Chinese LLaMA Alpaca
v5.0
? Chinesisch | Englisch | Dokumente/Dokumente | ❓ Fragen/Probleme | Diskussionen/Diskussionen | ⚔️ Arena/Arena

Dieses Projekt Open Source Das chinesische Lama-Modell und das Anleitungs-abgestimmte Alpaka-Modell, um die offene Forschung des großen Modells in der chinesischen NLP-Community weiter zu fördern. Diese Modelle haben die chinesische Vokabularliste basierend auf dem ursprünglichen Lama erweitert und chinesische Daten für die sekundäre Vorverarbeitung verwendet, wodurch die grundlegende semantische Verständnisfähigkeit von Chinesen weiter verbessert wird. Gleichzeitig verwendet das chinesische Alpaka -Modell chinesische Anweisungsdaten zur Feinanpassung, was die Verständnis- und Ausführungsfunktionen des Modells von Anweisungen erheblich verbessert.
Technischer Bericht (V2) : [Cui, Yang und Yao] Effiziente und effektive Textkodierung für chinesische Lama und Alpaka
Hauptinhalt dieses Projekts:
Die folgende Abbildung zeigt die tatsächliche Erlebnisgeschwindigkeit und den Wirkung des chinesischen Alpaca-Plus-7b-Modells nach der lokalen quantitativen CPU-Bereitstellung.
Chinesische Lama-2 & Alpaca-2 Big Model | Multimodales chinesisches Lama & Alpaca Big Model | Multimodale VLE | Chinesische Minirbt | Chinesische LERT | Chinese Englisch Pert | Chinesischer Macbert | Chinesische Elektrik | Chinesische xlnet | Chinesische Bert | Knowledge Destillation Tool Textbrewer | Modellschneidwerkzeug Textpruner
[2024/04/30] Chinese-Llama-Alpaca-3 wurde offiziell veröffentlicht, wobei Open Source LLAMA-3-Chinese-8b und Lama-3-Chinese-8b-Instruct basierend auf LLAMA-3. Es wird empfohlen, dass alle Projektbenutzer alle Projektbenutzer in Phase 1 und 2 auf das Modell der dritten Generation ein Upgrade finden
[2024/03/27] Dieses Projekt wurde im Herzen von Machine Sota eingesetzt! Modellplattform, Willkommen zu folgen: https://sota.jiqizhixin.com/project/chinese-lama-alpaca
[2023/08/14] Chinese-Llama-Alpaca-2 V2.0-Version wurde offiziell veröffentlicht, Open Source Chinese-Llama-2-13B und Chinese-Alpaca-2-13b. Es wird empfohlen, dass alle Benutzer von First-Phase-Benutzern auf das Modell der zweiten Generation aktualisieren. Weitere Informationen finden Sie unter: https://github.com/ymcui/chinese-lama-alpaca-2
[2023/07/31] Chinese-Llama-alpaca-2 v1.0 Version wurde offiziell veröffentlicht. Weitere Informationen finden Sie unter: https://github.com/ymcui/chinese-lama-alpaca-2
[2023/07/19] V5.0 Version: Veröffentlichen Sie das Modell der Alpaca-Pro-Serie, wodurch die Antwortlänge und -qualität erheblich verbessert wird; Veröffentlichen Sie gleichzeitig das Modell der Plus-33B-Serie.
[2023/07/19] Starten Sie die chinesischen LLAMA-2 und die Alpaca-2 Open Source Big Model-Projekte, willkommen, um die neuesten Informationen zu folgen und zu erfahren.
[2023/07/10] Beta -Test -Vorschau, erfahren Sie im Voraus die bevorstehenden Updates: Weitere Informationen finden Sie im Diskussionsbereich
[2023/07/07] Die Familie Chinese-Llama-Alpaca hat ein weiteres Mitglied hinzugefügt, das ein multimodales chinesisches Lama- und Alpaka-Modell für visuelle Frage und Antwort und Dialog gestartet und eine 7B-Testversion veröffentlicht.
