Chinese LLaMA Alpaca
v5.0
؟؟ الصينية | الإنجليزية | المستندات/المستندات | ❓ الأسئلة/القضايا | المناقشات/المناقشات | ⚔ الساحة/الساحة

هذا المشروع مفتوح المصدر: نموذج LLAMA الصيني ونموذج الألبكة الذي تم ضبطه للتعليمات لزيادة الترويج للبحث المفتوح للنموذج الكبير في مجتمع NLP الصيني. قامت هذه النماذج بتوسيع قائمة المفردات الصينية بناءً على LLAMA الأصلي واستخدمت البيانات الصينية للتدريب الثانوي ، مما يؤدي إلى تحسين قدرة الفهم الدلالي الأساسي للصينيين. في الوقت نفسه ، يستخدم نموذج الألبكة الصيني بيانات التعليمات الصينية أيضًا من أجل التعديل الدقيق ، مما يحسن بشكل كبير من إمكانيات تعليمات الفهم والتنفيذ للنموذج.
التقرير الفني (V2) : [CUI ، Yang ، and Yao] ترميز نص فعال وفعال لـ Llama و Alpaca الصيني
المحتوى الرئيسي لهذا المشروع:
يوضح الشكل أدناه سرعة التجربة الفعلية وتأثير نموذج الألبكة الصيني-7 ب بعد النشر الكمي لمجهزة وحدة المعالجة المركزية المحلية.
الصينية LAMA-2 و Alpaca-2 نموذج كبير | متعددة الوسائط الصينية لاما ولباكا نموذج كبير | متعدد الوسائط Vle | الصينية minirbt | ليرت الصينية | اللغة الإنجليزية الصينية بيرت | صينية ماكبرت | إلكترا الصينية | صينية XLNET | بيرت الصينية | أداة التقطير المعرفة TextBrewer | أداة قطع النموذج TextPruner
[2024/04/30] تم إصدار الصينية-الللام-Alpaca-3 رسميًا ، مع المصدر المفتوح LAMA-3-Chinese-8B و LLAMA-3-CHINESE-8B-instruct على أساس LLAMA-3. يوصى بترقية جميع مستخدمي المرحلة الأولى والمرحلة الثانية إلى طراز الجيل الثالث ، يرجى الرجوع إلى: https://github.com/ymcui/Chinese-lama-alpaca-3
[2024/03/27] تم نشر هذا المشروع في قلب آلة سوتا! منصة النموذج ، مرحبًا بك في متابعة: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] تم إصدار نسخة صينية-بلاما-ألباكا -2 V2.0 رسمياً ، مفتوح المصدر الصيني-لاما 2-13B والصينية-ALPACA-2-13B. يوصى بترقية جميع مستخدمي المرحلة الأولى إلى نموذج الجيل الثاني ، يرجى الرجوع إلى: https://github.com/ymcui/Chinese-lam-alpaca-2
[2023/07/31] تم إصدار نسخة صينية-ملاما-ألباكا -2 V1.0 رسميًا ، يرجى الرجوع إلى: https://github.com/ymcui/Chinese-llama-alpaca-2
[2023/07/19] الإصدار V5.0: حرر نموذج سلسلة الألباكا-برو ، مما يحسن بشكل كبير طول الرد والجودة ؛ في الوقت نفسه ، حرر نموذج سلسلة Plus-33b.
[2023/07/19] قم بإطلاق مشاريع LLAMA-2 و Alpaca-2 المفتوحة المصدر المفتوحة ، مرحبًا بك في متابعة أحدث المعلومات.
[2023/07/10] معاينة اختبار بيتا ، تعرف على التحديثات القادمة مقدمًا: راجع منطقة المناقشة للحصول على التفاصيل
[2023/07/07] أضافت عائلة الصينية اللاما-ألباكا عضوًا آخر ، حيث أطلقت نموذجًا متعدد الوسائط لاما وألباكا للأسئلة المرئية والإجابة والحوار ، وأصدرت نسخة اختبار 7B.
