Chinese Mixtral
v1.2
? Chinesisch | Englisch | Dokumente/Dokumente | ❓ Fragen/Probleme | Diskussionen/Diskussionen | ⚔️ Arena/Arena

Dieses Projekt basiert auf dem von Mistral.ai veröffentlichten Mixtral -Modell, das die spärliche Moe -Architektur verwendet. In diesem Projekt werden groß angelegte chinesische markierungsfreie Daten verwendet, um das chinesische inkrementelle Training durchzuführen, um das chinesische Mixtral- Basismodell zu erhalten, und die Befehlsfeinanpassung weiter verwendet, um das chinesische Mixtral-Instruct- Anweisungsmodell zu erhalten. Das Modell unterstützt nativ 32K -Kontext (bis zu 128K) , der einen langen Text effektiv verarbeiten und gleichzeitig signifikante Leistungsverbesserungen im mathematischen Denken, Codegenerierung usw. erzielen kann.
Technischer Bericht : [Cui und Yao, 2024] Überdenken der LLM -Sprachanpassung: Eine Fallstudie zum chinesischen Mixtral [Papierinterpretation]
Chinesische Lama-2 & Alpaca-2 Mockup | Chinese Lama & Alpaca Mockup | Multimodales chinesisches Lama & Alpaca Mockup | Multimodale VLE | Chinesische Minirbt | Chinesische LERT | Chinese Englisch Pert | Chinesischer Macbert | Chinesische Elektrik | Chinesische xlnet | Chinesische Bert | Knowledge Destillation Tool Textbrewer | Modell Schneidwerkzeug Textpruner | Destillation und Schnittintegrationskorn
[2024/04/30] Chinese-Llama-Alpaca-3 wurde offiziell veröffentlicht, Open Source LLAMA-3-chinese-8b und Llama-3-chinese-8b-instruct basierend auf Llama-3, bitte beziehen
[2024/03/27] 1-Bit/2-Bit/3-Bit quantitative Version des GGUF-Modells hinzufügen: [? HF]; Gleichzeitig wurde dieses Projekt im Herzen von Machine Sota eingesetzt! Modellplattform, Willkommen zu folgen: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Fügen Sie einen Mimic OpenAI -API -Bereitstellungsmodus hinzu. Details anzeigen: v1.2 Version Release -Protokoll
[2024/03/05] Open-Source-Modelltraining und Feinabstimmung Code, veröffentlichen technische Berichte. Details anzeigen: v1.1 Version Release -Protokoll
[2024/01/29] Offiziell veröffentlicht chinesisch-mixtral (Basismodell) und chinesisch-mixtral-instruct (Anweisungen/Chat-Modell). Details anzeigen: V1.0 Version Release -Protokoll
| Kapitel | beschreiben |
|---|---|
| ? | Stellen Sie kurz die technischen Merkmale der relevanten Modelle dieses Projekts ein |
| ⏬Model Download | Chinesische Mixtralmodell -Download -Adresse |
| Argumentation und Bereitstellung | Führen Sie vor |
| Modelleffekt | Der Effekt des Modells auf einige Aufgaben wird eingeführt |
| Training und gute Melodie | Einführung, wie man das chinesische Mixtralmodell trainiert und fein stimmt |
| ❓faq | Antworten auf einige FAQs |
