Chinese Mixtral
v1.2
?? Cina | Bahasa Inggris | Dokumen/dokumen | ❓ Pertanyaan/Masalah | Diskusi/Diskusi | ⚔️ Arena/arena

Proyek ini dikembangkan berdasarkan model mixtral yang dirilis oleh Mistral.ai, yang menggunakan arsitektur MOE yang jarang. Proyek ini menggunakan data bebas label China skala besar untuk melakukan pelatihan tambahan Cina untuk mendapatkan model dasar mixtral Cina , dan lebih lanjut menggunakan instruksi penyesuaian halus untuk mendapatkan model instruksi mixtral-instruct China . Model ini secara asli mendukung konteks 32K (diuji hingga 128k) , yang secara efektif dapat memproses teks panjang, dan pada saat yang sama mencapai peningkatan kinerja yang signifikan dalam penalaran matematika, pembuatan kode, dll. Saat menggunakan llama.cpp untuk penalaran kuantitatif, hanya mengambil memori 16G (atau memori video).
Laporan Teknis : [Cui dan Yao, 2024] Memikirkan kembali adaptasi bahasa LLM: Studi kasus tentang mixtral Cina [interpretasi kertas]
Chinese Llama-2 & Alpaca-2 Mockup | Chinese Llama & Alpaca Mockup | Multimodal Chinese Llama & Alpaca Mockup | Multimodal Vle | Minirbt Cina | Lert Cina | Bahasa Inggris Tiongkok PERT | Macbert Cina | China Electra | Xlnet Cina | Bert Cina | Alat Distilasi Pengetahuan TextBrewer | Model Cutting Tool TextPruner | Distilasi dan memotong biji -bijian integrasi
[2024/04/30] China-llama-alpaca-3 telah dirilis secara resmi, open source llama-3-chinese-8b dan llama-3-chinese-8b-instruct Berdasarkan llama-3, silakan merujuk ke: https://github.com/ymcui/chinese-lama-alpacac:/github.com
[2024/03/27] Tambahkan versi kuantitatif 1-bit/2-bit/3-bit dari model GGUF: [? HF]; Pada saat yang sama, proyek ini telah dikerahkan di jantung mesin Sota! Platform Model, Selamat datang untuk mengikuti: https://sota.jiqizhixin.com/project/chinese-mixtral
[2024/03/26] Tambahkan mode penyebaran MIMIC OpenAI API. Lihat Detail: V1.2 Versi Rilis Log
[2024/03/05] Pelatihan model open source dan kode penyempurnaan, menerbitkan laporan teknis. Lihat Detail: V1.1 Versi Rilis Log
[2024/01/29] secara resmi merilis China-Mixtral (model dasar) dan China-Mixtral-Instruk (Model Instruksi/Obrolan). Lihat Detail: V1.0 Versi Rilis Log
| bab | menggambarkan |
|---|---|
| ?? ♂️ PENDAHULUAN Podel | Perkenalkan secara singkat karakteristik teknis dari model yang relevan dari proyek ini |
| ⏬ Unduh Model | Alamat Unduh Model Mixtral Cina |
| Penalaran dan penempatan | Memperkenalkan cara mengukur model dan menggunakan dan mengalami model besar menggunakan komputer pribadi |
| ? Efek model | Efek model pada beberapa tugas diperkenalkan |
