Chinese LLaMA Alpaca
v5.0
?? 중국어 | 영어 | 문서/문서 | ❓ 질문/문제 | 토론/토론 | Arena/Arena

이 프로젝트는 중국 LLAMA 모델과 중국 NLP 커뮤니티의 큰 모델의 개방형 연구를 더욱 촉진하기 위해 중국 라마 모델과 교육 조정 된 알파카 모델을 오픈합니다. 이 모델은 원래 라마를 기반으로 중국 어휘 목록을 확장하고 2 차 전 사전 훈련을 위해 중국 데이터를 사용하여 중국의 기본 의미 론적 이해 능력을 더욱 향상 시켰습니다. 동시에, 중국 알파카 모델은 중국어 명령 데이터를 추가로 사용하여 미세 조정을 사용하여 모델의 이해 및 실행 능력을 크게 향상시킵니다.
기술 보고서 (v2) : [Cui, Yang 및 Yao] 중국 라마 및 알파카에 대한 효율적이고 효과적인 텍스트 인코딩
이 프로젝트의 주요 내용 :
아래 그림은 로컬 CPU 정량적 배치 후 중국 알파카 -Plus-7B 모델의 실제 경험 속도와 효과를 보여줍니다.
중국 llama-2 & alpaca-2 큰 모델 | 멀티 모달 중국어 라마 & 알파카 빅 모델 | 멀티 모달 vle | 중국 미니 브르트 | 중국어 | 중국 영어 pert | 중국 맥버트 | 중국 전자 | 중국어 xlnet | 중국 버트 | 지식 증류 도구 텍스트 브루어 | 모델 절단 도구 TextPruner
[2024/04/30] 중국어-알라 카카 -3은 공식적으로 석방되었으며, LLAMA-3을 기반으로 한 오픈 소스 LLAMA-3-CHINESE-8B 및 LLAMA-3-CHINESE-8B 비법과 함께 공식적으로 출시되었습니다. 모든 Phase One 및 Phase 2 프로젝트 사용자가 3 세대 모델로 업그레이드하는 것이 좋습니다. https://github.com/ymcui/chinese-llama-alpaca-3을 참조하십시오.
[2024/03/27]이 프로젝트는 Machine Sota의 중심부에 배치되었습니다! 모델 플랫폼, 오신 것을 환영합니다 : https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] 중국어-알라 카카 -2 v2.0 버전은 공식적으로 출시되었으며, 오픈 소스 중국어-롤라마 -2-13B 및 중국-알파카 -2-13B. 모든 1 단계 사용자가 2 세대 모델로 업그레이드하는 것이 좋습니다. https://github.com/ymcui/chinese-llama-alpaca-2를 참조하십시오.
[2023/07/31] 중국-롤라-알파카 -2 V1.0 버전은 공식적으로 출시되었습니다. https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] v5.0 버전 : Alpaca-Pro Series 모델을 릴리스하여 응답 길이와 품질을 크게 향상시킵니다. 동시에 Plus-33B 시리즈 모델을 출시하십시오.
[2023/07/19] 중국 LLAMA-2 및 ALPACA-2 오픈 소스 대형 모델 프로젝트를 시작하고 최신 정보에 대해 팔로우하고 배우는 것을 환영합니다.
[2023/07/10] 베타 테스트 미리보기, 미리 다가오는 업데이트에 대해 알아보십시오. 자세한 내용은 토론 영역을 참조하십시오.
[2023/07/07] 중국-알라 마라 카 가족은 다른 멤버를 추가하여 시각적 질문과 답변 및 대화를 위해 멀티 모달 중국어 라마 & 알파카 모델을 시작하고 7B 테스트 버전을 발표했습니다.
[2023/06/30] 8K LLAMA.CPP에 따른 8K 컨텍스트 지원 (모델에 대한 수정이 필요하지 않음). 관련 방법 및 토론은 토론 영역을 참조하십시오. 변압기에서 4K+ 컨텍스트를 지원하는 코드는 PR#705를 참조하십시오.
[2023/06/16] v4.1 버전 : 기술 보고서의 새 버전 출시, C-Eval Decoding Scripts 추가, 저주적 모델 병합 스크립트 등을 추가하십시오.
