Chinese Mixtral
v1.2
?? Chinês | Inglês | Documentos/documentos | ❓ Perguntas/questões | Discussões/discussões | Arena Arena/arena

Este projeto é desenvolvido com base no modelo mixtral lançado pelo Mistral.ai, que usa a arquitetura MOE esparsa. Este projeto utiliza dados sem rótulos chineses em larga escala para realizar treinamento incremental chinês para obter o modelo básico misto chinês e utilizar ainda mais a instrução ajuste fino para obter o modelo de instrução de instrução mixtral chinesa . O modelo suporta nativamente o contexto de 32k (testado até 128k) , que pode efetivamente processar texto longo e, ao mesmo tempo, obter melhorias significativas de desempenho no raciocínio matemático, geração de código etc. Ao usar llama.cpp para raciocínio quantitativo, ele só é de 16G de memória (ou memória de vídeo).
Relatório Técnico : [CUI e YAO, 2024] Repensando a adaptação ao idioma LLM: um estudo de caso sobre mixtral chinês [interpretação do papel]
Mockup chinês de lhama-2 e alpaca-2 | Mockup chinês de lhama e alpaca | Mockup multimodal chinês Llama & Alpaca | Vle multimodal | Minirbt chinês | Lert chinês | Pert inglesa chinesa | MacBert chinês | Electra chinês | Xlnet chinês | Bert chinês | Ferramenta de destilação do conhecimento Textbrewer | Ferramenta de corte de modelo PRUNHER DO TEXTO | Destilação e corte de grãos de integração
[2024/04/30] Chinês-llama-alpaca-3 foi lançado oficialmente, Llama-3-Chinese-8b de código aberto e LLAMA-3-CHINES-8B-Instruct baseado em llama-3, consulte: https://github.com/ymcui/chinese-lama-alpaca-alpaca-lpaça-
[2024/03/27] Adicionar versão quantitativa de 1 bit/2 bits/3 bits do modelo GGUF: [? HF]; Ao mesmo tempo, este projeto foi implantado no coração da STATA SOTA! Modelo Plataforma, Bem-vindo a seguir: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Adicione um modo de implantação MIMIC OpenAI API. View Detalhes: V1.2 Log de versão da versão
[2024/03/05] Treinamento de modelo de código aberto e código de ajuste fino, publique relatórios técnicos. View Detalhes: V1.1 Log de versão da versão
[2024/01/29] lançou oficialmente o chinês-mixtral (modelo básico) e a instrução chinesa-mixtral (modelo de instrução/bate-papo). View Detalhes: V1.0 Log de versão da versão
| capítulo | descrever |
|---|---|
| ?? ♂️Model Introdução | Apresente brevemente as características técnicas dos modelos relevantes deste projeto |
| ⏬Model Download | Endereço de download do modelo mixtral chinês |
| Raciocínio e implantação | Introduz como quantificar modelos e implantar e experimentar modelos grandes usando um computador pessoal |
| ? Efeito do modelo | O efeito do modelo em algumas tarefas é introduzido |
| Treinamento e Tune Fine | Apresentando como treinar e ajustar o modelo mixtral chinês |