Dieses Projekt Open Source Chinese Mixtral und Chinese Mixtral-Instruct-Modelle, die basierend auf Mixtral-Modell entwickelt wurden, sind wie folgt:
Mixtral ist ein spärliches Hybrid -Expertenmodell. Dieses Modell weist signifikante Unterschiede zu früheren Mainstream-großflächigen Modellen wie Lama auf, was sich hauptsächlich in den folgenden Punkten widerspiegelt:
Das Folgende ist ein strukturelles Diagramm im Mischpapier:
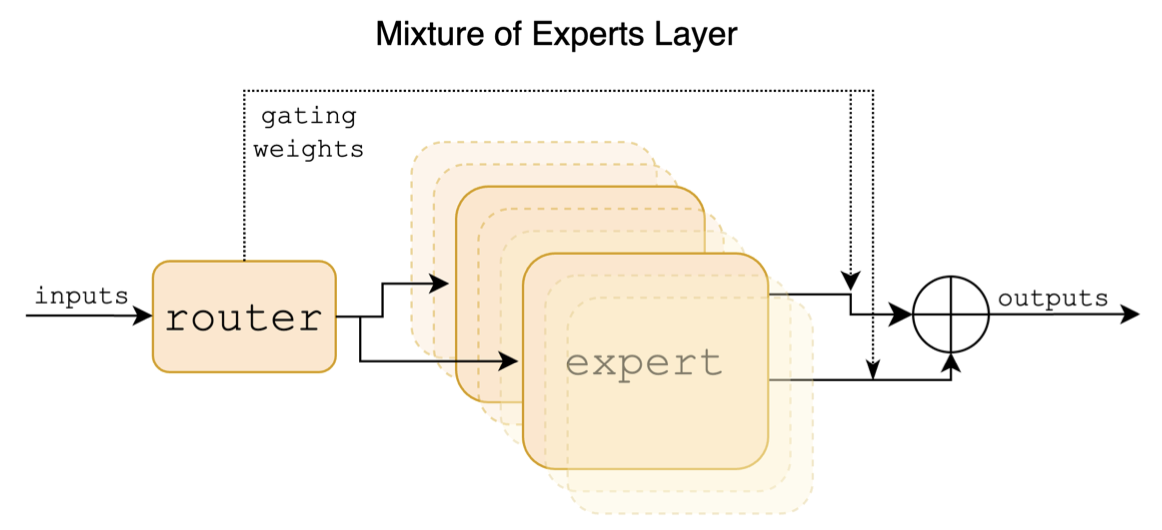
Im Gegensatz zu den Projekten Chinesen-Llama-Alpaca- und Chinesen-Llama-Alpaca-2-Projekte unterstützt das Mixtral-Modell den 32-km-Kontext nativ (die tatsächliche Messung kann 128K erreichen). Benutzer können ein einzelnes Modell verwenden, um verschiedene Aufgaben unterschiedlicher Längen zu lösen.
Das Folgende ist ein Vergleich des Modells dieses Projekts und der empfohlenen Nutzungsszenarien. Für die Chat -Interaktion wählen Sie die Version an.
| Vergleichselemente | Chinesische Mischung | Chinesische Mischungstruktur |
|---|---|---|
| Modelltyp | Basismodell | Richtlinie/Chat -Modell (Klasse Chatgpt) |
| Modellgröße | 8x7b (tatsächlich um 13b aktiviert) | 8x7b (tatsächlich um 13b aktiviert) |
| Anzahl der Experten | 8 (tatsächlich aktiviert 2) | 8 (tatsächlich aktiviert 2) |
| Trainingstyp | Kausal-lm (clm) | Befürworter feiner Einstellung |
| Trainingsmethode | Qlora + Vollmenge EMB/LM-Head | Qlora + Vollmenge EMB/LM-Head |
| Welches Modell zu trainieren | Original Mixtral-8x7b-V0.1 | Chinesische Mischung |
| Trainingsmaterialien | Nicht markierter allgemeiner Aufsatz | Beschriftete Anweisungsdaten |
| Wortschatzgröße | Original -Vokabularliste, 32000 | Original -Vokabularliste, 32000 |
| Unterstützt die Kontextlänge | 32k (tatsächlich gemessen bis zu 128K) | 32k (tatsächlich gemessen bis zu 128K) |
| Eingabemittel | unnötig | Müssen die Mixtral-In-Struktur-Vorlage anwenden |
| Anwendbare Szenarien | Textdauer: Lassen Sie das Modell den folgenden Text generieren | Befehlsverständnis: Fragen und Antworten, Schreiben, Chat, Interaktion usw. |
Hier sind 3 verschiedene Arten von Modellen:
| Modellname | Typ | Spezifikation | Vollversion (87 GB) | Lora -Version (2,4 GB) | GGUF -Version |
|---|---|---|---|---|---|
| Chinesisch-mixtral | Basismodell | 8x7b | [Baidu] [? HF] [? ModelsCope] | [Baidu] [? HF] [? ModelsCope] | [? HF] |
| Chinese-Mixtral-Instruction | Anweisungsmodell | 8x7b | [Baidu] [? HF] [? ModelsCope] | [Baidu] [? HF] [? ModelsCope] | [? HF] |
Notiz
Wenn Sie nicht auf HF zugreifen können, können Sie einige Mirror-Websites (z. B. hf-mirror.com) in Betracht ziehen. Finden und lösen Sie die spezifischen Methoden selbst.