[2023/06/08] v4.0 버전 : 릴리스 중국어 llama/alpaca-33b 릴리스, PrivateGpt 사용 예제 추가, C-Eval 결과 추가 등을 추가하십시오.
| 장 | 설명하다 |
|---|---|
| model 다운로드 | 중국 라마와 알파카 대형 모델 다운로드 주소 |
| ? 모델을 병합하십시오 | (중요) 다운로드 된 LORA 모델을 오리지널 라마와 병합하는 방법을 소개하십시오. |
| 현지 추론 및 빠른 배치 | 개인 컴퓨터를 사용하여 모델을 정량화하고 대형 모델을 배포하고 경험하는 방법을 소개합니다. |
| ? 시스템 효과 | 일부 시나리오 및 작업에서 사용자 경험 효과가 소개됩니다. |
| 교육 세부 사항 | 중국 라마 및 알파카 모델의 교육 세부 사항을 소개했습니다. |
| faq | 일부 FAQ에 답장합니다 |
| 이 프로젝트에는 모델의 한계가 포함됩니다 |
Facebook이 공식적으로 발표 한 LLAMA 모델은 상업용 사용이 금지되며 공무원은 공식 오픈 소스 모델 가중치가 없습니다 (이미 인터넷에는 많은 타사 다운로드 주소가 있지만). 해당 권한을 준수하기 위해 여기에서 발표 된 LORA 가중치는 원래 LLAMA 모델에서 "패치"로 이해 될 수 있습니다. 두 사람은 전체 저작권을 얻기 위해 결합 할 수 있습니다. 다음 중국 라마/알파카 로라 모델은 단독으로 사용할 수 없으며 원래 라마 모델과 일치해야합니다. 모델을 재구성하려면이 프로젝트에 제공된 병합 모델 단계를 참조하십시오.
다음 그림은이 프로젝트와 두 번째 단계 프로젝트에서 시작한 모든 큰 모델 간의 관계를 보여줍니다.
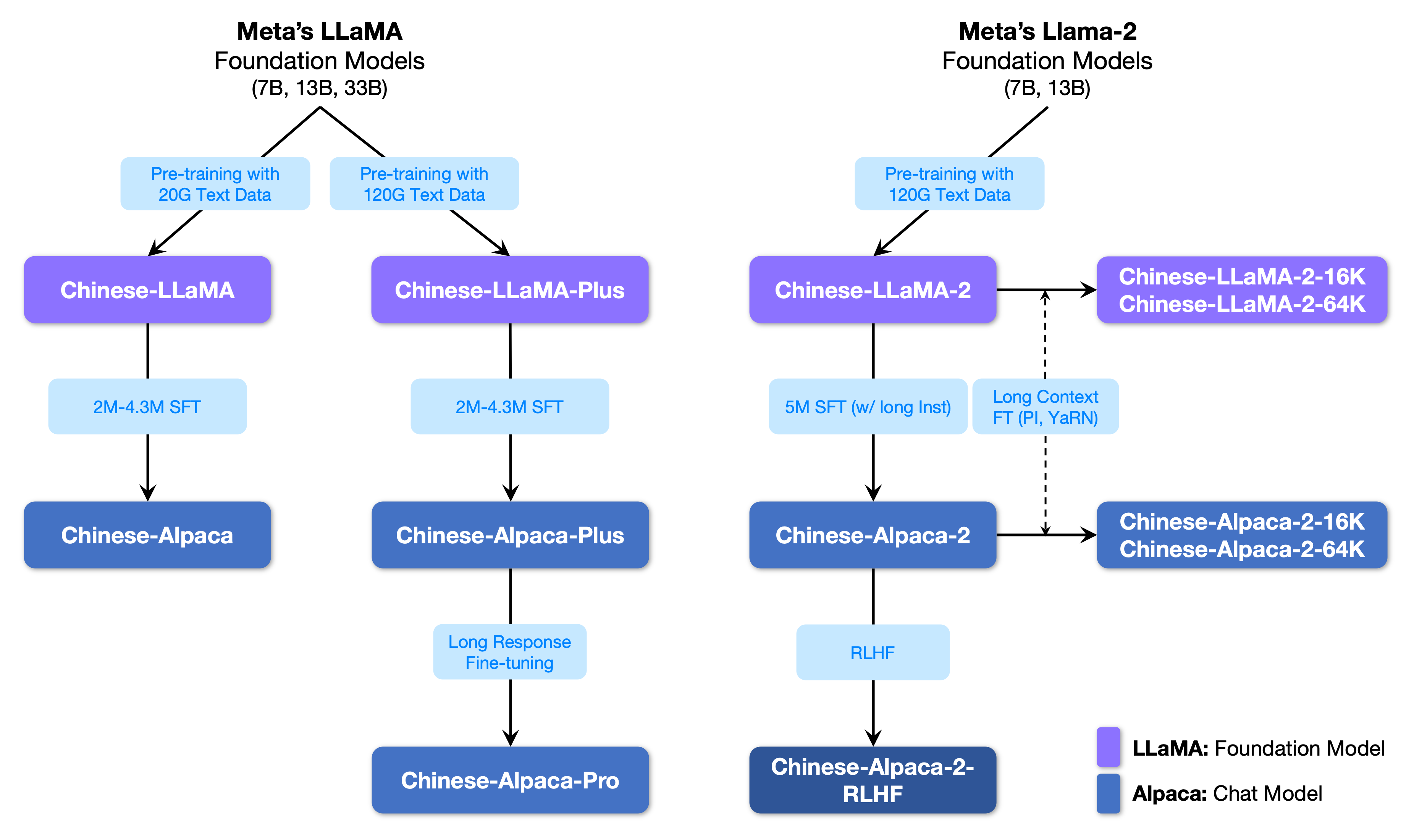
아래는 중국 라마 및 알파카 모델과 권장 사용 시나리오 (포함되지만 이에 국한되지 않음)의 기본 비교입니다. 자세한 내용은 교육 세부 정보를 참조하십시오.
