Chinese Mixtral
v1.2
Китайский | Английский | Документы/документы | ❓ Вопросы/проблемы | Обсуждения/дискуссии | ⚔ Арена/Арена

Этот проект разработан на основе миктральной модели, выпущенной Mistral.ai, которая использует редкую архитектуру MOE. В этом проекте используются крупномасштабные данные китайской без метки для проведения китайской инкрементной подготовки для получения китайской миктральной базовой модели, а также используют тонкую корректировку обучения для получения китайской модели инструкции с инсталляцией китайской инсталляции . Модель изначально поддерживает контекст 32K (протестированный до 128 тыс.) , Который может эффективно обрабатывать длинный текст и в то же время достигать значительных улучшений производительности в математических рассуждениях, генерации кода и т. Д. При использовании Llama.cpp для количественных рассуждений требуется только память 16G (или видео память).
Технический отчет : [Cui and Yao, 2024] Переосмысление языковой адаптации LLM: тематическое исследование китайской миктральной [бумажной интерпретации]
Китайская лама-2 и макет альпака-2 | Китайская лама и макет альпака | Мультимодальная китайская лама и макет альпака | Мультимодальный VLE | Китайский Minirbt | Китайский Лерт | Китайский английский pert | Китайский Макберт | Китайская электро | Китайский Xlnet | Китайский берт | Инструмент для дистилляции знаний TextBrewer | Модель режущего инструмента TextPruner | Дистилляция и резка интеграция зерна
[2024/04/30] китайский-лама-альпака-3 был официально выпущен, Llama-3-Chinese-8b и Llama-3-chinese-8b-instruct на основе Llama-3, пожалуйста, см.
[2024/03/27] Добавить 1-битную/2-битную/3-битную количественную версию модели GGUF: [? HF]; В то же время этот проект был развернут в самом сердце машины SOTA! Модельная платформа, добро пожаловать: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Добавьте режим развертывания API Mimic OpenAI. Просмотр деталей: v1.2
[2024/03/05] Обучение модели с открытым исходным кодом и код точной настройки, публикуйте технические отчеты. Просмотр деталей: v1.1 журнал выпуска версии
[2024/01/29] Официально выпущенные китайские миктральные (базовую модель) и китайскую-микстральную инстакцию (модель инструкции/чата). Просмотр подробностей: v1.0 журнал выпуска версии
| глава | описывать |
|---|---|
| ? | Кратко представить технические характеристики соответствующих моделей этого проекта |
| ⏬model скачать | Адрес загрузки китайской миктральной модели |
| Рассуждения и развертывание | Представляет, как количественно оценить модели и развернуть и испытать большие модели, используя персональный компьютер |
| ? Модельный эффект | Влияние модели на некоторые задачи вводится |