[2023/06/30] دعم سياق 8K تحت llama.cpp (لا يلزم تعديل للنموذج). يرجى الرجوع إلى مجال المناقشة للأساليب والمناقشات ذات الصلة ؛ يرجى الرجوع إلى PR#705 للحصول على الرموز التي تدعم سياق 4K+ تحت المحولات.
[2023/06/16] الإصدار V4.1: إصدار نسخة جديدة من التقرير الفني ، إضافة نصوص فك تشفير C-Eval ، إضافة البرامج النصية لدمج النموذج منخفضة الموارد ، إلخ.
[2023/06/08] الإصدار V4.0: إصدار Llama/alpaca-33b الصيني ، أضف أمثلة استخدام خصوصية ، إضافة نتائج C-Eval ، إلخ.
| الفصل | يصف |
|---|---|
| تنزيل model | عنوان تنزيل النموذج الصيني Llama و Alpaca Big Model |
| دمج النموذج | (مهم) تقديم كيفية دمج طراز Lora الذي تم تنزيله مع Llama الأصلي |
| التفكير المحلي والنشر السريع | يقدم كيفية تحديد النماذج ونشر وتجربة نماذج كبيرة باستخدام جهاز كمبيوتر شخصي |
| آثار النظام | يتم تقديم تأثير تجربة المستخدم في ظل بعض السيناريوهات والمهام |
| تفاصيل التدريب | قدمت تفاصيل التدريب لنماذج اللاما الصينية والألبكة |
| ❓faq | ردود على بعض الأسئلة الشائعة |
| يتضمن هذا المشروع قيودًا على النموذج |
يُحظر على نموذج LLAMA الذي تم إصداره رسميًا من قبل Facebook الاستخدام التجاري ، وليس للمسؤول أوزان نموذجية مفتوحة المصدر (على الرغم من وجود العديد من عناوين تنزيل الطرف الثالث على الإنترنت). من أجل الامتثال للإذن المقابل ، يمكن فهم أوزان Lora التي تم إصدارها هنا على أنها "تصحيح" على نموذج LLAMA الأصلي. يمكن الجمع بين الاثنين للحصول على حقوق الطبع والنشر الكاملة. لا يمكن استخدام نموذج Llama/Alpaca Lora الصيني التالي بمفرده ويحتاج إلى مطابقة مع نموذج LLAMA الأصلي. يرجى الرجوع إلى خطوات نموذج الدمج الواردة في هذا المشروع لإعادة بناء النموذج.
يوضح الشكل التالي العلاقة بين هذا المشروع وجميع النماذج الكبيرة التي أطلقتها مشروع المرحلة الثانية.
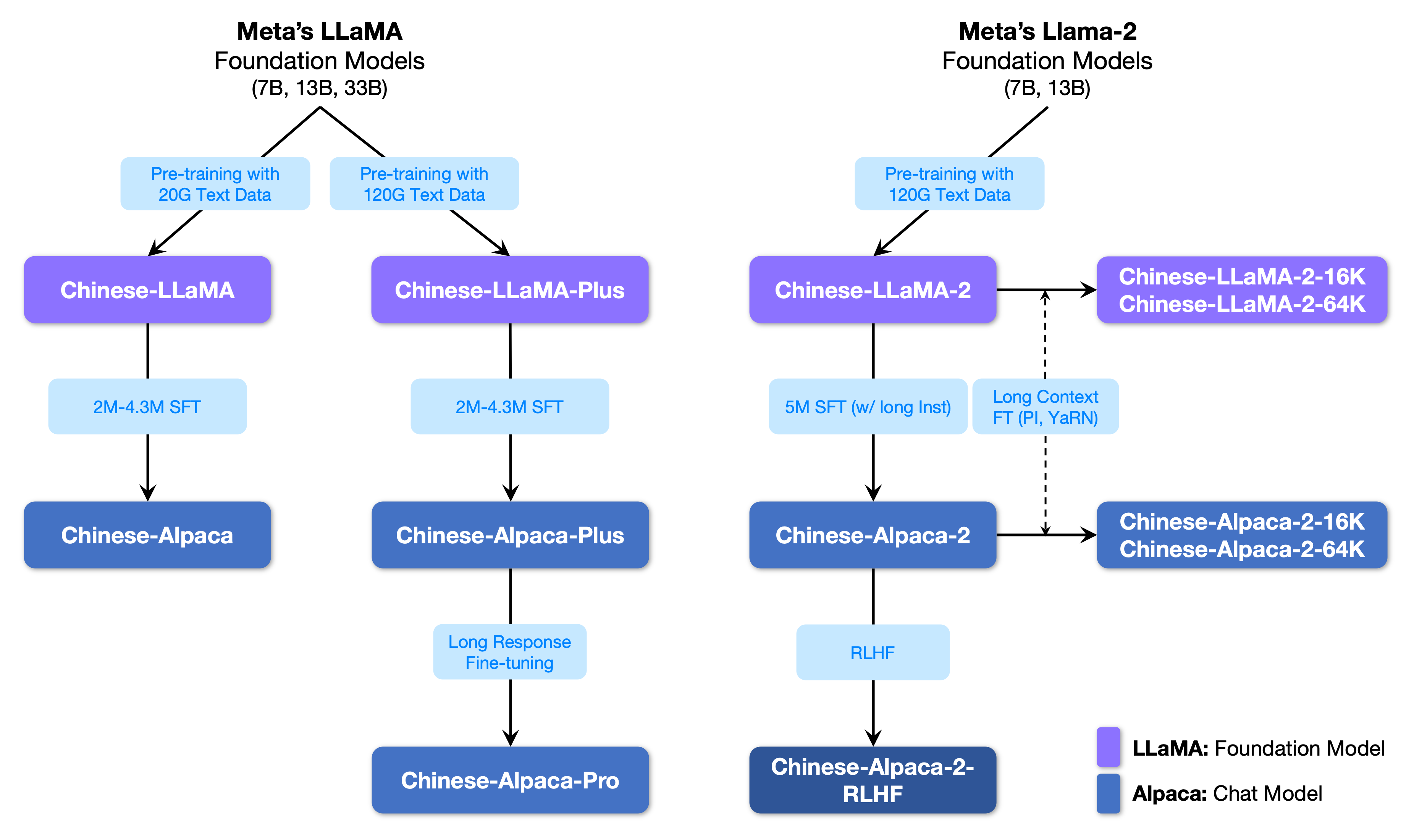
