Chinese LLaMA Alpaca
v5.0
?? chino | Inglés | Documentos/documentos | ❓ Preguntas/problemas | Discusiones/discusiones | ⚔️ Arena/Arena

Este proyecto de código abierto , el modelo de Llama China y el modelo de Alpaca ajustado a instrucciones para promover aún más la investigación abierta del gran modelo en la comunidad china de la PNL. Estos modelos han ampliado la lista de vocabulario chino basada en la llama original y utilizaron datos chinos para la pre-entrenamiento secundario, mejorando aún más la capacidad de comprensión semántica básica de los chinos. Al mismo tiempo, el modelo de Alpaca chino utiliza aún más los datos de instrucciones chinos para un ajuste fino, lo que mejora significativamente las capacidades de comprensión y ejecución del modelo de instrucciones.
Informe técnico (V2) : [CUI, Yang y Yao] Codificación de texto eficiente y efectivo para Llama y Alpaca chinos
Contenido principal de este proyecto:
La siguiente figura muestra la velocidad y el efecto de la experiencia real del modelo chino Alpaca-plus-7b después del despliegue cuantitativo de CPU local.
Chinese Llama-2 y Alpaca-2 Big Model | Llama chino multimodal y alpaca Big Model | VLE multimodal | Minirbt chino | Lert chino | Inglés chino Pert | Macbert chino | Electra chino | Chino xlnet | Bert chino | Herramienta de destilación de conocimiento TextBrewer | Herramienta de corte de modelos Pruner de texto
[2024/04/30] chino-llama-alpaca-3 se ha publicado oficialmente, con código abierto LLAMA-3-Chinese-8B y Llama-3-Chinese-8B-Instructo basado en LLAMA-3. Se recomienda que todos los usuarios de proyectos de fase uno y fase dos se actualicen al modelo de tercera generación, consulte: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] ¡Este proyecto se ha desplegado en el corazón de la máquina Sota! Plataforma modelo, bienvenido a seguir: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] La versión china-llama-alpaca-2 v2.0 ha sido lanzada oficialmente, código abierto chino-llama-2-13b y chino-alpaca-2-13b. Se recomienda que todos los usuarios de primera fase se actualicen al modelo de segunda generación, consulte: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/31] La versión china-llama-alpaca-2 v1.0 ha sido lanzada oficialmente, consulte: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] V5.0 Versión: libera el modelo de la serie Alpaca-Pro, mejorando significativamente la longitud y la calidad de la respuesta; Al mismo tiempo, lanze el modelo de serie Plus-33B.
[2023/07/19] Lanzan los proyectos modelo de código abierto de Llama-2 y Alpaca-2, bienvenidos para seguir y aprender sobre la información más reciente.
[2023/07/10] Vista previa de la prueba beta, aprenda sobre las próximas actualizaciones de antemano: consulte el área de discusión para más detalles
[2023/07/07] La familia china-llama-alpaca ha agregado a otro miembro, lanzando un modelo multimodal de Llama y Alpaca para preguntas y respuestas y diálogo visuales, y ha lanzado una versión de prueba de 7B.
[2023/06/30] Soporte de contexto de 8K bajo Llama.cpp (no se requiere modificación al modelo). Consulte el área de discusión para obtener métodos y discusiones relacionados; Consulte PR#705 para obtener códigos que admitan 4K+ contexto en Transformers.
[2023/06/16] V4.1 Versión: Libera una nueva versión del informe técnico, agregue scripts de decodificación C-EVAL, agregue scripts de combinación de modelo de baja recursos, etc.
