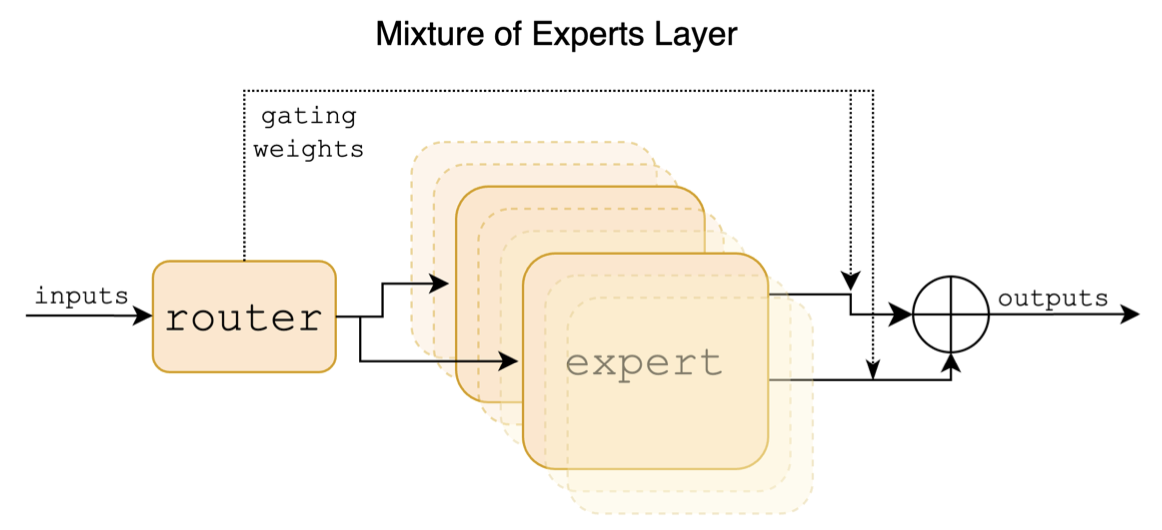
ซึ่งแตกต่างจากโครงการ Chinese-Llama-Alpaca และโครงการจีน-llama-Alpaca-2 โมเดล Mixtral สนับสนุนบริบท 32K (การวัดจริงสามารถเข้าถึง 128K) ผู้ใช้สามารถใช้รุ่นเดียวเพื่อแก้ปัญหาต่าง ๆ ที่มีความยาวต่างกัน
ต่อไปนี้เป็นการเปรียบเทียบแบบจำลองของโครงการนี้และสถานการณ์การใช้งานที่แนะนำ สำหรับการโต้ตอบการแชทเลือกเวอร์ชันแนะนำ
| รายการเปรียบเทียบ | มิกซ์ตรัลจีน | Instruct |
|---|---|---|
| ประเภทรุ่น | รุ่นฐาน | Directive/Chat Model (Class CHATGPT) |
| ขนาดรุ่น | 8x7b (เปิดใช้งานจริงประมาณ 13b) | 8x7b (เปิดใช้งานจริงประมาณ 13b) |
| จำนวนผู้เชี่ยวชาญ | 8 (เปิดใช้งานจริง 2) | 8 (เปิดใช้งานจริง 2) |
| ประเภทการฝึกอบรม | Causal-LM (CLM) | คำแนะนำการปรับแต่งอย่างละเอียด |
| วิธีการฝึกอบรม | Qlora + จำนวนเต็ม emb/lm-head | Qlora + จำนวนเต็ม emb/lm-head |
| โมเดลอะไรในการฝึกอบรม | Mixtral-8x7b-v0.1 ดั้งเดิม | มิกซ์ตรัลจีน |
| สื่อการฝึกอบรม | เรียงความทั่วไปที่ไม่มีเครื่องหมาย | ข้อมูลคำสั่งที่มีป้ายกำกับ |
| ขนาดคำศัพท์ | รายการคำศัพท์ดั้งเดิม 32000 | รายการคำศัพท์ดั้งเดิม 32000 |
| รองรับความยาวบริบท | 32K (วัดได้มากถึง 128K) | 32K (วัดได้มากถึง 128K) |
| เทมเพลตอินพุต | ไม่จำเป็น | จำเป็นต้องใช้เทมเพลต Mixtral-Instruct |
| สถานการณ์ที่เกี่ยวข้อง | ความต่อเนื่องของข้อความ: ให้ข้อความข้างต้นให้โมเดลสร้างข้อความต่อไปนี้ | คำสั่งความเข้าใจ: คำถามและคำตอบการเขียนการแชทการโต้ตอบ ฯลฯ |
นี่คือ 3 รุ่นที่แตกต่างกัน:
| ชื่อนางแบบ | พิมพ์ | ข้อมูลจำเพาะ | เวอร์ชันเต็ม (87 GB) | เวอร์ชัน LORA (2.4 GB) | เวอร์ชัน gguf |
|---|---|---|---|---|---|
| มิกซ์ทรัลจีน | รุ่นฐาน | 8x7b | [Baidu] [? hf] [? ModelsCope] | [Baidu] [? hf] [? ModelsCope] | [? hf] |