| Pelatihan dan Saring Tune | Memperkenalkan cara melatih dan menyempurnakan model mixtral Cina |
| ❓FAQ | Membalas beberapa faq |
Proyek ini Open Source Chinese Mixtral dan Model Mixtral-Instruct China yang dikembangkan berdasarkan model mixtral, dan fitur utamanya adalah sebagai berikut:
Mixtral adalah model ahli hibrida yang jarang. Model ini memiliki perbedaan yang signifikan dari model skala besar utama sebelumnya seperti LLAMA, yang terutama tercermin dalam poin-poin berikut:
Berikut ini adalah diagram struktural di kertas mixtral:
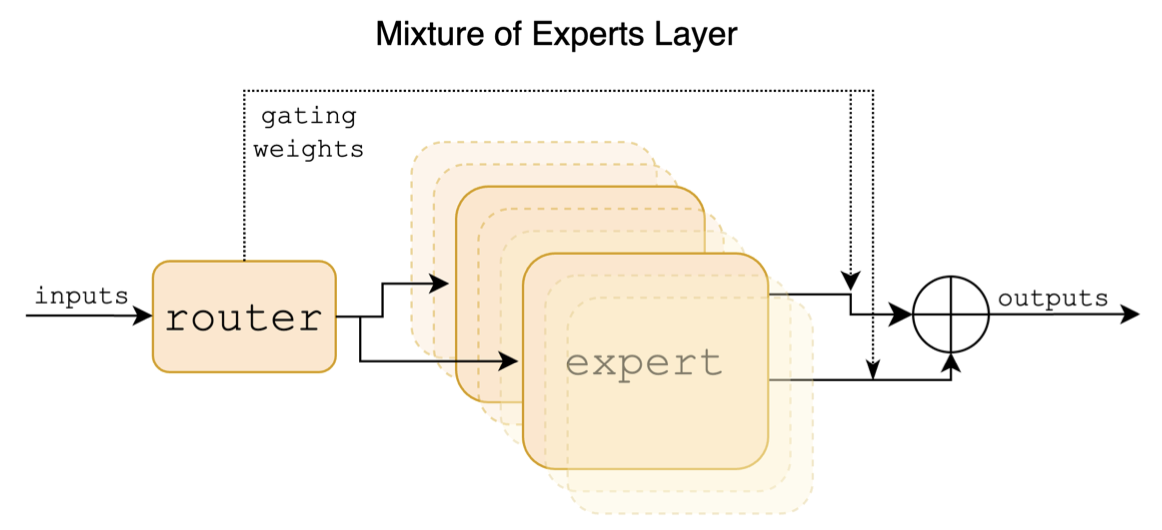
Berbeda dengan proyek Cina-Llama-Alpaca dan Cina-Llama-Alpaca-2, model mixtral secara asli mendukung konteks 32K (pengukuran aktual dapat mencapai 128k). Pengguna dapat menggunakan model tunggal untuk menyelesaikan berbagai tugas dengan panjang yang berbeda.
Berikut ini adalah perbandingan model proyek ini dan skenario penggunaan yang direkomendasikan. Untuk interaksi obrolan, pilih Versi Instruksi.
| Item perbandingan | Mixtral Cina | Mixtral-instruct China |
|---|---|---|
| Tipe model | Model dasar | Model Directive/Chat (kelas chatgpt) |
| Ukuran model | 8x7b (sebenarnya diaktifkan sekitar 13b) | 8x7b (sebenarnya diaktifkan sekitar 13b) |
| Jumlah ahli | 8 (sebenarnya diaktifkan 2) | 8 (sebenarnya diaktifkan 2) |
| Jenis pelatihan | Causal-LM (CLM) | Instruksi Penyesuaian Baik |
| Metode pelatihan | Qlora + jumlah penuh emb/lm-head | Qlora + jumlah penuh emb/lm-head |
| Model apa yang harus dilatih | Mixtral-8x7b-V0.1 asli | Mixtral Cina |
| Materi pelatihan | Esai umum yang tidak ditandai | Data instruksi berlabel |
| Ukuran kosa kata | Daftar Kosakata Asli, 32000 | Daftar Kosakata Asli, 32000 |
| Mendukung panjang konteks | 32k (sebenarnya diukur hingga 128k) | 32k (sebenarnya diukur hingga 128k) |
| Input Template | tidak perlu | Perlu menerapkan template mixtral-instruct |
| Skenario yang berlaku | Lanjutan Teks: Diberikan teks di atas, biarkan model menghasilkan teks berikut | Pemahaman Perintah: Tanya Jawab, Menulis, Obrolan, Interaksi, dll. |
Berikut adalah 3 jenis model:
| Nama model | jenis | Spesifikasi | Versi Lengkap (87 GB) | Versi Lora (2,4 GB) | Versi GGUF |
|---|---|---|---|---|---|
| Mixtral Cina | Model dasar | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
| China-mixtral-instruct | Model instruksi | 8x7b | [Baidu] [? Hf] [? Modelscope] | [Baidu] [? Hf] [? Modelscope] | [? Hf] |
Catatan
Jika Anda tidak dapat mengakses HF, Anda dapat mempertimbangkan beberapa situs cermin (seperti HF-mirror.com). Silakan temukan dan selesaikan metode spesifik sendiri.