[2023/06/08] V4.0 Versión: Release Chinese Llama/Alpaca-33B, agregue ejemplos de uso privadoGPT, agregue resultados C-Eval, etc.
| capítulo | describir |
|---|---|
| ⏬ Descarga del modelo | Dirección de descarga de modelos de Llama Chinese y Alpaca |
| ? Fusionar el modelo | (Importante) Presente cómo fusionar el modelo Lora descargado con la Llama original |
| Razonamiento local y implementación rápida | Presenta cómo cuantificar modelos e implementar y experimentar modelos grandes utilizando una computadora personal |
| ? Efectos del sistema | Se introduce el efecto de experiencia del usuario en algunos escenarios y tareas |
| Detalles de capacitación | Introdujo los detalles de capacitación de los modelos de Llama y Alpaca. |
| ❓faq | Responde a algunas preguntas frecuentes |
| Este proyecto implica limitaciones del modelo |
El modelo LLAMA publicado oficialmente por Facebook está prohibido por el uso comercial, y el funcionario no tiene pesos oficiales de modelos de código abierto (aunque ya hay muchas direcciones de descarga de terceros en Internet). Para cumplir con el permiso correspondiente, los pesos Lora liberados aquí pueden entenderse como un "parche" en el modelo de llama original. Los dos se pueden combinar para obtener los derechos de autor completos. El siguiente modelo chino de Llama/Alpaca Lora no se puede usar solo y debe combinarse con el modelo de llamas original. Consulte los pasos del modelo de fusión dados en este proyecto para reconstruir el modelo.
La siguiente figura muestra la relación entre este proyecto y todos los grandes modelos lanzados por el proyecto de la segunda fase.
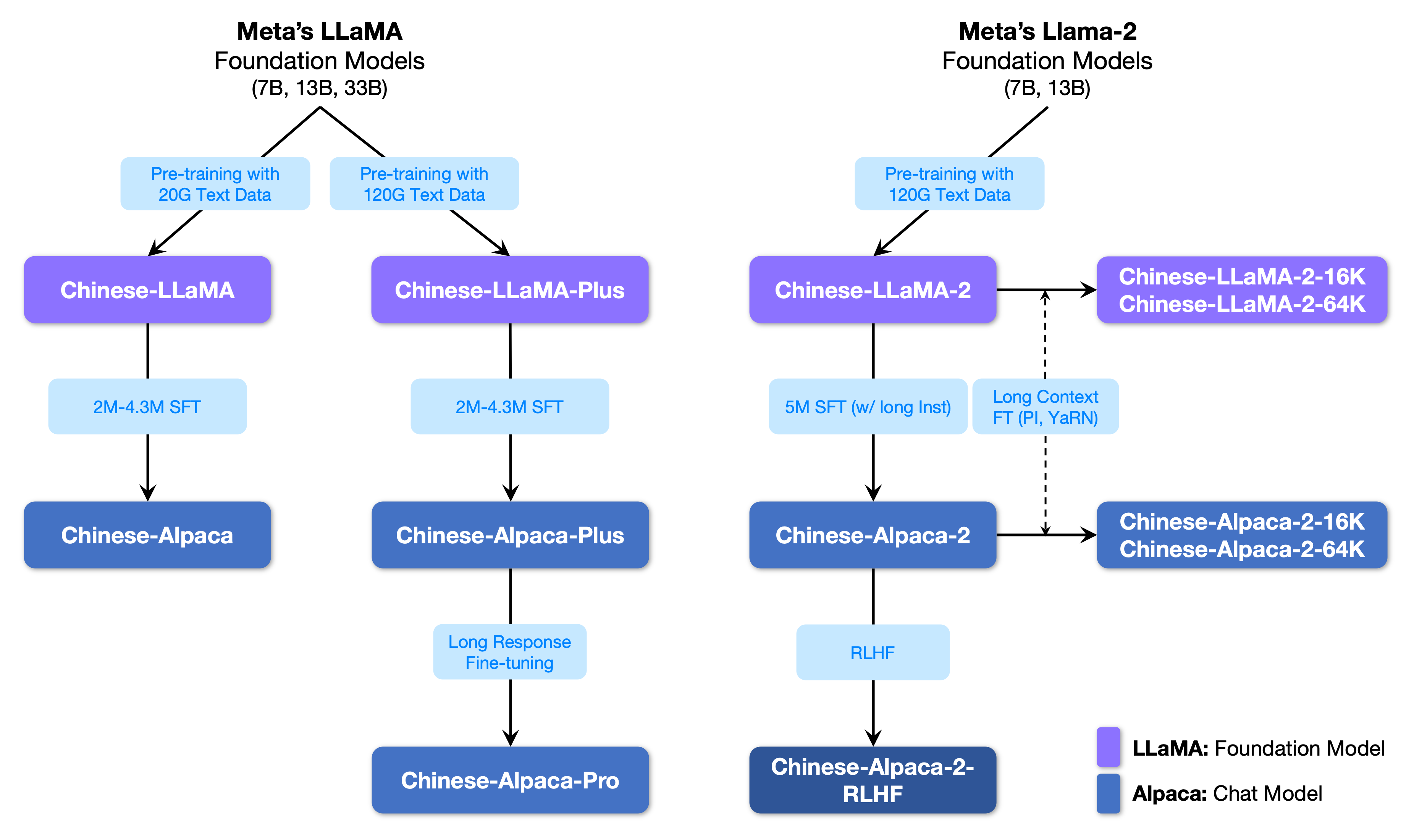
A continuación se muestra una comparación básica de los modelos de Llama y Alpaca chinos y escenarios de uso recomendados (incluidos, entre otros). Para obtener más información, consulte los detalles de la capacitación.