| 비교 항목 | 중국 라마 | 중국 알파카 |
|---|---|---|
| 훈련 방법 | 전통적인 CLM | 지시 미세 조정 |
| 모델 유형 | 기본 모델 | 교육 이해 모델 (클래스 chatgpt) |
| 교육 자료 | 표시되지 않은 일반 에세이 | 라벨이 붙은 명령 데이터 |
| 어휘 크기 [3] | 4995 3 | 4995 4 = 49953+1 (패드 토큰) |
| 입력 템플릿 | 불필요한 | 템플릿 요구 사항을 충족해야합니다 [1] |
| 적용 가능한 시나리오 ios️ | 텍스트 연속 : 위의 내용이 주어지면 모델이 다음 텍스트를 생성하도록합니다. | 교육 이해 (질문과 답변, 글쓰기, 제안 등); 다소 라운드 컨텍스트 이해 (채팅 등) |
| 적용 할 수 없습니다 | 명령 이해, 여러 라운드의 채팅 등 | 무제한 텍스트 생성 |
| llama.cpp | -p 매개 변수를 사용하여 위를 지정하십시오 | -ins 매개 변수를 사용하여 지침 이해 + 채팅 모드를 시작하십시오. |
| 텍스트-세대-부이 | 채팅 모드에 적합하지 않습니다 | --cpu 사용하여 그래픽 카드없이 실행하십시오 |
| llamachat | 모델을로드 할 때 "LLAMA"를 선택하십시오 | 모델을로드 할 때 "알파카"를 선택하십시오 |
| HF 추론 코드 | 추가 시작 매개 변수가 필요하지 않습니다 | 시작시 매개 변수 추가 --with_prompt |
| 웹 데모 코드 | 적용 할 수 없습니다 | 알파카 모델 위치를 직접 제공하십시오. 여러 라운드의 대화를 지원합니다 |
| Langchain 예제/PrivateGpt | 적용 할 수 없습니다 | Alpaca 모델 위치를 직접 제공하십시오 |
| 알려진 문제 | 제어가 끝나지 않으면 상단 출력 길이 한계에 도달 할 때까지 계속 씁니다. [2] | Pro 버전을 사용하여 플러스 버전의 문제가 너무 짧지 않도록하십시오. |
[1] llama.cpp/llamachat/hf 추론 코드/웹 데모 코드/langchain 예제 등이 포함되어 있으므로 수동으로 템플릿을 추가 할 필요가 없습니다.
[2] 모델 답변 품질이 특히 낮거나 말도 안되거나 문제를 이해하지 못하면 올바른 모델 및 시작 매개 변수가 사용되는지 확인하십시오.
[3] 미세 조정 지침이 장착 된 알파카에는 라마보다 패드 토큰이 하나 더 있으므로 llama/alpaca 어휘 목록을 혼합하지 마십시오 .