Model yang relevan dalam proyek ini terutama mendukung metode kuantisasi, penalaran, dan penyebaran berikut. Untuk detailnya, silakan merujuk ke tutorial yang sesuai.
| alat | Fitur | CPU | GPU | Hitungan | GUI | API | vllm | Tutorial |
|---|---|---|---|---|---|---|---|---|
| llama.cpp | Opsi kuantitatif yang kaya dan penalaran lokal yang efisien | ✅ | ✅ | ✅ | ✅ | [link] | ||
| ? Transformers | Antarmuka Inferensi Transformer Asli | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Imitasi Panggilan API Openai | Demo server yang meniru antarmuka API openai | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Text-generation-webui | Cara Menyebarkan Antarmuka UI Web Front-End | ✅ | ✅ | ✅ | ✅ | ✅ | [link] | |
| Langchain | Kerangka kerja open source untuk aplikasi skala besar yang cocok untuk pengembangan sekunder | ✅ | ✅ | ✅ | [link] | |||
| Privategpt | Kerangka kerja tanya jawab lokal multi-dokumen | ✅ | ✅ | ✅ | [link] | |||
| LM Studio | Perangkat lunak obrolan multi-platform (dengan antarmuka) | ✅ | ✅ | ✅ | ✅ | ✅ | [link] |
Untuk mengevaluasi efek dari model terkait, proyek ini melakukan evaluasi efek generatif dan evaluasi efek objektif (kelas NLU) masing -masing, dan mengevaluasi model besar dari sudut yang berbeda. Disarankan agar pengguna menguji tugas yang mereka khawatirkan dan pilih model yang beradaptasi dengan tugas terkait.
C-Eval adalah rangkaian evaluasi model dasar Tiongkok yang komprehensif, di mana set verifikasi dan set tes berisi pertanyaan pilihan ganda 1.3K dan 12.3K, masing-masing mencakup 52 subjek. Silakan merujuk pada proyek ini untuk kode inferensi C-eval: Github Wiki
| Model | jenis | Valid (0-shot) | Valid (5-shot) | Tes (0-shot) | Tes (5-shot) |
|---|---|---|---|---|---|
| China-mixtral-instruct | petunjuk | 51.7 | 55.0 | 50.0 | 51.5 |
| Mixtral Cina | Alas | 45.8 | 54.2 | 43.1 | 49.1 |
| Mixtral-8x7b-instruct-V0.1 | petunjuk | 51.6 | 54.0 | 48.7 | 50.7 |
| Mixtral-8x7b-V0.1 | Alas | 47.3 | 54.6 | 46.1 | 50.3 |
| China-Alpaca-2-13b | petunjuk | 44.3 | 45.9 | 42.6 | 44.0 |
| China-llama-2-13b | Alas | 40.6 | 42.7 | 38.0 | 41.6 |
CMMLU adalah dataset evaluasi Cina komprehensif lainnya, secara khusus digunakan untuk mengevaluasi pengetahuan dan kemampuan penalaran model bahasa dalam konteks Cina, mencakup 67 topik dari subjek dasar hingga tingkat profesional tingkat lanjut, dengan total pertanyaan pilihan ganda 11,5k. Silakan merujuk pada proyek ini untuk kode inferensi CMMLU: Github Wiki
| Model | jenis | Tes (0-shot) | Tes (5-shot) |
|---|---|---|---|
| China-mixtral-instruct | petunjuk | 50.0 | 53.0 |
