Chinese LLaMA Alpaca
v5.0
?? Cina | Bahasa Inggris | Dokumen/dokumen | ❓ Pertanyaan/Masalah | Diskusi/Diskusi | ⚔️ Arena/arena

Proyek ini open source model llama Cina dan model alpaca yang disesuaikan instruksi untuk lebih mempromosikan penelitian terbuka model besar di komunitas NLP Cina. Model-model ini telah memperluas daftar kosa kata Tiongkok berdasarkan LLAMA asli dan menggunakan data Cina untuk pra-pelatihan sekunder, lebih lanjut meningkatkan kemampuan pemahaman semantik dasar Cina. Pada saat yang sama, model Alpaca Cina lebih lanjut menggunakan data instruksi Cina untuk penyesuaian yang baik, yang secara signifikan meningkatkan kemampuan pemahaman dan eksekusi model dari instruksi.
Laporan Teknis (V2) : [CUI, Yang, dan Yao] Pengkodean teks yang efisien dan efektif untuk llama dan alpaca Cina
Konten utama dari proyek ini:
Gambar di bawah ini menunjukkan kecepatan dan efek pengalaman aktual dari model Alpaca-plus-7b Cina setelah penyebaran kuantitatif CPU lokal.
Model Besar Llama-2 & Alpaca-2 Cina | Model Besar Multimodal Chinese Llama & Alpaca | Multimodal Vle | Minirbt Cina | Lert Cina | Bahasa Inggris Tiongkok PERT | Macbert Cina | China Electra | Xlnet Cina | Bert Cina | Alat Distilasi Pengetahuan TextBrewer | Model Cutting Tool TextPruner
[2024/04/30] China-llama-alpaca-3 telah dirilis secara resmi, dengan open source llama-3-chinese-8b dan llama-3-chinese-8b-instruct berdasarkan Llama-3. Direkomendasikan bahwa semua fase satu dan fase dua pengguna proyek upgrade ke model generasi ketiga, silakan merujuk ke: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] Proyek ini telah dikerahkan di jantung mesin Sota! Platform Model, Selamat datang untuk mengikuti: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] Versi Cina-Llama-Alpaca-2 V2.0 telah dirilis secara resmi, open source China-llama-2-13b dan Cina-Alpaca-2-13b. Direkomendasikan agar semua upgrade pengguna fase pertama ke model generasi kedua, silakan merujuk ke: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/31] Versi China-llama-alpaca-2 v1.0 telah dirilis secara resmi, silakan merujuk ke: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] Versi V5.0: Lepaskan model seri Alpaca-Pro, secara signifikan meningkatkan panjang dan kualitas balasan; Pada saat yang sama, rilis model seri Plus-33B.
[2023/07/19] Luncurkan proyek model besar open source Chinese Llama-2 dan Alpaca-2, selamat datang untuk mengikuti dan belajar tentang informasi terbaru.
[2023/07/10] Pratinjau tes beta, pelajari tentang pembaruan yang akan datang sebelumnya: lihat area diskusi untuk detailnya
[2023/07/07] Keluarga Cina-Llama-Alpaca telah menambahkan anggota lain, meluncurkan model Multimodal Chinese Llama & Alpaca untuk pertanyaan visual dan jawaban dan dialog, dan merilis versi uji 7B.
[2023/06/30] Dukungan Konteks 8K di bawah llama.cpp (tidak diperlukan modifikasi pada model). Silakan merujuk ke area diskusi untuk metode dan diskusi terkait; Silakan merujuk ke PR#705 untuk kode yang mendukung konteks 4K+ di bawah Transformers.
[2023/06/16] Versi V4.1: Rilis versi baru dari laporan teknis, tambahkan skrip decoding C-eval, tambahkan skrip penggabungan model rendah sumber daya, dll.
