Chinese LLaMA Alpaca
v5.0
?? จีน | ภาษาอังกฤษ | เอกสาร/เอกสาร | ❓คำถาม/ปัญหา | การอภิปราย/การอภิปราย | ⚔ Arena/Arena

โครงการนี้โอเพ่นซอร์ส รูปแบบ Llama จีนและโมเดล Alpaca ที่ปรับแต่ง เพื่อส่งเสริมการวิจัยแบบเปิดของโมเดลขนาดใหญ่ในชุมชน NLP จีน โมเดลเหล่านี้ ได้ขยายรายการคำศัพท์ภาษาจีนตาม Llama ดั้งเดิม และใช้ข้อมูลภาษาจีนสำหรับการฝึกอบรมก่อนการฝึกอบรมระดับมัธยมศึกษาเพื่อปรับปรุงความสามารถในการทำความเข้าใจความหมายขั้นพื้นฐานของจีน ในเวลาเดียวกันโมเดล Alpaca จีนจะใช้ข้อมูลการเรียนการสอนภาษาจีนเพิ่มเติมเพื่อการปรับที่ดีซึ่งช่วยปรับปรุงความเข้าใจและความสามารถในการดำเนินการของแบบจำลองอย่างมีนัยสำคัญ
รายงานทางเทคนิค (v2) : [Cui, Yang และ Yao] การเข้ารหัสข้อความที่มีประสิทธิภาพและมีประสิทธิภาพสำหรับ Llama จีนและ Alpaca
เนื้อหาหลักของโครงการนี้:
รูปด้านล่างแสดงความเร็วประสบการณ์จริงและผลกระทบของโมเดล Alpaca-Plus-7B ของจีนหลังจากการปรับใช้เชิงปริมาณ CPU ในท้องถิ่น
LLAMA LLAMA-2 & Alpaca-2 รุ่นใหญ่ | Multimodal Chinese Llama & Alpaca Big Model | Multimodal VLE | MINIRBT จีน Lert จีน ภาษาอังกฤษภาษาอังกฤษ Pert | Macbert จีน Electra จีน XLNET จีน | เบิร์ตจีน เครื่องมือกลั่นความรู้ TextBrewer | เครื่องมือตัดแบบจำลอง TextPruner
[2024/04/30] Chinese-Llama-Alpaca-3 ได้รับการปล่อยตัวอย่างเป็นทางการโดยมีโอเพ่นซอร์ส LLAMA-3-Chinese-8B และ LLAMA-3-Chinese-8B-Instruct บนพื้นฐานของ LLAMA-3 ขอแนะนำให้ผู้ใช้เฟสหนึ่งและเฟสสองโครงการอัพเกรดเป็นรุ่นรุ่นที่สามโปรดดูที่: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] โครงการนี้ได้รับการปรับใช้ในใจกลางของเครื่อง Sota! แพลตฟอร์มโมเดลยินดีต้อนรับสู่การติดตาม: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] เวอร์ชั่นจีน-llama-alpaca-2 v2.0 ได้รับการปล่อยตัวอย่างเป็นทางการโอเพนซอร์สจีน -llama-2-13b และจีน -Alpaca-2-13b ขอแนะนำให้ผู้ใช้เฟสแรกทุกคนอัปเกรดเป็นรุ่นรุ่นที่สองโปรดดูที่: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/31] เวอร์ชัน Chinese-llama-alpaca-2 v1.0 ได้รับการเผยแพร่อย่างเป็นทางการโปรดดูที่: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] เวอร์ชั่น V5.0: ปล่อยโมเดล Alpaca-Pro Series, ปรับปรุงความยาวและคุณภาพการตอบกลับอย่างมีนัยสำคัญ ในเวลาเดียวกันปล่อยโมเดล Plus-33B Series