| ❓faq | Respostas a algumas perguntas frequentes |
Este projeto, os modelos Mixtral-Mixtral-Instruções Mixtral de código aberto desenvolvidas com base no modelo mixtral, e seus principais recursos são os seguintes:
Mixtral é um modelo de especialista híbrido esparso. Este modelo possui diferenças significativas em relação aos modelos anteriores em larga escala, como o LLAMA, que se reflete principalmente nos seguintes pontos:
A seguir, é apresentado um diagrama estrutural no papel mixtral:
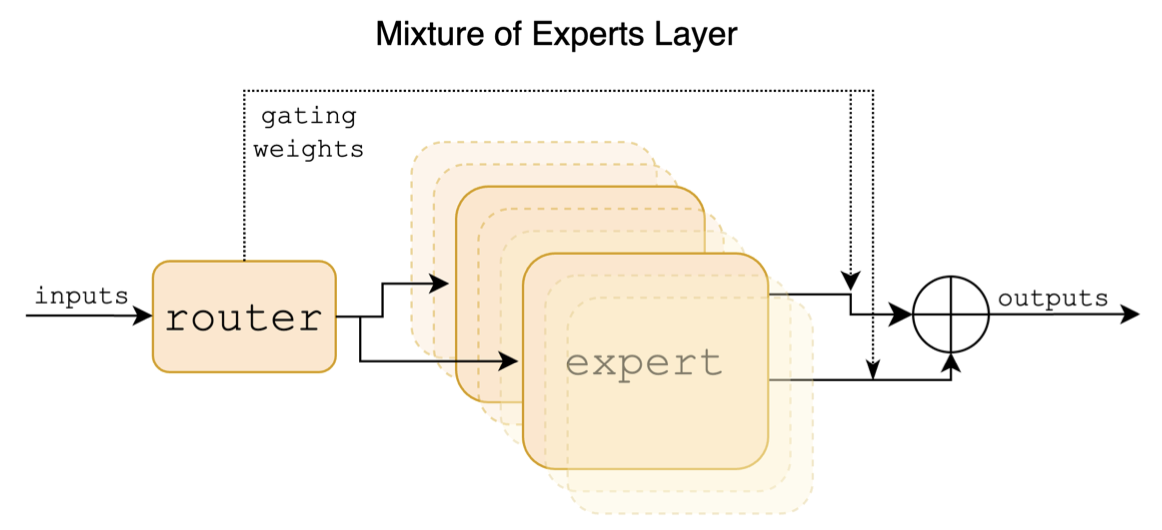
Ao contrário dos projetos chineses-lama-alpaca e chinês-lama-alpaca-2, o modelo mixtral suporta nativamente o contexto de 32k (a medição real pode atingir 128k). Os usuários podem usar um único modelo para resolver várias tarefas de diferentes comprimentos.
A seguir, é apresentada uma comparação do modelo deste projeto e dos cenários de uso recomendado. Para interação de bate -papo, selecione a versão Instruct.
| Itens de comparação | Mixtral chinês | Instrução mista chinesa |
|---|---|---|
| Tipo de modelo | Modelo base | Modelo de diretiva/bate -papo (classe chatgpt) |
| Tamanho do modelo | 8x7b (na verdade ativado cerca de 13b) | 8x7b (na verdade ativado cerca de 13b) |
| Número de especialistas | 8 (na verdade ativado 2) | 8 (na verdade ativado 2) |
| Tipo de treinamento | Causal-lm (CLM) | Instrução Ajuste fino |
| Método de treinamento | Qlora + quantidade completa emb/lm-cabeça | Qlora + quantidade completa emb/lm-cabeça |
| Que modelo para treinar | Mixtral-8x7b-v0.1 original | Mixtral chinês |
| Materiais de treinamento | Ensaio geral não marcado | Dados de instrução rotulados |
| Tamanho do vocabulário | Lista de vocabulário original, 32000 | Lista de vocabulário original, 32000 |
| Suporta o comprimento do contexto | 32k (na verdade medido até 128k) | 32k (na verdade medido até 128k) |
| Modelo de entrada | desnecessário | Precisa aplicar o modelo de instrução mixtral |
| Cenários aplicáveis | Continuação do texto: Dado o texto acima, deixe o modelo gerar o seguinte texto | Entendimento de comando: Perguntas e respostas, escrita, bate -papo, interação, etc. |
Aqui estão três tipos diferentes de modelos:
| Nome do modelo | tipo | Especificação | Versão completa (87 GB) | Lora versão (2,4 GB) | Versão GGUF |
|---|---|---|---|---|---|
| Mixtral chinês | Modelo base | 8x7b | [Baidu] [? HF] [? ModelsCope] | [Baidu] [? HF] [? ModelsCope] | [? HF] |
| Instrução chinesa-mixtral | Modelo de instrução | 8x7b | [Baidu] [? HF] [? ModelsCope] | [Baidu] [? HF] [? ModelsCope] | [? HF] |
Observação
Se você não puder acessar a HF, pode considerar alguns sites de espelho (como hf-mirror.com). Encontre e resolva os métodos específicos você mesmo.
