Chinese Mixtral
v1.2
??Chinese | English | Documents/Docs | ❓ Questions/Issues | Discussions/Discussions | ⚔️ Arena/Arena

This project is developed based on the Mixtral model released by Mistral.ai, which uses the Sparse MoE architecture. This project uses large-scale Chinese label-free data to conduct Chinese incremental training to obtain the Chinese Mixtral basic model, and further uses instruction fine adjustment to obtain the Chinese Mixtral-Instruct instruction model. The model natively supports 32K context (tested up to 128K) , which can effectively process long text, and at the same time achieve significant performance improvements in mathematical reasoning, code generation, etc. When using llama.cpp for quantitative reasoning, it only takes 16G memory (or video memory).
Technical report : [Cui and Yao, 2024] Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral [Paper Interpretation]
Chinese LLaMA-2&Alpaca-2 mockup | Chinese LLaMA&Alpaca mockup | Multimodal Chinese LLaMA&Alpaca mockup | Multimodal VLE | Chinese MiniRBT | Chinese LERT | Chinese English PERT | Chinese MacBERT | Chinese ELECTRA | Chinese XLNet | Chinese BERT | Knowledge distillation tool TextBrewer | Model cutting tool TextPruner | Distillation and cutting integration GRAIN
[2024/04/30] Chinese-LLaMA-Alpaca-3 has been officially released, open source Llama-3-Chinese-8B and Llama-3-Chinese-8B-Instruct based on Llama-3, please refer to: https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
[2024/03/27] Add 1-bit/2-bit/3-bit quantitative version of GGUF model: [?HF]; at the same time, this project has been deployed in the Heart of Machine SOTA! model platform, welcome to follow: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Add a mimic OpenAI API deployment mode. View details: v1.2 version release log
[2024/03/05] Open source model training and fine-tuning code, publish technical reports. View details: v1.1 version release log
[2024/01/29] Officially released Chinese-Mixtral (base model) and Chinese-Mixtral-Instruct (instruction/chat model). View details: v1.0 version release log
| chapter | describe |
|---|---|
| ??♂️Model Introduction | Briefly introduce the technical characteristics of the relevant models of this project |
| ⏬Model Download | Chinese Mixtral model download address |
| Reasoning and deployment | Introduces how to quantify models and deploy and experience large models using a personal computer |
| ?Model effect | The effect of the model on some tasks is introduced |
| Training and fine tune | Introducing how to train and fine tune the Chinese Mixtral model |
| ❓FAQ | Replies to some FAQs |
This project open source Chinese Mixtral and Chinese Mixtral-Instruct models developed based on Mixtral model, and its main features are as follows:
Mixtral is a sparse hybrid expert model. This model has significant differences from previous mainstream large-scale models such as LLaMA, which is mainly reflected in the following points:
The following is a structural diagram in the Mixtral paper:
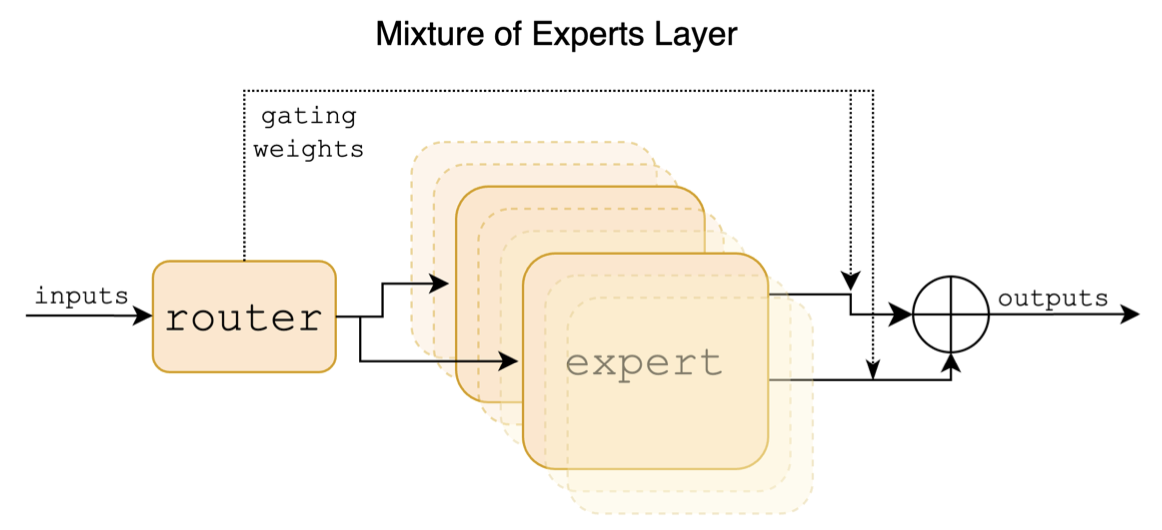
Unlike the Chinese-LLaMA-Alpaca and Chinese-LLaMA-Alpaca-2 projects, the Mixtral model natively supports 32K context (the actual measurement can reach 128K). Users can use a single model to solve various tasks of different lengths.