[2023/06/08] Versi v4.0: Rilis Chinese Llama/Alpaca-33b, tambahkan contoh penggunaan privategt, tambahkan hasil C-eval, dll.
| bab | menggambarkan |
|---|---|
| ⏬ Unduh Model | Alamat Unduh Model Besar Llama dan Alpaca |
| Gabungkan modelnya | (Penting) Perkenalkan cara menggabungkan model lora yang diunduh dengan llama asli |
| Penalaran lokal dan penyebaran cepat | Memperkenalkan cara mengukur model dan menggunakan dan mengalami model besar menggunakan komputer pribadi |
| ? Efek sistem | Efek pengalaman pengguna dalam beberapa skenario dan tugas diperkenalkan |
| Detail Pelatihan | Memperkenalkan detail pelatihan model llama dan alpaca Cina |
| ❓FAQ | Membalas beberapa faq |
| Proyek ini melibatkan keterbatasan model |
Model LLAMA yang secara resmi dirilis oleh Facebook dilarang dari penggunaan komersial, dan pejabat tidak memiliki bobot model open source resmi (meskipun sudah ada banyak alamat unduhan pihak ketiga di internet). Untuk mematuhi izin yang sesuai, bobot Lora yang dilepaskan di sini dapat dipahami sebagai "tambalan" pada model Llama asli. Keduanya dapat digabungkan untuk mendapatkan hak cipta penuh. Model Llama/Alpaca Lora Cina berikut tidak dapat digunakan sendiri dan perlu dicocokkan dengan model LLAMA asli. Silakan merujuk ke langkah -langkah model merge yang diberikan dalam proyek ini untuk merekonstruksi model.
Gambar berikut menunjukkan hubungan antara proyek ini dan semua model besar yang diluncurkan oleh proyek fase kedua.
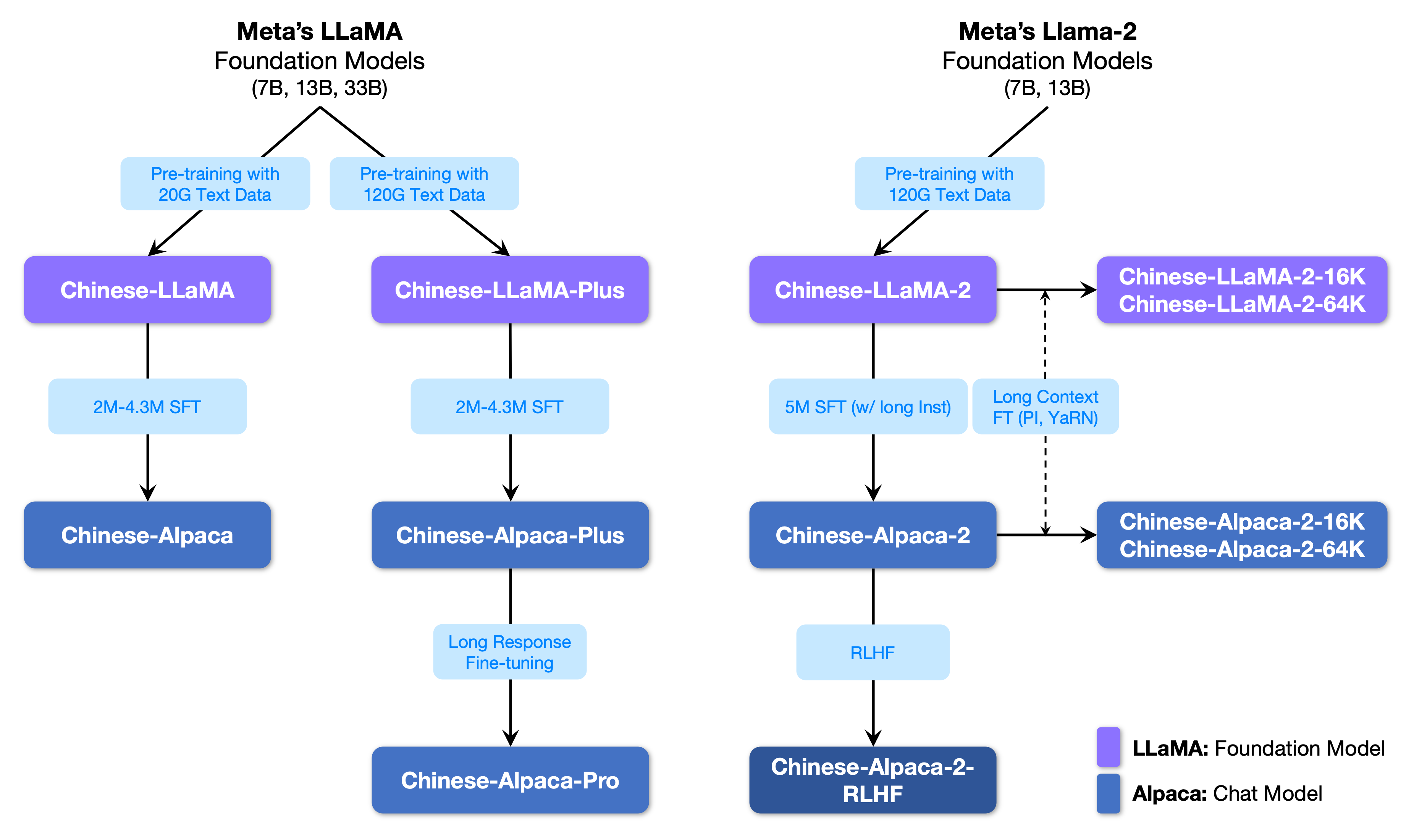
Di bawah ini adalah perbandingan dasar model Llama dan Alpaca Cina dan skenario penggunaan yang direkomendasikan (termasuk tetapi tidak terbatas pada). Untuk informasi lebih lanjut, lihat detail pelatihan.
| Item perbandingan | Llama Cina | Alpaka Cina |
|---|---|---|
| Metode pelatihan | CLM tradisional | Instruksi Penyesuaian Baik |
| Tipe model | Model dasar | Model Pemahaman Instruksi (kelas chatgpt) |