Os modelos relevantes deste projeto suportam principalmente os seguintes métodos de quantização, raciocínio e implantação. Para detalhes, consulte o tutorial correspondente.
| ferramenta | Características | CPU | GPU | Quantificação | GUI | API | vllm | Tutorial |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | Ricas opções quantitativas e raciocínio local eficiente | ✅ | ✅ | ✅ | ✅ | [link] | ||
| ? Transformadores | Interface de inferência dos transformadores nativos | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Imitação de chamadas de API OpenAi | Demoção do servidor que emula a interface da API OpenAi | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| GENERAÇÃO DE TEXTO-WEBUI | Como implantar a interface da interface do usuário do front-end | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Langchain | Estrutura de código aberto para aplicativos em larga escala adequados para desenvolvimento secundário | ✅ | ✅ | ✅ | [link] | |||
| privategpt | Multi-documenting Local Pergunta e estrutura de respostas | ✅ | ✅ | ✅ | [link] | |||
| LM Studio | Software de bate-papo com várias plataformas (com interface) | ✅ | ✅ | ✅ | ✅ | ✅ | [link] |
Para avaliar os efeitos de modelos relacionados, este projeto conduziu avaliação de efeitos generativos e avaliação de efeitos objetivos (classe NLU), respectivamente, e avaliou o grande modelo de diferentes ângulos. Recomenda -se que os usuários testem as tarefas com as quais se preocupem e selecione modelos que se adaptam às tarefas relacionadas.
O C-EVAL é um conjunto abrangente de avaliação de modelo básico chinês, no qual o conjunto de verificação e o conjunto de testes contêm perguntas de 1,3 mil e 12,3k, cobrindo 52 indivíduos, respectivamente. Consulte este projeto para o código de inferência C-EVAL: Github Wiki
| Modelos | tipo | Válido (0-shot) | Válido (5-shot) | Teste (0-shot) | Teste (5-shot) |
|---|---|---|---|---|---|
| Instrução chinesa-mixtral | instrução | 51.7 | 55.0 | 50.0 | 51.5 |
| Mixtral chinês | Pedestal | 45.8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7b-Instruct-v0.1 | instrução | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7b-v0.1 | Pedestal | 47.3 | 54.6 | 46.1 | 50.3 |
| Chinês-alpaca-2-13b | instrução | 44.3 | 45.9 | 42.6 | 44.0 |
| Chinês-llama-2-13b | Pedestal | 40.6 | 42.7 | 38.0 | 41.6 |
O CMMLU é outro conjunto de dados abrangente de avaliação chinesa, usado especificamente para avaliar o conhecimento e a capacidade de raciocínio dos modelos de linguagem no contexto chinês, cobrindo 67 tópicos de assuntos básicos a nível profissional avançado, com um total de 11,5 mil perguntas de múltipla escolha. Consulte este projeto para o Código de Inferência CMMLU: Github Wiki
