Chinese Mixtral
v1.2
?? chino | Inglés | Documentos/documentos | ❓ Preguntas/problemas | Discusiones/discusiones | ⚔️ Arena/Arena

Este proyecto se desarrolla basado en el modelo mixtral publicado por Mistral.ai, que utiliza la arquitectura MOE dispersa. Este proyecto utiliza datos libres de etiquetas chinos a gran escala para llevar a cabo una capacitación incremental china para obtener el modelo básico de mixtral chino , y utiliza un ajuste fino de instrucción para obtener el modelo de instrucción de instrucciones mixtral china . El modelo admite de forma nativa 32K contexto (probado hasta 128k) , que puede procesar efectivamente un texto largo y, al mismo tiempo, lograr mejoras de rendimiento significativas en el razonamiento matemático, la generación de códigos, etc. Cuando se usa llama.cpp para razonamiento cuantitativo, solo se requiere memoria de 16 g (o memoria de video).
Informe técnico : [Cui y Yao, 2024] Repensar la adaptación del lenguaje LLM: un estudio de caso sobre mixtral chino [interpretación en papel]
Maqueta china Llama-2 y Alpaca-2 | Mockup de Llama y Alpaca | Multimodal chino Llama y maqueta de alpaca | VLE multimodal | Minirbt chino | Lert chino | Inglés chino Pert | Macbert chino | Electra chino | Chino xlnet | Bert chino | Herramienta de destilación de conocimiento TextBrewer | Herramienta de corte de modelos Textpruner | Destilación y grano de integración de corte
[2024/04/30] chino-llama-alpaca-3 se ha lanzado oficialmente, código abierto Llama-3-Chinese-8b y Llama-3-chinese-8b-instructo basado en Llama-3, consulte: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] Agregue la versión cuantitativa de 1 bit/2 bits/3 bits del modelo GGUF: [? Hf]; Al mismo tiempo, este proyecto se ha implementado en el corazón de la máquina Sota! Plataforma modelo, bienvenido a seguir: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Agregue un modo de implementación de API de Mimic OpenAI. Ver Detalles: V1.2 REGISTRO DE VERSIÓN
[2024/03/05] Capacitación de modelos de código abierto y código de ajuste fino, publique informes técnicos. Ver detalles: V1.1 REGISTRO DE VERSIÓN
[2024/01/29] lanzó oficialmente chino (modelo base) de chino y instructo-mezcla-mezcla (modelo de instrucción/chat). Ver Detalles: Registro de lanzamiento de la versión V1.0
| capítulo | describir |
|---|---|
| ? | Introducir brevemente las características técnicas de los modelos relevantes de este proyecto |
| ⏬ Descarga del modelo | Dirección de descarga del modelo mixtral chino |
| Razonamiento e implementación | Presenta cómo cuantificar modelos e implementar y experimentar modelos grandes utilizando una computadora personal |
| ? Efecto de modelo | Se introduce el efecto del modelo en algunas tareas |