[2023/06/30] 8K -Kontextunterstützung unter llama.cpp (es ist keine Änderung des Modells erforderlich). Weitere Methoden und Diskussionen finden Sie im Diskussionsbereich. In der PR#705 finden Sie Codes, die einen 4K+ -Kontext unter Transformers unterstützen.
[2023/06/16] v4.1 Version: Veröffentlichen Sie eine neue Version des technischen Berichts, fügen Sie C-Eval-Dekodierungsskripte hinzu, fügen Sie das Modell mit niedrigem Ressourcen-Model Ferge-Skripten hinzu, usw.
[2023/06/08] v4.0 Version: Veröffentlichung chinesischer Lama/Alpaca-33b, fügen Sie private GPT-Verwendungsbeispiele hinzu, fügen Sie C-Eval-Ergebnisse hinzu, usw.
| Kapitel | beschreiben |
|---|---|
| ⏬Model Download | Chinesische Lama- und Alpaca Big Model Download -Adresse |
| Das Modell verschmelzen | (WICHTIG) Führen Sie vor, wie Sie das heruntergeladene Lora -Modell mit dem ursprünglichen Lama zusammenführen können |
| Lokale Argumentation und schneller Einsatz | Führen Sie vor |
| Systemeffekte | Der Benutzererfahrungseffekt unter einigen Szenarien und Aufgaben wird eingeführt |
| Trainingsdetails | Stellte die Trainingsdetails der chinesischen Lama- und Alpaka -Modelle vor |
| ❓faq | Antworten auf einige FAQs |
| Dieses Projekt beinhaltet Einschränkungen des Modells |
Das von Facebook offiziell offiziell veröffentlichte Lama-Modell ist von der kommerziellen Nutzung verboten, und der Beamte hat keine offiziellen Open-Source-Modellgewichte (obwohl es bereits viele Download-Adressen von Drittanbietern im Internet gibt). Um der entsprechenden Erlaubnis einzuhalten, können die hier veröffentlichten Lora -Gewichte als "Patch" auf dem ursprünglichen Lama -Modell verstanden werden. Die beiden können kombiniert werden, um das vollständige Urheberrecht zu erhalten. Das folgende chinesische Lama/Alpaka -Lora -Modell kann nicht allein verwendet werden und muss mit dem ursprünglichen Lama -Modell übereinstimmen. Bitte beachten Sie die in diesem Projekt angegebenen Schritte für Merge -Modell, um das Modell zu rekonstruieren.
Die folgende Abbildung zeigt die Beziehung zwischen diesem Projekt und allen großen Modellen, die vom Projekt der zweiten Phase gestartet wurden.