| Modelos | tipo | Teste (0-shot) | Teste (5-shot) |
|---|---|---|---|
| Instrução chinesa-mixtral | instrução | 50.0 | 53.0 |
| Mixtral chinês | Pedestal | 42.5 | 51.0 |
| Mixtral-8x7b-Instruct-v0.1 | instrução | 48.2 | 51.6 |
| Mixtral-8x7b-v0.1 | Pedestal | 44.3 | 51.6 |
| Chinês-alpaca-2-13b | instrução | 43.2 | 45.5 |
| Chinês-llama-2-13b | Pedestal | 38.9 | 42.5 |
O MMLU é um conjunto de dados de avaliação em inglês para avaliar a capacidade de compreensão da linguagem natural. É um dos principais conjuntos de dados usados para avaliar hoje grandes recursos de modelo. O conjunto de verificação e o conjunto de testes contêm perguntas de 1,5 mil e 14,1k de múltipla escolha, respectivamente, cobrindo 57 indivíduos. Consulte este projeto para MMLU Código de Inferência: Github Wiki
| Modelos | tipo | Válido (0-shot) | Válido (5-shot) | Teste (0-shot) | Teste (5-shot) |
|---|---|---|---|---|---|
| Instrução chinesa-mixtral | instrução | 65.1 | 69.6 | 67.5 | 69.8 |
| Mixtral chinês | Pedestal | 63.2 | 67.1 | 65.5 | 68.3 |
| Mixtral-8x7b-Instruct-v0.1 | instrução | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-v0.1 | Pedestal | 64.9 | 69.0 | 67.0 | 69.5 |
| Chinês-alpaca-2-13b | instrução | 49.6 | 53.2 | 50.9 | 53.5 |
| Chinês-llama-2-13b | Pedestal | 46.8 | 50.0 | 46.6 | 51.8 |
O Longbench é uma referência para avaliar a capacidade de compreensão de texto longa de um modelo grande. Consiste em 6 categorias principais e 20 tarefas diferentes. O comprimento médio da maioria das tarefas está entre 5K-15k e contém cerca de 4,75k de dados de teste. A seguir, é apresentado o efeito de avaliação deste modelo de projeto nessa tarefa chinesa (incluindo tarefas de código). Consulte este projeto para o Código de Inferência de Longbench: Github Wiki
| Modelos | QA de documento único | QA de vários documentos | resumo | Aprendizagem do FS | Conclusão do código | Tarefa de síntese | média |
|---|---|---|---|---|---|---|---|
| Instrução chinesa-mixtral | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| Mixtral chinês | 32.0 | 23.7 | 0,4 | 42.5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7b-Instruct-v0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| Chinês-alpaca-2-13b-16k | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinês-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinês-alpaca-2-7b-64k | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinês-llama-2-7b-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