فيما يلي مقارنة أساسية لنماذج Llama و Alpaca الصينية وسيناريوهات الاستخدام الموصى بها (بما في ذلك على سبيل المثال لا الحصر). لمزيد من المعلومات ، راجع تفاصيل التدريب.
| عناصر المقارنة | لاما الصينية | الألبكة الصينية |
|---|---|---|
| طريقة التدريب | CLM التقليدية | تعليمات تعليم غرامة |
| نوع النموذج | نموذج قاعدة | نموذج فهم التعليمات (الفصل الدراسي) |
| مواد التدريب | مقال عام غير مميز | بيانات التعليمات المسمى |
| حجم المفردات [3] | 4995 3 | 4995 4 = 49953+1 (رمز وسادة) |
| قالب الإدخال | غير ضروري | تحتاج إلى تلبية متطلبات القالب [1] |
| سيناريوهات سارية ✔ | استمرار النص: بالنظر إلى المحتوى أعلاه ، دع النموذج ينشئ النص التالي | فهم التعليمات (الأسئلة والأجوبة ، الكتابة ، الاقتراحات ، إلخ) ؛ فهم السياق متعدد الدورات (الدردشة ، إلخ) |
| لا ينطبق | فهم القيادة ، جولات متعددة من الدردشة ، إلخ. | توليد نص غير محدود |
| llama.cpp | استخدم المعلمة -p لتحديد ما سبق | استخدم المعلمة -ins لبدء تعليمات التفاهم + وضع الدردشة |
| توليد النص ويبوي | غير مناسب لوضع الدردشة | استخدم --cpu لتشغيله بدون بطاقة رسومات |
| اللاما | حدد "Llama" عند تحميل النموذج | حدد "الألبكة" عند تحميل النموذج |
| رمز الاستدلال HF | لا توجد معلمات بدء تشغيل إضافية مطلوبة | أضف معلمات عند بدء التشغيل --with_prompt |
| رمز الويب | لا ينطبق | مجرد توفير موقف نموذج الألبكة مباشرة ؛ دعم جولات متعددة من المحادثات |
| Langchain مثال/خصوصية | لا ينطبق | ما عليك سوى توفير موقع نموذج الألبكة مباشرة |
| القضايا المعروفة | إذا لم ينتهي أي عنصر تحكم ، فسوف يستمر في الكتابة حتى يتم الوصول إلى حد طول الإخراج العلوي. [2] | يرجى استخدام الإصدار Pro لتجنب مشكلة الإصدار Plus الذي يكون قصيرًا جدًا. |
[1] llama.cpp/llamachat/hf رمز الاستدلال/رمز web-demo/langchain ، إلخ ، لا حاجة لإضافة قوالب يدويًا.