[2023/07/19] เปิดตัวโครงการขนาดใหญ่ของจีน Llama-2 และ Alpaca-2 Open Model, ยินดีต้อนรับสู่การติดตามและเรียนรู้เกี่ยวกับข้อมูลล่าสุด
[2023/07/10] ตัวอย่างการทดสอบเบต้าเรียนรู้เกี่ยวกับการอัปเดตล่วงหน้าที่กำลังจะมาถึง: ดูพื้นที่สนทนาสำหรับรายละเอียด
[2023/07/07] ตระกูล Chinese-Llama-Alpaca ได้เพิ่มสมาชิกอีกคนหนึ่งเปิดตัวโมเดล Llama & Alpaca จีนหลายรูปแบบสำหรับคำถามและคำตอบและการสนทนาและเปิดตัวรุ่นทดสอบ 7B
[2023/06/30] การสนับสนุนบริบท 8K ภายใต้ LLAMA.CPP (ไม่จำเป็นต้องมีการดัดแปลงโมเดล) โปรดดูพื้นที่สนทนาสำหรับวิธีการและการอภิปรายที่เกี่ยวข้อง โปรดดู PR#705 สำหรับรหัสที่รองรับบริบท 4K+ ภายใต้ Transformers
[2023/06/16] เวอร์ชัน v4.1: ปล่อยรายงานทางเทคนิคเวอร์ชันใหม่เพิ่มสคริปต์การถอดรหัส C-eval, เพิ่มสคริปต์แบบรวมรุ่นที่มีทรัพยากรต่ำ ฯลฯ
[2023/06/08] เวอร์ชั่น v4.0: ปล่อยภาษาจีน Llama/Alpaca-33b, เพิ่มตัวอย่างการใช้งาน Privategpt, เพิ่มผลลัพธ์ C-eval ฯลฯ
| บท | อธิบาย |
|---|---|
| ⏬โมเดลดาวน์โหลด | Llama Llama และ Alpaca Big Model ดาวน์โหลดที่อยู่ |
| รวมโมเดล | (สำคัญ) แนะนำวิธีการรวมรุ่น Lora ที่ดาวน์โหลดมากับ Llama ดั้งเดิม |
| การใช้เหตุผลในท้องถิ่นและการปรับใช้อย่างรวดเร็ว | แนะนำวิธีการหาปริมาณแบบจำลองและปรับใช้และสัมผัสกับรุ่นขนาดใหญ่โดยใช้คอมพิวเตอร์ส่วนบุคคล |
| เอฟเฟกต์ระบบ | มีการแนะนำเอฟเฟกต์ประสบการณ์การใช้งานภายใต้สถานการณ์และงานบางอย่าง |
| รายละเอียดการฝึกอบรม | แนะนำรายละเอียดการฝึกอบรมของรุ่น Llama และ Alpaca จีน |
| ❓faq | ตอบคำถามที่พบบ่อย |
| โครงการนี้เกี่ยวข้องกับข้อ จำกัด ของแบบจำลอง |
โมเดล Llama ที่วางจำหน่ายอย่างเป็นทางการโดย Facebook นั้นถูกห้ามไม่ให้ใช้งานเชิงพาณิชย์และเจ้าหน้าที่ไม่ได้มีน้ำหนักโมเดลโอเพ่นซอร์สอย่างเป็นทางการ (แม้ว่าจะมีที่อยู่ดาวน์โหลดของบุคคลที่สามจำนวนมากบนอินเทอร์เน็ต) เพื่อให้สอดคล้องกับการอนุญาตที่สอดคล้องกัน น้ำหนัก LORA ที่ปล่อยออกมาที่นี่ สามารถเข้าใจได้ว่าเป็น "แพตช์" ในรุ่น Llama ดั้งเดิม ทั้งสองสามารถรวมกันเพื่อให้ได้ลิขสิทธิ์เต็มรูปแบบ โมเดล Llama/Alpaca Lora ของจีนต่อไปนี้ไม่สามารถใช้เพียงอย่างเดียวและจำเป็นต้องจับคู่กับรุ่น Llama ดั้งเดิม โปรดดูขั้นตอนการผสานแบบจำลองที่กำหนดในโครงการนี้เพื่อสร้างโมเดลขึ้นใหม่
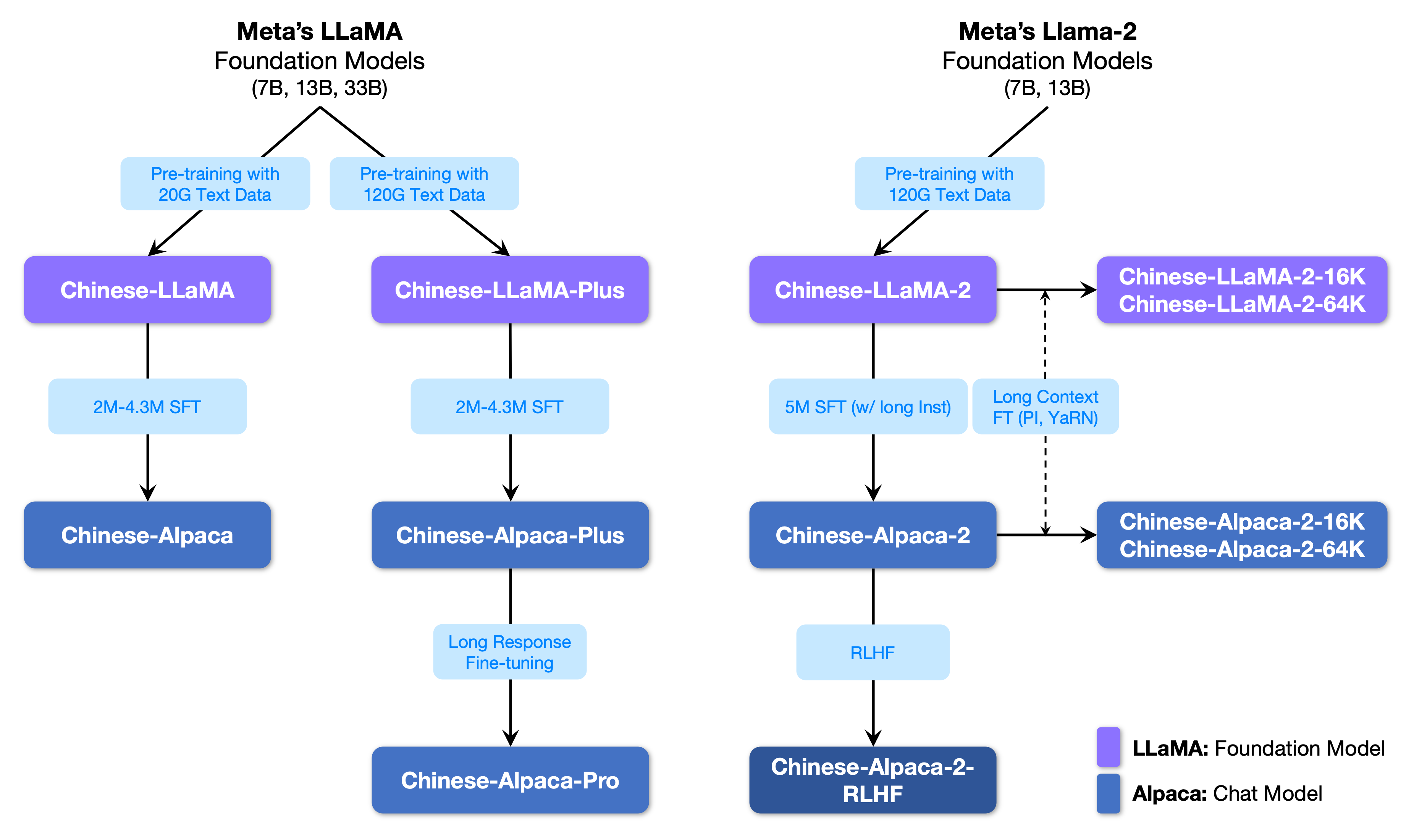