| Обучение и тонкая настройка | Представляем, как тренировать и точно настроить китайскую миктральную модель |
| ❓faq | Ответ на некоторые часто задаваемых вопросов |
Этот проект с открытым исходным кодом китайский микстральный и китайский инстакционный инстакционный инстакционный инстакционный инстакционный
Mixtral - редкая гибридная экспертная модель. Эта модель имеет значительные отличия от предыдущих основных крупномасштабных моделей, таких как лама, что в основном отражается в следующих точках:
Ниже приведена структурная схема в смеси с миктральной бумагой:
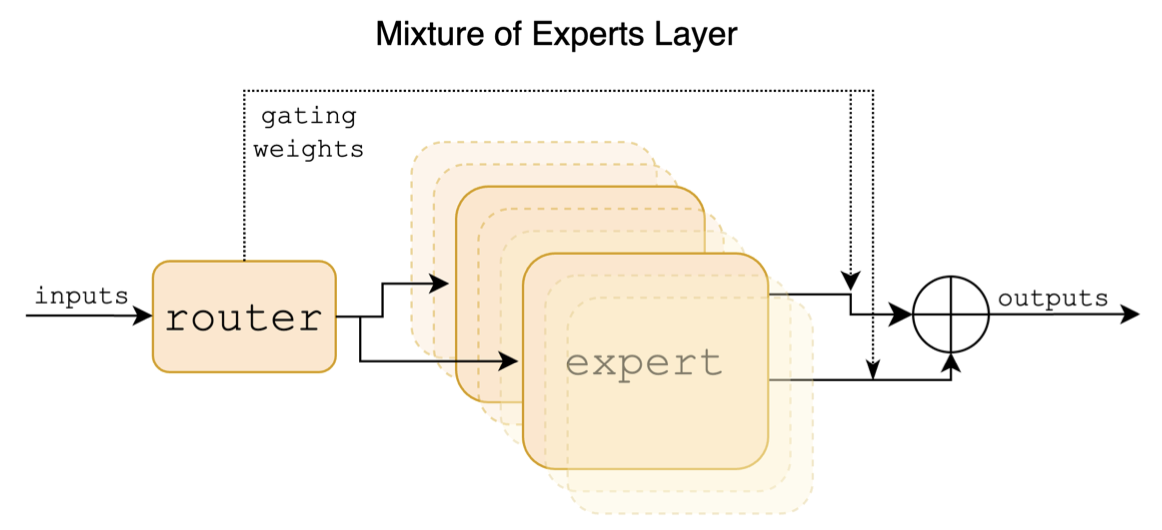
В отличие от проектов Китая-Лама-Альпака и Китая-Лама-Альпака-2, микстральная модель изначально поддерживает контекст 32K (фактическое измерение может достигать 128K). Пользователи могут использовать одну модель для решения различных задач различной длины.
Ниже приводится сравнение модели этого проекта и рекомендуемых сценариев использования. Для взаимодействия в чате выберите версию инструктирования.
| Сравнение пунктов | Китайская миктральная | Китайская миктральная установка |
|---|---|---|
| Тип модели | Базовая модель | Директива/модель чата (класс CHATGPT) |
| Размер модели | 8x7b (фактически активировано около 13b) | 8x7b (фактически активировано около 13b) |
| Количество экспертов | 8 (фактически активировано 2) | 8 (фактически активировано 2) |
| Тип обучения | Причинный-LM (CLM) | Инструкция тонкая корректировка |
| Метод обучения | Qlora + полная сумма Emb/LM-голова | Qlora + полная сумма Emb/LM-голова |
| Какая модель тренировать | Оригинал Mixtral-8x7b-V0.1 | Китайская миктральная |
| Учебные материалы | Оснастенное общее эссе | Замеченные данные инструкции |
| Размер словарного запаса | Оригинальный словарный список, 32000 | Оригинальный словарный список, 32000 |
| Поддерживает длину контекста | 32K (фактически измерено до 128 тыс.) | 32K (фактически измерено до 128 тыс.) |
| Входной шаблон | ненужный | Необходимо применить шаблон с миктральной установкой |
| Применимые сценарии | Продолжение текста: Учитывая приведенный выше текст, пусть модель генерирует следующий текст | Понимание команды: Q & A, написание, чат, взаимодействие и т. Д. |
Вот 3 различных типа моделей:
| Название модели | тип | Спецификация | Полная версия (87 ГБ) | Версия LORA (2,4 ГБ) | GGUF версия |
|---|---|---|---|---|---|
| Китайский микстрал | Базовая модель | 8x7b | [Baidu] [? Hf] [? Modelcope] | [Baidu] [? Hf] [? Modelcope] | [? HF] |
| Китайская миктральная установка | Модель инструкции | 8x7b | [Baidu] [? Hf] [? Modelcope] | [Baidu] [? Hf] [? Modelcope] | [? HF] |
Примечание
Если вы не можете получить доступ к HF, вы можете рассмотреть некоторые зеркальные сайты (например, HF-mirror.com). Пожалуйста, найдите и решите конкретные методы самостоятельно.