| Elementos de comparación | Llama chino | Alpaca china |
|---|---|---|
| Método de entrenamiento | CLM tradicional | Instrucción Ajuste fino |
| Tipo de modelo | Modelo base | Modelo de comprensión de instrucciones (ChatGPT de clase) |
| Materiales de capacitación | Ensayo general sin marcar | Datos de instrucciones etiquetados |
| Tamaño del vocabulario [3] | 4995 3 | 4995 4 = 49953+1 (token de almohadilla) |
| Plantilla de entrada | innecesario | Necesita cumplir con los requisitos de la plantilla [1] |
| Escenarios aplicables ✔️ | Continuación de texto: dado el contenido anterior, deje que el modelo genere el siguiente texto | Comprensión de instrucciones (preguntas y respuestas, escritura, sugerencias, etc.); Comprensión de contexto de múltiples rondas (chat, etc.) |
| No aplicable | Comprensión de comandos, múltiples rondas de chat, etc. | Generación de texto ilimitada |
| llama.cpp | Use el parámetro -p para especificar lo anterior | Use el parámetro -ins para iniciar el modo de comprensión de instrucciones + chat |
| Webui de texto de texto | No es adecuado para el modo de chat | Usar --cpu para ejecutar sin tarjeta gráfica |
| Pilón | Seleccione "Llama" al cargar el modelo | Seleccione "Alpaca" al cargar el modelo |
| Código de inferencia HF | No se requieren parámetros de inicio adicionales | Agregar parámetros al inicio --with_prompt |
| código web-demo | no aplicable | Simplemente proporcione la posición del modelo Alpaca directamente; apoyar múltiples rondas de conversaciones |
| Ejemplo de langchain/privategpt | no aplicable | Simplemente proporcione la ubicación del modelo de Alpaca directamente |
| Problemas conocidos | Si ningún control termina, continuará escribiendo hasta alcanzar el límite de longitud de salida superior. [2] | Utilice la versión PRO para evitar que el problema de la versión más sea demasiado corto. |
[1] Llama.cpp/Llamachat/HF Código de inferencia/código de demo web/ejemplos de cadena de lang, etc. están integrados, no es necesario agregar plantillas manualmente.
[2] Si la calidad de la respuesta del modelo es particularmente baja, sin sentido o no comprende el problema, verifique si se utilizan el modelo correcto y los parámetros de inicio.
[3] Alpaca con instrucciones ajustadas tendrá un token de almohadilla más que LLAMA, así que no mezcle la lista de vocabulario LLAMA/Alpaca .
