Chinese Mixtral
v1.2
?? Chinois | Anglais | Documents / Docs | ❓ Questions / problèmes | Discussions / discussions | ⚔️ Arena / Arena

Ce projet est développé sur la base du modèle Mixtral publié par Mistral.ai, qui utilise l'architecture MOE clairsemée. Ce projet utilise des données chinoises sans étiquettes chinoises à grande échelle pour effectuer une formation incrémentielle chinoise pour obtenir le modèle de base chinois Mixtral , et utilise en outre un ajustement fin des instructions pour obtenir le modèle d'instruction chinois de mixtral-instruct . Le modèle prend en charge le contexte 32k (testé jusqu'à 128k) , qui peut traiter efficacement le texte long, et en même temps d'améliorer des améliorations de performances significatives dans le raisonnement mathématique, la génération de code, etc. Lorsque vous utilisez Llama.cpp pour le raisonnement quantitatif, il ne faut que la mémoire 16G (ou la mémoire vidéo).
Rapport technique : [Cui et Yao, 2024] Repenser l'adaptation du langage LLM: une étude de cas sur le mixtral chinois [Interprétation du papier]
LLAMA-2 ET ALPACA-2 MOCKUP | Llama chinois et maquette d'alpaca | Llama chinois multimodal et alpaca Mockup | VLE multimodal | Minirbt chinois | Lert chinois | Pert anglais chinois | Macbert chinois | Electra chinois | Xlnet chinois | Chinois Bert | Outil de distillation de connaissances TextBrewer | Modèle de coupe TextPruner | Distillation et coupe de grain d'intégration
[2024/04/30] Chinese-Llama-Alpaca-3 a été officiellement publié, Open Source Llama-3-Chinese-8b et Llama-3-Chinese-8b-instruct basé sur Llama-3, veuillez vous référer à: https://gihub.com/ymcui/chinese-lama-alpaca-3
[2024/03/27] Ajouter une version quantitative 1 bits / 2 bits / 3 bits du modèle GGUF: [? HF]; Dans le même temps, ce projet a été déployé au cœur de Machine Sota! Plateforme modèle, bienvenue à suivre: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Ajoutez un mode de déploiement de l'API Mimic OpenAI. Afficher les détails: V1.2 Journal de publication de la version
[2024/03/05] Formation du modèle open source et code de réglage fin, publier des rapports techniques. Afficher les détails: V1.1 Version du journal de publication
[2024/01/29] a officiellement publié le chinois-mixtral (modèle de base) et l'instruct chinois-mixtral (modèle d'instruction / chat). Afficher les détails: V1.0 Version du journal de publication
| chapitre | décrire |
|---|---|
| ?? ️ Model Introduction | Introduire brièvement les caractéristiques techniques des modèles pertinents de ce projet |
| Téléchargement du modélisation | Adresse de téléchargement du modèle mixtral chinois |
| Raisonnement et déploiement | Présente comment quantifier les modèles et déployer et découvrir de grands modèles à l'aide d'un ordinateur personnel |