The following is a comparison of the model of this project and the recommended usage scenarios. For chat interaction, select Instruct version.
| Comparison items | Chinese Mixtral | Chinese Mixtral-Instruct |
|---|---|---|
| Model Type | Base model | Directive/Chat model (Class ChatGPT) |
| Model size | 8x7B (actually activated about 13B) | 8x7B (actually activated about 13B) |
| Number of experts | 8 (actually activated 2) | 8 (actually activated 2) |
| Training Type | Causal-LM (CLM) | Instruction fine adjustment |
| Training method | QLoRA + full amount emb/lm-head | QLoRA + full amount emb/lm-head |
| What model to train | Original Mixtral-8x7B-v0.1 | Chinese Mixtral |
| Training materials | Unmarked general essay | Labeled instruction data |
| Vocabulary size | Original vocabulary list, 32000 | Original vocabulary list, 32000 |
| Supports context length | 32K (actually measured up to 128K) | 32K (actually measured up to 128K) |
| Input template | unnecessary | Need to apply the Mixtral-Instruct template |
| Applicable scenarios | Text continuation: Given the above text, let the model generate the following text | Command understanding: Q&A, writing, chat, interaction, etc. |
Here are 3 different types of models:
| Model name | type | Specification | Full version (87 GB) | LoRA version (2.4 GB) | GGUF version |
|---|---|---|---|---|---|
| Chinese-Mixtral | Base model | 8x7B | [Baidu] [?HF] [?ModelScope] | [Baidu] [?HF] [?ModelScope] | [?HF] |
| Chinese-Mixtral-Instruct | Instruction Model | 8x7B | [Baidu] [?HF] [?ModelScope] | [Baidu] [?HF] [?ModelScope] | [?HF] |
Note
If you cannot access HF, you can consider some mirror sites (such as hf-mirror.com). Please find and solve the specific methods yourself.
The relevant models in this project mainly support the following quantization, reasoning and deployment methods. For details, please refer to the corresponding tutorial.
| tool | Features | CPU | GPU | Quantification | GUI | API | vLLM | Tutorial |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | Rich quantitative options and efficient local reasoning | ✅ | ✅ | ✅ | ✅ | [link] | ||
| ?Transformers | Native transformers inference interface | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Imitation of OpenAI API calls | Server demo that emulates OpenAI API interface | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| text-generation-webui | How to deploy the front-end Web UI interface | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| LangChain | Open source framework for large-scale application suitable for secondary development | ✅ | ✅ | ✅ | [link] | |||
| privateGPT | Multi-document local question and answer framework | ✅ | ✅ | ✅ | [link] | |||
| LM Studio | Multi-platform chat software (with interface) | ✅ | ✅ | ✅ | ✅ | ✅ | [link] |
In order to evaluate the effects of related models, this project conducted generative effect evaluation and objective effect evaluation (NLU class) respectively, and evaluated the large model from different angles. It is recommended that users test on tasks they are concerned about and select models that adapt to related tasks.