| Entrenamiento y melodía | Introducir cómo entrenar y ajustar el modelo chino mixtral |
| ❓faq | Responde a algunas preguntas frecuentes |
Este proyecto de código abierto mixtral y chinos modelos de instrucciones mixtrral mixtral desarrollados basados en el modelo mixtral, y sus características principales son las siguientes:
Mixtral es un modelo de experto híbrido escaso. Este modelo tiene diferencias significativas con respecto a los modelos anteriores de gran escala como LLAMA, que se refleja principalmente en los siguientes puntos:
El siguiente es un diagrama estructural en el papel mixtral:
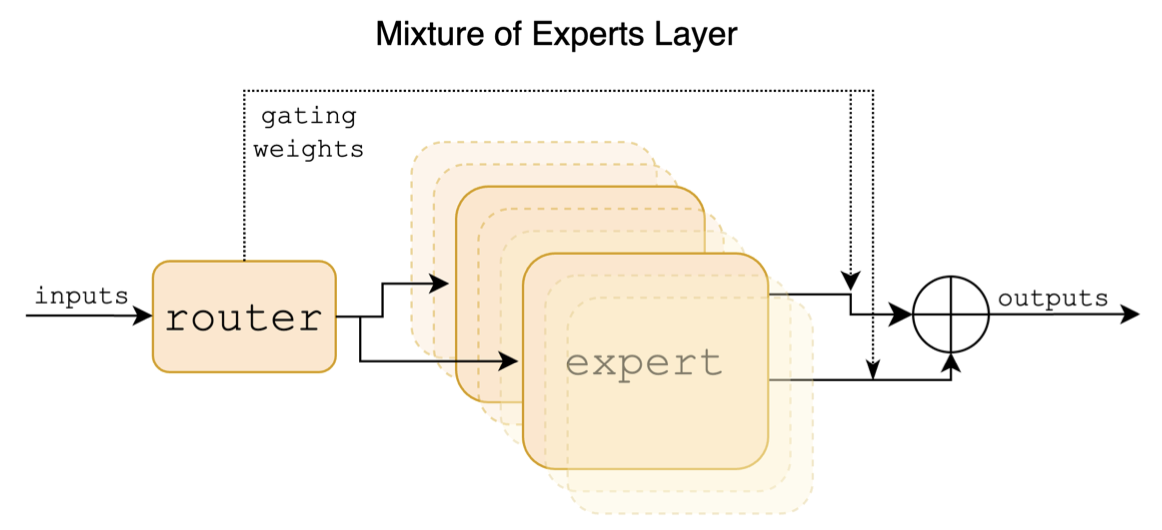
A diferencia de los proyectos chino-llama-alpaca y chino-llama-alpaca-2, el modelo mixtral admite de forma nativa de 32k (la medición real puede alcanzar 128k). Los usuarios pueden usar un solo modelo para resolver varias tareas de diferentes longitudes.
La siguiente es una comparación del modelo de este proyecto y los escenarios de uso recomendados. Para la interacción de chat, seleccione Instruir la versión.
| Elementos de comparación | Mixtral chino | INSTRUPO MIXTRAL CHINO |
|---|---|---|
| Tipo de modelo | Modelo base | Modelo de directiva/chat (chatgpt de clase) |
| Tamaño del modelo | 8x7b (en realidad activado alrededor de 13b) | 8x7b (en realidad activado alrededor de 13b) |
| Número de expertos | 8 (realmente activado 2) | 8 (realmente activado 2) |
| Tipo de entrenamiento | Causal-LM (CLM) | Instrucción Ajuste fino |
| Método de entrenamiento | Qlora + Cantidad completa EMB/LM-Head | Qlora + Cantidad completa EMB/LM-Head |
| Que modelo entrenar | Mixtral-8x7b-v0.1 original | Mixtral chino |
| Materiales de capacitación | Ensayo general sin marcar | Datos de instrucciones etiquetados |
| Tamaño de vocabulario | Lista de vocabulario original, 32000 | Lista de vocabulario original, 32000 |
| Admite la longitud del contexto | 32k (realmente medido hasta 128k) | 32k (realmente medido hasta 128k) |
| Plantilla de entrada | innecesario | Necesita aplicar la plantilla de instrucciones de mezcla mixtral |
| Escenarios aplicables | Continuación del texto: dado el texto anterior, deje que el modelo genere el siguiente texto | Comprensión del comando: preguntas y respuestas, escritura, chat, interacción, etc. |
Aquí hay 3 tipos diferentes de modelos:
| Nombre del modelo | tipo | Especificación | Versión completa (87 GB) | Versión de Lora (2.4 GB) | Versión de Gguf |
|---|---|---|---|---|---|
| Mixtral chino | Modelo base | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
| Instrucción china-mixtral | Modelo de instrucción | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
Nota
Si no puede acceder a HF, puede considerar algunos sitios de espejo (como HF-Mirror.com). Encuentre y resuelva los métodos específicos usted mismo.