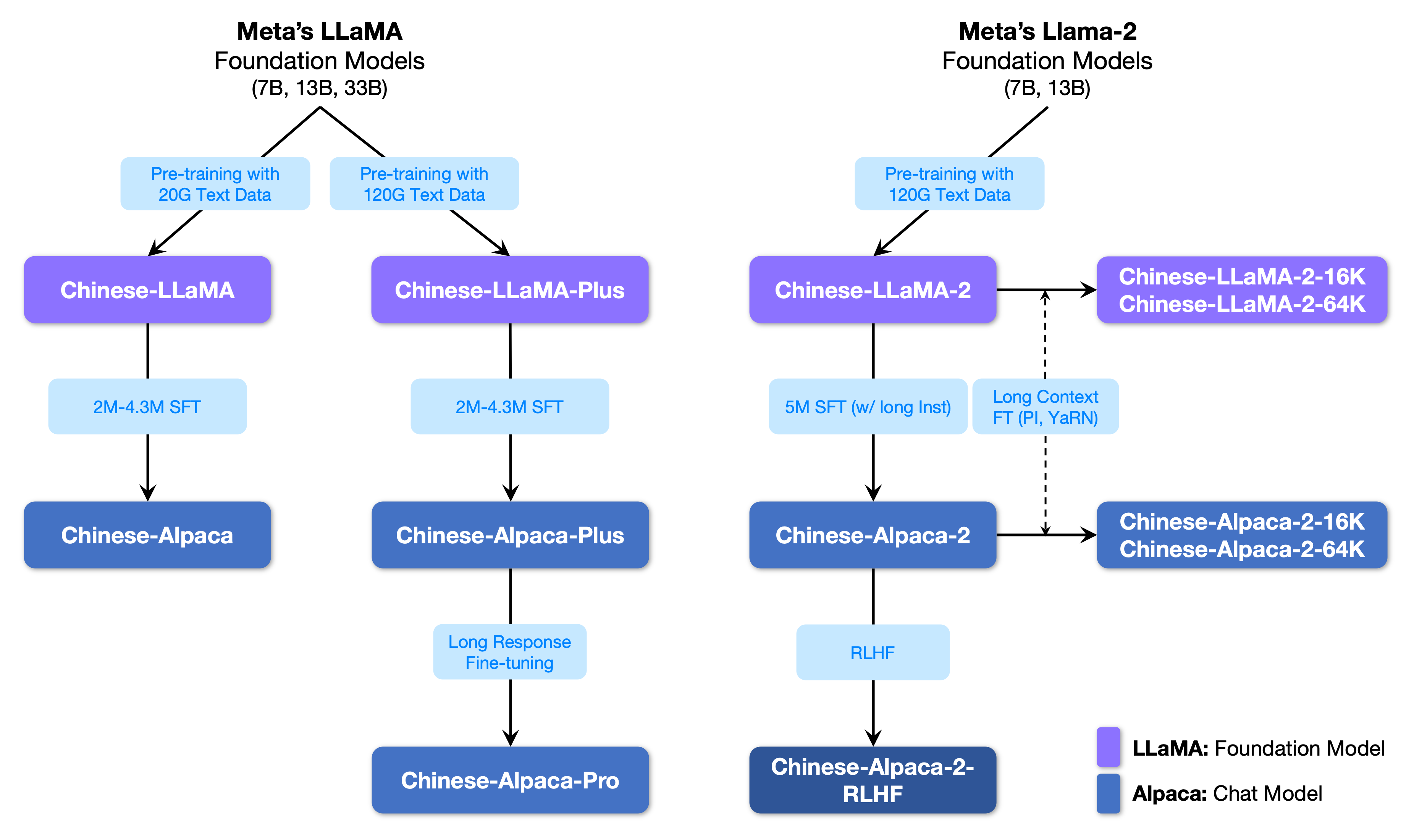
Im Folgenden finden Sie einen grundlegenden Vergleich von chinesischen Lama- und Alpaka -Modellen und empfohlenen Nutzungsszenarien (einschließlich, aber nicht beschränkt auf). Weitere Informationen finden Sie in den Trainingsdetails.
| Vergleichselemente | Chinesisches Lama | Chinesisches Alpaka |
|---|---|---|
| Trainingsmethode | Traditioneller CLM | Befürworter feiner Einstellung |
| Modelltyp | Basismodell | Anweisungsverständnismodell (Klasse Chatgpt) |
| Trainingsmaterialien | Nicht markierter allgemeiner Aufsatz | Beschriftete Anweisungsdaten |
| Wortschatzgröße [3] | 4995 3 | 4995 4 = 49953+1 (Pad Token) |
| Eingabemittel | unnötig | Müssen die Vorlagenanforderungen erfüllen [1] |
| Anwendbare Szenarien ✔️ | Textdauer: Lassen Sie das Modell den folgenden Text generieren | Verständnis für Anweisungen (Fragen und Antworten, Schreiben, Vorschläge usw.); Multi-Runden-Kontextverständnis (Chat usw.) |
| Nicht anwendbar | Befehlsverständnis, mehrere Runden Chat usw. | Unbegrenzte Textgenerierung |
| lama.cpp | Verwenden Sie den Parameter -p , um das oben angegeben anzugeben | Verwenden Sie den Parameter -ins , um den Anweisungsverständnis + Chat -Modus zu starten |
| Text-Generation-Webui | Nicht für den Chat -Modus geeignet | Verwenden Sie --cpu , um ohne Grafikkarte auszuführen |
| Llamachat | Wählen Sie "Lama" beim Laden des Modells | Wählen Sie "Alpaka" beim Laden des Modells |
| HF -Inferenzcode | Keine zusätzlichen Startparameter erforderlich | Fügen Sie beim Start Parameter hinzu --with_prompt |
| Web-Demo-Code | nicht anwendbar | Geben Sie einfach die Position der Alpaka -Modell direkt an. Unterstützen Sie mehrere Gesprächerunden |
| Langchain Beispiel/privatgpt | nicht anwendbar | Geben Sie einfach den Standort des Alpaka -Modells direkt an |
| Bekannte Probleme | Wenn kein Steuerelement endet, wird es weiter geschrieben, bis die obere Ausgangslängengrenze erreicht ist. [2] | Bitte verwenden Sie die Pro -Version, um zu vermeiden, dass das Problem der Plus -Version zu kurz ist. |
[1] llama.cpp/llamachat/hf Inferenzcode/Web-Demo-Code/Langchain-Beispiele usw. sind eingebettet, keine Vorlagen manuell hinzuzufügen.