C-Eval is a comprehensive Chinese basic model evaluation suite, in which the verification set and the test set contain 1.3K and 12.3K multiple-choice questions, covering 52 subjects, respectively. Please refer to this project for C-Eval inference code: GitHub Wiki
| Models | type | Valid (0-shot) | Valid (5-shot) | Test (0-shot) | Test (5-shot) |
|---|---|---|---|---|---|
| Chinese-Mixtral-Instruct | instruction | 51.7 | 55.0 | 50.0 | 51.5 |
| Chinese-Mixtral | Pedestal | 45.8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7B-Instruct-v0.1 | instruction | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7B-v0.1 | Pedestal | 47.3 | 54.6 | 46.1 | 50.3 |
| Chinese-Alpaca-2-13B | instruction | 44.3 | 45.9 | 42.6 | 44.0 |
| Chinese-LLaMA-2-13B | Pedestal | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU is another comprehensive Chinese evaluation dataset, specifically used to evaluate the knowledge and reasoning ability of language models in the Chinese context, covering 67 topics from basic subjects to advanced professional level, with a total of 11.5K multiple-choice questions. Please refer to this project for CMMLU inference code: GitHub Wiki
| Models | type | Test (0-shot) | Test (5-shot) |
|---|---|---|---|
| Chinese-Mixtral-Instruct | instruction | 50.0 | 53.0 |
| Chinese-Mixtral | Pedestal | 42.5 | 51.0 |
| Mixtral-8x7B-Instruct-v0.1 | instruction | 48.2 | 51.6 |
| Mixtral-8x7B-v0.1 | Pedestal | 44.3 | 51.6 |
| Chinese-Alpaca-2-13B | instruction | 43.2 | 45.5 |
| Chinese-LLaMA-2-13B | Pedestal | 38.9 | 42.5 |
MMLU is an English evaluation dataset for evaluating natural language comprehension ability. It is one of the main datasets used to evaluate large model capabilities today. The verification set and test set contain 1.5K and 14.1K multiple-choice questions, respectively, covering 57 subjects. Please refer to this project for MMLU inference code: GitHub Wiki
| Models | type | Valid (0-shot) | Valid (5-shot) | Test (0-shot) | Test (5-shot) |
|---|---|---|---|---|---|
| Chinese-Mixtral-Instruct | instruction | 65.1 | 69.6 | 67.5 | 69.8 |
| Chinese-Mixtral | Pedestal | 63.2 | 67.1 | 65.5 | 68.3 |
| Mixtral-8x7B-Instruct-v0.1 | instruction | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7B-v0.1 | Pedestal | 64.9 | 69.0 | 67.0 | 69.5 |
| Chinese-Alpaca-2-13B | instruction | 49.6 | 53.2 | 50.9 | 53.5 |
| Chinese-LLaMA-2-13B | Pedestal | 46.8 | 50.0 | 46.6 | 51.8 |
LongBench is a benchmark for evaluating long text comprehension ability of a large model. It consists of 6 major categories and 20 different tasks. The average length of most tasks is between 5K-15K, and contains about 4.75K test data. The following is the evaluation effect of this project model on this Chinese task (including code tasks). Please refer to this project for LongBench inference code: GitHub Wiki
| Models | Single document QA | Multi-document QA | summary | FS Learning | Code completion | Synthesis task | average |