| Mixtral Cina | Alas | 42.5 | 51.0 |
| Mixtral-8x7b-instruct-V0.1 | petunjuk | 48.2 | 51.6 |
| Mixtral-8x7b-V0.1 | Alas | 44.3 | 51.6 |
| China-Alpaca-2-13b | petunjuk | 43.2 | 45.5 |
| China-llama-2-13b | Alas | 38.9 | 42.5 |
MMLU adalah dataset evaluasi bahasa Inggris untuk mengevaluasi kemampuan pemahaman bahasa alami. Ini adalah salah satu dataset utama yang digunakan untuk mengevaluasi kemampuan model besar saat ini. Set verifikasi dan set tes masing-masing berisi pertanyaan pilihan ganda 1.5k dan 14.1k, yang mencakup 57 subjek. Silakan merujuk pada proyek ini untuk Kode Inferensi MMLU: Github Wiki
| Model | jenis | Valid (0-shot) | Valid (5-shot) | Tes (0-shot) | Tes (5-shot) |
|---|---|---|---|---|---|
| China-mixtral-instruct | petunjuk | 65.1 | 69.6 | 67.5 | 69.8 |
| Mixtral Cina | Alas | 63.2 | 67.1 | 65.5 | 68.3 |
| Mixtral-8x7b-instruct-V0.1 | petunjuk | 68.5 | 70.4 | 68.2 | 70.2 |
| Mixtral-8x7b-V0.1 | Alas | 64.9 | 69.0 | 67.0 | 69.5 |
| China-Alpaca-2-13b | petunjuk | 49.6 | 53.2 | 50.9 | 53.5 |
| China-llama-2-13b | Alas | 46.8 | 50.0 | 46.6 | 51.8 |
Longbench adalah tolok ukur untuk mengevaluasi kemampuan pemahaman teks panjang dari model besar. Ini terdiri dari 6 kategori utama dan 20 tugas berbeda. Panjang rata-rata sebagian besar tugas adalah antara 5k-15k, dan berisi sekitar 4,75K data uji. Berikut ini adalah efek evaluasi dari model proyek ini pada tugas Cina ini (termasuk tugas kode). Silakan merujuk pada proyek ini untuk Kode Inferensi Longbench: Github Wiki
| Model | Dokumen tunggal QA | QA multi-dokumen | ringkasan | Pembelajaran FS | Penyelesaian kode | Tugas sintesis | rata-rata |
|---|---|---|---|---|---|---|---|
| China-mixtral-instruct | 50.3 | 34.2 | 16.4 | 42.0 | 56.1 | 89.5 | 48.1 |
| Mixtral Cina | 32.0 | 23.7 | 0.4 | 42.5 | 27.4 | 14.0 | 23.3 |
| Mixtral-8x7b-instruct-V0.1 | 56.5 | 35.7 | 15.4 | 46.0 | 63.6 | 98.0 | 52.5 |
| Mixtral-8x7b-V0.1 | 35.5 | 9.5 | 16.4 | 46.5 | 57.2 | 83.5 | 41.4 |
| China-Alpaca-2-13b-16k | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| China-llama-2-13b-16k | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| China-Alpaca-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| China-Llama-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
Di bawah llama.cpp, kinerja model versi kuantitatif mixtral Cina diuji, seperti yang ditunjukkan pada tabel berikut.
| F16 | Q8_0 | Q6_k | Q5_k | Q5_0 | Q4_k | Q4_0 | Q3_K | IQ3_XXS | Q2_k | IQ2_XS | IQ2_XXS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ukuran (GB) | 87.0 | 46.2 | 35.7 | 30.0 | 30.0 | 24.6 | 24.6 | 19.0 | 17.1 | 16.1 | 12.7 | 11.4 |