[2] Wenn das Modell der Modellantwort besonders niedrig ist, das Problem nicht zu verstehen oder nicht zu verstehen, prüfen Sie bitte, ob die richtigen Modell- und Startparameter verwendet werden.
[3] Alpaka mit fein abgestimmten Anweisungen haben ein weiteres Pad-Token als Lama. Bitte mischen Sie also nicht die Liste der Lama/Alpaka-Vokabeln .
Das Folgende ist eine Liste von Modellen, die für dieses Projekt empfohlen werden. Normalerweise werden mehr Trainingsdaten und optimierte Modelltrainingsmethoden und -parameter verwendet. Bitte geben Sie diesen Modellen Priorität (siehe andere Modelle für den Rest der Modelle). Wenn Sie die Interaktion mit Chatgpt -Dialog -Interaktion erleben möchten, verwenden Sie bitte das Alpaca -Modell anstelle des Lama -Modells. Für das Alpaca -Modell hat die Pro -Version das Problem des zu kurzer Antwortinhalts verbessert, und der Modell -Antworteffekt wurde erheblich verbessert. Wenn Sie kurze Antworten bevorzugen, wählen Sie bitte die Plus -Serie.
| Modellname | Typ | Trainingsdaten | Rekonstruktion des Modells [1] | Größe [2] | Lora Download [3] |
|---|---|---|---|---|---|
| Chinese-Llama-plus-7b | Basismodell | Allgemeiner Zweck 120g | Original Lama-7b | 790 m | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Llama-plus-13b | Basismodell | Allgemeiner Zweck 120g | Original Lama-13b | 1,0g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Llama-plus-33b? | Basismodell | Allgemeiner Zweck 120g | Original Lama-33b | 1,3g [6] | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Pro-7b? | Anweisungsmodell | Anweisung 4.3m | Original Lama-7b & LAMA-PLUS-7B [4] | 1.1g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Pro-13b? | Anweisungsmodell | Anweisung 4.3m | Original Lama-13b & LAMA-PLUS-13B [4] | 1,3g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Pro-33b? | Anweisungsmodell | Anweisung 4.3m | Original Lama-33b & LAMA-PLUS-33B [4] | 2.1g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
[1] Refactoring erfordert das ursprüngliche Lama -Modell, wechseln Sie zum Lama -Projekt, um sie zu beantragen oder sich auf diese PR zu beziehen. Aufgrund von Urheberrechtsproblemen kann dieses Projekt keinen Download -Link bereitstellen.
[2] Die rekonstruierte Modellgröße ist größer als das ursprüngliche Lama der gleichen Größe (hauptsächlich wegen der erweiterten Vokabularliste).
[3] Überprüfen Sie nach dem Herunterladen unbedingt, ob der SHA256 der Modelldatei im komprimierten Paket konsistent ist. Bitte überprüfen Sie SHA256.md.