| Materi pelatihan | Esai umum yang tidak ditandai | Data instruksi berlabel |
| Ukuran kosa kata [3] | 4995 3 | 4995 4 = 49953+1 (Token Pad) |
| Input Template | tidak perlu | Perlu memenuhi persyaratan template [1] |
| Skenario yang berlaku ✔️ | Kelanjutan Teks: Mengingat konten di atas, biarkan model menghasilkan teks berikut | Pemahaman instruksi (pertanyaan dan jawaban, penulisan, saran, dll.); pemahaman konteks multi-putaran (obrolan, dll.) |
| Tidak berlaku | Pemahaman perintah, beberapa putaran obrolan, dll. | Pembuatan teks tanpa batas |
| llama.cpp | Gunakan parameter -p untuk menentukan yang di atas | Gunakan parameter -ins untuk memulai instruksi pemahaman + mode obrolan |
| Text-generation-webui | Tidak cocok untuk mode obrolan | Gunakan --cpu untuk dijalankan tanpa kartu grafis |
| Llamachat | Pilih "llama" saat memuat model | Pilih "Alpaca" saat memuat model |
| Kode inferensi HF | Tidak ada parameter startup tambahan yang diperlukan | Tambahkan parameter saat startup --with_prompt |
| Kode Web-Demo | tidak berlaku | Cukup berikan posisi model alpaca secara langsung; mendukung beberapa putaran percakapan |
| Contoh Langchain/Privategpt | tidak berlaku | Cukup berikan lokasi model alpaca secara langsung |
| Masalah yang diketahui | Jika tidak ada kontrol yang berakhir, itu akan terus menulis sampai batas panjang output atas tercapai. [2] | Silakan gunakan versi Pro untuk menghindari masalah versi plus yang terlalu pendek. |
[1] llama.cpp/llelaachat/kode inferensi hf/kode web-demo/contoh langchain dll disematkan, tidak perlu menambahkan templat secara manual.
[2] Jika kualitas jawaban model sangat rendah, omong kosong, atau tidak memahami masalahnya, silakan periksa apakah model yang benar dan parameter startup digunakan.
[3] Alpaca dengan instruksi yang disesuaikan akan memiliki satu token lagi dari Llama, jadi tolong jangan mencampur daftar kosa kata Llama/Alpaca .
