Chinese Mixtral
v1.2
؟؟ الصينية | الإنجليزية | المستندات/المستندات | ❓ الأسئلة/القضايا | المناقشات/المناقشات | ⚔ الساحة/الساحة

تم تطوير هذا المشروع استنادًا إلى نموذج Mixtral الذي تم إصداره بواسطة Mistral.ai ، والذي يستخدم بنية Moe المتفجرة. يستخدم هذا المشروع بيانات صينية خالية من الملصقات على نطاق واسع لإجراء تدريب تدريجي صيني للحصول على النموذج الأساسي لـ Mixtral الصيني ، ويستخدم مزيد من التعليمات لتعليم غرامة للحصول على نموذج تعليمات البنية الصينية . يدعم النموذج سياق 32 كيلو لتر (تم اختباره حتى 128 كيلو) ، والذي يمكنه معالجة النص الطويل بشكل فعال ، وفي الوقت نفسه يحقق تحسينات كبيرة في الأداء في التفكير الرياضي ، وتوليد الرموز ، وما إلى ذلك عند استخدام llama.cpp للتفكير الكمي ، يستغرق فقط ذاكرة 16G (أو ذاكرة الفيديو).
التقرير الفني : [Cui and Yao ، 2024] إعادة التفكير في تكييف اللغة LLM: دراسة حالة عن المختلط الصيني [تفسير الورق]
الصينية LAMA-2 و Alpaca-2 Mockup | الصينية لاما وألباكا النموذج | متعددة الوسائط الصينية LAMA & Alpaca Mockup | متعدد الوسائط Vle | الصينية minirbt | ليرت الصينية | اللغة الإنجليزية الصينية بيرت | صينية ماكبرت | إلكترا الصينية | صينية XLNET | بيرت الصينية | أداة التقطير المعرفة TextBrewer | أداة قطع النموذج TextPruner | التقطير وحبوب تكامل القطع
[2024/04/30] تم إصدار الصينية-اللاما-Alpaca-3 رسميًا ، المصدر المفتوح Llama-3-Chinese-8b و Llama-3-chinese-8b-instruct على أساس Llama-3 ، يرجى الرجوع إلى: https://github.com/ymcui/chinese-llama-3
[2024/03/27] أضف نسخة كمية 1-bit/2-bit/3-bit من نموذج GGUF: [؟ HF] ؛ في الوقت نفسه ، تم نشر هذا المشروع في قلب آلة سوتا! منصة النموذج ، مرحبًا بك في متابعة: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] أضف وضع نشر API Openai Mimic. عرض التفاصيل: V1.2 إصدار إصدار الإصدار
[2024/03/05] تدريب النموذج المفتوح المصدر ورمز النقل ، نشر التقارير الفنية. عرض التفاصيل: V1.1 إصدار إصدار الإصدار
[2024/01/29] تم إصداره رسميًا من الصينيين (النموذج الأساسي) والبنية الصينية-ميكسترال (نموذج التعليم/الدردشة). عرض التفاصيل: سجل الإصدار v1.0
| الفصل | يصف |
|---|---|
| ؟؟ model مقدمة | قدم بإيجاز الخصائص التقنية للنماذج ذات الصلة لهذا المشروع |
| تنزيل model | عنوان تنزيل نموذج Mixtral الصيني |
| التفكير والنشر | يقدم كيفية تحديد النماذج ونشر وتجربة نماذج كبيرة باستخدام جهاز كمبيوتر شخصي |
| تأثير النموذج | يتم تقديم تأثير النموذج على بعض المهام |
| التدريب واللحن | تقديم كيفية تدريب وضبط نموذج Mixtral الصيني |