|---|---|---|---|---|---|---|---|
| Chinese-Mixtral-Instruct | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| Chinese-Mixtral | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7B-Instruct-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7B-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| Chinese-Alpaca-2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinese-LLaMA-2-13B-16K | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinese-Alpaca-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinese-LLaMA-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
Under llama.cpp, the performance of the Chinese-Mixtral quantitative version model was tested, as shown in the following table.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | IQ2_XS | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| PPL | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 Max Speed | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 Speed | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Note
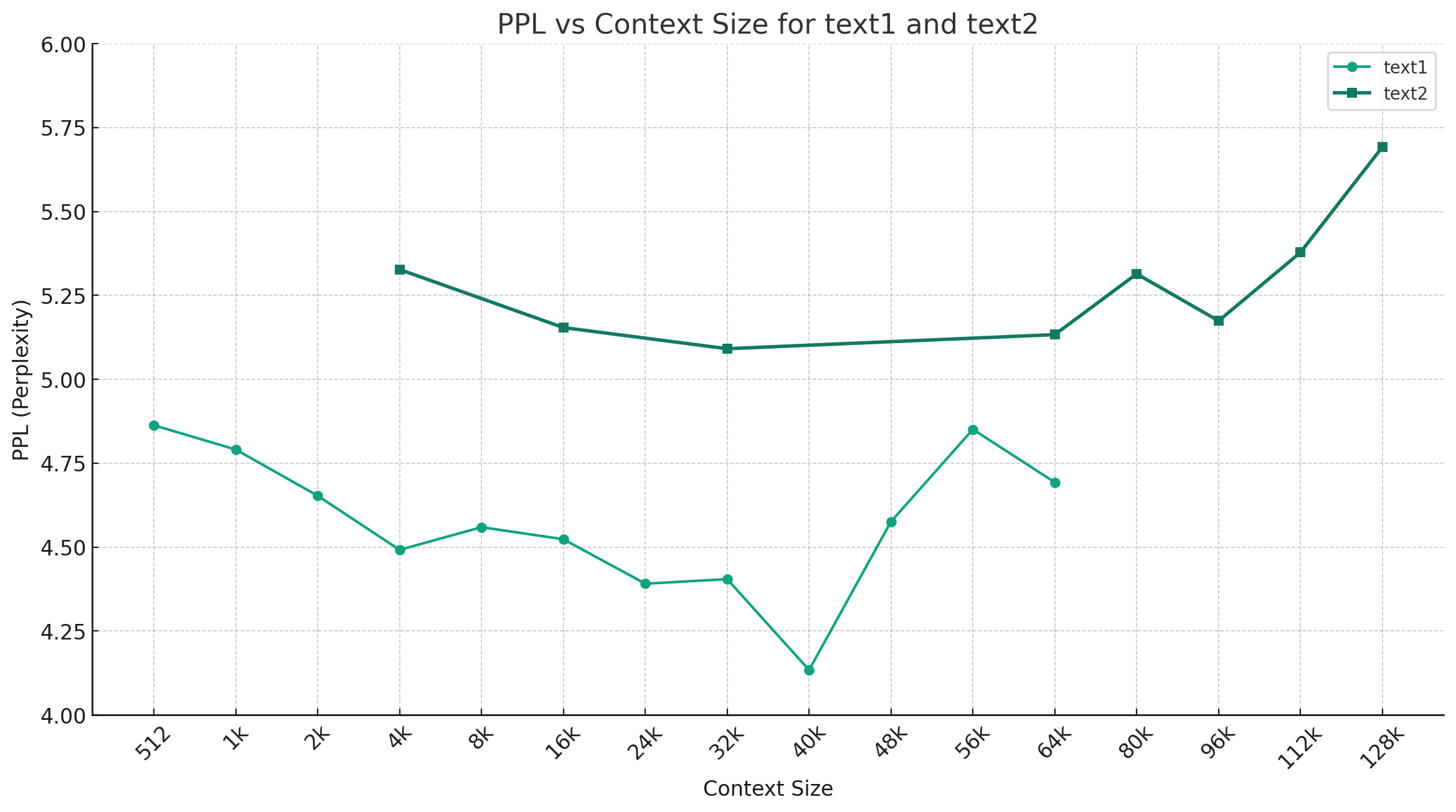
Taking Chinese-Mixtral-Q4_0 as an example, the figure below shows the PPL change trend under different context lengths, and two different sets of plain text data were selected. The experimental results show that the context length supported by the Mixtral model has exceeded the nominal 32K, and it still has good performance under 64K+ context (actually measured up to 128K).
Directive template:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Note: <s> and </s> are special tokens representing the beginning and end of a sequence, while [INST] and [/INST] are ordinary strings.
Please check whether the solution already exists in the FAQ before you mention the Issue. For specific questions and answers, please refer to this project GitHub Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}This project is developed based on the Mixtral model published by Mistral.ai. Please strictly abide by the Mixtral open source license agreement during use. If using third-party code is involved, be sure to comply with the relevant open source license agreement. The content generated by the model may affect its accuracy due to calculation methods, random factors, and quantitative accuracy losses. Therefore, this project does not provide any guarantee for the accuracy of the model output, nor will it be liable for any losses caused by the use of relevant resources and output results. If the relevant models of this project are used for commercial purposes, the developer shall abide by local laws and regulations to ensure compliance with the output content of the model. This project shall not be liable for any products or services derived therefrom.
If you have any questions, please submit it in GitHub Issue. Ask questions politely and build a harmonious discussion community.