| ? Effet du modèle | L'effet du modèle sur certaines tâches est introduit |
| Formation et affine | Introduire comment former et affiner le modèle de mixtral chinois |
| ❓faq | Réponses à certaines FAQ |
Ce projet open source chinois mixtral et chinois des modèles d'instruments mixtraux développés sur la base du modèle mixtral, et ses principales caractéristiques sont les suivantes:
Mixtral est un modèle expert hybride clairsemé. Ce modèle a des différences significatives par rapport aux modèles à grande échelle traditionnels précédents tels que LLAMA, qui se reflète principalement dans les points suivants:
Ce qui suit est un diagramme structurel dans le papier mixtral:
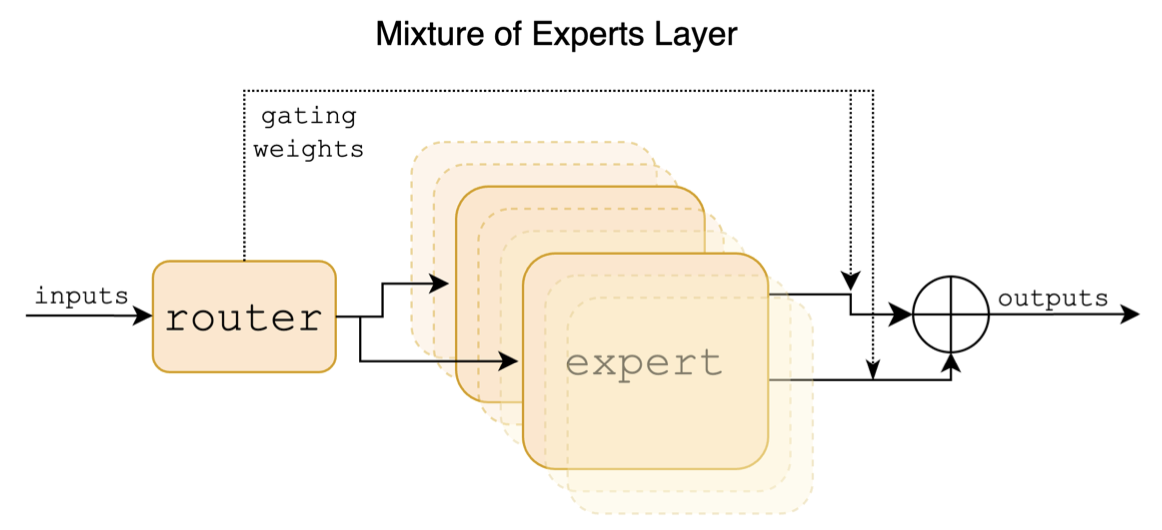
Contrairement aux projets chinois-llama-alpaca et chinois-llama-alpaca-2, le modèle mixtral soutient nativement le contexte 32k (la mesure réelle peut atteindre 128k). Les utilisateurs peuvent utiliser un seul modèle pour résoudre diverses tâches de différentes longueurs.
Ce qui suit est une comparaison du modèle de ce projet et des scénarios d'utilisation recommandés. Pour l'interaction de chat, sélectionnez Instruct Version.
| Articles de comparaison | Mixtral chinois | Mixtral-instruct chinois |
|---|---|---|
| Type de modèle | Modèle de base | Directive / Chat Modèle (classe Chatgpt) |
| Taille du modèle | 8x7b (réellement activé environ 13B) | 8x7b (réellement activé environ 13B) |
| Nombre d'experts | 8 (réellement activé 2) | 8 (réellement activé 2) |
| Type de formation | Causal-LM (CLM) | Instruction Fine ajustement |
| Méthode de formation | Qlora + montant complet EMB / LM-Head | Qlora + montant complet EMB / LM-Head |
| Quel modèle à former | Mixtral-8x7b-V0.1 d'origine | Mixtral chinois |
| Matériel de formation | Essai général non marqué | Données d'instructions étiquetées |
| Taille de vocabulaire | Liste de vocabulaire originale, 32000 | Liste de vocabulaire originale, 32000 |
| Prend en charge la longueur du contexte | 32k (en fait mesuré jusqu'à 128k) | 32k (en fait mesuré jusqu'à 128k) |
| Modèle d'entrée | inutile | Besoin d'appliquer le modèle d'instruct mixtral |
| Scénarios applicables | Continuation du texte: Compte tenu du texte ci-dessus, laissez le modèle générer le texte suivant | Compréhension des commandes: Q&R, écriture, chat, interaction, etc. |
Voici 3 types de modèles différents:
| Nom du modèle | taper | Spécification | Version complète (87 Go) | Version LORA (2,4 Go) | Version GGUF |
|---|---|---|---|---|---|
| Chinois-mixtral | Modèle de base | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
| Instruct chinois | Modèle d'instruction | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
Note
Si vous ne pouvez pas accéder à HF, vous pouvez considérer certains sites de miroir (tels que hf-mirror.com). Veuillez trouver et résoudre les méthodes spécifiques vous-même.