Соответствующие модели в этом проекте в основном поддерживают следующие методы квантования, рассуждения и развертывания. Для получения подробной информации, пожалуйста, обратитесь к соответствующему учебному пособию.
| инструмент | Функции | Процессор | Графический процессор | Количественная оценка | Графический интерфейс | API | vllm | Учебник |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | Богатые количественные варианты и эффективные локальные рассуждения | ✅ | ✅ | ✅ | ✅ | [связь] | ||
| ? Трансформеры | Интерфейс вывода нативных трансформаторов | ✅ | ✅ | ✅ | ✅ | ✅ | [связь] | |
| Имитация вызовов API Openai | Демонстрация сервера, которая эмулирует интерфейс API OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | [связь] | |
| Генерация текста-вабуи | Как развернуть интерфейс интерфейса веб-интерфейса интерфейса | ✅ | ✅ | ✅ | ✅ | ✅ | [связь] | |
| Лангхейн | Рамки с открытым исходным кодом для крупномасштабного применения, подходящего для вторичной разработки | ✅ | ✅ | ✅ | [связь] | |||
| Приваттеги | Многодокументированная локальная структура вопросов и ответов | ✅ | ✅ | ✅ | [связь] | |||
| LM Studio | Многоплатформенное программное обеспечение чата (с интерфейсом) | ✅ | ✅ | ✅ | ✅ | ✅ | [связь] |
Чтобы оценить влияние связанных моделей, этот проект провел оценку генеративного эффекта и оценку объективного эффекта (класс NLU) соответственно и оценил большую модель с разных сторон. Рекомендуется, чтобы пользователи проверяли задачи, которые они обеспокоены, и выбирать модели, которые адаптируются к связанным задачам.
C-Eval-это комплексный китайский набор базовой модели, в котором набор проверки и набор тестов содержат вопросы 1,3K и 12,3K с несколькими вариантами выбора, охватывающие 52 субъекта соответственно. Пожалуйста, обратитесь к этому проекту для C-Eval Code: GitHub Wiki
| Модели | тип | Действительно (0-выстрел) | Действительно (5-выстрел) | Тест (0-выстрел) | Тест (5 выстрелов) |
|---|---|---|---|---|---|
| Китайская миктральная установка | инструкция | 51.7 | 55,0 | 50.0 | 51,5 |
| Китайский микстрал | Пьедестал | 45,8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7b-Instruct-V0.1 | инструкция | 51.6 | 54,0 | 48.7 | 50,7 |
| Mixtral-8x7b-v0.1 | Пьедестал | 47.3 | 54,6 | 46.1 | 50.3 |
| Китай-Альпака-2-13B | инструкция | 44.3 | 45,9 | 42,6 | 44,0 |
| Китай-лама-2-13b | Пьедестал | 40.6 | 42,7 | 38.0 | 41.6 |
CMMLU является еще одним комплексным китайским набором данных по оценке, специально используемым для оценки способности знаний и рассуждений языковых моделей в китайском контексте, охватывая 67 тем, от основных субъектов до продвинутого профессионального уровня, в общей сложности 11,5 тыс. Вопросов с несколькими вариантами ответов. Пожалуйста, обратитесь к этому проекту для CMMLU Code: GitHub Wiki