[2] إذا كانت جودة الإجابة النموذجية منخفضة بشكل خاص أو هراء أو لا تفهم المشكلة ، فيرجى التحقق مما إذا كان يتم استخدام المعلمات النموذج الصحي وبدء التشغيل.
[3] سيكون لدى الألبكة مع تعليمات دقيقة واحدة رمز وسادة آخر من Llama ، لذا يرجى عدم مزج قائمة المفردات LAMA/الألباكا .
فيما يلي قائمة بالنماذج الموصى بها لهذا المشروع. عادة ، يتم استخدام المزيد من بيانات التدريب وأساليب تدريب النماذج المحسنة والمعلمات. يرجى إعطاء الأولوية لهذه النماذج (انظر النماذج الأخرى لبقية النماذج). إذا كنت ترغب في تجربة تفاعل الحوار ChatGPT ، فيرجى استخدام نموذج الألبكة بدلاً من نموذج LLAMA. بالنسبة لنموذج الألبكة ، قام الإصدار المحترف بتحسين مشكلة محتوى الاستجابة القصير للغاية ، وقد تم تحسين تأثير رد النموذج بشكل كبير ؛ إذا كنت تفضل ردود قصيرة ، يرجى تحديد سلسلة Plus.
| اسم النموذج | يكتب | بيانات التدريب | إعادة بناء النموذج [1] | الحجم [2] | تنزيل لورا [3] |
|---|---|---|---|---|---|
| الصينية بلاما زائد 7 ب | نموذج قاعدة | الغرض العام 120g | الأصلي LAMA-7B | 790M | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية بلاما زائد 13 ب | نموذج قاعدة | الغرض العام 120g | الأصلي LAMA-13B | 1.0 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية بلاما زائد 33 ب؟ | نموذج قاعدة | الغرض العام 120g | الأصلي LAMA-33B | 1.3 جم [6] | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية alpaca-pro-7b؟ | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-7B & Llama-plus-7b [4] | 1.1 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية alpaca-pro-13b؟ | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-13B & Llama-Plus-13B [4] | 1.3 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية alpaca-pro-33b؟ | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-33B & Llama-plus-33b [4] | 2.1g | [Baidu] [Google] [؟ HF] [؟ modelscope] |
[1] تتطلب إعادة البيع نموذج LLAMA الأصلي ، انتقل إلى مشروع LLAMA للتقدم للاستخدام أو الرجوع إلى هذا العلاقات العامة. بسبب مشكلات حقوق الطبع والنشر ، لا يمكن لهذا المشروع توفير رابط تنزيل.
[2] حجم النموذج الذي أعيد بناؤه أكبر من llama الأصلي بنفس الحجم (ويرجع ذلك أساسًا إلى قائمة المفردات الموسعة).
[3] بعد التنزيل ، تأكد من التحقق مما إذا كان SHA256 من ملف النموذج في الحزمة المضغوطة متسقة. يرجى التحقق من sha256.md.
[4] يحتاج نموذج الألبكة الزائد إلى تنزيل نموذج Llama-Plus المقابل في نفس الوقت ، يرجى الرجوع إلى البرنامج التعليمي.
[5] بعض الأماكن تسميها 30 ب ، ولكن في الواقع كتبها Facebook بشكل خاطئ عند نشر النموذج ، وما زالت الورقة تكتب 33B.
[6] استخدم تخزين FP16 ، وبالتالي فإن حجم النموذج صغير.