รูปต่อไปนี้แสดงความสัมพันธ์ระหว่างโครงการนี้กับรุ่นใหญ่ทั้งหมดที่เปิดตัวโดยโครงการเฟสที่สอง
ด้านล่างเป็นการเปรียบเทียบพื้นฐานของรุ่น Llama และ Alpaca จีนและสถานการณ์การใช้งานที่แนะนำ (รวมถึง แต่ไม่ จำกัด เพียง) สำหรับข้อมูลเพิ่มเติมดูรายละเอียดการฝึกอบรม
| รายการเปรียบเทียบ | ลามะจีน | อัลปากาจีน |
|---|---|---|
| วิธีการฝึกอบรม | CLM แบบดั้งเดิม | คำแนะนำการปรับแต่งอย่างละเอียด |
| ประเภทรุ่น | รุ่นฐาน | รูปแบบการทำความเข้าใจคำสั่ง (คลาส chatgpt) |
| สื่อการฝึกอบรม | เรียงความทั่วไปที่ไม่มีเครื่องหมาย | ข้อมูลคำสั่งที่มีป้ายกำกับ |
| ขนาดคำศัพท์ [3] | 4995 3 | 4995 4 = 49953+1 (Pad Token) |
| เทมเพลตอินพุต | ไม่จำเป็น | ต้องปฏิบัติตามข้อกำหนดเทมเพลต [1] |
| สถานการณ์ที่เกี่ยวข้อง✔ | ความต่อเนื่องของข้อความ: ให้เนื้อหาข้างต้นให้โมเดลสร้างข้อความต่อไปนี้ | ความเข้าใจในการสอน (คำถามและคำตอบการเขียนคำแนะนำ ฯลฯ ); ความเข้าใจบริบทหลายรอบ (แชท ฯลฯ ) |
| ไม่สามารถใช้ได้ | คำสั่งความเข้าใจการแชทหลายรอบ ฯลฯ | การสร้างข้อความไม่ จำกัด |
| llama.cpp | ใช้พารามิเตอร์ -p เพื่อระบุด้านบน | ใช้พารามิเตอร์ -ins เพื่อเริ่มต้นการเรียนการสอน + โหมดแชท |
| Text-Generation-Webui | ไม่เหมาะสำหรับโหมดแชท | ใช้ --cpu เพื่อเรียกใช้โดยไม่มีกราฟิกการ์ด |
| ลาลาคัท | เลือก "llama" เมื่อโหลดโมเดล | เลือก "Alpaca" เมื่อโหลดโมเดล |
| รหัสอนุมาน HF | ไม่จำเป็นต้องใช้พารามิเตอร์การเริ่มต้นเพิ่มเติม | เพิ่มพารามิเตอร์เมื่อเริ่มต้น --with_prompt |
| รหัสเว็บ-เดโม | ไม่สามารถใช้ได้ | เพียงแค่ให้ตำแหน่งโมเดล Alpaca โดยตรง สนับสนุนการสนทนาหลายรอบ |
| ตัวอย่าง langchain/privateptpt | ไม่สามารถใช้ได้ | เพียงแค่ให้ตำแหน่งของโมเดล Alpaca โดยตรง |
| ปัญหาที่รู้จัก | หากไม่มีการควบคุมสิ้นสุดลงมันจะยังคงเขียนต่อไปจนกว่าจะถึงขีด จำกัด ความยาวเอาต์พุตด้านบน [2] | โปรดใช้เวอร์ชัน PRO เพื่อหลีกเลี่ยงปัญหาของเวอร์ชันบวกที่สั้นเกินไป |
[1] llama.cpp/llamachat/hf รหัสการอนุมาน/รหัสเว็บ-เดโม/ตัวอย่าง langchain ฯลฯ ถูกฝังอยู่ไม่จำเป็นต้องเพิ่มเทมเพลตด้วยตนเอง
[2] หากคุณภาพคำตอบของแบบจำลองต่ำโดยเฉพาะไร้สาระหรือไม่เข้าใจปัญหาโปรดตรวจสอบว่ามีการใช้โมเดลและพารามิเตอร์เริ่มต้นที่ถูกต้องหรือไม่
[3] Alpaca ที่มีคำแนะนำที่ปรับแต่งจะมีโทเค็นแผ่นหนึ่งมากกว่า Llama ดังนั้นโปรดอย่าผสมรายการคำศัพท์ Llama/Alpaca