La siguiente es una lista de modelos recomendados para este proyecto. Por lo general, se utilizan más datos de entrenamiento y métodos y parámetros optimizados de entrenamiento de modelos. Por favor, dé prioridad a estos modelos (consulte otros modelos para el resto de los modelos). Si desea experimentar la interacción del diálogo ChatGPT, utilice el modelo Alpaca en lugar del modelo LLAMA. Para el modelo Alpaca, la versión Pro ha mejorado el problema del contenido de respuesta que es demasiado corto, y el efecto de respuesta del modelo ha mejorado significativamente; Si prefiere respuestas cortas, seleccione la serie Plus.
| Nombre del modelo | tipo | Datos de capacitación | Reconstruyendo el modelo [1] | Tamaño [2] | Descargar Lora [3] |
|---|---|---|---|---|---|
| Chino-llama-plus-7b | Modelo base | Propósito general 120G | Llama-7b original | 790m | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-llama-plus-13b | Modelo base | Propósito general 120G | Llama-13b original | 1.0g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-llama-plus-33b? | Modelo base | Propósito general 120G | Llama-33b original | 1.3g [6] | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-Pro-7b? | Modelo de instrucción | Instrucción 4.3m | LLAMA-7B ORIGINAL Y Llama-plus-7b [4] | 1.1G | [Baidu] [Google] [? Hf] [? Modelscope] |
| China-Alpaca-Pro-13b? | Modelo de instrucción | Instrucción 4.3m | LLAMA-13B ORIGINAL Y Llama-plus-13b [4] | 1.3g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-pro-33b? | Modelo de instrucción | Instrucción 4.3m | LLAMA-33B ORIGINAL Y Llama-plus-33b [4] | 2.1G | [Baidu] [Google] [? Hf] [? Modelscope] |
[1] La refactorización requiere el modelo de llama original, vaya al proyecto LLAMA para solicitar su uso o consulte este PR. Debido a problemas de derechos de autor, este proyecto no puede proporcionar un enlace de descarga.
[2] El tamaño del modelo reconstruido es más grande que la llama original de la misma magnitud (principalmente debido a la lista de vocabulario expandido).
[3] Después de descargar, asegúrese de verificar si el SHA256 del archivo modelo en el paquete comprimido es consistente. Consulte SHA256.MD.
[4] El modelo ALPACA-PLUS necesita descargar el modelo Llama-Plus correspondiente al mismo tiempo, consulte el tutorial de fusión.
[5] Algunos lugares lo llaman 30B, pero de hecho Facebook lo escribió erróneamente al publicar el modelo, y el documento todavía escribió 33B.
[6] Use el almacenamiento FP16, por lo que el tamaño del modelo es pequeño.
El directorio de archivos en el paquete comprimido es el siguiente (tomar chino-llama-7b como ejemplo):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Debido a factores como métodos de entrenamiento y datos de capacitación, los siguientes modelos ya no se recomiendan (aún pueden ser útiles en escenarios específicos) . Da prioridad a los modelos recomendados en la sección anterior.
| Nombre del modelo | tipo | Datos de capacitación | Refactorizar el modelo | tamaño | Descarga de Lora |
|---|---|---|---|---|---|
| Chino-llama-7b | Modelo base | General 20g | Llama-7b original | 770m | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-llama-13b | Modelo base | General 20g | Llama-13b original | 1.0g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-llama-33b | Modelo base | General 20g | Llama-33b original | 2.7g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-7b | Modelo de instrucción | Instrucción 2m | Llama-7b original | 790m | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-13b | Modelo de instrucción | Instrucción 3m | Llama-13b original | 1.1G | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-33b | Modelo de instrucción | Instrucción 4.3m | Llama-33b original | 2.8g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-plus-7b | Modelo de instrucción | Instrucción 4m | LLAMA-7B ORIGINAL Y Llama-plus-7b | 1.1G | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-plus-13b | Modelo de instrucción | Instrucción 4.3m | LLAMA-13B ORIGINAL Y Llama-plus-13b | 1.3g | [Baidu] [Google] [? Hf] [? Modelscope] |
| Chino-alpaca-plus-33b | Modelo de instrucción | Instrucción 4.3m | LLAMA-33B ORIGINAL Y Llama-plus-33b | 2.1G | [Baidu] [Google] [? Hf] [? Modelscope] |
Todos los modelos anteriores se pueden descargar en Model Hub y los modelos chinos Llama o Alpaca Lora se pueden llamar usando Transformers y PEFT. El siguiente nombre de llamada del modelo se refiere al nombre del modelo especificado en .from_pretrained() .