دليل الملفات في الحزمة المضغوطة على النحو التالي (مع أخذ الصينيين-الللام -7 ب كمثال):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
نظرًا لعوامل مثل طرق التدريب وبيانات التدريب ، لم تعد النماذج التالية موصى بها (قد لا تزال مفيدة في سيناريوهات محددة) . يرجى إعطاء الأولوية للنماذج الموصى بها في القسم السابق.
| اسم النموذج | يكتب | بيانات التدريب | إعادة إنشاء النموذج | مقاس | تنزيل لورا |
|---|---|---|---|---|---|
| الصينية لاما -7 ب | نموذج قاعدة | عام 20G | الأصلي LAMA-7B | 770 م | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية لاما -13 ب | نموذج قاعدة | عام 20G | الأصلي LAMA-13B | 1.0 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية لما 33 ب | نموذج قاعدة | عام 20G | الأصلي LAMA-33B | 2.7 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية alpaca-7b | نموذج التعليمات | التعليمات 2M | الأصلي LAMA-7B | 790M | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية alpaca-13b | نموذج التعليمات | تعليمات 3M | الأصلي LAMA-13B | 1.1 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية-ألباكا 33 ب | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-33B | 2.8g | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية-ألباكا زائد 7 ب | نموذج التعليمات | تعليمات 4M | الأصلي LAMA-7B & Llama-plus-7b | 1.1 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية-ألباكا زائد 13 ب | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-13B & لاما زائد 13 ب | 1.3 جم | [Baidu] [Google] [؟ HF] [؟ modelscope] |
| الصينية-ألباكا زائد 33 ب | نموذج التعليمات | التعليمات 4.3m | الأصلي LAMA-33B & Llama-plus-33b | 2.1g | [Baidu] [Google] [؟ HF] [؟ modelscope] |
يمكن تنزيل جميع النماذج المذكورة أعلاه على موديل Hub ويمكن استدعاء نماذج Llama أو الألبكة Lora الصينية باستخدام المحولات و PEFT. يشير اسم استدعاء النموذج التالي إلى اسم النموذج المحدد في .from_pretrained() .
قائمة مفصلة وعنوان تنزيل النموذج: https://huggingface.co/hfl
كما ذكرنا سابقًا ، لا يمكن استخدام نموذج Lora بمفرده ويجب دمجه مع Llama الأصلي ليتم تحويله إلى نموذج كامل لاستدلال النموذج أو القياس الكمي أو التدريب الإضافي. يرجى تحديد الطريقة التالية لتحويل النموذج ودمجه.
| طريق | السيناريوهات المعمول بها | درس تعليمي |
|---|---|---|
| تحويل عبر الإنترنت | يمكن لمستخدمي كولاب استخدام دفتر الملاحظات الذي يوفره هذا المشروع لتحويل النماذج عبر الإنترنت وتحديد النماذج. | وصلة |
| التحويل اليدوي | قم بتحويل دون اتصال بالإنترنت ، وإنشاء نماذج بتنسيقات مختلفة للتحديد الكمي أو مزيد من التحسين | وصلة |
فيما يلي دقة FP16 وحجم كمية 4 بت بعد دمج النموذج. تأكد من أن الجهاز لديه مساحة كافية للذاكرة والقرص قبل التحويل (الحد الأدنى من المتطلبات):
| نسخة نموذج | 7 ب | 13 ب | 33 ب | 65 ب |
|---|---|---|---|---|
| حجم النموذج الأصلي (FP16) | 13 غيغابايت | 24 غيغابايت | 60 جيجابايت | 120 غيغابايت |
| الحجم الكمي (8 بت) | 7.8 جيجابايت | 14.9 غيغابايت | 32.4 جيجابايت | ~ 60 جيجابايت |
| الحجم الكمي (4 بت) | 3.9 جيجابايت | 7.8 جيجابايت | 17.2 غيغابايت | 38.5 جيجابايت |
للحصول على تفاصيل ، يرجى الرجوع إلى هذا المشروع >>> Github Wiki
تدعم النماذج في هذا المشروع بشكل أساسي أساليب القياس الكمي والتفكير والنشر التالي.