다음은이 프로젝트에 권장되는 모델 목록입니다. 일반적으로 더 많은 교육 데이터와 최적화 된 모델 교육 방법 및 매개 변수가 사용됩니다. 이 모델에 우선 순위를 두십시오 (나머지 모델의 다른 모델 참조). ChatGpt 대화 상호 작용을 경험하려면 LLAMA 모델 대신 Alpaca 모델을 사용하십시오. Alpaca 모델의 경우 Pro 버전은 너무 짧은 응답 내용의 문제를 개선했으며 모델 응답 효과가 크게 향상되었습니다. 짧은 답변을 선호하는 경우 Plus 시리즈를 선택하십시오.
| 모델 이름 | 유형 | 교육 데이터 | 모델 재구성 [1] | 크기 [2] | 로라 다운로드 [3] |
|---|---|---|---|---|---|
| 중국어-플러스 -7b | 기본 모델 | 범용 120g | 원래 llama-7b | 790m | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국어-플러스 -13B | 기본 모델 | 범용 120g | 원래 llama-13b | 1.0g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국어-플러스 -33B? | 기본 모델 | 범용 120g | 원래 llama-33b | 1.3G [6] | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 프로-7B? | 교육 모델 | 지침 4.3m | 원래 llama-7b & llama-plus-7b [4] | 1.1g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -pro-13B? | 교육 모델 | 지침 4.3m | 원래 llama-13b & llama-plus-13b [4] | 1.3g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 프로-33B? | 교육 모델 | 지침 4.3m | 오리지널 라마 -33B & llama-plus-33b [4] | 2.1g | [Baidu] [Google] [? hf] [? ModelScope] |
[1] 리팩토링에는 원래 Llama 모델이 필요합니다. Llama 프로젝트로 이동하여 사용을 신청 하거나이 PR을 참조하십시오. 저작권 문제로 인해이 프로젝트는 다운로드 링크를 제공 할 수 없습니다.
[2] 재구성 된 모델 크기는 같은 크기의 원래 라마보다 큽니다 (주로 확장 된 어휘 목록으로 인해).
[3] 다운로드 후 압축 패키지의 모델 파일의 SHA256이 일관성이 있는지 확인하십시오. SHA256.md를 확인하십시오.
[4] Alpaca-Plus 모델은 해당 LLAMA-PLUS 모델을 동시에 다운로드해야합니다. Merge 자습서를 참조하십시오.
[5] 일부 장소는 그것을 30B라고 부르지 만 실제로 Facebook은 모델을 게시 할 때 잘못 썼 으며이 논문은 여전히 33B를 썼습니다.
[6] FP16 스토리지를 사용하여 모델 크기가 작습니다.
압축 패키지의 파일 디렉토리는 다음과 같습니다.
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
교육 방법 및 교육 데이터와 같은 요소로 인해 다음 모델을 더 이상 권장하지 않습니다 (특정 시나리오에서는 여전히 유용 할 수 있음) . 이전 섹션에서 권장 모델에 우선 순위를 두십시오.
| 모델 이름 | 유형 | 교육 데이터 | 모델을 리팩토링합니다 | 크기 | 로라 다운로드 |
|---|---|---|---|---|---|
| 중국어-7B | 기본 모델 | 일반 20g | 원래 llama-7b | 770m | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-줄라기 -13b | 기본 모델 | 일반 20g | 원래 llama-13b | 1.0g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국어-33b | 기본 모델 | 일반 20g | 원래 llama-33b | 2.7g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -7b | 교육 모델 | 지시 2m | 원래 llama-7b | 790m | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -13b | 교육 모델 | 지침 3m | 원래 llama-13b | 1.1g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -33b | 교육 모델 | 지침 4.3m | 원래 llama-33b | 2.8g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -plus-7b | 교육 모델 | 지침 4m | 원래 llama-7b & llama-plus-7b | 1.1g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -Plus-13B | 교육 모델 | 지침 4.3m | 원래 llama-13b & llama-plus-13b | 1.3g | [Baidu] [Google] [? hf] [? ModelScope] |
| 중국-알파카 -plus-33b | 교육 모델 | 지침 4.3m | 오리지널 라마 -33B & llama-plus-33b | 2.1g | [Baidu] [Google] [? hf] [? ModelScope] |
위의 모든 모델은 Model Hub에서 다운로드 할 수 있으며 중국 라마 또는 Alpaca Lora 모델은 변압기 및 PEFT를 사용하여 호출 할 수 있습니다. 다음 모델 호출 이름은 .from_pretrained() 에 지정된 모델 이름을 나타냅니다.
