Chinese Mixtral
v1.2
?? 중국어 | 영어 | 문서/문서 | ❓ 질문/문제 | 토론/토론 | Arena/Arena

이 프로젝트는 희소 MOE 아키텍처를 사용하는 Mistral.ai가 발표 한 Mixtral 모델을 기반으로 개발되었습니다. 이 프로젝트는 대규모 중국 레이블 프리 데이터를 사용하여 중국 믹스 트랄 기본 모델을 얻기 위해 중국 증분 훈련을 수행하고, 중국 믹스 트랙 비 스트럭 지침 모델을 얻기 위해 명령 미세 조정을 사용합니다. 이 모델은 기본적으로 긴 텍스트를 효과적으로 처리 할 수있는 32K 컨텍스트 (최대 128k까지 테스트)를 지원하며 동시에 수학적 추론, 코드 생성 등을 상당한 성능 향상을 달성 할 때 정량적 추론에 LLAMA.CPP를 사용할 때 16G 메모리 (또는 비디오 메모리) 만 필요합니다.
기술 보고서 : [Cui and Yao, 2024] LLM 언어 적응을 재고하는 것 : 중국어 혼합에 대한 사례 연구 [논문 해석]
중국 llama-2 & alpaca-2 mockup | 중국 라마 & 알파카 모형 | 멀티 모달 중국어 llama & alpaca mockup | 멀티 모달 vle | 중국 미니 브르트 | 중국어 | 중국 영어 pert | 중국 맥버트 | 중국 전자 | 중국어 xlnet | 중국 버트 | 지식 증류 도구 텍스트 브루어 | 모델 절단 도구 TextPruner | 증류 및 절단 통합 곡물
[2024/04/30] 중국어-롤라마-알파카 -3은 공식적으로 출시되었으며, llama-3을 기반으로 한 오픈 소스 LLAMA-3-CHINESE-8B 및 LLAMA-3-CHINESE-8B-Instruct를 기반으로합니다.
[2024/03/27] GGUF 모델의 1 비트/2 비트/3 비트 정량적 버전 추가 : [? HF]; 동시에이 프로젝트는 Machine Sota의 중심부에 배치되었습니다! 모델 플랫폼, 오신 것을 환영합니다 : https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Mimic OpenAI API 배포 모드를 추가하십시오. 세부 사항보기 : v1.2 버전 릴리스 로그
[2024/03/05] 오픈 소스 모델 교육 및 미세 조정 코드, 기술 보고서를 게시하십시오. 세부 사항보기 : v1.1 버전 릴리스 로그
[2024/01/29]는 공식적으로 중국-믹스 트랄 (기본 모델)과 중국-믹스 트랄-무역 (명령/채팅 모델)을 발표했다. 세부 사항보기 : v1.0 버전 릴리스 로그
| 장 | 설명하다 |
|---|---|
| ? | 이 프로젝트의 관련 모델의 기술적 특성을 간략하게 소개합니다. |
| model 다운로드 | 중국 믹스 트랄 모델 다운로드 주소 |
| 추론 및 배치 | 개인 컴퓨터를 사용하여 모델을 정량화하고 대형 모델을 배포하고 경험하는 방법을 소개합니다. |
| ? 모델 효과 | 일부 작업에 대한 모델의 효과가 소개됩니다. |
| 훈련 및 미세 조정 | 중국 믹스 트랄 모델을 훈련하고 미세 조정하는 방법 소개 |
| faq | 일부 FAQ에 답장합니다 |
이 프로젝트 오픈 소스 중국어 믹스 트랄 및 중국 믹스 트랄 강조 모델은 Mixtral 모델을 기반으로 개발되었으며 주요 기능은 다음과 같습니다.
Mixtral은 희소 하이브리드 전문가 모델입니다. 이 모델은 LLAMA와 같은 이전의 주류 대규모 모델과 유의 한 차이가 있으며, 이는 주로 다음 지점에 반영됩니다.
다음은 Mixtral 용지의 구조 다이어그램입니다.