ต่อไปนี้เป็นรายการของรุ่นที่แนะนำสำหรับโครงการนี้ โดยปกติจะใช้ข้อมูลการฝึกอบรมเพิ่มเติมและวิธีการฝึกอบรมและพารามิเตอร์แบบจำลองที่เหมาะสมที่สุด โปรดให้ความสำคัญกับโมเดลเหล่านี้ (ดูรุ่นอื่น ๆ สำหรับส่วนที่เหลือของโมเดล) หากคุณต้องการสัมผัสกับการโต้ตอบบทสนทนา CHATGPT โปรดใช้โมเดล Alpaca แทนรุ่น Llama สำหรับโมเดล ALPACA รุ่น PRO ได้ปรับปรุงปัญหาของเนื้อหาการตอบกลับที่สั้นเกินไปและเอฟเฟกต์การตอบกลับของแบบจำลองได้รับการปรับปรุงอย่างมีนัยสำคัญ หากคุณต้องการคำตอบสั้น ๆ โปรดเลือกซีรี่ส์ Plus
| ชื่อนางแบบ | พิมพ์ | ข้อมูลการฝึกอบรม | การสร้างโมเดลใหม่ [1] | ขนาด [2] | ดาวน์โหลด lora [3] |
|---|---|---|---|---|---|
| จีน-llama-plus-7b | รุ่นฐาน | วัตถุประสงค์ทั่วไป 120 กรัม | LLAMA-7B ดั้งเดิม | 790m | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-llama-plus-13b | รุ่นฐาน | วัตถุประสงค์ทั่วไป 120 กรัม | LLAMA-13B ดั้งเดิม | 1.0 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-llama-plus-33b? | รุ่นฐาน | วัตถุประสงค์ทั่วไป 120 กรัม | ต้นฉบับ Llama-33b | 1.3G [6] | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Pro-7b? | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-7b & llama-plus-7b [4] | 1.1 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Pro-13b? | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-13b & llama-plus-13b [4] | 1.3G | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Pro-33b? | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-33b & llama-plus-33b [4] | 2.1 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
[1] refactoring ต้องใช้โมเดล Llama ดั้งเดิมไปที่โครงการ Llama เพื่อใช้เพื่อใช้หรืออ้างถึง PR นี้ เนื่องจากปัญหาด้านลิขสิทธิ์โครงการนี้ไม่สามารถให้ลิงก์ดาวน์โหลดได้
[2] ขนาดรุ่นที่สร้างขึ้นใหม่มีขนาดใหญ่กว่า Llama ดั้งเดิมที่มีขนาดเท่ากัน (ส่วนใหญ่เป็นเพราะรายการคำศัพท์ที่ขยายตัว)
[3] หลังจากดาวน์โหลดตรวจสอบให้แน่ใจว่าได้ตรวจสอบว่า sha256 ของไฟล์รุ่นในแพ็คเกจบีบอัดนั้นสอดคล้องกันหรือไม่ โปรดตรวจสอบ sha256.md
[4] โมเดล Alpaca-Plus จำเป็นต้องดาวน์โหลดโมเดล Llama-Plus ที่เกี่ยวข้องในเวลาเดียวกันโปรดดูที่การสอนการผสาน
[5] สถานที่บางแห่งเรียกมันว่า 30b แต่ในความเป็นจริง Facebook เขียนมันผิดเมื่อเผยแพร่โมเดลและบทความยังคงเขียน 33b
