Chinese LLaMA Alpaca
v5.0
?? Chinois | Anglais | Documents / Docs | ❓ Questions / problèmes | Discussions / discussions | ⚔️ Arena / Arena

Ce projet a ouvert le modèle de Llama chinois et le modèle alpaca réglé par l'instruction pour promouvoir davantage la recherche ouverte du grand modèle dans la communauté des PNL chinois. Ces modèles ont élargi la liste de vocabulaire chinois sur la base du lama d'origine et utilisé des données chinoises pour la pré-formation secondaire, améliorant davantage la capacité de compréhension sémantique de base des Chinois. Dans le même temps, le modèle d'alpaga chinois utilise en outre les données d'instruction chinoise pour un ajustement fin, ce qui améliore considérablement les capacités de compréhension et d'exécution du modèle des instructions.
Rapport technique (V2) : [Cui, Yang et Yao] Encodage de texte efficace et efficace pour le lama chinois et l'alpaga
Contenu principal de ce projet:
La figure ci-dessous montre la vitesse et l'effet d'expérience réels du modèle chinois de l'alpaca et 7b après déploiement quantitatif du processeur local.
Chinese Llama-2 & Alpaca-2 Big Model | Multimodal Chinese Llama & Alpaca Big Model | VLE multimodal | Minirbt chinois | Lert chinois | Pert anglais chinois | Macbert chinois | Electra chinois | Xlnet chinois | Chinois Bert | Outil de distillation de connaissances TextBrewer | Modèle de coupe TextPruner
[2024/04/30] Chinese-Llama-Alpaca-3 a été officiellement libéré, avec l'Open Source Llama-3-Chinese-8b et Llama-3-Chinese-8b-Istruct basé sur LLAMA-3. Il est recommandé de passer à tous les utilisateurs de phase un et deux phases au modèle de troisième génération, veuillez vous référer à: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] Ce projet a été déployé au cœur de la machine Sota! Plateforme modèle, bienvenue à suivre: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] Chinese-Llama-Alpaca-2 V2.0 a été officiellement publié, Open Source Chinese-Llama-2-13B et Chinese-Alpaca-2-13B. Il est recommandé de passer tous les utilisateurs de première phase vers le modèle de deuxième génération, veuillez vous référer à: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/31] Chinese-Llama-Alpaca-2 V1.0 a été officiellement publié, veuillez vous référer à: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] Version V5.0: Libérez le modèle Alpaca-PRO, améliorant considérablement la longueur et la qualité de la réponse; En même temps, publiez le modèle de série plus-33B.
[2023/07/19] Lancez le LLAMA-2 chinois-2 et les projets Open Source Model, bienvenue, bienvenue à suivre et à découvrir les dernières informations.
[2023/07/10] Aperçu du test bêta, découvrez les mises à jour à venir à l'avance: voir la zone de discussion pour plus de détails
[2023/07/07] La famille Chinese-Llama-Alpaca a ajouté un autre membre, lançant un modèle multimodal chinois et alpaga pour la question visuelle et la réponse et le dialogue, et a publié une version de test 7B.
[2023/06/30] Support de contexte 8K sous Llama.cpp (aucune modification du modèle n'est requise). Veuillez vous référer au domaine de discussion pour les méthodes et discussions connexes; Veuillez vous référer à PR # 705 pour les codes qui prennent en charge le contexte 4K + sous Transformers.
[2023/06/16] V4.1 Version: publiez une nouvelle version du rapport technique, ajoutez des scripts de décodage C-Eval, ajoutez des scripts de fusion de modèle à faible ressource, etc.
[2023/06/08] V4.0 Version: Libérez chinois LLAMA / ALPACA-33B, Ajoutez des exemples d'utilisation privées, ajoutez des résultats C-Eval, etc.
| chapitre | décrire |
|---|---|
| Téléchargement du modélisation | Adresse de téléchargement de Big Model Llama et Alpaca Big Model |
| ? Fusionner le modèle | (IMPORTANT) Introduire comment fusionner le modèle Lora téléchargé avec le LLAMA original |
| Raisonnement local et déploiement rapide | Présente comment quantifier les modèles et déployer et découvrir de grands modèles à l'aide d'un ordinateur personnel |
| ? Effets du système | L'effet d'expérience utilisateur dans certains scénarios et tâches est introduit |
| Détails de la formation | A présenté les détails de formation des modèles de lama chinoise et d'alpaga |
| ❓faq | Réponses à certaines FAQ |
| Ce projet implique des limites du modèle |
Le modèle LLAMA officiellement publié par Facebook est interdit à une utilisation commerciale, et le responsable n'a pas de poids officiel du modèle open source (bien qu'il existe déjà de nombreuses adresses de téléchargement tierces sur Internet). Afin de se conformer à l'autorisation correspondante, les poids LORA publiés ici peuvent être compris comme un "patch" sur le modèle LLAMA d'origine. Les deux peuvent être combinés pour obtenir le droit d'auteur complet. Le modèle LLAMA / ALPACA LORA suivant ne peut pas être utilisé seul et doit être jumelé avec le modèle LLAMA d'origine. Veuillez vous référer aux étapes du modèle de fusion indiquées dans ce projet pour reconstruire le modèle.