Die relevanten Modelle in diesem Projekt unterstützen hauptsächlich die folgenden Methoden zur Quantisierung, Argumentation und Bereitstellung. Weitere Informationen finden Sie im entsprechenden Tutorial.
| Werkzeug | Merkmale | CPU | GPU | Quantifizierung | GUI | API | vllm | Tutorial |
|---|---|---|---|---|---|---|---|---|
| lama.cpp | Reiche quantitative Optionen und effiziente lokale Argumentation | ✅ | ✅ | ✅ | ✅ | [Link] | ||
| ? Transformatoren | Native Transformers Inference Interface | ✅ | ✅ | ✅ | ✅ | ✅ | [Link] | |
| Nachahmung von OpenAI -API -Aufrufen | Server -Demo, die die OpenAI -API -Schnittstelle emuliert | ✅ | ✅ | ✅ | ✅ | ✅ | [Link] | |
| Text-Generation-Webui | So bereitstellen Sie die Front-End-Web-UI-Schnittstelle | ✅ | ✅ | ✅ | ✅ | ✅ | [Link] | |
| Langchain | Open Source-Framework für eine groß angelegte Anwendung, die für die Sekundärentwicklung geeignet ist | ✅ | ✅ | ✅ | [Link] | |||
| privatgpt | Multi-Dokument-lokaler Frage- und Antwort-Framework | ✅ | ✅ | ✅ | [Link] | |||
| LM Studio | Multi-Plattform-Chat-Software (mit Schnittstelle) | ✅ | ✅ | ✅ | ✅ | ✅ | [Link] |
Um die Auswirkungen verwandter Modelle zu bewerten, führte dieses Projekt eine generative Effektbewertung und objektive Effektbewertung (NLU -Klasse) durch und bewertete das große Modell aus verschiedenen Blickwinkeln. Es wird empfohlen, dass Benutzer auf Aufgaben testen, über die sie besorgt sind, und Modelle auszuwählen, die sich an verwandte Aufgaben anpassen.
C-Eval ist eine umfassende chinesische Basismodell-Bewertungssuite, in der der Verifizierungssatz und der Testsatz 1,3K- und 12,3K-Multiple-Choice-Fragen enthalten und 52 Probanden abdecken. Weitere Informationen finden Sie in diesem Projekt für C-Eval-Inferenzcode: Github Wiki
| Modelle | Typ | Gültig (0-shot) | Gültig (5-shot) | Test (0-Shot) | Test (5-Shot) |
|---|---|---|---|---|---|
| Chinese-Mixtral-Instruction | Anweisung | 51.7 | 55.0 | 50.0 | 51,5 |
| Chinesisch-mixtral | Sockel | 45,8 | 54.2 | 43.1 | 49.1 |
| MIMTRAL-8X7B-ISTRUCT-V0.1 | Anweisung | 51.6 | 54.0 | 48,7 | 50.7 |
| MIMTRAL-8X7B-V0.1 | Sockel | 47,3 | 54.6 | 46.1 | 50.3 |
| Chinesisch-Alpaka-2-13b | Anweisung | 44.3 | 45,9 | 42.6 | 44.0 |
| Chinese-Llama-2-13b | Sockel | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU ist ein weiterer umfassender Datensatz für chinesische Bewertungen, der speziell zur Bewertung der Wissens- und Argumentationsfähigkeit von Sprachmodellen im chinesischen Kontext verwendet wird und 67 Themen von grundlegenden Fächern bis hin zu fortgeschrittener professioneller Ebene mit insgesamt 11,5.000 Multiple-Choice-Fragen abdeckt. Weitere Informationen finden Sie in diesem Projekt für CMMLU -Inferenzcode: Github Wiki