[6] ใช้พื้นที่เก็บข้อมูล FP16 ดังนั้นขนาดของรุ่นจึงมีขนาดเล็ก
ไดเรกทอรีไฟล์ในแพ็คเกจบีบอัดมีดังนี้ (การใช้ภาษาจีน-llama-7b เป็นตัวอย่าง):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
เนื่องจากปัจจัยต่าง ๆ เช่นวิธีการฝึกอบรมและข้อมูลการฝึกอบรม จึงไม่แนะนำรุ่นต่อไปนี้อีกต่อไป (อาจยังคงมีประโยชน์ในสถานการณ์เฉพาะ) โปรดให้ความสำคัญกับรุ่นที่แนะนำในส่วนก่อนหน้า
| ชื่อนางแบบ | พิมพ์ | ข้อมูลการฝึกอบรม | การปรับแต่งโมเดล | ขนาด | ดาวน์โหลด lora |
|---|---|---|---|---|---|
| จีน-llama-7b | รุ่นฐาน | ทั่วไป 20 กรัม | LLAMA-7B ดั้งเดิม | 770m | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-llama-13b | รุ่นฐาน | ทั่วไป 20 กรัม | LLAMA-13B ดั้งเดิม | 1.0 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-llama-33b | รุ่นฐาน | ทั่วไป 20 กรัม | ต้นฉบับ Llama-33b | 2.7 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-อัลปากา -7B | โมเดลคำสั่ง | คำแนะนำ 2m | LLAMA-7B ดั้งเดิม | 790m | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-อัลปากา 13b | โมเดลคำสั่ง | คำแนะนำ 3m | LLAMA-13B ดั้งเดิม | 1.1 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| จีน-อัลปากา -33b | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-33b | 2.8 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Plus-7B | โมเดลคำสั่ง | คำแนะนำ 4m | ต้นฉบับ Llama-7b & llama-plus-7b | 1.1 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Plus-13b | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-13b & llama-plus-13b | 1.3G | [Baidu] [Google] [? hf] [? modelscope] |
| Chinese-Alpaca-Plus-33B | โมเดลคำสั่ง | คำแนะนำ 4.3m | ต้นฉบับ Llama-33b & llama-plus-33b | 2.1 กรัม | [Baidu] [Google] [? hf] [? modelscope] |
ทุกรุ่นข้างต้นสามารถดาวน์โหลดได้บน Model Hub และรุ่น Llama Llama หรือ Alpaca Lora สามารถเรียกได้ว่าใช้หม้อแปลงและ Peft ชื่อการเรียกรุ่นต่อไปนี้หมายถึงชื่อรุ่นที่ระบุใน .from_pretrained()
รายละเอียดรายการและรุ่นดาวน์โหลดที่อยู่: https://huggingface.co/hfl
ดังที่ได้กล่าวไว้ก่อนหน้านี้โมเดล LORA ไม่สามารถใช้เพียงอย่างเดียวและจะต้องรวมเข้ากับ Llama ดั้งเดิมเพื่อแปลงเป็นแบบจำลองที่สมบูรณ์สำหรับการอนุมานแบบจำลองปริมาณหรือการฝึกอบรมเพิ่มเติม โปรดเลือกวิธีการต่อไปนี้เพื่อแปลงและรวมโมเดล