| Модели | тип | Тест (0-выстрел) | Тест (5 выстрелов) |
|---|---|---|---|
| Китайская миктральная установка | инструкция | 50.0 | 53,0 |
| Китайский микстрал | Пьедестал | 42,5 | 51.0 |
| Mixtral-8x7b-Instruct-V0.1 | инструкция | 48.2 | 51.6 |
| Mixtral-8x7b-v0.1 | Пьедестал | 44.3 | 51.6 |
| Китай-Альпака-2-13B | инструкция | 43.2 | 45,5 |
| Китай-лама-2-13b | Пьедестал | 38.9 | 42,5 |
MMLU - это набор данных по оценке английского языка для оценки способности к естественному языку. Это один из основных наборов данных, используемых для оценки больших возможностей модели сегодня. Набор проверки и набор тестов содержат 1,5K и 14,1K вопросов с несколькими вариантами ответов, соответственно, охватывающие 57 субъектов. Пожалуйста, обратитесь к этому проекту для кода вывода MMLU: GitHub Wiki
| Модели | тип | Действительно (0-выстрел) | Действительно (5-выстрел) | Тест (0-выстрел) | Тест (5 выстрелов) |
|---|---|---|---|---|---|
| Китайская миктральная установка | инструкция | 65,1 | 69,6 | 67.5 | 69,8 |
| Китайский микстрал | Пьедестал | 63.2 | 67.1 | 65,5 | 68.3 |
| Mixtral-8x7b-Instruct-V0.1 | инструкция | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-v0.1 | Пьедестал | 64,9 | 69,0 | 67.0 | 69,5 |
| Китай-Альпака-2-13B | инструкция | 49,6 | 53,2 | 50,9 | 53,5 |
| Китай-лама-2-13b | Пьедестал | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench является ориентиром для оценки длинной способности к пониманию текста большой модели. Он состоит из 6 основных категорий и 20 различных задач. Средняя длина большинства задач составляет от 5K-15K и содержит около 4,75K тестовых данных. Ниже приводится эффект оценки этой модели проекта на эту китайскую задачу (включая задачи кода). Пожалуйста, обратитесь к этому проекту для Longbench Code: GitHub Wiki
| Модели | QA единого документа | Многодокумент QA | краткое содержание | FS Learning | Завершение кода | Задача синтеза | средний |
|---|---|---|---|---|---|---|---|
| Китайская миктральная установка | 50.3 | 34.2 | 16.4 | 42,0 | 56.1 | 89,5 | 48.1 |
| Китайский микстрал | 32,0 | 23.7 | 0,4 | 42,5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7b-Instruct-V0.1 | 56.5 | 35,7 | 15.4 | 46.0 | 63,6 | 98.0 | 52,5 |
| Mixtral-8x7b-v0.1 | 35,5 | 9.5 | 16.4 | 46.5 | 57.2 | 83,5 | 41.4 |
| Китай-Альпака-2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21,5 | 29,7 |
| Китай-лама-2-13B-16K | 36.7 | 17.7 | 3.1 | 29,8 | 13.8 | 3.0 | 17.3 |