Los modelos relevantes en este proyecto admiten principalmente los siguientes métodos de cuantificación, razonamiento e implementación. Para más detalles, consulte el tutorial correspondiente.
| herramienta | Características | UPC | GPU | Cuantificación | Guía | API | vllm | Tutorial |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | Opciones cuantitativas ricas y razonamiento local eficiente | ✅ | ✅ | ✅ | ✅ | [enlace] | ||
| ? Transformadores | Interfaz de inferencia de transformadores nativos | ✅ | ✅ | ✅ | ✅ | ✅ | [enlace] | |
| Imitación de llamadas de API de Operai | Demostración del servidor que emula la interfaz API de OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | [enlace] | |
| Webui de texto de texto | Cómo implementar la interfaz de interfaz de usuario web front-end | ✅ | ✅ | ✅ | ✅ | ✅ | [enlace] | |
| Langchain | Marco de código abierto para aplicaciones a gran escala adecuada para el desarrollo secundario | ✅ | ✅ | ✅ | [enlace] | |||
| privategpt | Marco de preguntas y respuestas locales multi-documentos | ✅ | ✅ | ✅ | [enlace] | |||
| LM Studio | Software de chat multiplataforma (con interfaz) | ✅ | ✅ | ✅ | ✅ | ✅ | [enlace] |
Para evaluar los efectos de los modelos relacionados, este proyecto realizó la evaluación del efecto generativo y la evaluación del efecto objetivo (clase NLU) respectivamente, y evaluó el modelo grande desde diferentes ángulos. Se recomienda que los usuarios prueben en las tareas que les preocupa y seleccione modelos que se adapten a las tareas relacionadas.
C-EVAL es un conjunto integral de evaluación del modelo básico chino, en el que el conjunto de verificación y el conjunto de pruebas contienen preguntas de opción múltiple 1.3k y 12.3k, que cubren 52 sujetos, respectivamente. Consulte este proyecto para el código de inferencia C-EVAL: GitHub Wiki
| Modelos | tipo | Válido (0-shot) | Válido (5-shot) | Prueba (0-shot) | Prueba (5-shot) |
|---|---|---|---|---|---|
| Instrucción china-mixtral | instrucción | 51.7 | 55.0 | 50.0 | 51.5 |
| Mixtral chino | Pedestal | 45.8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7b-instructo-v0.1 | instrucción | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7b-v0.1 | Pedestal | 47.3 | 54.6 | 46.1 | 50.3 |
| Chino-alpaca-2-13b | instrucción | 44.3 | 45.9 | 42.6 | 44.0 |
| Chino-llama-2-13b | Pedestal | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU es otro conjunto de datos de evaluación chino integral, utilizado específicamente para evaluar el conocimiento y la capacidad de razonamiento de los modelos de idiomas en el contexto chino, que cubre 67 temas de sujetos básicos a nivel profesional avanzado, con un total de 11.5k preguntas de opción múltiple. Consulte este proyecto para el código de inferencia CMMLU: GitHub Wiki