| ทาง | สถานการณ์ที่เกี่ยวข้อง | การสอน |
|---|---|---|
| การแปลงออนไลน์ | ผู้ใช้ Colab สามารถใช้สมุดบันทึกที่จัดทำโดยโครงการนี้เพื่อแปลงแบบออนไลน์และหาปริมาณโมเดล | การเชื่อมโยง |
| การแปลงด้วยตนเอง | แปลงออฟไลน์สร้างแบบจำลองในรูปแบบที่แตกต่างกันสำหรับการวัดปริมาณหรือการปรับแต่งเพิ่มเติม | การเชื่อมโยง |
ต่อไปนี้เป็นขนาดความแม่นยำ FP16 และขนาดปริมาณ 4 บิตหลังจากรวมโมเดล ตรวจสอบให้แน่ใจว่าเครื่องมีหน่วยความจำและพื้นที่ดิสก์เพียงพอก่อนการแปลง (ข้อกำหนดขั้นต่ำ):
| รุ่นรุ่น | 7b | 13B | 33B | 65B |
|---|---|---|---|---|
| ขนาดรุ่นดั้งเดิม (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| ขนาดปริมาณ (8 บิต) | 7.8 GB | 14.9 GB | 32.4 GB | ~ 60 GB |
| ขนาดปริมาณ (4 บิต) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
สำหรับรายละเอียดโปรดดูโครงการนี้ >>> GitHub Wiki
แบบจำลองในโครงการนี้ส่วนใหญ่สนับสนุนการหาปริมาณการใช้เหตุผลและวิธีการปรับใช้ต่อไปนี้
| วิธีการให้เหตุผลและการปรับใช้ | คุณสมบัติ | แพลตฟอร์ม | ซีพียู | GPU | การโหลดเชิงปริมาณ | อินเตอร์เฟสกราฟิก | การสอน |
|---|---|---|---|---|---|---|---|
| llama.cpp | ตัวเลือกเชิงปริมาณที่หลากหลายและการใช้เหตุผลในท้องถิ่นที่มีประสิทธิภาพ | ทั่วไป | การเชื่อมโยง | ||||
| ? Transformers | อินเทอร์เฟซการอนุมานของ Transformers | ทั่วไป | การเชื่อมโยง | ||||
| Text-Generation-Webui | วิธีการปรับใช้อินเทอร์เฟซ Web Front-end | ทั่วไป | การเชื่อมโยง | ||||
| ลาลาคัท | อินเทอร์เฟซแบบอินเทอร์แอคทีฟกราฟิกภายใต้ macOS | แม็กอส | การเชื่อมโยง | ||||
| คนขี้เกียจ | กรอบการพัฒนาแอปพลิเคชัน LLM เหมาะสำหรับการพัฒนารอง | ทั่วไป | ✅ † | ✅ † | การเชื่อมโยง | ||
| หมวดหมู่ | คำถามและคำตอบในท้องถิ่นหลายเอกสารตาม Langchain | ทั่วไป | การเชื่อมโยง | ||||
| การสาธิต colab gradio | เริ่มต้นบริการเว็บที่ใช้ Gradeio ใน colab | ทั่วไป | การเชื่อมโยง | ||||
| การโทร API | การสาธิตเซิร์ฟเวอร์ที่จำลองอินเทอร์เฟซ OpenAI API | ทั่วไป | การเชื่อมโยง |
† : กรอบ Langchain รองรับ แต่ไม่ได้ใช้ในการสอน โปรดดูเอกสารอย่างเป็นทางการของ Langchain สำหรับรายละเอียด
สำหรับรายละเอียดโปรดดูโครงการนี้ >>> GitHub Wiki