| ❓faq | ردود على بعض الأسئلة الشائعة |
هذا المشروع مفتوح المصدر النماذج الصينية المختلطة والنماذج الصينية المزيج المزيج على أساس نموذج مختلط ، وميزاته الرئيسية هي كما يلي:
Mixtral هو نموذج خبير مختلط متناثر. هذا النموذج له اختلافات كبيرة عن النماذج السائدة السائدة السابقة مثل Llama ، والتي تنعكس بشكل أساسي في النقاط التالية:
فيما يلي رسم بياني هيكلي في ورقة mixtral:
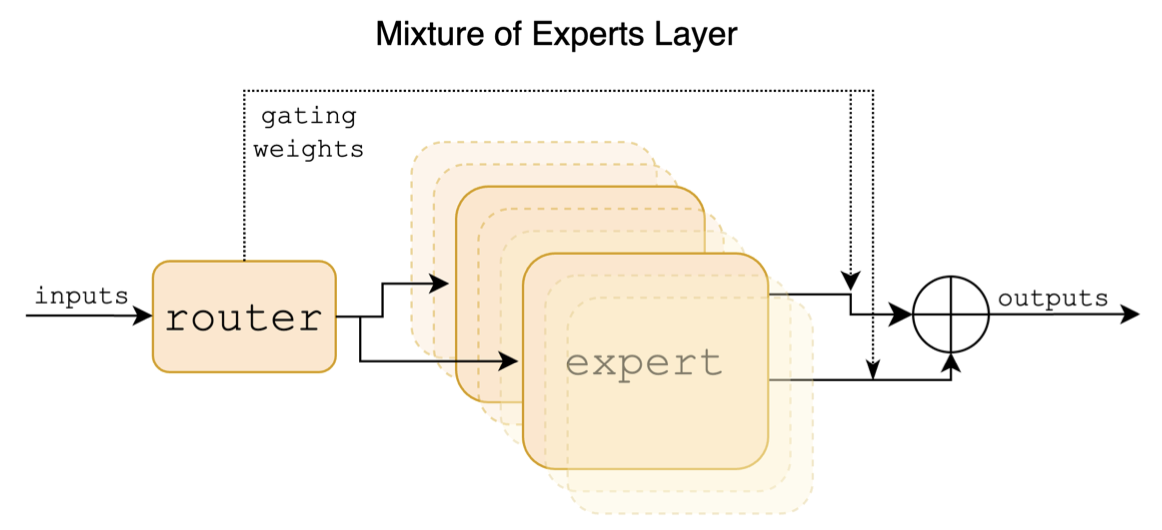
على عكس مشاريع الصينية اللاماما-ألباكا والصينية لاما-ألبياكا -2 ، يدعم نموذج Mixtral سياق 32 كيلو (يمكن أن يصل القياس الفعلي إلى 128 كيلو بايت). يمكن للمستخدمين استخدام نموذج واحد لحل مهام مختلفة بأطوال مختلفة.
فيما يلي مقارنة بين نموذج هذا المشروع وسيناريوهات الاستخدام الموصى بها. لتفاعل الدردشة ، حدد إصدار الإرشادات.
| عناصر المقارنة | mixtral الصينية | البنية الصينية mixtral-instral |
|---|---|---|
| نوع النموذج | نموذج قاعدة | نموذج التوجيه/الدردشة (دراستيك) |
| حجم النموذج | 8x7b (تم تنشيطه بالفعل حوالي 13 ب) | 8x7b (تم تنشيطه بالفعل حوالي 13 ب) |
| عدد الخبراء | 8 (المنشط فعليًا 2) | 8 (المنشط فعليًا 2) |
| نوع التدريب | السببية (CLM) السببية (CLM) | تعليمات تعليم غرامة |
| طريقة التدريب | qlora + المبلغ الكامل EMB/LM-HEAD | qlora + المبلغ الكامل EMB/LM-HEAD |
| أي نموذج للتدريب | Original Mixtral-8x7B-V0.1 | mixtral الصينية |
| مواد التدريب | مقال عام غير مميز | بيانات التعليمات المسمى |
| حجم المفردات | قائمة المفردات الأصلية ، 32000 | قائمة المفردات الأصلية ، 32000 |
| يدعم طول السياق | 32 كيلو (تم قياسه بالفعل حتى 128 كيلو) | 32 كيلو (تم قياسه بالفعل حتى 128 كيلو) |
| قالب الإدخال | غير ضروري | تحتاج إلى تطبيق قالب mixtral-instruct |
| السيناريوهات المعمول بها | استمرار النص: بالنظر إلى النص أعلاه ، دع النموذج ينشئ النص التالي | فهم القيادة: سؤال وجواب ، الكتابة ، الدردشة ، التفاعل ، إلخ. |
فيما يلي 3 أنواع مختلفة من النماذج:
| اسم النموذج | يكتب | مواصفة | النسخة الكاملة (87 جيجابايت) | إصدار لورا (2.4 جيجابايت) | نسخة GGUF |
|---|---|---|---|---|---|
| صينية mixtral | نموذج قاعدة | 8x7b | [بايدو] [؟ HF] [؟ modelscope] | [بايدو] [؟ HF] [؟ modelscope] | [؟ HF] |
| صينية ميكسترال-إرساء | نموذج التعليمات | 8x7b | [بايدو] [؟ HF] [؟ modelscope] | [بايدو] [؟ HF] [؟ modelscope] | [؟ HF] |
ملحوظة
إذا لم تتمكن من الوصول إلى HF ، فيمكنك النظر في بعض مواقع المرآة (مثل hf-mirror.com). يرجى العثور على الأساليب المحددة وحلها بنفسك.