| Instruct | โมเดลคำสั่ง | 8x7b | [Baidu] [? hf] [? ModelsCope] | [Baidu] [? hf] [? ModelsCope] | [? hf] |
บันทึก
หากคุณไม่สามารถเข้าถึง HF ได้คุณสามารถพิจารณาเว็บไซต์กระจกบางแห่ง (เช่น HF-Mirror.com) โปรดค้นหาและแก้ไขวิธีการเฉพาะด้วยตัวคุณเอง
โมเดลที่เกี่ยวข้องในโครงการนี้ส่วนใหญ่สนับสนุนการหาปริมาณการใช้เหตุผลและวิธีการปรับใช้ต่อไปนี้ สำหรับรายละเอียดโปรดดูบทช่วยสอนที่เกี่ยวข้อง
| เครื่องมือ | คุณสมบัติ | ซีพียู | GPU | การหาปริมาณ | GUI | API | vllm | การสอน |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | ตัวเลือกเชิงปริมาณที่หลากหลายและการใช้เหตุผลในท้องถิ่นที่มีประสิทธิภาพ | [ลิงก์] | ||||||
| ? Transformers | อินเทอร์เฟซการอนุมานของ Transformers | [ลิงก์] | ||||||
| การเลียนแบบการโทร Openai API | การสาธิตเซิร์ฟเวอร์ที่จำลองอินเทอร์เฟซ OpenAI API | [ลิงก์] | ||||||
| Text-Generation-Webui | วิธีการปรับใช้อินเทอร์เฟซ Web Front-end | [ลิงก์] | ||||||
| คนขี้เกียจ | เฟรมเวิร์กโอเพ่นซอร์สสำหรับแอปพลิเคชันขนาดใหญ่ที่เหมาะสำหรับการพัฒนารอง | [ลิงก์] | ||||||
| หมวดหมู่ | คำถามและคำตอบในท้องถิ่นหลายเอกสาร | [ลิงก์] | ||||||
| สตูดิโอ LM | ซอฟต์แวร์แชทแบบหลายแพลตฟอร์ม (พร้อมอินเทอร์เฟซ) | [ลิงก์] |
เพื่อประเมินผลกระทบของแบบจำลองที่เกี่ยวข้องโครงการนี้ได้ทำการประเมินผลการกำเนิดและการประเมินผลกระทบตามวัตถุประสงค์ (ระดับ NLU) ตามลำดับและประเมินโมเดลขนาดใหญ่จากมุมที่แตกต่างกัน ขอแนะนำให้ผู้ใช้ทดสอบงานที่พวกเขากังวลและเลือกรุ่นที่ปรับให้เข้ากับงานที่เกี่ยวข้อง
C-Eval เป็นชุดประเมินผลแบบจำลองพื้นฐานของจีนที่ครอบคลุมซึ่งชุดการตรวจสอบและชุดทดสอบมีคำถามแบบปรนัย 1.3K และ 12.3K ซึ่งครอบคลุม 52 วิชาตามลำดับ โปรดดูโครงการนี้สำหรับรหัสการอนุมาน C-Eval: GitHub Wiki
| แบบจำลอง | พิมพ์ | ถูกต้อง (0-shot) | ถูกต้อง (5-shot) | ทดสอบ (0-shot) | ทดสอบ (5-shot) |
