Chinese Mixtral
v1.2
??中国語|英語|ドキュメント/ドキュメント| ❓質問/問題|ディスカッション/ディスカッション| ⚔️アリーナ/アリーナ

このプロジェクトは、Sparse Moeアーキテクチャを使用するMistral.aiによってリリースされたMixtralモデルに基づいて開発されています。このプロジェクトでは、中国の大規模なラベルフリーデータを使用して中国のインクリメンタルトレーニングを実施して、中国の混合トラル基本モデルを取得し、命令の微調整をさらに使用して、中国のミックストラルインストラクション指導モデルを取得します。モデルはネイティブに32Kコンテキスト(最大128Kテスト)をサポートします。これは、長いテキストを効果的に処理することができ、同時に数学的推論、コード生成などの大幅なパフォーマンスの改善を実現します。
テクニカルレポート:[CUI and Yao、2024] LLM言語適応の再考:中国のMixtralのケーススタディ[紙の解釈]
中国のllama-2&alpaca-2 mockup |中国のllama&alpaca mockup |マルチモーダルチャイニーズラマ&アルパカモックアップ|マルチモーダルVLE |中国のミニルブ|中国語のレート|中国の英語のパート|中国のマッバート|中国のエレクトラ|中国のxlnet |中国のバート|知識蒸留ツールTextBrewer |モデル切削工具TextPruner |蒸留および切断統合穀物
[2024/04/30]中国語 - ラマ - アルパカ-3が公式にリリースされました、オープンソースのllama-3-chinese-8bおよびllama-3-chinese-8b-instruct lalama-3に基づいて、https://github.com/ymcui/chinese-llama-alpaca-3を参照してください
[2024/03/27] GGUFモデルの1ビット/2ビット/3ビットの定量バージョンを追加:[?HF];同時に、このプロジェクトはMachine Sotaの中心に展開されています!モデルプラットフォーム、歓迎:https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26]模倣Openai API展開モードを追加します。詳細を表示:V1.2バージョンリリースログ
[2024/03/05]オープンソースモデルトレーニングと微調整コード、技術レポートを公開します。詳細を表示:V1.1バージョンリリースログ
[2024/01/29]中国のミックストラル(基本モデル)および中国のミックストラル型(命令/チャットモデル)を正式にリリースしました。詳細を表示:V1.0バージョンリリースログ
| 章 | 説明する |
|---|---|
| ?? | このプロジェクトの関連モデルの技術的特性を簡単に紹介します |
| modelダウンロード | 中国のミックストラルモデルのダウンロードアドレス |
| 推論と展開 | モデルを定量化し、パーソナルコンピューターを使用して大規模なモデルを展開して体験する方法を紹介する |
| ?モデル効果 | いくつかのタスクに対するモデルの効果が導入されています |
| トレーニングと微調整 | 中国のミックストラルモデルを訓練して微調整する方法の紹介 |
| ❓faq | いくつかのFAQへの返信 |
このプロジェクトのオープンソース中国のミックストラルと中国のミックストラルインストラクションモデルは、MixTralモデルに基づいて開発されており、その主な機能は次のとおりです。