La figure suivante montre la relation entre ce projet et tous les grands modèles lancés par le projet de deuxième phase.
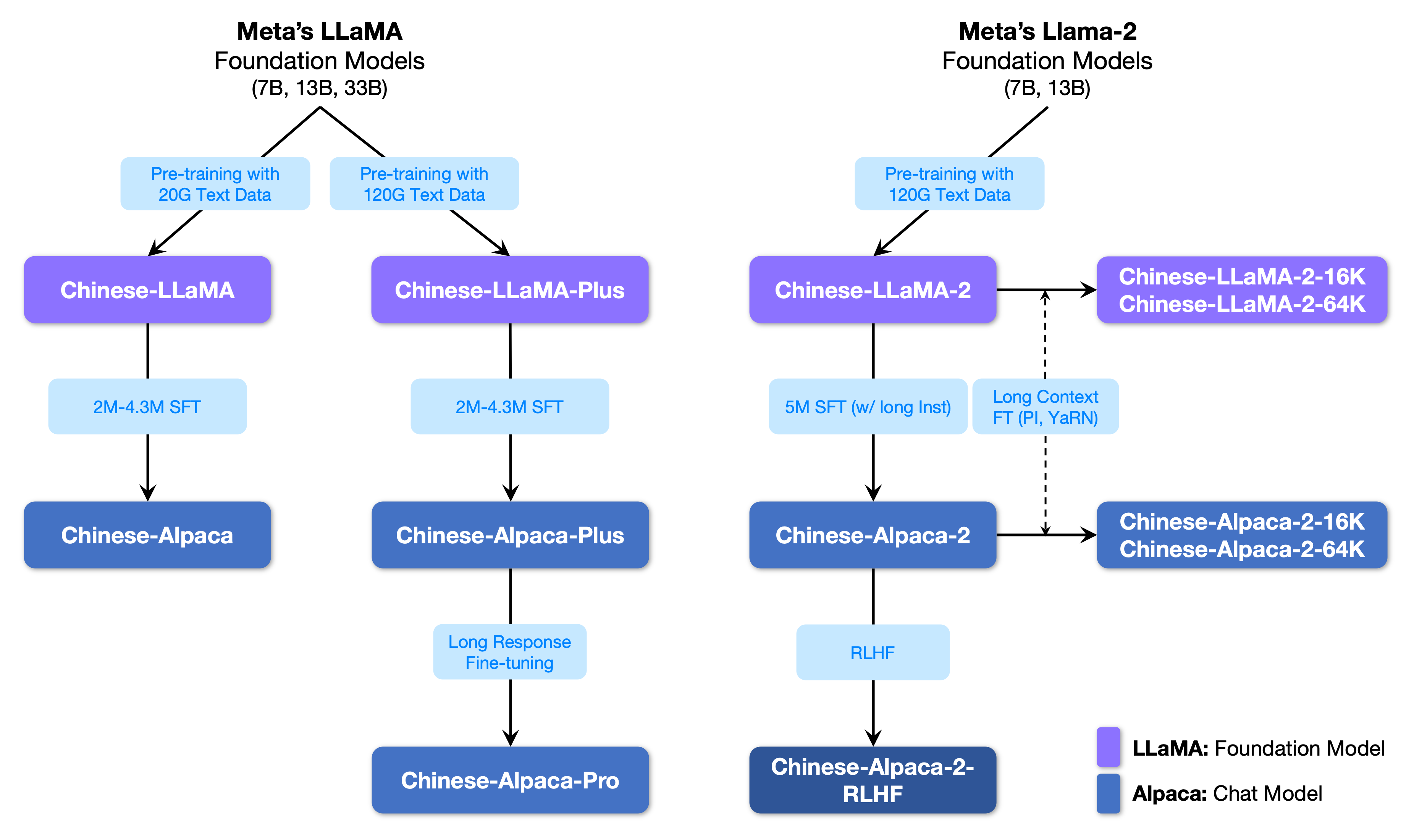
Vous trouverez ci-dessous une comparaison de base des modèles de lama et d'alpaga chinois et des scénarios d'utilisation recommandés (y compris, mais sans s'y limiter). Pour plus d'informations, consultez les détails de la formation.