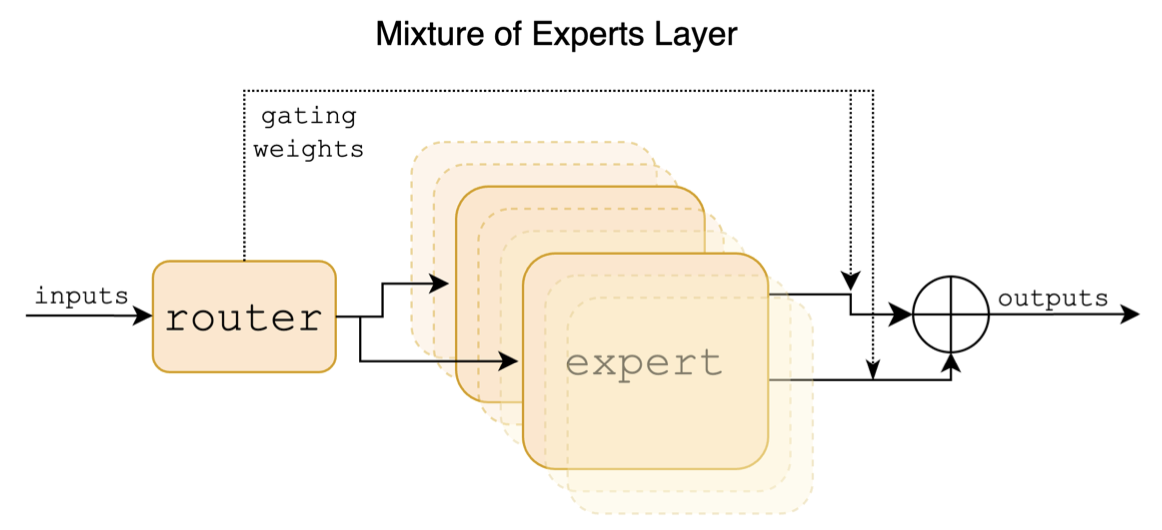
중국-알라 마-알파카 및 중국-줄라카카 -2 프로젝트와 달리 Mixtral 모델은 기본적으로 32k 컨텍스트를 지원합니다 (실제 측정은 128k에 도달 할 수 있음). 사용자는 단일 모델을 사용하여 다양한 길이의 다양한 작업을 해결할 수 있습니다.
다음은이 프로젝트의 모델과 권장 사용 시나리오를 비교 한 것입니다. 채팅 상호 작용을 위해서는 명령어 버전을 선택하십시오.
| 비교 항목 | 중국어 믹스 트랄 | 중국어 믹스 트랄 스트럭 |
|---|---|---|
| 모델 유형 | 기본 모델 | 지시/채팅 모델 (클래스 chatgpt) |
| 모델 크기 | 8x7b (실제로 약 13b) | 8x7b (실제로 약 13b) |
| 전문가 수 | 8 (실제로 활성화 된 2) | 8 (실제로 활성화 된 2) |
| 훈련 유형 | 인과 LM (CLM) | 지시 미세 조정 |
| 훈련 방법 | Qlora + 전체 양 EMB/LM 헤드 | Qlora + 전체 양 EMB/LM 헤드 |
| 훈련 할 모델 | 원래 mixtral-8x7b-v0.1 | 중국어 믹스 트랄 |
| 교육 자료 | 표시되지 않은 일반 에세이 | 라벨이 붙은 명령 데이터 |
| 어휘 크기 | 원래 어휘 목록, 32000 | 원래 어휘 목록, 32000 |
| 컨텍스트 길이를 지원합니다 | 32k (실제로 128k까지 측정) | 32k (실제로 128k까지 측정) |
| 입력 템플릿 | 불필요한 | Mixtral-Instruct 템플릿을 적용해야합니다 |
| 해당 시나리오 | 텍스트 연속 : 위의 텍스트가 주어지면 모델이 다음 텍스트를 생성하도록합니다. | 명령 이해 : Q & A, 쓰기, 채팅, 상호 작용 등 |
다음은 3 가지 유형의 모델입니다.
| 모델 이름 | 유형 | 사양 | 정식 버전 (87GB) | 로라 버전 (2.4GB) | GGUF 버전 |
|---|---|---|---|---|---|
| 중국-믹스 트랄 | 기본 모델 | 8x7b | [바이두] [? HF] [? modelscope] | [바이두] [? HF] [? modelscope] | [? HF] |
| 중국-믹스 트랄-비 구조 | 교육 모델 | 8x7b | [바이두] [? HF] [? modelscope] | [바이두] [? HF] [? modelscope] | [? HF] |
메모
HF에 액세스 할 수없는 경우 일부 미러 사이트 (예 : hf-mirror.com)를 고려할 수 있습니다. 특정 방법을 직접 찾아서 해결하십시오.