자세한 목록 및 모델 다운로드 주소 : https://huggingface.co/hfl
앞에서 언급했듯이 LORA 모델은 단독으로 사용될 수 없으며 원래 LLAMA와 병합되어 모델 추론, 정량화 또는 추가 교육을위한 완전한 모델로 변환되어야합니다. 모델을 변환하고 병합하려면 다음 방법을 선택하십시오.
| 방법 | 해당 시나리오 | 지도 시간 |
|---|---|---|
| 온라인 변환 | Colab 사용자는이 프로젝트에서 제공하는 노트북을 사용하여 온라인을 전환하고 모델을 정량화 할 수 있습니다. | 링크 |
| 수동 변환 | 오프라인 변환, 양자화 또는 추가 개선을 위해 다른 형식의 모델을 생성합니다. | 링크 |
다음은 모델을 병합 한 후 FP16 정밀 및 4 비트 양자화 크기입니다. 전환하기 전에 기계에 충분한 메모리 및 디스크 공간이 있는지 확인하십시오 (최소 요구 사항).
| 모델 버전 | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| 원래 모델 크기 (FP16) | 13GB | 24GB | 60GB | 120GB |
| 양자 크기 (8 비트) | 7.8 GB | 14.9 GB | 32.4 GB | ~ 60GB |
| 양자 크기 (4 비트) | 3.9 GB | 7.8 GB | 17.2GB | 38.5GB |
자세한 내용은이 프로젝트를 참조하십시오 >>> Github Wiki
이 프로젝트의 모델은 주로 다음의 정량화, 추론 및 배치 방법을 지원합니다.
| 추론 및 배치 방법 | 특징 | 플랫폼 | CPU | GPU | 정량적 하중 | 그래픽 인터페이스 | 지도 시간 |
|---|---|---|---|---|---|---|---|
| llama.cpp | 풍부한 양적 옵션과 효율적인 지역 추론 | 일반적인 | ✅ | ✅ | ✅ | 링크 | |
| ? 변압기 | 기본 변압기 추론 인터페이스 | 일반적인 | ✅ | ✅ | ✅ | ✅ | 링크 |
| 텍스트-세대-부이 | 프론트 엔드 웹 UI 인터페이스를 배포하는 방법 | 일반적인 | ✅ | ✅ | ✅ | ✅ | 링크 |
| llamachat | MACOS의 그래픽 대화식 인터페이스 | 마코스 | ✅ | ✅ | ✅ | 링크 | |
| 랭케인 | LLM 응용 프로그램 개발 프레임 워크, 2 차 개발에 적합합니다 | 일반적인 | ✅ † | ✅ | ✅ † | 링크 | |
| PrivateGpt | Langchain을 기반으로 한 멀티 문서 지역 질문 및 답변 프레임 워크 | 일반적인 | ✅ | ✅ | ✅ | 링크 | |
| Colab Gradio 데모 | Colab에서 대화식 그라디오 기반 웹 서비스를 시작하십시오 | 일반적인 | ✅ | ✅ | ✅ | 링크 | |
| API 호출 | OpenAI API 인터페이스를 에뮬레이션하는 서버 데모 | 일반적인 | ✅ | ✅ | ✅ | 링크 |
† : Langchain 프레임 워크는이를 지원하지만 자습서에는 구현되지 않습니다. 자세한 내용은 공식 Langchain 문서를 참조하십시오.
자세한 내용은이 프로젝트를 참조하십시오 >>> Github Wiki
동일한 Propt가 주어지면 관련 모델의 실제 텍스트 생성 성능을 신속하게 평가하기 위해이 프로젝트 에서이 프로젝트에서 중국 알파카 -7B, 중국 알파카 -33B, 중국 알파카 -PLUS-7B 및 중국 알파카 -PLUS-13B의 효과를 비교하고 테스트했습니다. 응답 생성은 무작위이며 하이퍼 파라미터 및 임의의 종자 디코딩과 같은 요인의 영향을받습니다. 다음과 관련된 검토는 절대적으로 엄격하지 않습니다. 테스트 결과는 건조 참조 전용입니다. 직접 경험할 수 있습니다.