| Articles de comparaison | Llama chinois | Alpaga chinois |
|---|---|---|
| Méthode de formation | CLM traditionnel | Instruction Fine ajustement |
| Type de modèle | Modèle de base | Modèle de compréhension de l'enseignement (classe Chatgpt) |
| Matériel de formation | Essai général non marqué | Données d'instructions étiquetées |
| Taille du vocabulaire [3] | 4995 3 | 4995 4 = 49953 + 1 (jeton de pad) |
| Modèle d'entrée | inutile | Besoin de répondre aux exigences du modèle [1] |
| Scénarios applicables ✔️ | Contenue du texte: Compte tenu du contenu ci-dessus, laissez le modèle générer le texte suivant | Compréhension de l'enseignement (questions et réponses, écriture, suggestions, etc.); Compréhension du contexte multi-ronde (chat, etc.) |
| Non applicable | Compréhension des commandes, plusieurs cycles de chat, etc. | Génération de texte illimitée |
| lama.cpp | Utilisez le paramètre -p pour spécifier ce qui précède | Utilisez le paramètre -ins pour démarrer la compréhension de l'instruction + le mode de chat |
| Génération de texte-webui | Pas adapté au mode chat | Utiliser --cpu pour fonctionner sans carte graphique |
| Llamachat | Sélectionnez "Llama" lors du chargement du modèle | Sélectionnez "Alpaga" lors du chargement du modèle |
| Code d'inférence HF | Aucun paramètre de démarrage supplémentaire requis | Ajouter des paramètres au démarrage --with_prompt |
| Code de dimurage Web | non applicable | Fournir simplement la position du modèle alpaca directement; Soutenez plusieurs cycles de conversations |
| Exemple de Langchain / Privategpt | non applicable | Fournissez simplement l'emplacement du modèle alpaca directement |
| Problèmes connus | Si aucun contrôle ne se termine, il continuera d'écrire jusqu'à ce que la limite de longueur de sortie supérieure soit atteinte. [2] | Veuillez utiliser la version Pro pour éviter que le problème de la version plus soit trop courte. |
[1] LLAMA.CPP / LLAMACHAT / HF Code d'inférence / code Web-Demo / Langchain Exemples, etc. sont intégrés, pas besoin d'ajouter des modèles manuellement.
[2] Si la qualité de réponse du modèle est particulièrement faible, absurde ou ne comprend pas le problème, veuillez vérifier si le modèle et les paramètres de démarrage sont utilisés.
[3] L'alpaga avec des instructions affinées aura un jeton de pad de plus que le lama, alors ne mélangez pas la liste de vocabulaire LLAMA / Alpaca .
Ce qui suit est une liste de modèles recommandés pour ce projet. Habituellement, davantage de données de formation et des méthodes et des paramètres de formation des modèles optimisés sont utilisés. Veuillez donner la priorité à ces modèles (voir d'autres modèles pour le reste des modèles). Si vous souhaitez découvrir l'interaction de dialogue Chatgpt, veuillez utiliser le modèle alpaca au lieu du modèle LLAMA. Pour le modèle alpaca, la version pro a amélioré le problème du contenu de réponse trop court et l'effet de réponse du modèle a été considérablement amélioré; Si vous préférez de courtes réponses, veuillez sélectionner la série Plus.
| Nom du modèle | taper | Données de formation | Reconstruire le modèle [1] | Taille [2] | Lora Télécharger [3] |
|---|---|---|---|---|---|
| Chinese-Llama-plus-7b | Modèle de base | Objectif général 120g | LLAMA-7B ORIGINAL | 790m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-Llama-plus-13b | Modèle de base | Objectif général 120g | LLAMA-13B ORIGINAL | 1,0 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinese-Llama-plus-33b? | Modèle de base | Objectif général 120g | LLAMA-33B ORIGINAL | 1,3 g [6] | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinese-alpaca-pro-7b? | Modèle d'instruction | Instruction 4,3m | LLAMA-7B ORIGINAL & Lama-plus-7b [4] | 1,1 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinese-alpaca-pro-13b? | Modèle d'instruction | Instruction 4,3m | LLAMA-13B ORIGINAL & Lama-plus-13b [4] | 1,3 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinese-alpaca-pro-33b? | Modèle d'instruction | Instruction 4,3m | Llama-33b d'origine & LLAMA-PLUS-33B [4] | 2.1g | [Baidu] [Google] [? HF] [? Modelscope] |
[1] Le refactorisation nécessite le modèle LLAMA d'origine, aller au projet LLAMA pour demander une utilisation ou se référer à ce PR. En raison de problèmes de droit d'auteur, ce projet ne peut pas fournir de lien de téléchargement.
[2] La taille du modèle reconstruit est plus grande que le lama d'origine de la même ampleur (principalement en raison de la liste de vocabulaire élargie).
[3] Après le téléchargement, assurez-vous de vérifier si le SHA256 du fichier modèle dans le package compressé est cohérent. Veuillez vérifier Sha256.md.