Les modèles pertinents de ce projet soutiennent principalement les méthodes de quantification, de raisonnement et de déploiement suivantes. Pour plus de détails, veuillez consulter le tutoriel correspondant.
| outil | Caractéristiques | Processeur | GPU | Quantification | Gui | API | vllm | Tutoriel |
|---|---|---|---|---|---|---|---|---|
| lama.cpp | Riches options quantitatives et raisonnement local efficace | ✅ | ✅ | ✅ | ✅ | [lien] | ||
| ? Transformers | Interface d'inférence des transformateurs natifs | ✅ | ✅ | ✅ | ✅ | ✅ | [lien] | |
| Imitation des appels d'API openai | Démo de serveur qui émule l'interface API OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | [lien] | |
| Génération de texte-webui | Comment déployer l'interface Interface Web frontale | ✅ | ✅ | ✅ | ✅ | ✅ | [lien] | |
| Lubriole | Framework open source pour une application à grande échelle adaptée au développement secondaire | ✅ | ✅ | ✅ | [lien] | |||
| privé | Cadre de questions et réponses locales à plusieurs documents | ✅ | ✅ | ✅ | [lien] | |||
| Studio LM | Logiciel de chat multiplateforme (avec interface) | ✅ | ✅ | ✅ | ✅ | ✅ | [lien] |
Afin d'évaluer les effets des modèles connexes, ce projet a effectué respectivement l'évaluation des effets génératifs et l'évaluation des effets objectifs (classe NLU) et a évalué le grand modèle sous différents angles. Il est recommandé que les utilisateurs testent sur les tâches qui les préoccupent et sélectionnent des modèles qui s'adaptent aux tâches connexes.
C-Eval est une suite complète d'évaluation de modèle de base chinois, dans laquelle l'ensemble de vérification et l'ensemble de test contiennent des questions de 1K et 12,3k à choix multiples, couvrant 52 sujets, respectivement. Veuillez vous référer à ce projet pour C-Eval Inference Code: GitHub Wiki
| Modèles | taper | Valide (0-shot) | VALIDE (5-Shot) | Test (0-shot) | Test (5-shot) |
|---|---|---|---|---|---|
| Instruct chinois | instruction | 51.7 | 55.0 | 50.0 | 51.5 |
| Chinois-mixtral | Piédestal | 45.8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7b-instruct-v0.1 | instruction | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7b-v0.1 | Piédestal | 47.3 | 54.6 | 46.1 | 50.3 |
| Chinois-alpaca-2-13b | instruction | 44.3 | 45.9 | 42.6 | 44.0 |
| Chinois-llama-2-13b | Piédestal | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU est un autre ensemble de données d'évaluation chinois complet, spécifiquement utilisé pour évaluer les connaissances et la capacité de raisonnement des modèles de langage dans le contexte chinois, couvrant 67 sujets des sujets de base au niveau professionnel avancé, avec un total de 11,5k à choix multiple. Veuillez vous référer à ce projet pour CMMLU Inference Code: GitHub Wiki