تدعم النماذج ذات الصلة في هذا المشروع بشكل أساسي أساليب القياس والتفكير والنشر التاليين. لمزيد من التفاصيل ، يرجى الرجوع إلى البرنامج التعليمي المقابل.
| أداة | سمات | وحدة المعالجة المركزية | GPU | الكمية | واجهة المستخدم الرسومية | API | vllm | درس تعليمي |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | الخيارات الكمية الغنية والتفكير المحلي الفعال | ✅ | ✅ | ✅ | ✅ | [وصلة] | ||
| ؟محولات | واجهة الاستدلال المحولات الأصلية | ✅ | ✅ | ✅ | ✅ | ✅ | [وصلة] | |
| تقليد مكالمات API Openai | العرض التجريبي الذي يحاكي واجهة Openai API | ✅ | ✅ | ✅ | ✅ | ✅ | [وصلة] | |
| توليد النص ويبوي | كيفية نشر واجهة واجهة مستخدم الويب الواجهة الأمامية | ✅ | ✅ | ✅ | ✅ | ✅ | [وصلة] | |
| لانجشين | إطار عمل مفتوح المصدر للتطبيق على نطاق واسع مناسب للتطوير الثانوي | ✅ | ✅ | ✅ | [وصلة] | |||
| خصوصية | إطار أسئلة وإجابة محلية متعددة الحجة | ✅ | ✅ | ✅ | [وصلة] | |||
| استوديو LM | برنامج دردشة متعدد المنصات (مع واجهة) | ✅ | ✅ | ✅ | ✅ | ✅ | [وصلة] |
من أجل تقييم تأثيرات النماذج ذات الصلة ، أجرى هذا المشروع تقييم التأثير التوليدي وتقييم التأثير الموضوعي (فئة NLU) على التوالي ، وتقييم النموذج الكبير من زوايا مختلفة. يوصى بأن يختبر المستخدمون في المهام التي يهتمون بها وتحديد النماذج التي تتكيف مع المهام ذات الصلة.
C-Eval هو جناح شامل لتقييم النموذج الصيني الأساسي ، حيث تحتوي مجموعة التحقق ومجموعة الاختبار على 1.3 كيلو و 12.3 ألف أسئلة متعددة الخيارات ، تغطي 52 موضوعًا ، على التوالي. يرجى الرجوع إلى هذا المشروع للحصول على رمز الاستدلال C: Github Wiki
| النماذج | يكتب | صالح (0 طلقة) | صالح (5 طلقة) | اختبار (0 طلقة) | اختبار (5 طلقة) |
|---|---|---|---|---|---|
| صينية ميكسترال-إرساء | تعليمات | 51.7 | 55.0 | 50.0 | 51.5 |
| صينية mixtral | قاعدة التمثال | 45.8 | 54.2 | 43.1 | 49.1 |
| mixtral-8x7b-instruct-v0.1 | تعليمات | 51.6 | 54.0 | 48.7 | 50.7 |
| mixtral-8x7b-v0.1 | قاعدة التمثال | 47.3 | 54.6 | 46.1 | 50.3 |
| الصينية alpaca-2-13b | تعليمات | 44.3 | 45.9 | 42.6 | 44.0 |
| الصينية لاما 2-13B | قاعدة التمثال | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU هي مجموعة بيانات شاملة للتقييم الصينية ، وتستخدم خصيصًا لتقييم المعرفة وقدرة النماذج اللغوية على المعرفة في السياق الصيني ، وتغطي 67 موضوعًا من الموضوعات الأساسية إلى المستوى المهني المتقدم ، مع ما مجموعه 11.5 كيلو أسئلة متعددة الخيارات. يرجى الرجوع إلى هذا المشروع لرمز الاستدلال CMMLU: جيثب ويكي