| Modelos | tipo | Prueba (0-shot) | Prueba (5-shot) |
|---|---|---|---|
| Instrucción china-mixtral | instrucción | 50.0 | 53.0 |
| Mixtral chino | Pedestal | 42.5 | 51.0 |
| Mixtral-8x7b-instructo-v0.1 | instrucción | 48.2 | 51.6 |
| Mixtral-8x7b-v0.1 | Pedestal | 44.3 | 51.6 |
| Chino-alpaca-2-13b | instrucción | 43.2 | 45.5 |
| Chino-llama-2-13b | Pedestal | 38.9 | 42.5 |
MMLU es un conjunto de datos de evaluación en inglés para evaluar la capacidad de comprensión del lenguaje natural. Es uno de los principales conjuntos de datos utilizados para evaluar las grandes capacidades del modelo hoy. El conjunto de verificación y el conjunto de pruebas contienen preguntas de opción múltiple 1.5k y 14.1k, respectivamente, que cubren 57 sujetos. Consulte este proyecto para el código de inferencia MMLU: GitHub Wiki
| Modelos | tipo | Válido (0-shot) | Válido (5-shot) | Prueba (0-shot) | Prueba (5-shot) |
|---|---|---|---|---|---|
| Instrucción china-mixtral | instrucción | 65.1 | 69.6 | 67.5 | 69.8 |
| Mixtral chino | Pedestal | 63.2 | 67.1 | 65.5 | 68.3 |
| Mixtral-8x7b-instructo-v0.1 | instrucción | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-v0.1 | Pedestal | 64.9 | 69.0 | 67.0 | 69.5 |
| Chino-alpaca-2-13b | instrucción | 49.6 | 53.2 | 50.9 | 53.5 |
| Chino-llama-2-13b | Pedestal | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench es un punto de referencia para evaluar la capacidad de comprensión de texto largo de un modelo grande. Consiste en 6 categorías principales y 20 tareas diferentes. La longitud promedio de la mayoría de las tareas es entre 5K-15K, y contiene aproximadamente 4.75k datos de prueba. El siguiente es el efecto de evaluación de este modelo de proyecto en esta tarea china (incluidas las tareas del código). Consulte este proyecto para el código de inferencia de Longbench: GitHub Wiki
| Modelos | QA de documento único | QA multi-documento | resumen | Aprendizaje de FS | Finalización del código | Tarea de síntesis | promedio |
|---|---|---|---|---|---|---|---|
| Instrucción china-mixtral | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| Mixtral chino | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7b-instructo-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| Chino-alpaca-2-13b-16k | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chino-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chino-alpaca-2-7b-64k | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chino-llama-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