| Китай-альпака-2-7B-64K | 44,7 | 28.1 | 14.4 | 39,0 | 44,6 | 5.0 | 29.3 |
| Китай-лама-2-7B-64K | 27.2 | 16.4 | 6.5 | 33,0 | 7,8 | 5.0 | 16.0 |
При Llama.cpp была протестирована производительность китайской модели количественной версии, как показано в следующей таблице.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | Iq2_xs | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Размер (ГБ) | 87.0 | 46.2 | 35,7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ппл | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 Max Speed | - | - | 36.0 | 36.9 | 35,7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| Скорость A100 | - | - | 29,9 | 22.6 | 20,5 | 21,7 | 17.1 | 21,7 | 20.6 | 20.3 | 23.7 | 22.5 |
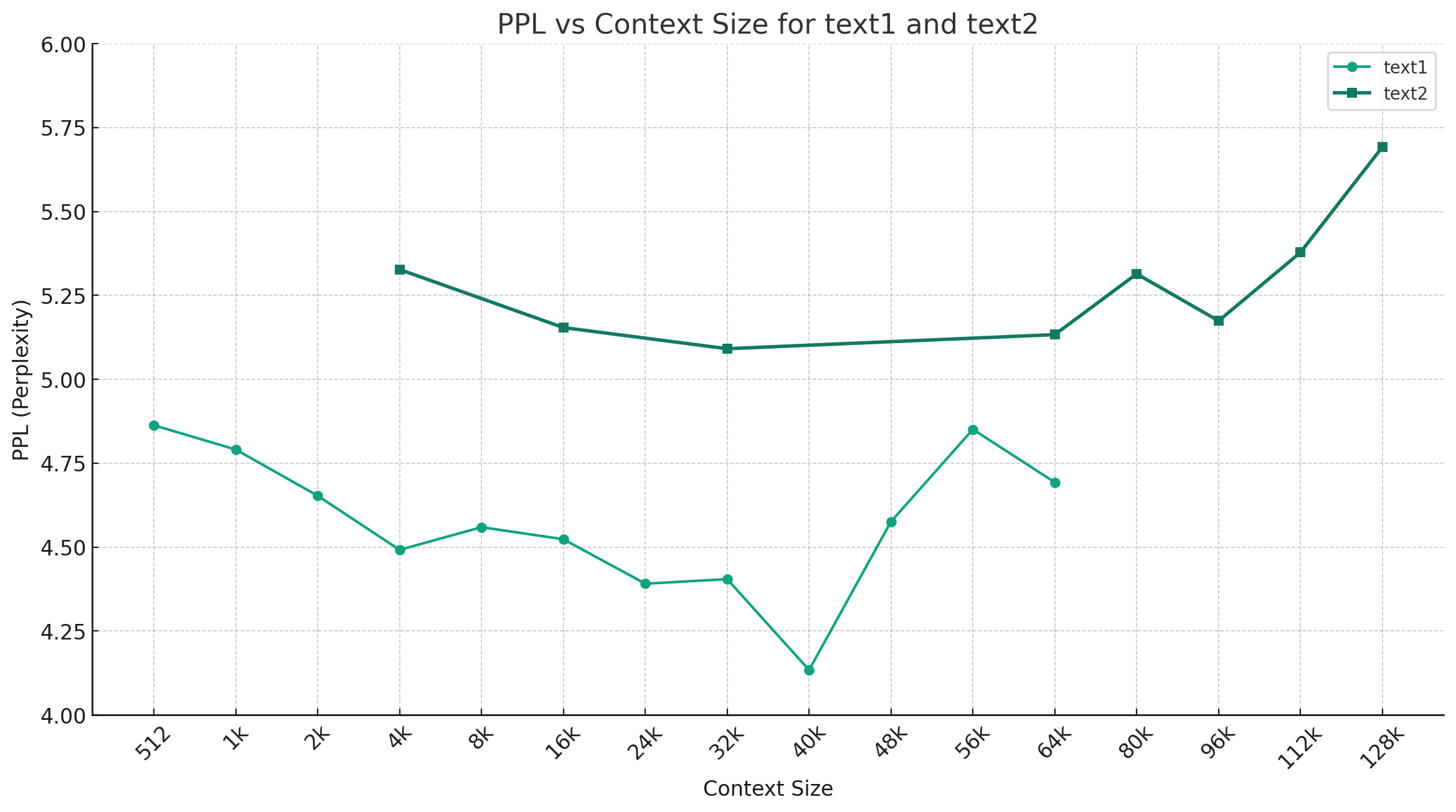
Примечание
В качестве примера приведен китайский Mixtral-Q4_0, на рисунке ниже показана тенденция изменения PPL в разных длинах контекста, и были выбраны два разных набора текстовых данных. Результаты эксперимента показывают, что длина контекста, поддерживаемая миктральной моделью, превысила номинальные 32K, и она все еще имеет хорошую производительность в контексте 64K+ (фактически измерено до 128 тыс.).
Директивный шаблон:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
<s> </s> [INST] [/INST]
Пожалуйста, проверьте, существует ли решение уже в FAQ, прежде чем упомянуть проблему. Для конкретных вопросов и ответов, пожалуйста, обратитесь к этому проекту GitHub Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Этот проект разработан на основе миктральной модели, опубликованной Mistral.ai. Пожалуйста, строго соблюдайте лицензионное соглашение с открытым исходным кодом во время использования. При использовании стороннего кода задействовано, обязательно соблюдайте соответствующее лицензионное соглашение с открытым исходным кодом. Содержание, генерируемое моделью, может влиять на его точность из -за методов расчета, случайных факторов и количественных потерь точности. Следовательно, этот проект не предоставляет никакой гарантии для точности вывода модели, а также не будет нести ответственность за любые убытки, вызванные использованием соответствующих ресурсов и результатов выходных данных. Если соответствующие модели этого проекта используются в коммерческих целях, разработчик должен соблюдать местные законы и правила для обеспечения соответствия выходному содержанию модели. Этот проект не несет ответственности за любые продукты или услуги, полученные от него.
Если у вас есть какие -либо вопросы, пожалуйста, отправьте их в выпуске GitHub. Вежливо задавать вопросы и построить гармоничное дискуссионное сообщество.