เพื่อประเมินประสิทธิภาพการสร้างข้อความที่แท้จริงของแบบจำลองที่เกี่ยวข้องอย่างรวดเร็วเนื่องจากโครงการนี้ได้เปรียบเทียบและทดสอบผลกระทบของ Alpaca-7b จีน, Alpaca-13b จีน, Alpaca-33b จีน, Alpaca-Plus-7B และจีน Alpaca-Plus-13B ในโครงการนี้ การสร้างการตอบกลับเป็นแบบสุ่มและได้รับผลกระทบจากปัจจัยต่าง ๆ เช่นการถอดรหัสไฮเปอร์พารามิเตอร์และเมล็ดสุ่ม บทวิจารณ์ที่เกี่ยวข้องต่อไปนี้ไม่ได้เข้มงวดอย่างแน่นอน ผลการทดสอบสำหรับการอ้างอิงการอบแห้งเท่านั้น คุณสามารถสัมผัสได้ด้วยตัวเอง
โครงการนี้ยังทดสอบโมเดลที่เกี่ยวข้องในชุดการประเมินวัตถุประสงค์ของ "NLU" ผลลัพธ์ของการประเมินประเภทนี้ไม่ได้เป็นอัตนัยและต้องการเฉพาะผลลัพธ์ของแท็กที่กำหนด (กลยุทธ์การแมปแท็กต้องได้รับการออกแบบ) ดังนั้นคุณสามารถเข้าใจความสามารถของโมเดลขนาดใหญ่จากมุมมองอื่น โครงการนี้ทดสอบผลกระทบของโมเดลที่เกี่ยวข้องในชุดข้อมูลการประเมินผล C-Eval ที่เพิ่งเปิดตัวซึ่งมีคำถามแบบปรนัย 12.3K และครอบคลุม 52 วิชา ต่อไปนี้เป็นผลการประเมินผลที่ถูกต้องและชุดทดสอบ (เฉลี่ย) ของบางรุ่น โปรดดูรายงานทางเทคนิคสำหรับผลลัพธ์ที่สมบูรณ์
| แบบอย่าง | ถูกต้อง (zero-shot) | ถูกต้อง (5-shot) | ทดสอบ (zero-shot) | ทดสอบ (5-shot) |
|---|---|---|---|---|
| Chinese-Alpaca-Plus-33B | 46.5 | 46.3 | 44.9 | 43.5 |
| จีน-อัลปากา -33b | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13b | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinese-Alpaca-Plus-7B | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-llama-plus-33b | 37.4 | 40.0 | 35.7 | 38.3 |
| จีน-llama-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| จีน-llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| จีน-llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
ควรสังเกตว่าการประเมินที่ครอบคลุมถึงความสามารถของแบบจำลองขนาดใหญ่ยังคงเป็นปัญหาสำคัญที่ต้องแก้ไขอย่างเร่งด่วน มุมมองที่สมเหตุสมผลและวิภาษวิธีของผลการประเมินที่เกี่ยวข้องกับโมเดลขนาดใหญ่จะช่วยให้การพัฒนาอย่างมีสุขภาพดีของเทคโนโลยีขนาดใหญ่ ขอแนะนำให้ผู้ใช้ทดสอบงานที่พวกเขากังวลและเลือกรุ่นที่ปรับให้เข้ากับงานที่เกี่ยวข้อง
โปรดดูโครงการนี้สำหรับรหัสการอนุมาน C-Eval >>> GitHub Wiki
กระบวนการฝึกอบรมทั้งหมดรวมถึงสามส่วน: การขยายคำศัพท์การฝึกอบรมล่วงหน้าและการปรับการเรียนการสอนที่ดี