| Modèles | taper | Test (0-shot) | Test (5-shot) |
|---|---|---|---|
| Instruct chinois | instruction | 50.0 | 53.0 |
| Chinois-mixtral | Piédestal | 42.5 | 51.0 |
| Mixtral-8x7b-instruct-v0.1 | instruction | 48.2 | 51.6 |
| Mixtral-8x7b-v0.1 | Piédestal | 44.3 | 51.6 |
| Chinois-alpaca-2-13b | instruction | 43.2 | 45,5 |
| Chinois-llama-2-13b | Piédestal | 38.9 | 42.5 |
MMLU est un ensemble de données d'évaluation en anglais pour évaluer la capacité de compréhension du langage naturel. C'est l'un des principaux ensembles de données utilisés pour évaluer les grandes capacités de modèle aujourd'hui. L'ensemble de vérification et le jeu de test contiennent respectivement des questions de 1K et 14,1k à choix multiples couvrant 57 sujets. Veuillez vous référer à ce projet pour le code d'inférence MMLU: GitHub Wiki
| Modèles | taper | Valide (0-shot) | VALIDE (5-Shot) | Test (0-shot) | Test (5-shot) |
|---|---|---|---|---|---|
| Instruct chinois | instruction | 65.1 | 69.6 | 67.5 | 69.8 |
| Chinois-mixtral | Piédestal | 63.2 | 67.1 | 65,5 | 68.3 |
| Mixtral-8x7b-instruct-v0.1 | instruction | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-v0.1 | Piédestal | 64.9 | 69.0 | 67.0 | 69.5 |
| Chinois-alpaca-2-13b | instruction | 49.6 | 53.2 | 50.9 | 53.5 |
| Chinois-llama-2-13b | Piédestal | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench est une référence pour évaluer la capacité de compréhension du texte long d'un grand modèle. Il se compose de 6 catégories grandes et de 20 tâches différentes. La durée moyenne de la plupart des tâches se situe entre 5k et 15k et contient environ 4,75k de données de test. Ce qui suit est l'effet d'évaluation de ce modèle de projet sur cette tâche chinoise (y compris les tâches de code). Veuillez vous référer à ce projet pour le code d'inférence Longbench: GitHub Wiki
| Modèles | Document unique QA | QA multi-documents | résumé | Apprentissage FS | Achèvement du code | Tâche de synthèse | moyenne |
|---|---|---|---|---|---|---|---|
| Instruct chinois | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| Chinois-mixtral | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7b-instruct-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7b-v0.1 | 35,5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| Chinois-alpaca-2-13b-16k | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinois-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinois-alpaca-2-7b-64k | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinois-Llama-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