| BPW | 16.0 | 8.50 | 6.57 | 5.69 | 5.52 | 4.87 | 4.53 | 3.86 | 3.14 | 2.96 | 2.34 | 2.10 |
| Ppl | - | 4.4076 | 4.4092 | 4.4192 | 4.4224 | 4.4488 | 4.4917 | 4.5545 | 4.5990 | 5.1846 | 6.9784 | 8.5981 |
| M3 Max Speed | - | - | 36.0 | 36.9 | 35.7 | 31.2 | 27.8 | 37.6 | - | 29.1 | - | - |
| Kecepatan A100 | - | - | 29.9 | 22.6 | 20.5 | 21.7 | 17.1 | 21.7 | 20.6 | 20.3 | 23.7 | 22.5 |
Catatan
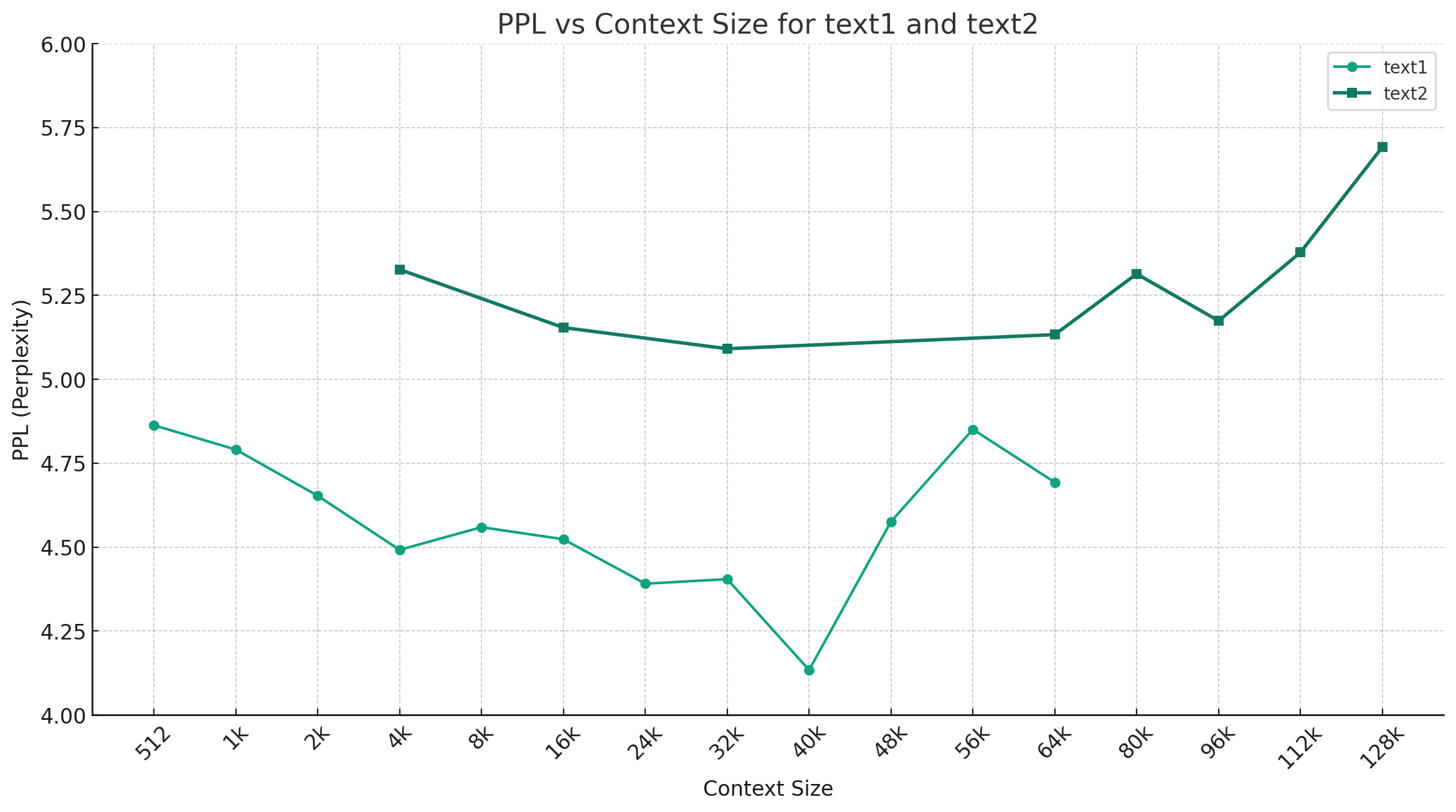
Mengambil Chinese-Mixtral-Q4_0 sebagai contoh, gambar di bawah ini menunjukkan tren perubahan ppl di bawah panjang konteks yang berbeda, dan dua set data teks biasa yang berbeda dipilih. Hasil eksperimen menunjukkan bahwa panjang konteks yang didukung oleh model mixtral telah melampaui nominal 32K, dan masih memiliki kinerja yang baik di bawah konteks 64K+ (sebenarnya diukur hingga 128K).
Template Arahan:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Catatan: <s> dan </s> adalah token khusus yang mewakili awal dan akhir dari suatu urutan, sedangkan [INST] dan [/INST] adalah string biasa.
Silakan periksa apakah solusi sudah ada di FAQ sebelum Anda menyebutkan masalah ini. Untuk pertanyaan dan jawaban tertentu, silakan merujuk pada proyek ini Github Wiki
问题1:后续会不会用更多数据进行训练?会不会做RLHF/DPO对齐?
问题2:为什么本次的模型没有做中文词表扩展?
问题3:是否支持Mixtral的下游生态?
@article{chinese-mixtral,
title={Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral},
author={Cui, Yiming and Yao, Xin},
journal={arXiv preprint arXiv:2403.01851},
url={https://arxiv.org/abs/2403.01851},
year={2024}
}Proyek ini dikembangkan berdasarkan model mixtral yang diterbitkan oleh Mistral.ai. Harap patuhi dengan ketat dengan perjanjian lisensi open source Mixtral selama penggunaan. Jika menggunakan kode pihak ketiga terlibat, pastikan untuk mematuhi perjanjian lisensi open source yang relevan. Konten yang dihasilkan oleh model dapat mempengaruhi keakuratannya karena metode perhitungan, faktor acak, dan kerugian akurasi kuantitatif. Oleh karena itu, proyek ini tidak memberikan jaminan untuk keakuratan output model, juga tidak akan bertanggung jawab atas kerugian yang disebabkan oleh penggunaan sumber daya yang relevan dan hasil output. Jika model yang relevan dari proyek ini digunakan untuk tujuan komersial, pengembang harus mematuhi hukum dan peraturan setempat untuk memastikan kepatuhan dengan konten output model. Proyek ini tidak akan bertanggung jawab atas produk atau layanan apa pun yang diperoleh darinya.
Jika Anda memiliki pertanyaan, silakan kirimkan dalam masalah GitHub. Ajukan pertanyaan dengan sopan dan bangun komunitas diskusi yang harmonis.