Mixtralは、スパースハイブリッドエキスパートモデルです。このモデルには、Llamaなどの以前の主流の大規模モデルと大きな違いがあります。これは、主に次のポイントに反映されています。
以下は、ミックストラルペーパーの構造図です。
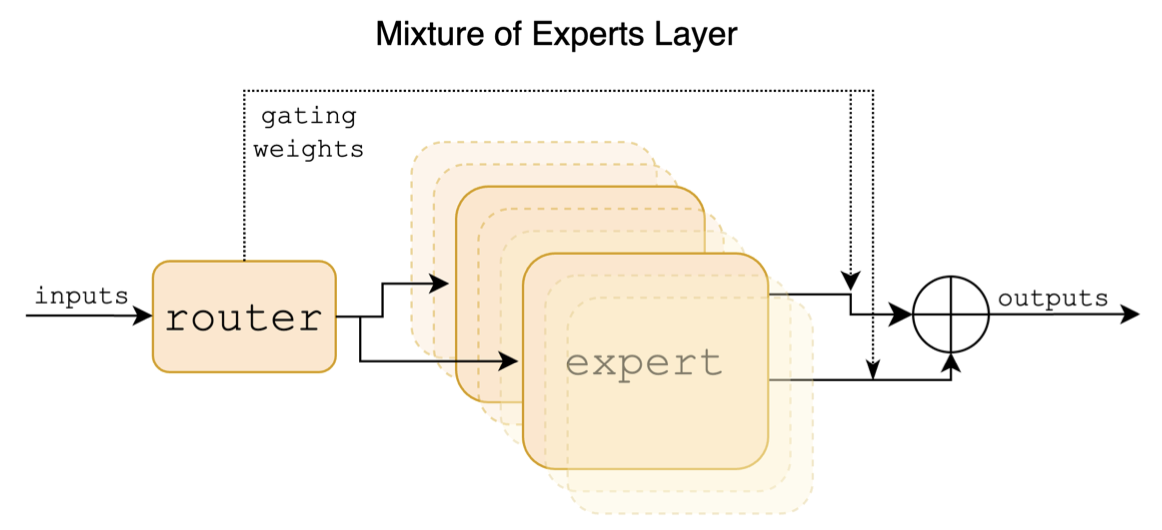
中国 - ラマ - アルパカや中国 - ラマ・アルパカ-2プロジェクトとは異なり、ミックストラルモデルは32Kコンテキストをネイティブにサポートします(実際の測定は128Kに達する可能性があります)。ユーザーは、単一のモデルを使用して、さまざまな長さのさまざまなタスクを解決できます。
以下は、このプロジェクトのモデルと推奨される使用シナリオの比較です。チャットインタラクションについては、[指示]バージョンを選択します。
| 比較項目 | 中国のミックストラル | 中国のミックストラック |
|---|---|---|
| モデルタイプ | ベースモデル | ディレクティブ/チャットモデル(クラスchatgpt) |
| モデルサイズ | 8x7b(実際に約13b) | 8x7b(実際に約13b) |
| 専門家の数 | 8(実際にアクティブ化された2) | 8(実際にアクティブ化された2) |
| トレーニングタイプ | 因果-LM(CLM) | 指示の微細な調整 |
| トレーニング方法 | Qlora +全額埋め込み/lm-head | Qlora +全額埋め込み/lm-head |
| 訓練するモデル | オリジナルMixTral-8X7B-V0.1 | 中国のミックストラル |
| トレーニング資料 | マークされていない一般的なエッセイ | ラベル付き命令データ |
| 語彙サイズ | 元の語彙リスト、32000 | 元の語彙リスト、32000 |
| コンテキストの長さをサポートします | 32K(実際には128Kまで測定) | 32K(実際には128Kまで測定) |
| 入力テンプレート | 不要 | MixTral-Instructテンプレートを適用する必要があります |
| 適用可能なシナリオ | テキストの継続:上記のテキストが与えられた場合、モデルに次のテキストを生成させます | コマンド理解:Q&A、ライティング、チャット、インタラクションなど。 |
ここに3つの異なるタイプのモデルがあります:
| モデル名 | タイプ | 仕様 | フルバージョン(87 GB) | Loraバージョン(2.4 GB) | GGUFバージョン |
|---|---|---|---|---|---|
| 中国のミックストラル | ベースモデル | 8x7b | [baidu] [?hf] [?ModelScope] | [baidu] [?hf] [?ModelScope] | [?hf] |
| 中国のミクスラル即興 | 指導モデル | 8x7b | [baidu] [?hf] [?ModelScope] | [baidu] [?hf] [?ModelScope] | [?hf] |
注記
HFにアクセスできない場合は、いくつかのミラーサイト(HF-Mirror.comなど)を検討できます。特定の方法を自分で見つけて解決してください。
このプロジェクトの関連モデルは、主に次の量子化、推論、展開方法をサポートしています。詳細については、対応するチュートリアルを参照してください。