|---|---|---|---|---|---|
| Instruct | คำแนะนำ | 51.7 | 55.0 | 50.0 | 51.5 |
| มิกซ์ทรัลจีน | แท่น | 45.8 | 54.2 | 43.1 | 49.1 |
| MixTRAL-8X7B-Instruct-V0.1 | คำแนะนำ | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7b-v0.1 | แท่น | 47.3 | 54.6 | 46.1 | 50.3 |
| Chinese-Alpaca-2-13b | คำแนะนำ | 44.3 | 45.9 | 42.6 | 44.0 |
| จีน-llama-2-13b | แท่น | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU เป็นอีกชุดข้อมูลการประเมินผลของจีนที่ครอบคลุมโดยเฉพาะที่ใช้ในการประเมินความรู้และความสามารถในการใช้เหตุผลของแบบจำลองภาษาในบริบทของจีนซึ่งครอบคลุม 67 หัวข้อจากวิชาพื้นฐานสู่ระดับมืออาชีพขั้นสูงโดยมีคำถามแบบปรนัย 11.5K โปรดดูโครงการนี้สำหรับรหัสอนุมาน CMMLU: GitHub Wiki
| แบบจำลอง | พิมพ์ | ทดสอบ (0-shot) | ทดสอบ (5-shot) |
|---|---|---|---|
| Instruct | คำแนะนำ | 50.0 | 53.0 |
| มิกซ์ทรัลจีน | แท่น | 42.5 | 51.0 |
| MixTRAL-8X7B-Instruct-V0.1 | คำแนะนำ | 48.2 | 51.6 |
| Mixtral-8x7b-v0.1 | แท่น | 44.3 | 51.6 |
| Chinese-Alpaca-2-13b | คำแนะนำ | 43.2 | 45.5 |
| จีน-llama-2-13b | แท่น | 38.9 | 42.5 |
MMLU เป็นชุดข้อมูลการประเมินภาษาอังกฤษสำหรับการประเมินความสามารถในการเข้าใจภาษาธรรมชาติ มันเป็นหนึ่งในชุดข้อมูลหลักที่ใช้ในการประเมินความสามารถของโมเดลขนาดใหญ่ในปัจจุบัน ชุดการตรวจสอบและชุดทดสอบมีคำถามแบบปรนัย 1.5K และ 14.1K ตามลำดับครอบคลุม 57 วิชา โปรดดูโครงการนี้สำหรับรหัสการอนุมาน MMLU: GitHub Wiki
| แบบจำลอง | พิมพ์ | ถูกต้อง (0-shot) | ถูกต้อง (5-shot) | ทดสอบ (0-shot) | ทดสอบ (5-shot) |
|---|---|---|---|---|---|
| Instruct | คำแนะนำ | 65.1 | 69.6 | 67.5 | 69.8 |
| มิกซ์ทรัลจีน | แท่น | 63.2 | 67.1 | 65.5 | 68.3 |