이 프로젝트의 관련 모델은 주로 다음 양자화, 추론 및 배포 방법을 지원합니다. 자세한 내용은 해당 자습서를 참조하십시오.
| 도구 | 특징 | CPU | GPU | 부량 | 구이 | API | vllm | 지도 시간 |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | 풍부한 양적 옵션과 효율적인 지역 추론 | ✅ | ✅ | ✅ | ✅ | [링크] | ||
| ? 변압기 | 기본 변압기 추론 인터페이스 | ✅ | ✅ | ✅ | ✅ | ✅ | [링크] | |
| OpenAI API 호출의 모방 | OpenAI API 인터페이스를 에뮬레이션하는 서버 데모 | ✅ | ✅ | ✅ | ✅ | ✅ | [링크] | |
| 텍스트-세대-부이 | 프론트 엔드 웹 UI 인터페이스를 배포하는 방법 | ✅ | ✅ | ✅ | ✅ | ✅ | [링크] | |
| 랭케인 | 2 차 개발에 적합한 대규모 응용 프로그램을위한 오픈 소스 프레임 워크 | ✅ | ✅ | ✅ | [링크] | |||
| PrivateGpt | 멀티 문서 로컬 질문 및 답변 프레임 워크 | ✅ | ✅ | ✅ | [링크] | |||
| LM 스튜디오 | 멀티 플랫폼 채팅 소프트웨어 (인터페이스 포함) | ✅ | ✅ | ✅ | ✅ | ✅ | [링크] |
관련 모델의 효과를 평가하기 위해이 프로젝트는 각각 생성 효과 평가 및 객관적인 효과 평가 (NLU 클래스)를 수행하고 다른 각도에서 큰 모델을 평가했습니다. 사용자는 관련 작업에 대해 관심있는 작업을 테스트하고 관련 작업에 적응하는 모델을 선택하는 것이 좋습니다.
C-Eval은 포괄적 인 중국 기본 모델 평가 제품군으로, 검증 세트와 테스트 세트에는 각각 52 명의 피험자를 다루는 1.3K 및 12.3K 객관식 질문이 포함되어 있습니다. C-Eval 추론 코드는이 프로젝트를 참조하십시오 : Github Wiki
| 모델 | 유형 | 유효한 (0- 샷) | 유효한 (5- 샷) | 테스트 (0- 샷) | 테스트 (5- 샷) |
|---|---|---|---|---|---|
| 중국-믹스 트랄-비 구조 | 지침 | 51.7 | 55.0 | 50.0 | 51.5 |
| 중국-믹스 트랄 | 받침대 | 45.8 | 54.2 | 43.1 | 49.1 |
| mixtral-8x7b- 비 스트럭 -V0.1 | 지침 | 51.6 | 54.0 | 48.7 | 50.7 |
| 믹스 트랄 -8x7b-v0.1 | 받침대 | 47.3 | 54.6 | 46.1 | 50.3 |
| 중국-알파카 -2-13B | 지침 | 44.3 | 45.9 | 42.6 | 44.0 |
| 중국-줄라기 -2-13B | 받침대 | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU는 또 다른 포괄적 인 중국 평가 데이터 세트이며, 특히 중국 맥락에서 언어 모델의 지식과 추론 능력을 평가하는 데 사용되며, 기본 주제에서 고급 전문가 수준에 이르기까지 총 11.5k 객관식 문제가 있습니다. CMMLU 추론 코드는이 프로젝트를 참조하십시오 : Github Wiki
| 모델 | 유형 | 테스트 (0- 샷) | 테스트 (5- 샷) |