| طرق التفكير والنشر | سمات | منصة | وحدة المعالجة المركزية | GPU | التحميل الكمي | واجهة الرسوم البيانية | درس تعليمي |
|---|---|---|---|---|---|---|---|
| llama.cpp | الخيارات الكمية الغنية والتفكير المحلي الفعال | عام | ✅ | ✅ | ✅ | وصلة | |
| ؟محولات | واجهة الاستدلال المحولات الأصلية | عام | ✅ | ✅ | ✅ | ✅ | وصلة |
| توليد النص ويبوي | كيفية نشر واجهة واجهة مستخدم الويب الواجهة الأمامية | عام | ✅ | ✅ | ✅ | ✅ | وصلة |
| اللاما | واجهة تفاعلية رسومية تحت MacOS | ماكوس | ✅ | ✅ | ✅ | وصلة | |
| لانجشين | إطار تطوير تطبيق LLM ، مناسب للتنمية الثانوية | عام | ✅ † | ✅ | ✅ † | وصلة | |
| خصوصية | إطار أسئلة وأجوبة محلية متعددة الحجة بناءً على Langchain | عام | ✅ | ✅ | ✅ | وصلة | |
| Colab Gradio Demo | ابدأ خدمة ويب تفاعلية قائمة على الخريجين في كولاب | عام | ✅ | ✅ | ✅ | وصلة | |
| مكالمات API | العرض التجريبي الذي يحاكي واجهة Openai API | عام | ✅ | ✅ | ✅ | وصلة |
† : يدعمه إطار Langchain ، لكنه لم يتم تنفيذه في البرنامج التعليمي ؛ يرجى الرجوع إلى وثائق Langchain الرسمية للحصول على التفاصيل.
للحصول على تفاصيل ، يرجى الرجوع إلى هذا المشروع >>> Github Wiki
من أجل تقييم أداء توليد النص الفعلي للنماذج ذات الصلة ، بالنظر إلى نفس propt ، قارن هذا المشروع واختبار آثار الألبكة الصينية 7 ب ، الألباكا -13 ب ، الألبكة الصينية 33 ب ، الألبكة الصينية-7 ب ، والألباكا الصينية -13 ب في هذا المشروع في بعض المتقلبات الشائعة. توليد الرد عشوائي ويتأثر بعوامل مثل فك تشفير الفصائل والبذور العشوائية. المراجعات ذات الصلة التالية ليست صارمة للغاية. نتائج الاختبار هي لتجفيف مرجع فقط. اهلا وسهلا بكم لتجربة ذلك بنفسك.
اختبر هذا المشروع أيضًا النماذج ذات الصلة على مجموعة التقييم الهدف من "NLU". نتائج هذا النوع من التقييم ليست ذاتية ، وتتطلب فقط إخراج علامة معينة (يجب تصميم استراتيجية تعيين العلامات) ، حتى تتمكن من فهم قدرات النموذج الكبير من منظور آخر. اختبر هذا المشروع تأثيرات النماذج ذات الصلة على مجموعة بيانات التقييم C-Eval التي تم إطلاقها مؤخرًا ، والتي تضمنت 12.3 كيلو بايت أسئلة متعددة الخيارات وغطت 52 موضوعًا. فيما يلي نتائج تقييم مجموعة صالحة واختبار (متوسط) لبعض النماذج. يرجى الرجوع إلى التقرير الفني للحصول على النتائج الكاملة.