| 道具 | 特徴 | CPU | GPU | 定量化 | GUI | API | vllm | チュートリアル |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | 豊富な定量的オプションと効率的なローカル推論 | ✅ | ✅ | ✅ | ✅ | [リンク] | ||
| ?変圧器 | ネイティブトランス推論インターフェイス | ✅ | ✅ | ✅ | ✅ | ✅ | [リンク] | |
| Openai API呼び出しの模倣 | OpenAI APIインターフェイスをエミュレートするサーバーデモ | ✅ | ✅ | ✅ | ✅ | ✅ | [リンク] | |
| Text-Generation-Webui | フロントエンドWeb UIインターフェイスを展開する方法 | ✅ | ✅ | ✅ | ✅ | ✅ | [リンク] | |
| ラングチェーン | 二次開発に適した大規模なアプリケーションのためのオープンソースフレームワーク | ✅ | ✅ | ✅ | [リンク] | |||
| privategpt | マルチドキュメントローカル質問と回答フレームワーク | ✅ | ✅ | ✅ | [リンク] | |||
| LMスタジオ | マルチプラットフォームチャットソフトウェア(インターフェイス付き) | ✅ | ✅ | ✅ | ✅ | ✅ | [リンク] |
関連モデルの効果を評価するために、このプロジェクトは、生成効果評価と客観的効果評価(NLUクラス)をそれぞれ実施し、異なる角度から大きなモデルを評価しました。ユーザーが懸念しているタスクでテストし、関連するタスクに適応するモデルを選択することをお勧めします。
C-Evalは、包括的な中国の基本モデル評価スイートであり、検証セットとテストセットにはそれぞれ52人の被験者をカバーする1.3Kおよび12.3Kの複数選択の質問が含まれています。 C-Eval推論コードについては、このプロジェクトを参照してください:Github Wiki
| モデル | タイプ | 有効(0ショット) | 有効(5ショット) | テスト(0ショット) | テスト(5ショット) |
|---|---|---|---|---|---|
| 中国のミクスラル即興 | 命令 | 51.7 | 55.0 | 50.0 | 51.5 |
| 中国のミックストラル | ペデスタル | 45.8 | 54.2 | 43.1 | 49.1 |
| mixtral-8x7b-instruct-v0.1 | 命令 | 51.6 | 54.0 | 48.7 | 50.7 |
| mixtral-8x7b-v0.1 | ペデスタル | 47.3 | 54.6 | 46.1 | 50.3 |
| 中国アルパカ-2-13b | 命令 | 44.3 | 45.9 | 42.6 | 44.0 |
| 中国語-llama-2-13b | ペデスタル | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLUは、中国の文脈における言語モデルの知識と推論能力を評価するために特に使用されるもう1つの包括的な中国の評価データセットであり、基本的な科目から高度な専門レベルまでの67のトピックをカバーし、合計11.5kの多肢選択の質問をカバーしています。 cmmlu推論コードについては、このプロジェクトを参照してください:github wiki
| モデル | タイプ | テスト(0ショット) | テスト(5ショット) |