สำหรับรายละเอียดโปรดดูโครงการนี้ >>> GitHub Wiki
คำถามที่พบบ่อยจะได้รับคำถามที่พบบ่อย โปรดตรวจสอบคำถามที่พบบ่อยก่อนขอปัญหา
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
โปรดดูโครงการนี้สำหรับคำถามและคำตอบเฉพาะ >>> GitHub Wiki
แม้ว่าโมเดลในโครงการนี้จะมีความเข้าใจและความสามารถในการสร้างของจีน แต่ก็มีข้อ จำกัด รวมถึง แต่ไม่ จำกัด เพียง:
หากคุณรู้สึกว่าโครงการนี้มีประโยชน์ต่อการวิจัยของคุณหรือใช้รหัสหรือข้อมูลของโครงการนี้โปรดดูรายงานทางเทคนิคที่อ้างถึงโครงการนี้: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| ชื่อโครงการ | การแนะนำ | พิมพ์ |
|---|---|---|
| Chinese-Llama-Alpaca-2 (โครงการอย่างเป็นทางการ) | LLAMA LLAMA-2, Alpaca-2 Model Big | ข้อความ |
| Visual-Chinese-llama-Alpaca (โครงการอย่างเป็นทางการ) | Multimodal Chinese Llama & Alpaca Big Model | หลายรูปแบบ |
ต้องการเข้าร่วมรายการหรือไม่? >>> ส่งใบสมัคร
โครงการนี้ขึ้นอยู่กับการพัฒนารองของโครงการโอเพ่นซอร์สต่อไปนี้ ฉันต้องการแสดงความขอบคุณต่อโครงการที่เกี่ยวข้องและเจ้าหน้าที่วิจัยและพัฒนา
| โมเดลพื้นฐานรหัส | ปริมาณการใช้เหตุผลการปรับใช้ | ข้อมูล |
|---|---|---|
| Llama by Facebook Alpaca โดย Stanford Alpaca-Lora โดย @tloen | llama.cpp โดย @ggerganov llamachat โดย @alexrozanski Text-Generation-Webui โดย @OOBABOOGA | ข้อมูล PCLUE และ MT โดย @BrightMart OASST1 โดย OpenAssistant |
ทรัพยากรที่เกี่ยวข้องกับโครงการนี้มีไว้สำหรับการวิจัยเชิงวิชาการเท่านั้นและห้ามมิให้มีวัตถุประสงค์เชิงพาณิชย์อย่างเคร่งครัด เมื่อใช้ชิ้นส่วนที่เกี่ยวข้องกับรหัสบุคคลที่สามโปรดติดตามโปรโตคอลโอเพ่นซอร์สที่สอดคล้องกันอย่างเคร่งครัด เนื้อหาที่สร้างขึ้นโดยแบบจำลองได้รับผลกระทบจากปัจจัยต่าง ๆ เช่นการคำนวณแบบจำลองการสุ่มและการสูญเสียความแม่นยำเชิงปริมาณ โครงการนี้ไม่รับประกันความถูกต้อง โครงการนี้จะไม่มีความรับผิดทางกฎหมายสำหรับการส่งออกเนื้อหาใด ๆ โดยแบบจำลองและไม่รับผิดชอบต่อการสูญเสียใด ๆ ที่อาจเกิดขึ้นจากการใช้ทรัพยากรที่เกี่ยวข้องและผลลัพธ์ผลลัพธ์ โครงการนี้เริ่มต้นและดูแลโดยบุคคลและผู้ทำงานร่วมกันในเวลาว่างดังนั้นจึงเป็นไปไม่ได้ที่จะรับประกันว่าพวกเขาสามารถตอบสนองได้ทันทีเพื่อแก้ปัญหาที่เกี่ยวข้อง
หากคุณมีคำถามใด ๆ โปรดส่งในปัญหา GitHub ถามคำถามอย่างสุภาพและสร้างชุมชนการสนทนาที่กลมกลืนกัน