Berikut ini adalah daftar model yang direkomendasikan untuk proyek ini. Biasanya, lebih banyak data pelatihan dan metode pelatihan model yang dioptimalkan dan parameter digunakan. Tolong beri prioritas untuk model -model ini (lihat model lain untuk sisa model). Jika Anda ingin mengalami interaksi dialog chatgpt, silakan gunakan model alpaca alih -alih model llama. Untuk model ALPACA, versi Pro telah meningkatkan masalah konten respons yang terlalu pendek, dan efek balasan model telah ditingkatkan secara signifikan; Jika Anda lebih suka balasan pendek, pilih seri Plus.
| Nama model | jenis | Data pelatihan | Merekonstruksi model [1] | Ukuran [2] | Unduh lora [3] |
|---|---|---|---|---|---|
| China-llama-plus-7b | Model dasar | Tujuan Umum 120g | Llama-7b asli | 790m | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-llama-plus-13b | Model dasar | Tujuan Umum 120g | Asli llama-13b | 1.0g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-llama-plus-33b? | Model dasar | Tujuan Umum 120g | Llama-33b asli | 1.3g [6] | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-Pro-7b? | Model instruksi | Instruksi 4.3m | Asli llama-7b & Llama-plus-7b [4] | 1.1g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-Pro-13b? | Model instruksi | Instruksi 4.3m | Asli llama-13b & Llama-plus-13b [4] | 1.3g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-Pro-33b? | Model instruksi | Instruksi 4.3m | Llama-33b asli & Llama-plus-33b [4] | 2.1g | [Baidu] [Google] [? Hf] [? Modelscope] |
[1] Refactoring membutuhkan model LLAMA asli, buka proyek LLAMA untuk melamar digunakan atau merujuk pada PR ini. Karena masalah hak cipta, proyek ini tidak dapat menyediakan tautan unduhan.
[2] Ukuran model yang direkonstruksi lebih besar dari llama asli dengan besarnya yang sama (terutama karena daftar kosa kata yang diperluas).
[3] Setelah mengunduh, pastikan untuk memeriksa apakah SHA256 dari file model dalam paket terkompresi konsisten. Silakan periksa sha256.md.
[4] Model Alpaca-Plus perlu mengunduh model Llama-Plus yang sesuai secara bersamaan, silakan merujuk ke tutorial gabungan.
[5] Beberapa tempat menyebutnya 30b, tetapi sebenarnya Facebook menulisnya secara keliru saat menerbitkan model, dan makalah masih menulis 33B.
[6] Gunakan penyimpanan FP16, jadi ukuran modelnya kecil.
Direktori file dalam paket terkompresi adalah sebagai berikut (mengambil cina-llama-7b sebagai contoh):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Karena faktor -faktor seperti metode pelatihan dan data pelatihan, model berikut tidak lagi direkomendasikan (mungkin masih berguna dalam skenario tertentu) . Harap beri prioritas pada model yang disarankan di bagian sebelumnya.
| Nama model | jenis | Data pelatihan | Refactoring model | ukuran | Unduh lora |
|---|---|---|---|---|---|
| China-llama-7b | Model dasar | Umum 20g | Llama-7b asli | 770m | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-llama-13b | Model dasar | Umum 20g | Asli llama-13b | 1.0g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-llama-33b | Model dasar | Umum 20g | Llama-33b asli | 2.7g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-7b | Model instruksi | Instruksi 2m | Llama-7b asli | 790m | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-13b | Model instruksi | Instruksi 3M | Asli llama-13b | 1.1g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-33b | Model instruksi | Instruksi 4.3m | Llama-33b asli | 2.8g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-plus-7b | Model instruksi | Instruksi 4M | Asli llama-7b & Llama-plus-7b | 1.1g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-plus-13b | Model instruksi | Instruksi 4.3m | Asli llama-13b & Llama-plus-13b | 1.3g | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-plus-33b | Model instruksi | Instruksi 4.3m | Llama-33b asli & Llama-plus-33b | 2.1g | [Baidu] [Google] [? Hf] [? Modelscope] |
Semua model di atas dapat diunduh di Model Hub dan model Llama China atau Alpaca Lora dapat dipanggil menggunakan Transformers dan Peft. Nama panggilan model berikut mengacu pada nama model yang ditentukan dalam .from_pretrained() .