Sous Llama.cpp, les performances du modèle de version quantitative chinoise-Mixtral ont été testées, comme indiqué dans le tableau suivant.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | Iq3_xxs | Q2_K | Iq2_xs | Iq2_xx | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Taille (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 SPEXE MAX | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 vitesse | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Note
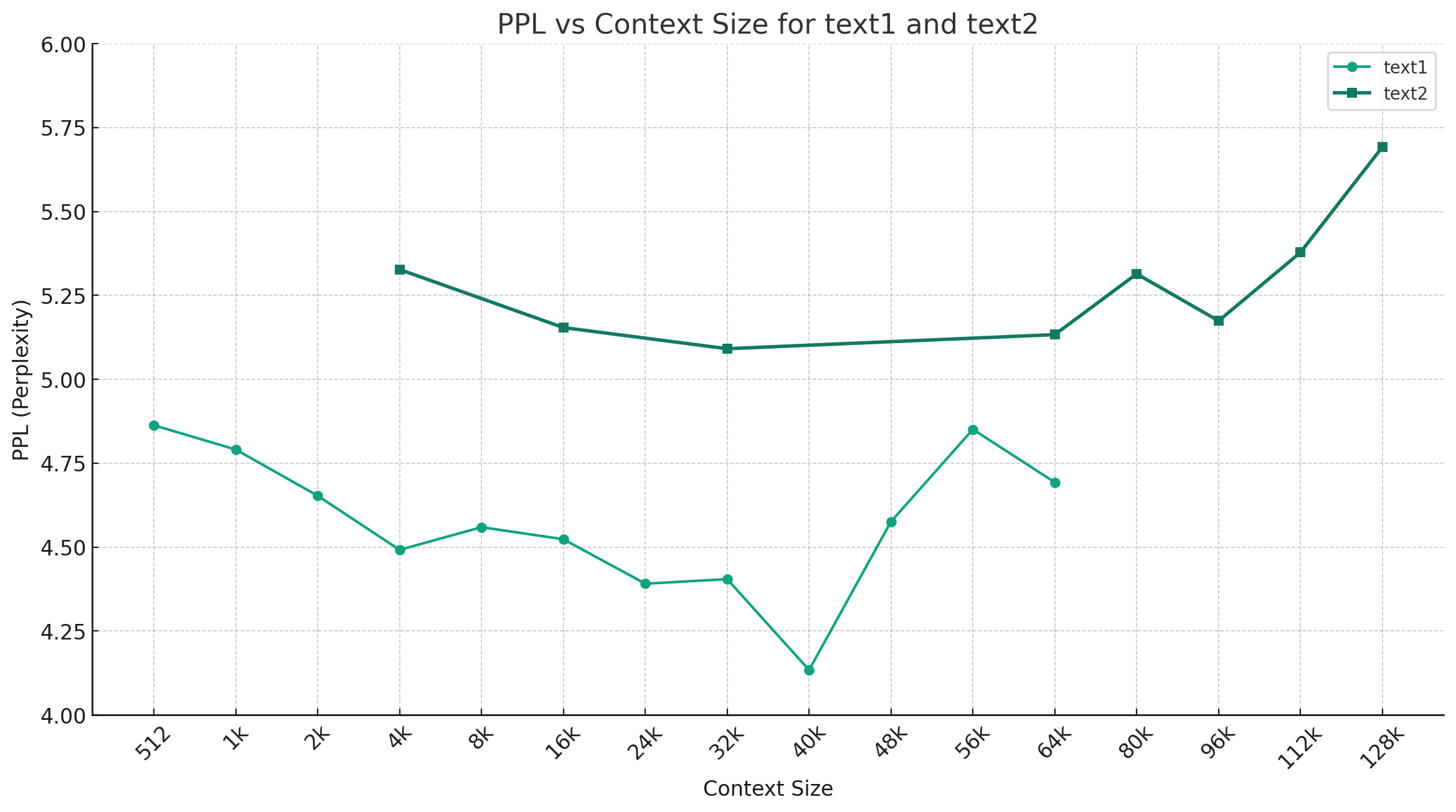
Prenant l'exemple du chinois-mixtral-Q4_0, la figure ci-dessous montre la tendance du changement de PPL sous différentes longueurs de contexte, et deux ensembles différents de données de texte brut ont été sélectionnés. Les résultats expérimentaux montrent que la longueur de contexte soutenue par le modèle Mixtral a dépassé le 32k nominal, et il a toujours de bonnes performances dans le cadre du contexte de 64k + (en fait mesuré jusqu'à 128k).
Modèle directif:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Remarque: <s> et </s> sont des jetons spéciaux représentant le début et la fin d'une séquence, tandis que [INST] et [/INST] sont des chaînes ordinaires.
Veuillez vérifier si la solution existe déjà dans la FAQ avant de mentionner le problème. Pour des questions et réponses spécifiques, veuillez vous référer à ce projet Wiki GitHub
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Ce projet est développé sur la base du modèle Mixtral publié par Mistral.ai. Veuillez respecter strictement le contrat de licence Open Source Mixtral pendant l'utilisation. Si l'utilisation du code tiers est impliquée, assurez-vous de respecter le contrat de licence open source pertinent. Le contenu généré par le modèle peut affecter sa précision en raison des méthodes de calcul, des facteurs aléatoires et des pertes de précision quantitative. Par conséquent, ce projet ne garantit aucune garantie de l'exactitude de la sortie du modèle, et il sera responsable des pertes causées par l'utilisation des ressources pertinentes et des résultats de sortie. Si les modèles pertinents de ce projet sont utilisés à des fins commerciales, le développeur doit respecter les lois et réglementations locales pour garantir le respect du contenu de sortie du modèle. Ce projet ne sera pas responsable des produits ou services qui en ont été dérivés.
Si vous avez des questions, veuillez la soumettre dans le problème de GitHub. Posez des questions poliment et construisez une communauté de discussion harmonieuse.