[4] Das Modell von Alpaca-Plus muss das entsprechende Lama-Plus-Modell gleichzeitig herunterladen. Weitere Informationen finden Sie im Merge-Tutorial.
[5] Einige Orte nennen es 30b, aber Facebook hat es bei der Veröffentlichung des Modells falsch geschrieben, und das Papier schrieb immer noch 33B.
[6] Verwenden Sie den FP16 -Speicher, sodass die Modellgröße klein ist.
Das Dateiverzeichnis im komprimierten Paket lautet wie folgt (als Beispiel Chinesisch-Llama-7b):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Aufgrund von Faktoren wie Trainingsmethoden und Trainingsdaten werden die folgenden Modelle nicht mehr empfohlen (können in bestimmten Szenarien weiterhin nützlich sein) . Bitte geben Sie den empfohlenen Modellen im vorherigen Abschnitt Vorrang.
| Modellname | Typ | Trainingsdaten | Das Modell neu aufstellen | Größe | Lora Download |
|---|---|---|---|---|---|
| Chinese-Llama-7b | Basismodell | General 20g | Original Lama-7b | 770 m | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Llama-13b | Basismodell | General 20g | Original Lama-13b | 1,0g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Llama-33b | Basismodell | General 20g | Original Lama-33b | 2,7g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-7b | Anweisungsmodell | Anweisung 2m | Original Lama-7b | 790 m | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-13b | Anweisungsmodell | Anweisung 3m | Original Lama-13b | 1.1g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-33b | Anweisungsmodell | Anweisung 4.3m | Original Lama-33b | 2,8g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Plus-7b | Anweisungsmodell | Anweisung 4m | Original Lama-7b & Lama-plus-7b | 1.1g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Plus-13b | Anweisungsmodell | Anweisung 4.3m | Original Lama-13b & Lama-plus-13b | 1,3g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
| Chinese-Alpaca-Plus-33b | Anweisungsmodell | Anweisung 4.3m | Original Lama-33b & LAMA-PLUS-33B | 2.1g | [Baidu] [Google] [? HF] [MODELLSCOPE] |
Alle oben genannten Modelle können auf dem Model Hub heruntergeladen werden und die chinesischen Lama- oder Alpaka -Lora -Modelle können mithilfe von Transformatoren und PEFT bezeichnet werden. Der folgende Modellanrufname bezieht sich auf den in .from_pretrained() angegebenen Modellnamen.
Detaillierte Liste und Modell -Download -Adresse: https://huggingface.co/hfl
Wie bereits erwähnt, kann das LORA -Modell nicht allein verwendet werden und muss mit dem ursprünglichen Lama zusammengeführt werden, um in ein vollständiges Modell für Modellinferenz, Quantifizierung oder weiteres Training umgewandelt zu werden. Bitte wählen Sie die folgende Methode, um das Modell umzuwandeln und zusammenzuführen.
| Weg | Anwendbare Szenarien | Tutorial |
|---|---|---|
| Online -Konvertierung | Colab -Benutzer können das von diesem Projekt bereitgestellte Notizbuch verwenden, um Online -Konvertiten zu konvertieren und Modelle zu quantifizieren. | Link |
| Manuelle Konvertierung | Offline konvertieren, Modelle in verschiedenen Formaten zur Quantisierung oder weiterer Verfeinerung erzeugen | Link |
Das Folgende ist die Größe der FP16-Präzision und die 4-Bit-Quantisierungsgröße nach dem Zusammenführen des Modells. Stellen Sie sicher, dass die Maschine vor der Konvertierung über ausreichend Speicher- und Festplattenraum verfügt (Mindestanforderungen):
| Modellversion | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| Originalmodellgröße (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| Quantisierte Größe (8-Bit) | 7,8 GB | 14,9 GB | 32,4 GB | ~ 60 GB |
| Quantisierte Größe (4-Bit) | 3,9 GB | 7,8 GB | 17,2 GB | 38,5 GB |
Weitere Informationen finden Sie in diesem Projekt >>> Github Wiki
Die Modelle in diesem Projekt unterstützen hauptsächlich die folgenden Methoden zur Quantifizierung, Argumentation und Bereitstellung.