|---|---|---|---|
| 중국-믹스 트랄-비 구조 | 지침 | 50.0 | 53.0 |
| 중국-믹스 트랄 | 받침대 | 42.5 | 51.0 |
| mixtral-8x7b- 비 스트럭 -V0.1 | 지침 | 48.2 | 51.6 |
| 믹스 트랄 -8x7b-v0.1 | 받침대 | 44.3 | 51.6 |
| 중국-알파카 -2-13B | 지침 | 43.2 | 45.5 |
| 중국-줄라기 -2-13B | 받침대 | 38.9 | 42.5 |
MMLU는 자연 언어 이해 능력을 평가하기위한 영어 평가 데이터 세트입니다. 오늘날 대형 모델 기능을 평가하는 데 사용되는 주요 데이터 세트 중 하나입니다. 검증 세트 및 테스트 세트에는 각각 57 명의 피험자를 다루는 1.5K 및 14.1K 객관식 질문이 포함됩니다. MMLU 추론 코드는이 프로젝트를 참조하십시오 : Github Wiki
| 모델 | 유형 | 유효한 (0- 샷) | 유효한 (5- 샷) | 테스트 (0- 샷) | 테스트 (5- 샷) |
|---|---|---|---|---|---|
| 중국-믹스 트랄-비 구조 | 지침 | 65.1 | 69.6 | 67.5 | 69.8 |
| 중국-믹스 트랄 | 받침대 | 63.2 | 67.1 | 65.5 | 68.3 |
| mixtral-8x7b- 비 스트럭 -V0.1 | 지침 | 68.5 | 70.4 | 68.2 | 70.2 |
| 믹스 트랄 -8x7b-v0.1 | 받침대 | 64.9 | 69.0 | 67.0 | 69.5 |
| 중국-알파카 -2-13B | 지침 | 49.6 | 53.2 | 50.9 | 53.5 |
| 중국-줄라기 -2-13B | 받침대 | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench는 큰 모델의 긴 텍스트 이해력을 평가하기위한 벤치 마크입니다. 6 개의 주요 범주와 20 개의 다른 작업으로 구성됩니다. 대부분의 작업의 평균 길이는 5K-15K이며 약 4.75K 테스트 데이터를 포함합니다. 다음은이 중국 작업 (코드 작업 포함)에 대한이 프로젝트 모델의 평가 효과입니다. Longbench 추론 코드는이 프로젝트를 참조하십시오 : Github Wiki
| 모델 | 단일 문서 QA | 다중 문서 QA | 요약 | FS 학습 | 코드 완료 | 합성 작업 | 평균 |
|---|---|---|---|---|---|---|---|
| 중국-믹스 트랄-비 구조 | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| 중국-믹스 트랄 | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| mixtral-8x7b- 비 스트럭 -V0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| 믹스 트랄 -8x7b-v0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| 중국-알파카 -2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| 중국-줄라기 -2-13B-16K | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| 중국-알파카 -2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| 중국-줄라기 -2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