Daftar Detail dan Model Alamat Unduh: https://huggingface.co/hfl
Seperti yang disebutkan sebelumnya, model LORA tidak dapat digunakan sendiri dan harus digabungkan dengan llama asli untuk dikonversi menjadi model lengkap untuk inferensi model, kuantifikasi atau pelatihan lebih lanjut. Pilih metode berikut untuk mengonversi dan menggabungkan model.
| Jalan | Skenario yang berlaku | Tutorial |
|---|---|---|
| Konversi online | Pengguna Colab dapat menggunakan notebook yang disediakan oleh proyek ini untuk mengonversi model online dan mengukur. | Link |
| Konversi manual | Konversi offline, menghasilkan model dalam format yang berbeda untuk kuantisasi atau penyempurnaan lebih lanjut | Link |
Berikut ini adalah presisi FP16 dan ukuran kuantisasi 4-bit setelah menggabungkan model. Pastikan mesin memiliki memori dan ruang disk yang cukup sebelum konversi (persyaratan minimum):
| Versi model | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| Ukuran model asli (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| Ukuran terkuantisasi (8-bit) | 7,8 GB | 14.9 GB | 32.4 GB | ~ 60 GB |
| Ukuran terkuantisasi (4-bit) | 3,9 GB | 7,8 GB | 17.2 GB | 38,5 GB |
Untuk detailnya, silakan merujuk ke proyek ini >>> Github Wiki
Model dalam proyek ini terutama mendukung metode kuantifikasi, penalaran, dan penyebaran berikut.
| Metode penalaran dan penempatan | Fitur | platform | CPU | GPU | Pemuatan kuantitatif | Antarmuka grafis | Tutorial |
|---|---|---|---|---|---|---|---|
| llama.cpp | Opsi kuantitatif yang kaya dan penalaran lokal yang efisien | Umum | ✅ | ✅ | ✅ | link | |
| ? Transformers | Antarmuka Inferensi Transformer Asli | Umum | ✅ | ✅ | ✅ | ✅ | link |
| Text-generation-webui | Cara Menyebarkan Antarmuka UI Web Front-End | Umum | ✅ | ✅ | ✅ | ✅ | link |
| Llamachat | Antarmuka interaktif grafis di bawah macOS | MacOS | ✅ | ✅ | ✅ | link | |
| Langchain | Kerangka Pengembangan Aplikasi LLM, Cocok untuk Pengembangan Sekunder | Umum | ✅ † | ✅ | ✅ † | link | |
| Privategpt | Kerangka kerja tanya jawab lokal multi-dokumen berdasarkan langchain | Umum | ✅ | ✅ | ✅ | link | |
| Demo Colab Gradio | Mulailah layanan web berbasis gradio interaktif di Colab | Umum | ✅ | ✅ | ✅ | link | |
| Panggilan API | Demo server yang meniru antarmuka API openai | Umum | ✅ | ✅ | ✅ | link |
† : Kerangka kerja Langchain mendukungnya, tetapi tidak diimplementasikan dalam tutorial; Silakan merujuk ke dokumentasi resmi Langchain untuk detailnya.
Untuk detailnya, silakan merujuk ke proyek ini >>> Github Wiki
Untuk dengan cepat mengevaluasi kinerja pembuatan teks aktual dari model yang relevan, mengingat propt yang sama, proyek ini membandingkan dan menguji efek Alpaca-7b Cina, Cina Alpaca-13b, Cina Alpaca-33b, Cina Alpaca-PLUS-7B, dan Alpaca-PLUS-13B Cina dalam proyek ini pada beberapa tugas umum. Balas menghasilkan acak dan dipengaruhi oleh faktor -faktor seperti decoding hyperparameters dan biji acak. Ulasan terkait berikut tidak sepenuhnya ketat. Hasil tes hanya untuk referensi pengeringan. Anda dipersilakan untuk mengalaminya sendiri.