| Argumentations- und Bereitstellungsmethoden | Merkmale | Plattform | CPU | GPU | Quantitative Belastung | Grafikschnittstelle | Tutorial |
|---|---|---|---|---|---|---|---|
| lama.cpp | Reiche quantitative Optionen und effiziente lokale Argumentation | Allgemein | ✅ | ✅ | ✅ | Link | |
| ? Transformatoren | Native Transformers Inference Interface | Allgemein | ✅ | ✅ | ✅ | ✅ | Link |
| Text-Generation-Webui | So bereitstellen Sie die Front-End-Web-UI-Schnittstelle | Allgemein | ✅ | ✅ | ✅ | ✅ | Link |
| Llamachat | Grafische interaktive Schnittstelle unter macOS | Macos | ✅ | ✅ | ✅ | Link | |
| Langchain | LLM Application Development Framework, geeignet für die Sekundärentwicklung | Allgemein | ✅ † | ✅ | ✅ † | Link | |
| privatgpt | Multi-Dokument-lokaler Frage- und Beantwortungsrahmen basierend auf Langchain | Allgemein | ✅ | ✅ | ✅ | Link | |
| Colab Gradio Demo | Starten Sie einen interaktiven Gradio-basierten Webdienst in Colab | Allgemein | ✅ | ✅ | ✅ | Link | |
| API -Anrufe | Server -Demo, die die OpenAI -API -Schnittstelle emuliert | Allgemein | ✅ | ✅ | ✅ | Link |
† : Das Langchain -Framework unterstützt es, wird jedoch im Tutorial nicht implementiert. Weitere Informationen finden Sie in der offiziellen Langchain -Dokumentation.
Weitere Informationen finden Sie in diesem Projekt >>> Github Wiki
Um die tatsächliche Leistung der relevanten Modelle mit demselben EPPT schnell zu bewerten, verglichen und testete dieses Projekt die Auswirkungen von chinesischem Alpaca-7b, chinesischem Alpaca-13b, chinesischem Alpaca-33b, chinesischer Alpaca-Plus-7b und chinesischer Alpaca-Plus-13b in diesem Projekt bei einigen gemeinsamen Aufgaben. Die Generierung der Antwort ist zufällig und wird von Faktoren wie Decodierung von Hyperparametern und zufälligen Samen beeinflusst. Die folgenden verwandten Bewertungen sind nicht absolut streng. Die Testergebnisse dienen nur zum Trocknen der Referenz. Sie können es gerne selbst erleben.
Dieses Projekt testete auch die relevanten Modelle auf dem Ziel der objektiven Bewertung von "NLU". Die Ergebnisse dieser Art der Bewertung sind nicht subjektiv und erfordern nur die Ausgabe eines bestimmten Tags (die Tag -Mapping -Strategie muss entwickelt werden), sodass Sie die Fähigkeiten des großen Modells aus einer anderen Perspektive verstehen können. Dieses Projekt testete die Auswirkungen verwandter Modelle auf den kürzlich gestarteten C-Eval-Bewertungsdatensatz, der 12,3K-Multiple-Choice-Fragen enthielt und 52 Probanden abgedeckt hat. Im Folgenden finden Sie die gültigen und Test -Set -Bewertungsergebnisse (Durchschnitt) einiger Modelle. Weitere Ergebnisse finden Sie im technischen Bericht.