이 프로젝트는 또한 "NLU"의 객관적인 평가 세트에서 관련 모델을 테스트했습니다. 이러한 유형의 평가 결과는 주관적이지 않으며 주어진 태그의 출력 만 필요하므로 (태그 매핑 전략을 설계해야 함) 다른 관점에서 큰 모델의 기능을 이해할 수 있습니다. 이 프로젝트는 최근에 출시 된 C-Eval Evaluation DataSet에 대한 관련 모델의 효과를 테스트했으며, 여기에는 12.3K 객관식 문제가 포함되어 있으며 52 명의 피험자를 다루었습니다. 다음은 일부 모델의 유효한 테스트 세트 평가 결과 (평균)입니다. 전체 결과는 기술 보고서를 참조하십시오.
| 모델 | 유효한 (제로 샷) | 유효한 (5- 샷) | 테스트 (제로 샷) | 테스트 (5- 샷) |
|---|---|---|---|---|
| 중국-알파카 -plus-33b | 46.5 | 46.3 | 44.9 | 43.5 |
| 중국-알파카 -33b | 43.3 | 42.6 | 41.6 | 40.4 |
| 중국-알파카 -Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| 중국-알파카 -plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| 중국어-플러스 -33b | 37.4 | 40.0 | 35.7 | 38.3 |
| 중국어-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| 중국어-플러스 -13B | 27.3 | 34.0 | 27.8 | 33.3 |
| 중국어-플러스 -7b | 27.3 | 28.3 | 26.9 | 28.4 |
큰 모델의 능력에 대한 포괄적 인 평가는 여전히 긴급하게 해결 해야하는 중요한 문제라는 점에 유의해야합니다. 큰 모델과 관련된 다양한 평가 결과에 대한 합리적이고 변증 법적 견해는 큰 모델 기술의 건강한 개발에 도움이 될 것입니다. 사용자는 관련 작업에 대해 관심있는 작업을 테스트하고 관련 작업에 적응하는 모델을 선택하는 것이 좋습니다.
C-Eval 추론 코드 >>> Github Wiki는이 프로젝트를 참조하십시오.
전체 교육 과정에는 어휘 확장, 사전 훈련 및 교육용 미세 조정의 세 부분이 포함됩니다.
자세한 내용은이 프로젝트를 참조하십시오 >>> Github Wiki
FAQ에는 자주 묻는 질문이 주어집니다. 문제를 묻기 전에 FAQ를 확인하십시오.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
특정 질문과 답변은이 프로젝트를 참조하십시오 >>> Github Wiki
이 프로젝트의 모델에는 특정 중국의 이해 및 세대 기능이 있지만 다음과 같은 제한 사항도 있습니다.
이 프로젝트가 귀하의 연구에 도움이 되거나이 프로젝트의 코드 또는 데이터를 사용한다고 생각되면이 프로젝트를 인용하는 기술 보고서를 참조하십시오 : https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| 프로젝트 이름 | 소개 | 유형 |
|---|---|---|
| 중국어-알파카 -2 (공식 프로젝트) | 중국 llama-2, Alpaca-2 큰 모델 | 텍스트 |
| 시각-중국어-알파카 (공식 프로젝트) | 멀티 모달 중국어 라마 & 알파카 큰 모델 | 멀티 모달 |
목록에 참여하고 싶습니까? >>> 신청서를 제출하십시오
이 프로젝트는 다음 오픈 소스 프로젝트의 2 차 개발을 기반으로합니다. 관련 프로젝트 및 연구 개발 직원에게 감사를 표하고 싶습니다.
| 기본 모델, 코드 | 정량화, 추론, 배포 | 데이터 |
|---|---|---|
| Facebook의 llama 스탠포드의 알파카 @tloen의 Alpaca-Lora | @ggerganov의 llama.cpp @alexrozanski의 llamachat @oobabooga의 텍스트-세대 webui | @BrightMart의 PCLUE 및 MT 데이터 OpenAsistant에 의한 OASST1 |
이 프로젝트와 관련된 자료는 학업 연구를위한 것이며 상업적 목적으로 엄격하게 금지되어 있습니다. 타사 코드와 관련된 부품을 사용하는 경우 해당 오픈 소스 프로토콜을 엄격히 따르십시오. 모델에 의해 생성 된 내용은 모델 계산, 임의성 및 정량적 정확도 손실과 같은 요소의 영향을받습니다. 이 프로젝트는 정확도를 보장하지 않습니다. 이 프로젝트는 모델의 컨텐츠 출력에 대한 법적 책임을지지 않으며 관련 리소스 및 출력 결과를 사용하여 발생할 수있는 손실에 대해 책임을지지 않습니다. 이 프로젝트는 여가 시간에 개인과 공동 작업자가 시작하고 유지하므로 해당 문제를 해결하기 위해 신속하게 응답 할 수 있음을 보장하는 것은 불가능합니다.
궁금한 점이 있으면 GitHub 문제로 제출하십시오. 정중하게 질문하고 조화로운 토론 커뮤니티를 구축하십시오.