| MixTRAL-8X7B-Instruct-V0.1 | คำแนะนำ | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-v0.1 | แท่น | 64.9 | 69.0 | 67.0 | 69.5 |
| Chinese-Alpaca-2-13b | คำแนะนำ | 49.6 | 53.2 | 50.9 | 53.5 |
| จีน-llama-2-13b | แท่น | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench เป็นมาตรฐานสำหรับการประเมินความสามารถในการเข้าใจข้อความที่ยาวนานของรุ่นขนาดใหญ่ ประกอบด้วย 6 หมวดหมู่หลักและ 20 งานที่แตกต่างกัน ความยาวเฉลี่ยของงานส่วนใหญ่อยู่ระหว่าง 5K-15K และมีข้อมูลการทดสอบประมาณ 4.75K ต่อไปนี้เป็นผลการประเมินผลของโมเดลโครงการนี้ในงานภาษาจีนนี้ (รวมถึงงานโค้ด) โปรดดูโครงการนี้สำหรับรหัสการอนุมาน Longbench: GitHub Wiki
| แบบจำลอง | QA เอกสารเดียว | QA หลายเอกสาร | สรุป | การเรียนรู้ FS | เสร็จสิ้นรหัส | งานสังเคราะห์ | เฉลี่ย |
|---|---|---|---|---|---|---|---|
| Instruct | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| มิกซ์ทรัลจีน | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| MixTRAL-8X7B-Instruct-V0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| Chinese-Alpaca-2-13b-16k | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinese-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinese-Alpaca-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinese-Llama-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
ภายใต้ llama.cpp ประสิทธิภาพของรุ่นเวอร์ชันเชิงปริมาณของจีน-มิกซ์ทรัลได้รับการทดสอบดังแสดงในตารางต่อไปนี้
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | iq2_xs | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ขนาด (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| ความเร็ว M3 Max | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| ความเร็ว A100 | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