| Modell | Gültig (Null-Shot) | Gültig (5-shot) | Test (Null-Shot) | Test (5-Shot) |
|---|---|---|---|---|
| Chinese-Alpaca-Plus-33b | 46,5 | 46,3 | 44,9 | 43,5 |
| Chinese-Alpaca-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13b | 43.3 | 42.4 | 41,5 | 39.9 |
| Chinese-Alpaca-Plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-Llama-plus-33b | 37,4 | 40.0 | 35.7 | 38.3 |
| Chinese-Llama-33b | 34.9 | 38,4 | 34.6 | 39,5 |
| Chinese-Llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-Llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Es ist zu beachten, dass eine umfassende Bewertung der Fähigkeit großer Modelle immer noch ein wichtiges Thema ist, das dringend gelöst werden muss. Eine vernünftige und dialektische Sicht auf verschiedene Evaluierungsergebnisse im Zusammenhang mit großen Modellen wird die gesunde Entwicklung der großen Modelltechnologie helfen. Es wird empfohlen, dass Benutzer auf Aufgaben testen, über die sie besorgt sind, und Modelle auszuwählen, die sich an verwandte Aufgaben anpassen.
Weitere Informationen finden Sie in diesem Projekt für C-Eval-Inferenzcode >>> Github Wiki
Der gesamte Trainingsprozess umfasst drei Teile: Vokabularerweiterung, Feinanpassung vor der Ausbildung und Anweisung.
Weitere Informationen finden Sie in diesem Projekt >>> Github Wiki
Die FAQ wird eine häufig gestellte Frage gegeben. Bitte überprüfen Sie die FAQ, bevor Sie nach einem Problem fragen.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
In diesem Projekt finden Sie spezielle Fragen und Antworten >>> Github Wiki
Obwohl die Modelle in diesem Projekt bestimmte chinesische Verständnis- und Erzeugungsfähigkeiten haben, haben sie auch Einschränkungen, einschließlich, aber nicht beschränkt auf:
Wenn Sie der Meinung sind, dass dieses Projekt für Ihre Forschung hilfreich ist oder den Code oder die Daten dieses Projekts verwenden, finden Sie im technischen Bericht unter Berufung auf dieses Projekt: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Projektname | Einführung | Typ |
|---|---|---|
| Chinese-Llama-Alpaca-2 (offizielles Projekt) | Chinesische Lama-2, Alpaca-2 Big Model | Text |
| Visual-Chinese-Llama-Alpaca (offizielles Projekt) | Multimodales chinesisches Lama & Alpaka Big Model | Multimodal |
Möchten Sie der Liste beitreten? >>> Einen Antrag einreichen
Dieses Projekt basiert auf der sekundären Entwicklung der folgenden Open -Source -Projekte. Ich möchte den relevanten Projekten sowie Forschungs- und Entwicklungspersonal meinen Dank aussprechen.
| Basismodell, Code | Quantifizierung, Argumentation, Einsatz | Daten |
|---|---|---|
| Lama von Facebook Alpaka von Stanford Alpaca-Lora von @tloen | lama.cpp von @ggerganov Llamachat von @alexrozanski Text-Generation-Webui von @Oobabooga | PCLUE- und MT -Daten von @brightmart Oast1 von OpenSthsistant |
Die Ressourcen im Zusammenhang mit diesem Projekt dienen nur für die akademische Forschung und sind für kommerzielle Zwecke strengstens untersagt. Wenn Sie Teile mit Code von Drittanbietern verwenden, folgen Sie bitte dem entsprechenden Open-Source-Protokoll ausschließlich. Der vom Modell erzeugte Inhalt wird durch Faktoren wie Modellberechnung, Zufälligkeit und quantitative Genauigkeitsverluste beeinflusst. Dieses Projekt garantiert seine Genauigkeit nicht. Dieses Projekt setzt keine gesetzliche Haftung für eine Inhaltsausgabe durch das Modell über und haftet auch nicht für Verluste, die sich aus der Verwendung relevanter Ressourcen und Ausgabeergebnisse ergeben können. Dieses Projekt wird in ihrer Freizeit von Einzelpersonen und Mitarbeitern initiiert und gepflegt. Daher ist es unmöglich zu garantieren, dass sie sofort reagieren können, um die entsprechenden Probleme zu lösen.
Wenn Sie Fragen haben, senden Sie diese bitte in Github -Problem. Stellen Sie die Fragen höflich und bauen Sie eine harmonische Diskussionsgemeinschaft auf.