Bajo llama.cpp, se probó el rendimiento del modelo de versión cuantitativa-mezcla china, como se muestra en la siguiente tabla.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | IQ2_XS | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tamaño (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| Bpw | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| Velocidad M3 MAX | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 Velocidad | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Nota
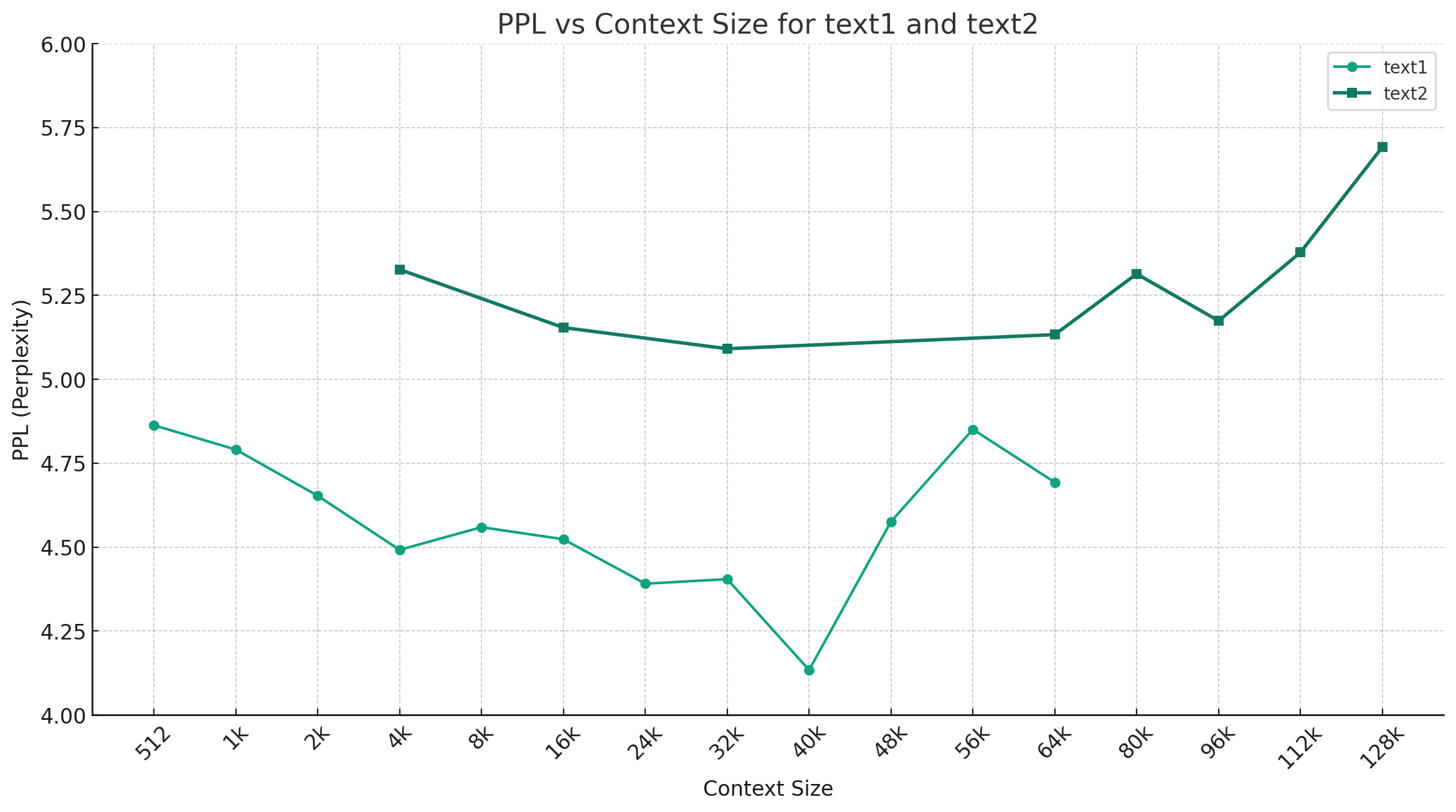
Tomando chino-mixtral-q4_0 como ejemplo, la siguiente figura muestra la tendencia de cambio de PPL bajo diferentes longitudes de contexto, y se seleccionaron dos conjuntos diferentes de datos de texto plano. Los resultados experimentales muestran que la longitud de contexto respaldada por el modelo mixtral ha excedido el 32k nominal, y todavía tiene un buen rendimiento bajo 64K+ contexto (en realidad medido hasta 128k).
Plantilla de directiva:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Nota: <s> y </s> son tokens especiales que representan el principio y el final de una secuencia, mientras que [INST] e [/INST] son cadenas ordinarias.
Compruebe si la solución ya existe en las preguntas frecuentes antes de mencionar el problema. Para preguntas y respuestas específicas, consulte este proyecto Wiki Github
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Este proyecto se desarrolla basado en el modelo mixtral publicado por Mistral.ai. Por favor, cumpla estrictamente con el acuerdo de licencia de código abierto de mixtral durante el uso. Si se trata de usar código de terceros, asegúrese de cumplir con el acuerdo de licencia de código abierto correspondiente. El contenido generado por el modelo puede afectar su precisión debido a métodos de cálculo, factores aleatorios y pérdidas cuantitativas de precisión. Por lo tanto, este proyecto no proporciona ninguna garantía para la precisión de la salida del modelo, ni será responsable de las pérdidas causadas por el uso de recursos relevantes y resultados de salida. Si los modelos relevantes de este proyecto se utilizan con fines comerciales, el desarrollador cumplirá con las leyes y regulaciones locales para garantizar el cumplimiento del contenido de salida del modelo. Este proyecto no será responsable de ningún producto o servicio derivado de ellos.
Si tiene alguna pregunta, envíelo en el problema de GitHub. Haga preguntas cortésmente y cree una comunidad de discusión armoniosa.