| النماذج | يكتب | اختبار (0 طلقة) | اختبار (5 طلقة) |
|---|---|---|---|
| صينية ميكسترال-إرساء | تعليمات | 50.0 | 53.0 |
| صينية mixtral | قاعدة التمثال | 42.5 | 51.0 |
| mixtral-8x7b-instruct-v0.1 | تعليمات | 48.2 | 51.6 |
| mixtral-8x7b-v0.1 | قاعدة التمثال | 44.3 | 51.6 |
| الصينية alpaca-2-13b | تعليمات | 43.2 | 45.5 |
| الصينية لاما 2-13B | قاعدة التمثال | 38.9 | 42.5 |
MMLU هي مجموعة بيانات تقييم اللغة الإنجليزية لتقييم القدرة على فهم اللغة الطبيعية. إنها واحدة من مجموعات البيانات الرئيسية المستخدمة لتقييم إمكانيات النموذج الكبيرة اليوم. تحتوي مجموعة التحقق ومجموعة الاختبار على 1.5k و 14.1k أسئلة متعددة الخيارات ، على التوالي ، تغطي 57 موضوعًا. يرجى الرجوع إلى هذا المشروع لرمز الاستدلال MMLU: جيثب ويكي
| النماذج | يكتب | صالح (0 طلقة) | صالح (5 طلقة) | اختبار (0 طلقة) | اختبار (5 طلقة) |
|---|---|---|---|---|---|
| صينية ميكسترال-إرساء | تعليمات | 65.1 | 69.6 | 67.5 | 69.8 |
| صينية mixtral | قاعدة التمثال | 63.2 | 67.1 | 65.5 | 68.3 |
| mixtral-8x7b-instruct-v0.1 | تعليمات | 68.5 | 70.4 | 68.2 | 70.2 |
| mixtral-8x7b-v0.1 | قاعدة التمثال | 64.9 | 69.0 | 67.0 | 69.5 |
| الصينية alpaca-2-13b | تعليمات | 49.6 | 53.2 | 50.9 | 53.5 |
| الصينية لاما 2-13B | قاعدة التمثال | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench هو معيار لتقييم قدرة فهم النص الطويل لنموذج كبير. وهو يتكون من 6 فئات رئيسية و 20 مهمة مختلفة. يتراوح متوسط طول المهام بين 5 كيلو و 15 كيلو ، ويحتوي على حوالي 4.75 ألف بيانات اختبار. فيما يلي تأثير التقييم لنموذج المشروع هذا على هذه المهمة الصينية (بما في ذلك مهام الكود). يرجى الرجوع إلى هذا المشروع لرمز الاستدلال Longbench: Github Wiki
| النماذج | وثيقة واحدة QA | متعددة الوثيقة QA | ملخص | التعلم FS | إكمال رمز | مهمة التوليف | متوسط |
|---|---|---|---|---|---|---|---|
| صينية ميكسترال-إرساء | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| صينية mixtral | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| mixtral-8x7b-instruct-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| mixtral-8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| الصينية-ألبياكا -2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| الصينية-لاما -2-13B-16K | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| الصينية-alpaca-2-7b-64k | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| الصينية لاما 2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