De acordo com o LLAMA.CPP, o desempenho do modelo de versão quantitativa chinês-mixtral foi testado, como mostrado na tabela a seguir.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | Iq3_xxs | Q2_K | Iq2_xs | Iq2_xxs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tamanho (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 Velocidade máxima | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 Velocidade | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Observação
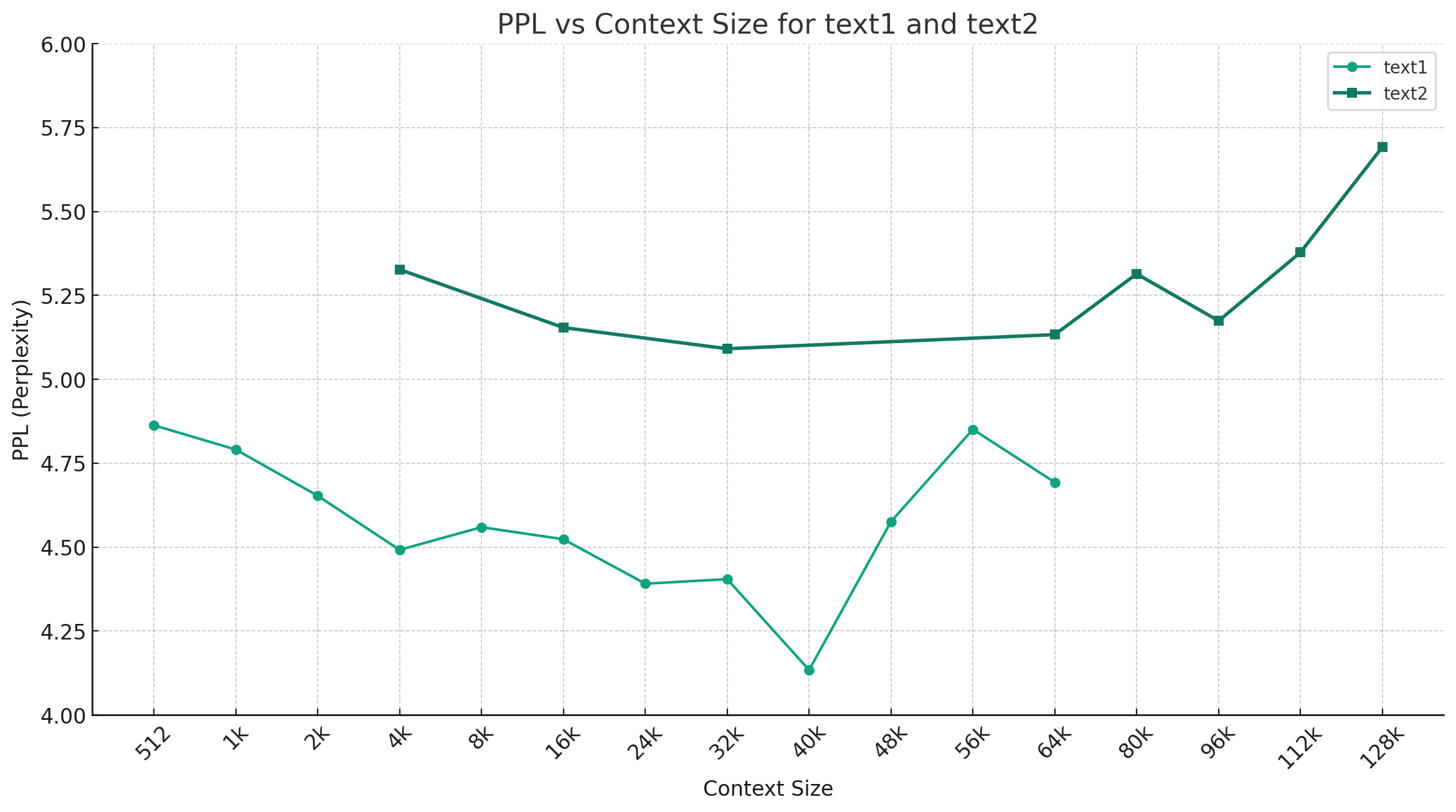
Tomando chinês-mixtral-q4_0 como exemplo, a figura abaixo mostra a tendência de alteração de PPL sob diferentes comprimentos de contexto e dois conjuntos diferentes de dados de texto simples foram selecionados. Os resultados experimentais mostram que o comprimento do contexto suportado pelo modelo mixtral excedeu o nominal 32K e ainda tem um bom desempenho abaixo do contexto de 64k+ (na verdade medido até 128k).
Modelo de diretiva:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Nota: <s> e </s> são tokens especiais que representam o início e o fim de uma sequência, enquanto [INST] e [/INST] são seqüências comuns.
Verifique se a solução já existe nas perguntas frequentes antes de mencionar o problema. Para perguntas e respostas específicas, consulte este projeto Github Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Este projeto é desenvolvido com base no modelo mixtral publicado pelo Mistral.ai. Por favor, respeite estritamente o contrato de licença de código aberto mixtral durante o uso. Se o uso de código de terceiros estiver envolvido, certifique-se de cumprir o contrato de licença de código aberto relevante. O conteúdo gerado pelo modelo pode afetar sua precisão devido a métodos de cálculo, fatores aleatórios e perdas de precisão quantitativa. Portanto, este projeto não fornece nenhuma garantia para a precisão da saída do modelo, nem será responsável por quaisquer perdas causadas pelo uso de recursos relevantes e resultados de saída. Se os modelos relevantes deste projeto forem usados para fins comerciais, o desenvolvedor deve cumprir as leis e regulamentos locais para garantir a conformidade com o conteúdo de saída do modelo. Este projeto não se responsabiliza por quaisquer produtos ou serviços derivados daí.
Se você tiver alguma dúvida, envie -o no problema do GitHub. Faça perguntas educadamente e construa uma comunidade de discussão harmoniosa.