| نموذج | صالح (صفر طلقة) | صالح (5 طلقة) | اختبار (صفر طلقة) | اختبار (5 طلقة) |
|---|---|---|---|---|
| الصينية-ألباكا زائد 33 ب | 46.5 | 46.3 | 44.9 | 43.5 |
| الصينية-ألباكا 33 ب | 43.3 | 42.6 | 41.6 | 40.4 |
| الصينية-ألباكا زائد 13 ب | 43.3 | 42.4 | 41.5 | 39.9 |
| الصينية-ألباكا زائد 7 ب | 36.7 | 32.9 | 36.4 | 32.3 |
| الصينية بلاما زائد 33 ب | 37.4 | 40.0 | 35.7 | 38.3 |
| الصينية لما 33 ب | 34.9 | 38.4 | 34.6 | 39.5 |
| الصينية بلاما زائد 13 ب | 27.3 | 34.0 | 27.8 | 33.3 |
| الصينية بلاما زائد 7 ب | 27.3 | 28.3 | 26.9 | 28.4 |
تجدر الإشارة إلى أن التقييم الشامل لقدرة النماذج الكبيرة لا يزال مشكلة مهمة يجب حلها بشكل عاجل. إن النظرة المعقولة والديلي لنتائج التقييم المختلفة المتعلقة بالنماذج الكبيرة ستساعد على التطوير الصحي لتكنولوجيا النماذج الكبيرة. يوصى بأن يختبر المستخدمون في المهام التي يهتمون بها وتحديد النماذج التي تتكيف مع المهام ذات الصلة.
يرجى الرجوع إلى هذا المشروع للحصول على رمز الاستدلال C
تتضمن عملية التدريب بأكملها ثلاثة أجزاء: التوسع في المفردات ، والتدريب المسبق وتعديل التعليمات.
للحصول على تفاصيل ، يرجى الرجوع إلى هذا المشروع >>> Github Wiki
يتم إعطاء الأسئلة الشائعة سؤالًا متكررًا. يرجى التحقق من الأسئلة الشائعة قبل طلب مشكلة.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
يرجى الرجوع إلى هذا المشروع للحصول على أسئلة وأجوبة محددة >>> github wiki
على الرغم من أن النماذج الواردة في هذا المشروع لديها بعض القدرات الصينية والتوليد ، إلا أنها لها قيود ، بما في ذلك على سبيل المثال لا الحصر:
إذا شعرت أن هذا المشروع مفيد لبحثك أو استخدم الكود أو بيانات هذا المشروع ، فيرجى الرجوع إلى التقرير الفني نقلاً عن هذا المشروع: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| اسم المشروع | مقدمة | يكتب |
|---|---|---|
| الصينية لاما-ألباكا -2 (المشروع الرسمي) | صينية لاما -2 ، الألباكا -2 نموذج كبير | نص |
| البصرية الصينية الللاما ألبياكا (المشروع الرسمي) | نموذج كبير الصينية متعددة الوسائط | متعدد الوسائط |
تريد الانضمام إلى القائمة؟ >>> إرسال طلب
يعتمد هذا المشروع على التطوير الثانوي لمشاريع المصادر المفتوحة التالية. أود أن أعرب عن امتناني للمشاريع ذات الصلة وموظفي البحث والتطوير.
| النموذج الأساسي ، الكود | القياس الكمي ، المنطق ، النشر | بيانات |
|---|---|---|
| لاما بواسطة Facebook الألبكة من قبل ستانفورد الألباكا لورا بواسطة tloen | llama.cpp بواسطة ggerganov Llamachat بواسطة alexrozanski النصوص النصية Webui بواسطة @Oobabooga | بيانات PCLUE و MT بواسطة BrightMart OASST1 بواسطة OpenAssistant |
الموارد المتعلقة بهذا المشروع مخصصة للبحث الأكاديمي فقط وهي محظورة بشكل صارم لأغراض تجارية. عند استخدام أجزاء تتضمن رمز الطرف الثالث ، يرجى متابعة بروتوكول المصدر المفتوح المقابل. يتأثر المحتوى الناتج عن النموذج بعوامل مثل حساب النموذج والعشوائية وخسائر الدقة الكمية. هذا المشروع لا يضمن دقته. لا يتحمل هذا المشروع أي مسؤولية قانونية عن أي إخراج للمحتوى حسب النموذج ، كما أنه لا يتحمل أي خسائر قد تنشأ عن استخدام الموارد ذات الصلة ونتائج الإخراج. يتم بدء هذا المشروع وصيانته من قبل الأفراد والمتعاونين في أوقات فراغهم ، لذلك من المستحيل ضمان أن يتمكنوا من الاستجابة على الفور لحل المشكلات المقابلة.
إذا كان لديك أي أسئلة ، فيرجى إرسالها في قضية GitHub. اطرح أسئلة بأدب وبناء مجتمع نقاش متناغم.