| Modelle | Typ | Test (0-Shot) | Test (5-Shot) |
|---|---|---|---|
| Chinese-Mixtral-Instruction | Anweisung | 50.0 | 53.0 |
| Chinesisch-mixtral | Sockel | 42,5 | 51.0 |
| MIMTRAL-8X7B-ISTRUCT-V0.1 | Anweisung | 48.2 | 51.6 |
| MIMTRAL-8X7B-V0.1 | Sockel | 44.3 | 51.6 |
| Chinesisch-Alpaka-2-13b | Anweisung | 43.2 | 45,5 |
| Chinese-Llama-2-13b | Sockel | 38,9 | 42,5 |
MMLU ist ein englischer Bewertungsdatensatz zur Bewertung der Fähigkeit zum Verständnis der natürlichen Sprache. Es ist eines der Hauptdatensätze, mit denen große Modellfunktionen heute bewertet werden. Der Bestätigungssatz und der Testsatz enthalten 1,5K- und 14,1K-Multiple-Choice-Fragen, die 57 Probanden abdecken. Weitere Informationen finden Sie in diesem Projekt für MMLU -Inferenzcode: Github Wiki
| Modelle | Typ | Gültig (0-shot) | Gültig (5-shot) | Test (0-Shot) | Test (5-Shot) |
|---|---|---|---|---|---|
| Chinese-Mixtral-Instruction | Anweisung | 65.1 | 69.6 | 67,5 | 69,8 |
| Chinesisch-mixtral | Sockel | 63.2 | 67.1 | 65,5 | 68,3 |
| MIMTRAL-8X7B-ISTRUCT-V0.1 | Anweisung | 68,5 | 70,4 | 68,2 | 70,2 |
| MIMTRAL-8X7B-V0.1 | Sockel | 64.9 | 69.0 | 67.0 | 69,5 |
| Chinesisch-Alpaka-2-13b | Anweisung | 49,6 | 53.2 | 50.9 | 53,5 |
| Chinese-Llama-2-13b | Sockel | 46,8 | 50.0 | 46.6 | 51.8 |
Longbench ist ein Benchmark für die Bewertung der Fähigkeit des langen Textverständnisses eines großen Modells. Es besteht aus 6 Hauptkategorien und 20 verschiedenen Aufgaben. Die durchschnittliche Länge der meisten Aufgaben liegt zwischen 5K-15K und enthält etwa 4,75.000 Testdaten. Das Folgende ist der Bewertungseffekt dieses Projektmodells auf diese chinesische Aufgabe (einschließlich Codeaufgaben). In diesem Projekt finden Sie in Longbench Inferenzcode: Github Wiki
| Modelle | Einzeldokument QA | Multi-Dokument-QA | Zusammenfassung | FS Lernen | Code -Abschluss | Syntheseaufgabe | Durchschnitt |
|---|---|---|---|---|---|---|---|
| Chinese-Mixtral-Instruction | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89,5 | 48.1 |
| Chinesisch-mixtral | 32.0 | 23.7 | 0,4 | 42,5 | 27.4 | 14.0 | 23.3 |
| MIMTRAL-8X7B-ISTRUCT-V0.1 | 56,5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52,5 |
| MIMTRAL-8X7B-V0.1 | 35.5 | 9.5 | 16.4 | 46,5 | 57,2 | 83,5 | 41,4 |
| Chinesisch-Alpaka-2-13b-16k | 47,9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinese-Llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinese-Alpaca-2-7b-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44,6 | 5.0 | 29.3 |
| Chinese-Llama-2-7b-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