|---|---|---|---|
| 中国のミクスラル即興 | 命令 | 50.0 | 53.0 |
| 中国のミックストラル | ペデスタル | 42.5 | 51.0 |
| mixtral-8x7b-instruct-v0.1 | 命令 | 48.2 | 51.6 |
| mixtral-8x7b-v0.1 | ペデスタル | 44.3 | 51.6 |
| 中国アルパカ-2-13b | 命令 | 43.2 | 45.5 |
| 中国語-llama-2-13b | ペデスタル | 38.9 | 42.5 |
MMLUは、自然言語の理解能力を評価するための英語の評価データセットです。これは、今日の大きなモデル機能を評価するために使用される主要なデータセットの1つです。検証セットとテストセットには、それぞれ57人の被験者をカバーする1.5kおよび14.1kの複数選択の質問が含まれています。 MMLU推論コードについては、このプロジェクトを参照してください:Github Wiki
| モデル | タイプ | 有効(0ショット) | 有効(5ショット) | テスト(0ショット) | テスト(5ショット) |
|---|---|---|---|---|---|
| 中国のミクスラル即興 | 命令 | 65.1 | 69.6 | 67.5 | 69.8 |
| 中国のミックストラル | ペデスタル | 63.2 | 67.1 | 65.5 | 68.3 |
| mixtral-8x7b-instruct-v0.1 | 命令 | 68.5 | 70.4 | 68.2 | 70.2 |
| mixtral-8x7b-v0.1 | ペデスタル | 64.9 | 69.0 | 67.0 | 69.5 |
| 中国アルパカ-2-13b | 命令 | 49.6 | 53.2 | 50.9 | 53.5 |
| 中国語-llama-2-13b | ペデスタル | 46.8 | 50.0 | 46.6 | 51.8 |
ロングベンチは、大規模なモデルの長いテキスト理解能力を評価するためのベンチマークです。 6つの主要なカテゴリと20の異なるタスクで構成されています。ほとんどのタスクの平均長は5K-15Kで、約4.75Kのテストデータが含まれています。以下は、この中国のタスク(コードタスクを含む)に対するこのプロジェクトモデルの評価効果です。ロングベンチの推論コードについては、このプロジェクトを参照してください:github wiki
| モデル | 単一のドキュメントQA | マルチドキュメントQA | まとめ | FS学習 | コードの完了 | 合成タスク | 平均 |
|---|---|---|---|---|---|---|---|
| 中国のミクスラル即興 | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| 中国のミックストラル | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| mixtral-8x7b-instruct-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| mixtral-8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| 中国アルパカ-2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| 中国語-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| 中国アルパカ-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| 中国語-llama-2-7b-64k | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