บันทึก
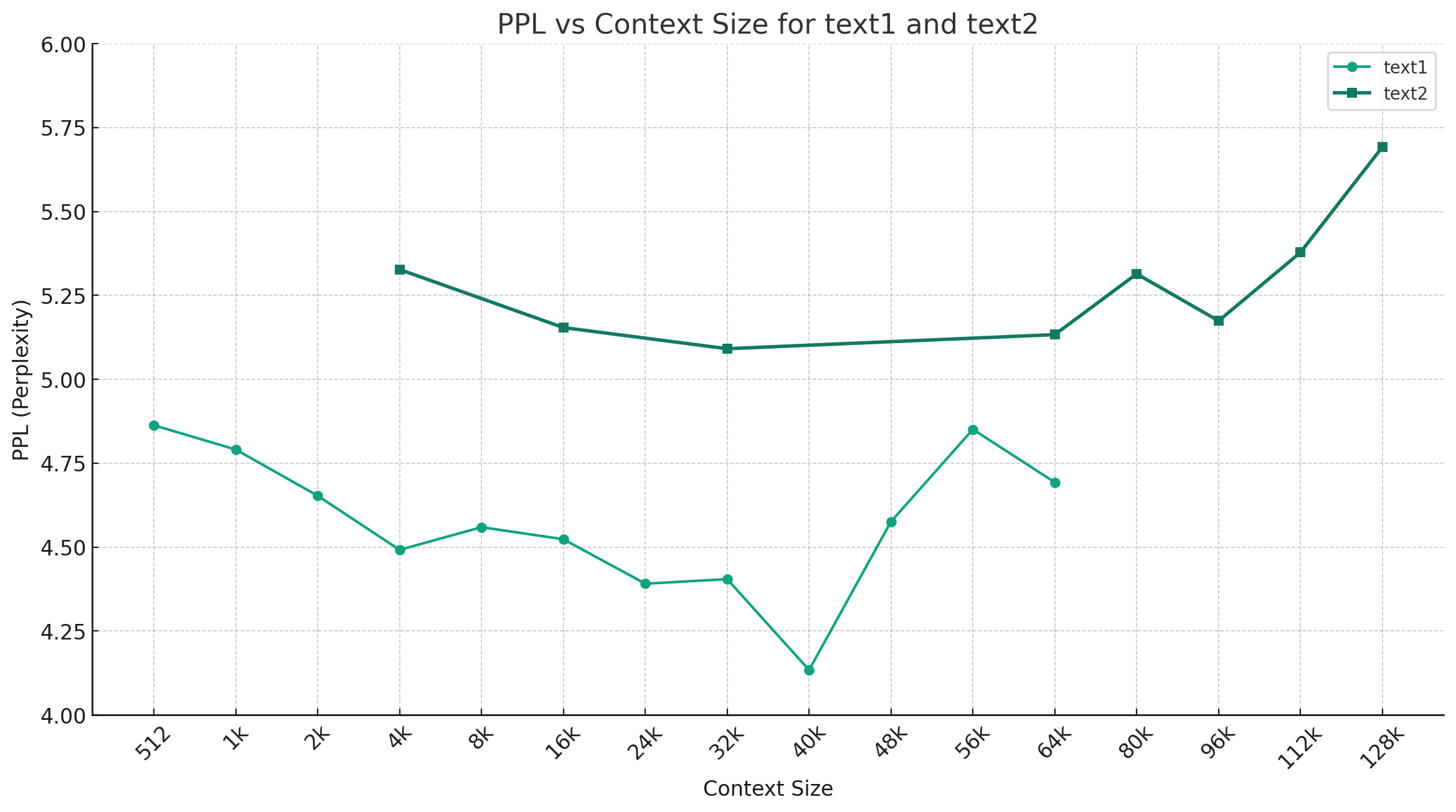
การเลือกตัวอย่างด้านล่างของจีน-Mixtral-Q4_0 เป็นตัวอย่างด้านล่างแสดงแนวโน้มการเปลี่ยนแปลง PPL ภายใต้ความยาวบริบทที่แตกต่างกันและมีการเลือกข้อมูลข้อความธรรมดาสองชุดที่แตกต่างกัน ผลการทดลองแสดงให้เห็นว่าความ ยาวบริบทที่รองรับโดยโมเดล Mixtral นั้นเกินกว่า 32K เล็กน้อยและยังคงมีประสิทธิภาพที่ดีภายใต้บริบท 64K+ (วัดได้สูงถึง 128K)
เทมเพลตคำสั่ง:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
หมายเหตุ: <s> และ </s> เป็นโทเค็นพิเศษที่แสดงถึงจุดเริ่มต้นและจุดสิ้นสุดของลำดับในขณะที่ [INST] และ [/INST] เป็นสตริงธรรมดา
โปรดตรวจสอบว่ามีการแก้ปัญหาอยู่แล้วในคำถามที่พบบ่อยหรือไม่ก่อนที่คุณจะพูดถึงปัญหา สำหรับคำถามและคำตอบเฉพาะโปรดดูโครงการนี้ GitHub Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}โครงการนี้ได้รับการพัฒนาตามโมเดล Mixtral ที่เผยแพร่โดย Mistral.ai โปรดปฏิบัติตามข้อตกลงใบอนุญาตโอเพ่นซอร์ส Mixtral อย่างเคร่งครัดในระหว่างการใช้งาน หากการใช้รหัสบุคคลที่สามมีส่วนเกี่ยวข้องให้แน่ใจว่าได้ปฏิบัติตามข้อตกลงสิทธิ์การใช้งานโอเพ่นซอร์สที่เกี่ยวข้อง เนื้อหาที่สร้างขึ้นโดยแบบจำลองอาจส่งผลกระทบต่อความแม่นยำเนื่องจากวิธีการคำนวณปัจจัยสุ่มและการสูญเสียความแม่นยำเชิงปริมาณ ดังนั้นโครงการนี้ไม่ได้ให้การรับประกันความถูกต้องของผลลัพธ์ของโมเดลและจะไม่รับผิดชอบต่อการสูญเสียใด ๆ ที่เกิดจากการใช้ทรัพยากรที่เกี่ยวข้องและผลลัพธ์ผลลัพธ์ หากรูปแบบที่เกี่ยวข้องของโครงการนี้ถูกใช้เพื่อวัตถุประสงค์ทางการค้าผู้พัฒนาจะปฏิบัติตามกฎหมายและข้อบังคับในท้องถิ่นเพื่อให้แน่ใจว่าสอดคล้องกับเนื้อหาผลลัพธ์ของโมเดล โครงการนี้จะไม่รับผิดชอบต่อผลิตภัณฑ์หรือบริการใด ๆ ที่ได้รับจากนั้น
หากคุณมีคำถามใด ๆ โปรดส่งในปัญหา GitHub ถามคำถามอย่างสุภาพและสร้างชุมชนการสนทนาที่กลมกลืนกัน