Unter llama.cpp wurde die Leistung des chinesisch-mixtralen quantitativen Versionsmodells getestet, wie in der folgenden Tabelle gezeigt.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | Iq3_xxs | Q2_K | Iq2_xs | Iq2_xxs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Größe (GB) | 87.0 | 46,2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| Bpw | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ppl | - - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 Maximale Geschwindigkeit | - - | - - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - - | 29.1 | - - | - - |
| A100 Geschwindigkeit | - - | - - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Notiz
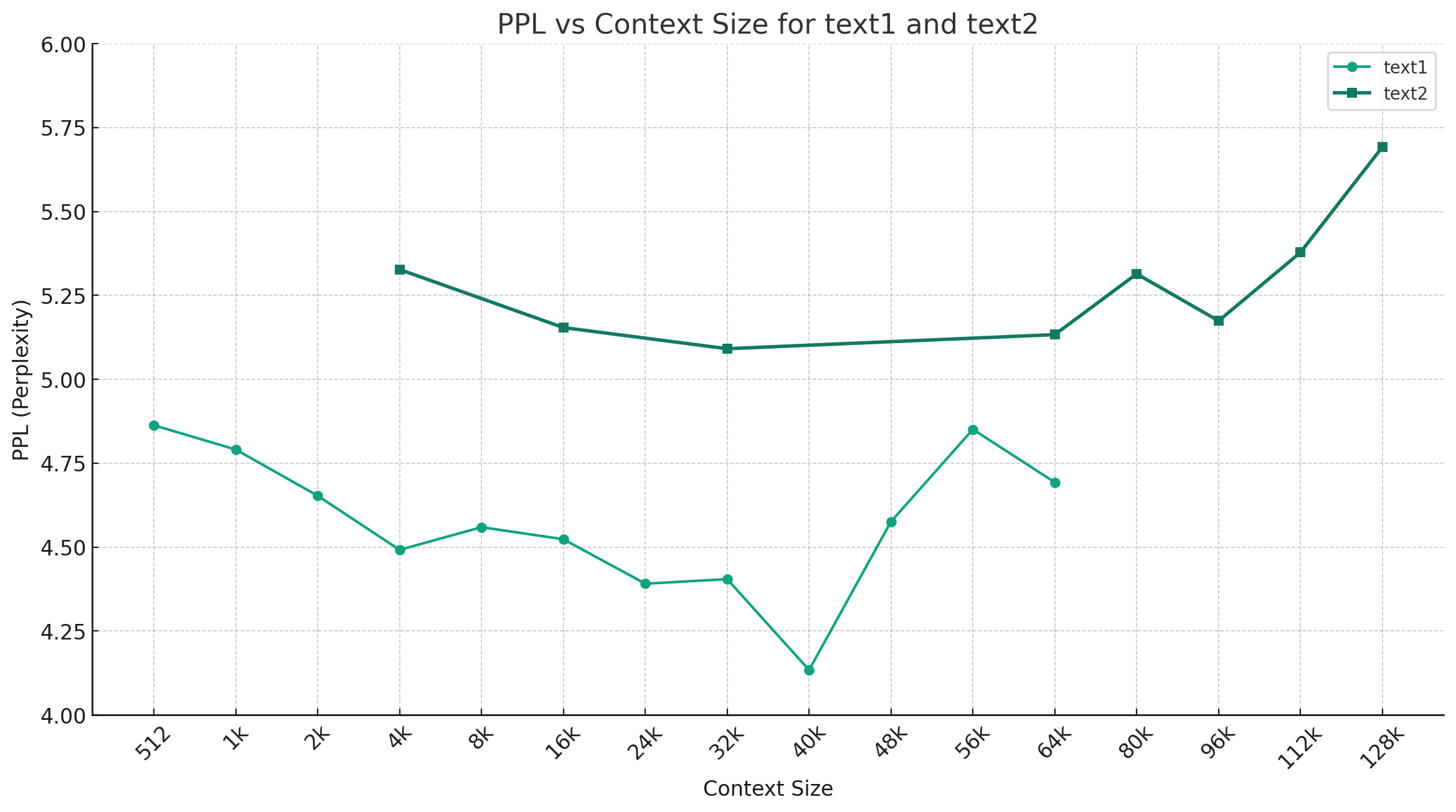
In der folgenden Abbildung zeigt die Abbildung den PPL-Änderungstrend unter verschiedenen Kontextlängen und zwei verschiedene Sätze von Klartextdaten wurden ausgewählt. Die experimentellen Ergebnisse zeigen, dass die vom Mixtral -Modell unterstützte Kontextlänge den nominalen 32k überschritten hat und immer noch eine gute Leistung unter 64 K+ Kontext hat (tatsächlich gemessen bis zu 128K).
Richtlinienvorlage:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
HINWEIS: <s> und </s> sind spezielle Token, die den Beginn und das Ende einer Sequenz darstellen, während [INST] und [/INST] gewöhnliche Zeichenfolgen sind.
Bitte überprüfen Sie, ob die Lösung in den FAQ bereits vorhanden ist, bevor Sie das Problem erwähnen. Weitere Fragen und Antworten finden Sie in diesem Projekt Github Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Dieses Projekt basiert auf dem von Mistral.ai veröffentlichten Mixtral -Modell. Bitte halten Sie sich die Mixtral Open -Source -Lizenzvereinbarung während der Verwendung ausschließlich ein. Wenn der Code von Drittanbietern verwendet wird, müssen Sie die entsprechende Open-Source-Lizenzvereinbarung einhalten. Der vom Modell erzeugte Inhalt kann seine Genauigkeit aufgrund von Berechnungsmethoden, zufälligen Faktoren und quantitativen Genauigkeitsverlusten beeinflussen. Daher bietet dieses Projekt keine Garantie für die Genauigkeit der Modellausgabe, und es haftet auch nicht für Verluste, die durch die Verwendung relevanter Ressourcen und Ausgabeergebnisse verursacht werden. Wenn die relevanten Modelle dieses Projekts für kommerzielle Zwecke verwendet werden, muss der Entwickler die lokalen Gesetze und Vorschriften einhalten, um die Einhaltung des Ausgangsinhalts des Modells sicherzustellen. Dieses Projekt haftet nicht für Produkte oder Dienstleistungen, die daraus abgeleitet werden.
Wenn Sie Fragen haben, senden Sie diese bitte in Github -Problem. Stellen Sie die Fragen höflich und bauen Sie eine harmonische Diskussionsgemeinschaft auf.