llama.cpp에서는 다음 표에서 볼 수 있듯이 중국-믹스 트랄 정량적 버전 모델의 성능을 테스트했습니다.
| F16 | Q8_0 | Q6_K | Q5_K | Q5_0 | Q4_K | Q4_0 | Q3_K | IQ3_XXS | Q2_K | IQ2_XS | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 크기 (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 최대 속도 | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| A100 속도 | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
메모
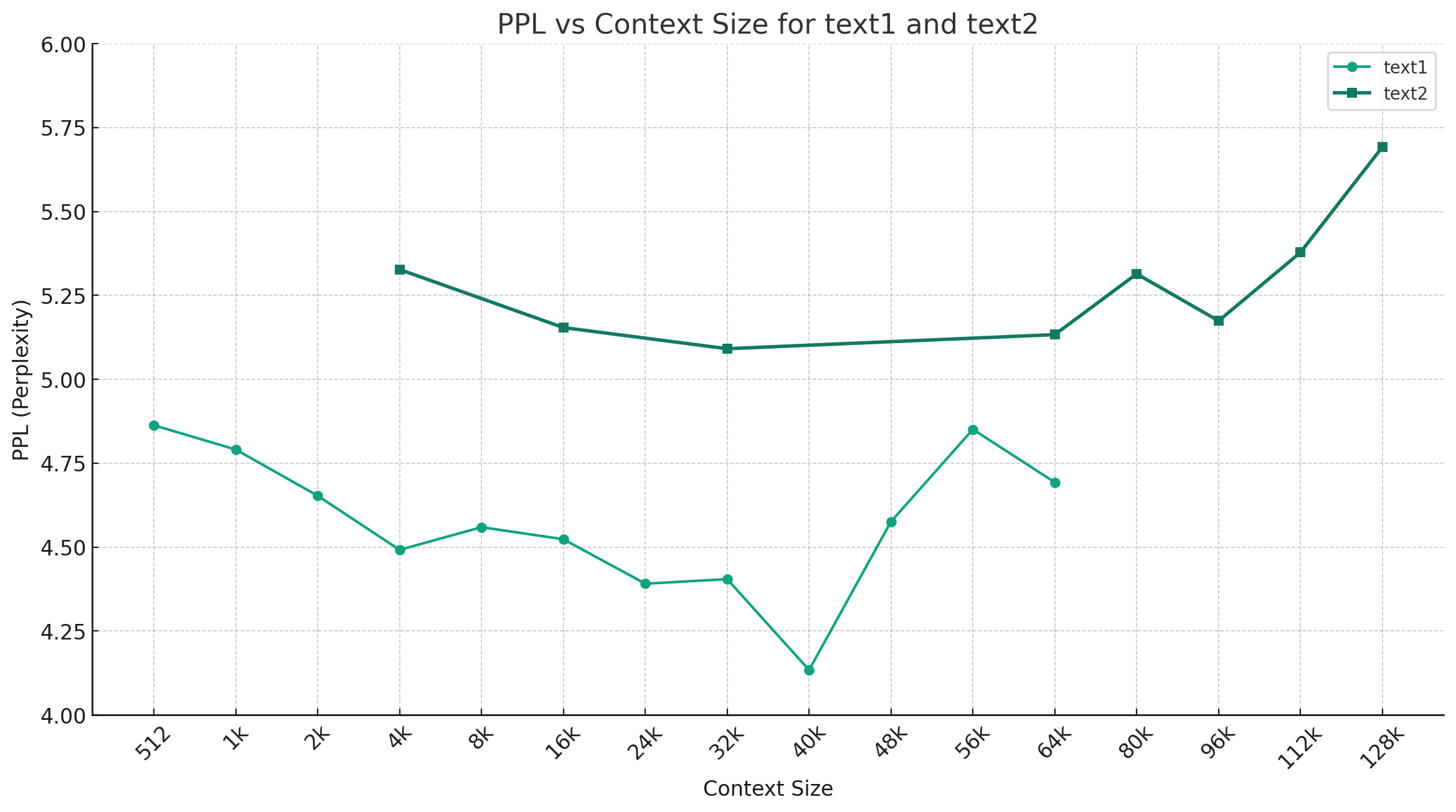
중국-믹스 트랄 -Q4_0을 예로 들어 보면 아래 그림은 다른 컨텍스트 길이의 PPL 변화 추세를 보여주고 두 가지 다른 일반 텍스트 데이터 세트가 선택되었습니다. 실험 결과는 Mixtral 모델에 의해 지원되는 컨텍스트 길이가 공칭 32K를 초과했으며 여전히 64K+ 컨텍스트 (실제로 128K까지 측정)에서 여전히 우수한 성능을 가지고 있음을 보여줍니다.
지침 템플릿 :
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
참고 : <s> 및 </s> 는 시퀀스의 시작과 끝을 나타내는 특수 토큰이며 [INST] 및 [/INST] 는 일반적인 문자열입니다.
문제를 언급하기 전에 솔루션이 FAQ에 이미 존재하는지 확인하십시오. 구체적인 질문과 답변은이 프로젝트 Github Wiki를 참조하십시오.
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}이 프로젝트는 Mistral.ai가 게시 한 Mixtral 모델을 기반으로 개발되었습니다. 사용 중에 Mixtral 오픈 소스 라이센스 계약을 엄격히 준수하십시오. 타사 코드를 사용하는 경우 관련 오픈 소스 라이센스 계약을 준수하십시오. 모델에 의해 생성 된 내용은 계산 방법, 임의 요인 및 정량적 정확도 손실로 인해 정확도에 영향을 줄 수 있습니다. 따라서이 프로젝트는 모델 출력의 정확성에 대한 보장을 제공하지 않으며 관련 리소스 및 출력 결과로 인한 손실에 대해 책임을지지 않습니다. 이 프로젝트의 관련 모델이 상업적 목적으로 사용되는 경우, 개발자는 모델의 출력 내용을 준수하기 위해 현지 법률 및 규정을 준수해야합니다. 이 프로젝트는 그로부터 파생 된 제품이나 서비스에 대해 책임을지지 않습니다.
궁금한 점이 있으면 GitHub 문제로 제출하십시오. 정중하게 질문하고 조화로운 토론 커뮤니티를 구축하십시오.