llama.cppでは、次の表に示すように、中国のミックストラル定量バージョンモデルのパフォーマンスがテストされました。
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | IQ2_XS | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| サイズ(GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3最大速度 | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100速度 | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
注記
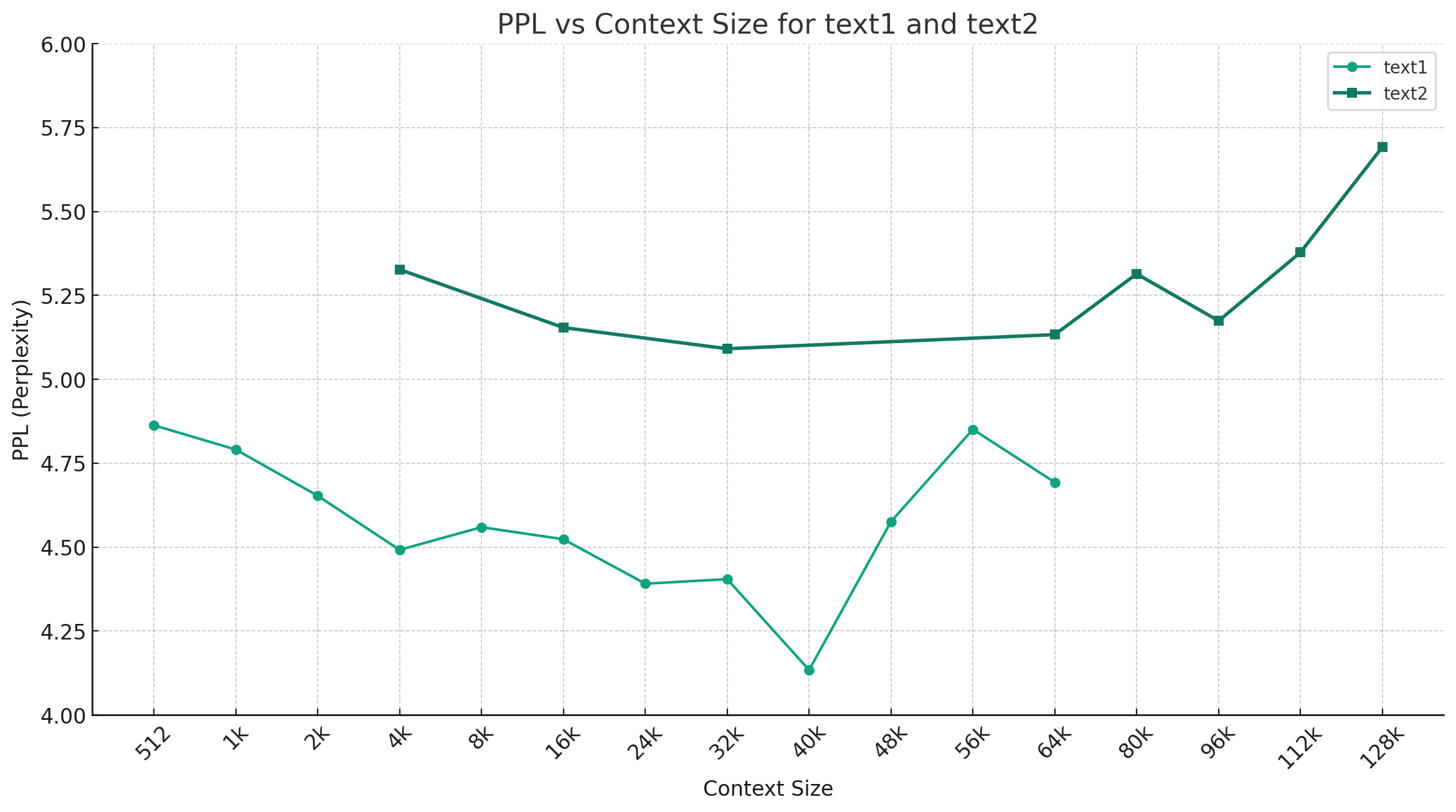
中国のミックストラルQ4_0を例にとると、以下の図は、異なるコンテキスト長の下でのPPLの変化傾向を示しており、2つの異なるプレーンテキストデータが選択されました。実験結果は、MixTralモデルによってサポートされているコンテキスト長が名目32Kを超えており、64K+コンテキスト(実際には最大128K)で良好なパフォーマンスを持っていることを示しています。
ディレクティブテンプレート:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
注: <s>および</s>は、シーケンスの開始と終了を表す特別なトークンであり、 [INST]と[/INST]は通常の文字列です。
問題に言及する前に、ソリューションがFAQに既に存在するかどうかを確認してください。具体的な質問と回答については、このプロジェクトGithub wikiを参照してください
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}このプロジェクトは、Mistral.aiが発行したMixtralモデルに基づいて開発されています。使用中のMixtralオープンソースライセンス契約を厳守してください。サードパーティのコードを使用している場合は、関連するオープンソースライセンス契約を遵守してください。モデルによって生成されるコンテンツは、計算方法、ランダム因子、および定量的精度の損失により、精度に影響を与える可能性があります。したがって、このプロジェクトは、モデル出力の精度を保証するものではなく、関連するリソースと出力結果の使用によって引き起こされる損失についても責任を負いません。このプロジェクトの関連モデルが商業目的で使用されている場合、開発者はモデルの出力コンテンツのコンプライアンスを確保するために、現地の法律と規制を順守するものとします。このプロジェクトは、そこから派生した製品またはサービスに対して責任を負いません。
ご質問がある場合は、GitHub Issueで送信してください。丁寧に質問し、調和のとれたディスカッションコミュニティを構築します。