تحت llama.cpp ، تم اختبار أداء نموذج الإصدار الكمي الصيني ، كما هو موضح في الجدول التالي.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | iq3_xxs | Q2_K | iq2_xs | iq2_xxs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| الحجم (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| PPL | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 أقصى سرعة | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 سرعة | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
ملحوظة
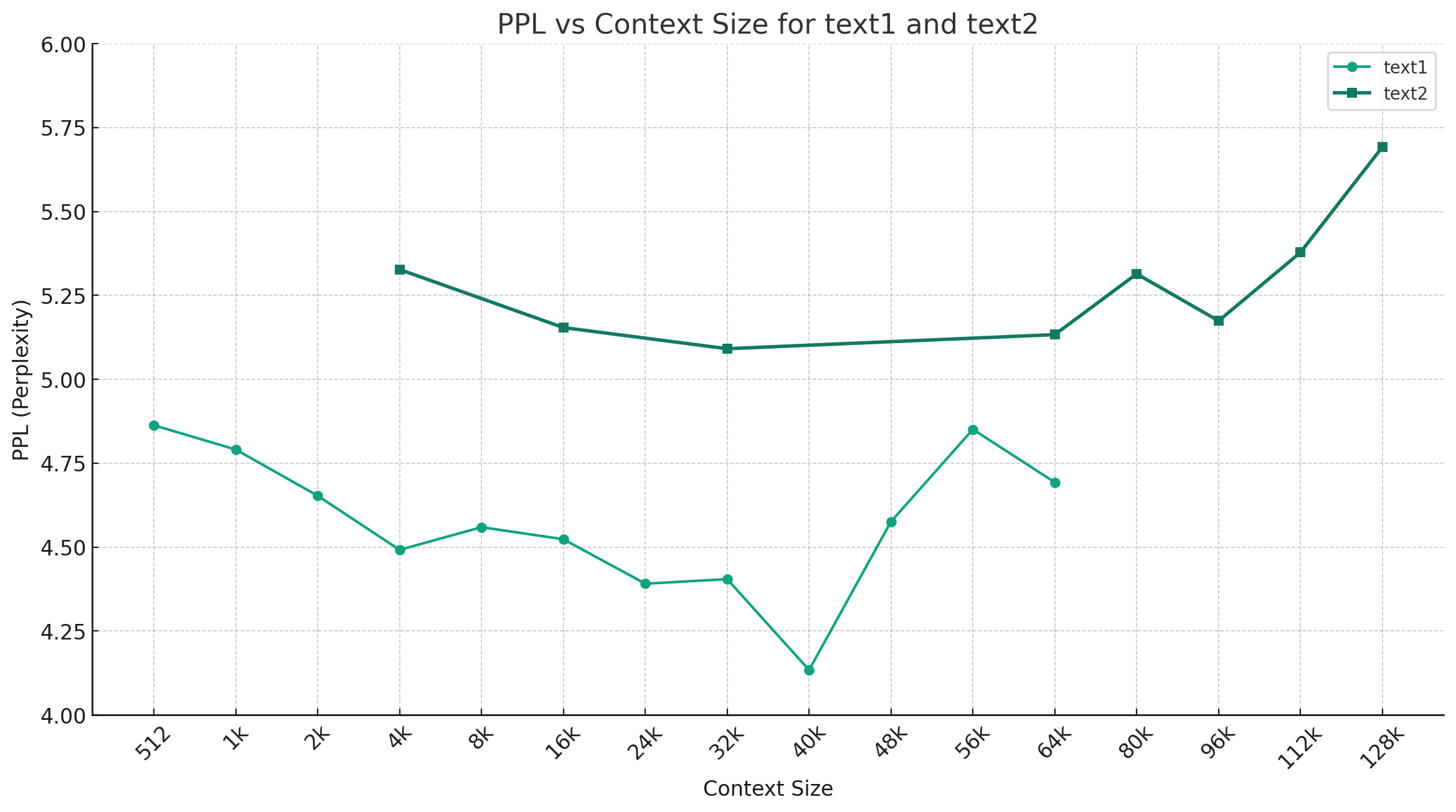
مع أخذ صيني mixtral-q4_0 كمثال ، يوضح الشكل أدناه اتجاه تغيير PPL تحت أطوال سياق مختلفة ، وتم تحديد مجموعتين مختلفتين من بيانات النص العادي. تُظهر النتائج التجريبية أن طول السياق المدعوم من نموذج Mixtral قد تجاوز 32 ألفًا الاسمية ، ولا يزال يتمتع بأداء جيد أقل من 64 كيلو+ سياق (تم قياسه فعليًا حتى 128 كيلو بايت).
قالب التوجيه:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
ملاحظة: <s> و </s> رموز خاصة تمثل بداية ونهاية التسلسل ، في حين أن [INST] و [/INST] سلاسل عادية.
يرجى التحقق مما إذا كان الحل موجود بالفعل في الأسئلة الشائعة قبل ذكر المشكلة. للحصول على أسئلة وأجوبة محددة ، يرجى الرجوع إلى هذا المشروع Github Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}تم تطوير هذا المشروع بناءً على نموذج Mixtral الذي نشرته Mistral.ai. يرجى الالتزام الصارم باتفاقية ترخيص المصدر المفتوح Mixtral أثناء الاستخدام. إذا كان استخدام رمز الطرف الثالث متورطًا ، فتأكد من الامتثال لاتفاقية ترخيص المصدر المفتوح ذات الصلة. قد يؤثر المحتوى الناتج عن النموذج على دقته بسبب طرق الحساب ، والعوامل العشوائية ، وخسائر الدقة الكمية. لذلك ، لا يوفر هذا المشروع أي ضمان لدقة ناتج النموذج ، ولن يكون مسؤولاً عن أي خسائر ناتجة عن استخدام الموارد ونتائج الإخراج ذات الصلة. إذا تم استخدام النماذج ذات الصلة لهذا المشروع للأغراض التجارية ، فيجب على المطور الالتزام بالقوانين واللوائح المحلية لضمان الامتثال لمحتوى الإخراج للنموذج. لن يكون هذا المشروع مسؤولاً عن أي منتجات أو خدمات مستمدة منها.
إذا كان لديك أي أسئلة ، فيرجى إرسالها في قضية GitHub. اطرح أسئلة بأدب وبناء مجتمع نقاش متناغم.