Dirección de descarga de la lista detallada y del modelo: https://huggingface.co/hfl
Como se mencionó anteriormente, el modelo Lora no se puede usar solo y debe fusionarse con la llama original para convertirse en un modelo completo para la inferencia del modelo, la cuantificación o la capacitación adicional. Seleccione el siguiente método para convertir y fusionar el modelo.
| Forma | Escenarios aplicables | Tutorial |
|---|---|---|
| Conversión en línea | Los usuarios de Colab pueden usar el cuaderno proporcionado por este proyecto para convertir los modelos en línea y cuantificar. | Enlace |
| Conversión manual | Convierta fuera de línea, genere modelos en diferentes formatos para cuantización o refinamiento adicional | Enlace |
El siguiente es la precisión FP16 y el tamaño de cuantización de 4 bits después de fusionar el modelo. Asegúrese de que la máquina tenga suficiente espacio de memoria y disco antes de la conversión (requisitos mínimos):
| Versión modelo | 7b | 13B | 33b | 65b |
|---|---|---|---|---|
| Tamaño del modelo original (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| Tamaño cuantificado (8 bits) | 7.8 GB | 14.9 GB | 32.4 GB | ~ 60 GB |
| Tamaño cuantificado (4 bits) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
Para más detalles, consulte este proyecto >>> Wiki Github
Los modelos en este proyecto admiten principalmente los siguientes métodos de cuantificación, razonamiento e implementación.
| Métodos de razonamiento e implementación | Características | plataforma | UPC | GPU | Carga cuantitativa | Interfaz gráfica | Tutorial |
|---|---|---|---|---|---|---|---|
| llama.cpp | Opciones cuantitativas ricas y razonamiento local eficiente | General | ✅ | ✅ | ✅ | enlace | |
| ? Transformadores | Interfaz de inferencia de transformadores nativos | General | ✅ | ✅ | ✅ | ✅ | enlace |
| Webui de texto de texto | Cómo implementar la interfaz de interfaz de usuario web front-end | General | ✅ | ✅ | ✅ | ✅ | enlace |
| Pilón | Interfaz interactiva gráfica en macOS | Macosa | ✅ | ✅ | ✅ | enlace | |
| Langchain | Marco de desarrollo de aplicaciones LLM, adecuado para el desarrollo secundario | General | ✅ † | ✅ | ✅ † | enlace | |
| privategpt | Marco de preguntas y respuestas locales multi-documentos basado en Langchain | General | ✅ | ✅ | ✅ | enlace | |
| Demo de Colab Gradio | Iniciar un servicio web interactivo basado en Gradio en Colab | General | ✅ | ✅ | ✅ | enlace | |
| Llamadas de API | Demostración del servidor que emula la interfaz API de OpenAI | General | ✅ | ✅ | ✅ | enlace |
† : El marco Langchain lo admite, pero no se implementa en el tutorial; Consulte la documentación oficial de Langchain para obtener más detalles.
Para más detalles, consulte este proyecto >>> Wiki Github
Para evaluar rápidamente el rendimiento real de la generación de texto de los modelos relevantes, dado el mismo PropT, este proyecto comparó y probó los efectos de Alpaca-7B chino, AlpACA-13B chino, Alpaca-33B chino, Alpaca-Plus-7B chino y Alpaca-PLUS-13B chino en este proyecto en algunas tareas comunes. La generación de la respuesta es aleatoria y se ve afectada por factores como la decodificación de hiperparámetros y semillas aleatorias. Las siguientes revisiones relacionadas no son absolutamente rigurosas. Los resultados de la prueba son solo para referencia de secado. Eres bienvenido a experimentarlo tú mismo.