Proyek ini juga menguji model yang relevan pada set evaluasi objektif "NLU". Hasil dari jenis evaluasi ini tidak subyektif, dan hanya memerlukan output dari tag yang diberikan (strategi pemetaan tag perlu dirancang), sehingga Anda dapat memahami kemampuan model besar dari perspektif lain. Proyek ini menguji efek dari model terkait pada dataset evaluasi C-eval yang baru diluncurkan, yang berisi 12,3k pertanyaan pilihan ganda dan mencakup 52 subjek. Berikut ini adalah hasil evaluasi yang valid dan tes (rata -rata) dari beberapa model. Silakan merujuk ke laporan teknis untuk hasil yang lengkap.
| Model | Valid (Zero-shot) | Valid (5-shot) | Tes (Zero-shot) | Tes (5-shot) |
|---|---|---|---|---|
| China-Alpaca-plus-33b | 46.5 | 46.3 | 44.9 | 43.5 |
| China-Alpaca-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| China-Alpaca-plus-13b | 43.3 | 42.4 | 41.5 | 39.9 |
| China-Alpaca-plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| China-llama-plus-33b | 37.4 | 40.0 | 35.7 | 38.3 |
| China-llama-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| China-llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| China-llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Perlu dicatat bahwa evaluasi komprehensif dari kemampuan model besar masih merupakan masalah penting yang perlu diselesaikan dengan segera. Pandangan yang masuk akal dan dialektis dari berbagai hasil evaluasi yang terkait dengan model besar akan membantu pengembangan teknologi model besar yang sehat. Disarankan agar pengguna menguji tugas yang mereka khawatirkan dan pilih model yang beradaptasi dengan tugas terkait.
Silakan merujuk pada proyek ini untuk kode inferensi C-eval >>> github wiki
Seluruh proses pelatihan mencakup tiga bagian: ekspansi kosa kata, pra-pelatihan dan penyesuaian instruksi.
Untuk detailnya, silakan merujuk ke proyek ini >>> Github Wiki
FAQ diberi pertanyaan yang sering diajukan. Silakan periksa FAQ sebelum meminta masalah.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Silakan merujuk pada proyek ini untuk pertanyaan dan jawaban tertentu >>> Github Wiki
Meskipun model dalam proyek ini memiliki kemampuan pemahaman dan generasi Cina tertentu, mereka juga memiliki keterbatasan, termasuk tetapi tidak terbatas pada:
Jika Anda merasa proyek ini bermanfaat untuk penelitian Anda atau menggunakan kode atau data proyek ini, silakan merujuk ke laporan teknis yang mengutip proyek ini: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Nama proyek | Perkenalan | jenis |
|---|---|---|
| China-Llama-Alpaca-2 (Proyek Resmi) | Model Besar Llama-2, Alpaca-2 China | teks |
| Visual-Chinese-Llama-Alpaca (Proyek Resmi) | Model Besar Llama & Alpaca Multimodal | Multimodal |
Ingin bergabung dengan daftar? >>> Kirimkan aplikasi
Proyek ini didasarkan pada pengembangan sekunder dari proyek sumber terbuka berikut. Saya ingin mengucapkan terima kasih kepada proyek yang relevan dan staf penelitian dan pengembangan.
| Model Dasar, Kode | Kuantifikasi, Penalaran, Penyebaran | data |
|---|---|---|
| Llama oleh Facebook Alpaca oleh Stanford alpaca-lora oleh @tloen | llama.cpp oleh @ggerganov Llamachat oleh @alexrozanski Text-Generation-Webui oleh @oobabooga | data pclue dan mt oleh @brightmart OASST1 oleh OpenAssistant |
Sumber daya yang terkait dengan proyek ini hanya untuk penelitian akademik dan dilarang ketat untuk tujuan komersial. Saat menggunakan bagian yang melibatkan kode pihak ketiga, silakan ikuti protokol open source yang sesuai. Konten yang dihasilkan oleh model dipengaruhi oleh faktor -faktor seperti perhitungan model, keacakan dan kerugian akurasi kuantitatif. Proyek ini tidak menjamin keakuratannya. Proyek ini mengasumsikan tidak ada kewajiban hukum untuk setiap output konten oleh model, juga tidak bertanggung jawab atas kerugian yang mungkin timbul dari penggunaan sumber daya yang relevan dan hasil output. Proyek ini dimulai dan dikelola oleh individu dan kolaborator di waktu luang mereka, sehingga tidak mungkin untuk menjamin bahwa mereka dapat segera merespons untuk menyelesaikan masalah yang sesuai.
Jika Anda memiliki pertanyaan, silakan kirimkan dalam masalah GitHub. Ajukan pertanyaan dengan sopan dan bangun komunitas diskusi yang harmonis.