Este proyecto también probó los modelos relevantes en el conjunto de evaluación objetiva de "NLU". Los resultados de este tipo de evaluación no son subjetivos, y solo requieren la salida de una etiqueta dada (la estrategia de mapeo de etiquetas debe ser diseñada), por lo que puede comprender las capacidades del modelo grande desde otra perspectiva. Este proyecto probó los efectos de los modelos relacionados en el conjunto de datos de evaluación C-EVAL recientemente lanzado, que contenía 12.3k preguntas de opción múltiple y cubría 52 sujetos. Los siguientes son los resultados de evaluación válidos y del conjunto de pruebas (promedio) de algunos modelos. Consulte el informe técnico para obtener los resultados completos.
| Modelo | Válido (disparo cero) | Válido (5-shot) | Prueba (cero-shot) | Prueba (5-shot) |
|---|---|---|---|---|
| Chino-alpaca-plus-33b | 46.5 | 46.3 | 44.9 | 43.5 |
| Chino-alpaca-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| Chino-alpaca-plus-13b | 43.3 | 42.4 | 41.5 | 39.9 |
| Chino-alpaca-plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| Chino-llama-plus-33b | 37.4 | 40.0 | 35.7 | 38.3 |
| Chino-llama-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| Chino-llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| Chino-llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Cabe señalar que la evaluación integral de la capacidad de los grandes modelos sigue siendo un problema importante que debe resolverse con urgencia. Una visión razonable y dialéctica de varios resultados de evaluación relacionados con grandes modelos ayudará al desarrollo saludable de la gran tecnología de modelos. Se recomienda que los usuarios prueben en las tareas que les preocupa y seleccione modelos que se adapten a las tareas relacionadas.
Consulte este proyecto para el código de inferencia C-Eval >>> Wiki GitHub
Todo el proceso de entrenamiento incluye tres partes: expansión de vocabulario, pre-entrenamiento e instrucción FINA Ajuste.
Para más detalles, consulte este proyecto >>> Wiki Github
Las preguntas frecuentes se le da una pregunta frecuente. Consulte las preguntas frecuentes antes de pedir un problema.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Consulte este proyecto para detectar preguntas y respuestas específicas >>> Github Wiki
Aunque los modelos en este proyecto tienen ciertas capacidades de comprensión y generación china, también tienen limitaciones, incluidas, entre otros::
Si cree que este proyecto es útil para su investigación o usa el código o los datos de este proyecto, consulte el informe técnico que cita este proyecto: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Nombre del proyecto | Introducción | tipo |
|---|---|---|
| Chino-llama-alpaca-2 (proyecto oficial) | Llama-2 chino, Alpaca-2 Big Model | texto |
| Visual-Chinese-Llama-Alpaca (proyecto oficial) | Llama chino multimodal y alpaca gran modelo | Multimodal |
¿Quieres unirte a la lista? >>> Envíe una solicitud
Este proyecto se basa en el desarrollo secundario de los siguientes proyectos de código abierto. Me gustaría expresar mi gratitud a los proyectos relevantes y al personal de investigación y desarrollo.
| Modelo básico, código | Cuantificación, razonamiento, implementación | datos |
|---|---|---|
| LLAMA de Facebook Alpaca por Stanford Alpaca-lora de @tloen | llama.cpp por @ggerganov Llamachat por @alexrozanski Generación de texto-webui por @oobabooga | Datos de PCLUE y MT por @BrightMart Oasst1 por OpenSistant |
Los recursos relacionados con este proyecto son solo para la investigación académica y están estrictamente prohibidas para fines comerciales. Al usar piezas que involucran código de terceros, siga estrictamente el protocolo de código abierto correspondiente. El contenido generado por el modelo se ve afectado por factores como el cálculo del modelo, la aleatoriedad y las pérdidas cuantitativas de precisión. Este proyecto no garantiza su precisión. Este proyecto no asume ninguna responsabilidad legal por la producción de contenido por parte del modelo, ni es responsable de las pérdidas que puedan surgir del uso de recursos relevantes y resultados de salida. Este proyecto es iniciado y mantenido por individuos y colaboradores en su tiempo libre, por lo que es imposible garantizar que puedan responder rápidamente para resolver los problemas correspondientes.
Si tiene alguna pregunta, envíelo en el problema de GitHub. Haga preguntas cortésmente y cree una comunidad de discusión armoniosa.