[4] Le modèle Alpaca-Plus doit télécharger le modèle LLAMA-plus correspondant en même temps, veuillez vous référer au tutoriel de fusion.
[5] Certains endroits l'appellent 30b, mais en fait Facebook l'a écrit à tort lors de la publication du modèle, et le journal a toujours écrit 33b.
[6] Utilisez le stockage FP16, de sorte que la taille du modèle est petite.
Le répertoire de fichiers dans le package compressé est le suivant (prendre le chinois-llama-7b à titre d'exemple):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
En raison de facteurs tels que les méthodes de formation et les données de formation, les modèles suivants ne sont plus recommandés (peuvent toujours être utiles dans des scénarios spécifiques) . Veuillez donner la priorité aux modèles recommandés dans la section précédente.
| Nom du modèle | taper | Données de formation | Refactoriser le modèle | taille | Téléchargement de Lora |
|---|---|---|---|---|---|
| Chinois-llama-7b | Modèle de base | Général 20G | LLAMA-7B ORIGINAL | 770m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-llama-13b | Modèle de base | Général 20G | LLAMA-13B ORIGINAL | 1,0 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-llama-33b | Modèle de base | Général 20G | LLAMA-33B ORIGINAL | 2,7 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-7b | Modèle d'instruction | Instruction 2m | LLAMA-7B ORIGINAL | 790m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-13b | Modèle d'instruction | Instruction 3m | LLAMA-13B ORIGINAL | 1,1 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-33b | Modèle d'instruction | Instruction 4,3m | LLAMA-33B ORIGINAL | 2,8 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-plus-7b | Modèle d'instruction | Instruction 4m | LLAMA-7B ORIGINAL & LLAMA-PLUS-7B | 1,1 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-plus-13b | Modèle d'instruction | Instruction 4,3m | LLAMA-13B ORIGINAL & LLAMA-PLUS-13B | 1,3 g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinois-alpaca-PLUS-33B | Modèle d'instruction | Instruction 4,3m | Llama-33b d'origine & LLAMA-PLUS-33B | 2.1g | [Baidu] [Google] [? HF] [? Modelscope] |
Tous les modèles ci-dessus peuvent être téléchargés sur Model Hub et les modèles chinois Llama ou Alpaca Lora peuvent être appelés à l'aide de Transformers et PEFT. Le nom d'appel de modèle suivant fait référence au nom du modèle spécifié dans .from_pretrained() .
Adresse détaillée de la liste et du modèle de téléchargement: https://huggingface.co/hfl
Comme mentionné précédemment, le modèle LORA ne peut pas être utilisé seul et doit être fusionné avec le LLAMA d'origine pour être converti en un modèle complet pour l'inférence du modèle, la quantification ou la formation plus approfondie. Veuillez sélectionner la méthode suivante pour convertir et fusionner le modèle.
| Chemin | Scénarios applicables | Tutoriel |
|---|---|---|
| Conversion en ligne | Les utilisateurs de Colab peuvent utiliser le cahier fourni par ce projet pour convertir en ligne et quantifier les modèles. | Lien |
| Conversion manuelle | Convertir hors ligne, générer des modèles dans différents formats de quantification ou de raffinement supplémentaire | Lien |
Ce qui suit est la précision FP16 et la taille de quantification 4 bits après avoir fusionné le modèle. Assurez-vous que la machine a suffisamment d'espace de mémoire et de disque avant la conversion (exigences minimales):
| Version modèle | 7b | 13B | 33b | 65b |
|---|---|---|---|---|
| Taille du modèle d'origine (FP16) | 13 Go | 24 Go | 60 Go | 120 Go |
| Taille quantifiée (8 bits) | 7,8 Go | 14,9 Go | 32,4 Go | ~ 60 Go |
| Taille quantifiée (4 bits) | 3,9 Go | 7,8 Go | 17.2 Go | 38,5 Go |
Pour plus de détails, veuillez consulter ce projet >>> github wiki
Les modèles de ce projet soutiennent principalement les méthodes de quantification, de raisonnement et de déploiement suivantes.
| Méthodes de raisonnement et de déploiement | Caractéristiques | plate-forme | Processeur | GPU | Chargement quantitatif | Interface graphique | Tutoriel |
|---|---|---|---|---|---|---|---|
| lama.cpp | Riches options quantitatives et raisonnement local efficace | Général | ✅ | ✅ | ✅ | lien | |
| ? Transformers | Interface d'inférence des transformateurs natifs | Général | ✅ | ✅ | ✅ | ✅ | lien |
| Génération de texte-webui | Comment déployer l'interface Interface Web frontale | Général | ✅ | ✅ | ✅ | ✅ | lien |
| Llamachat | Interface interactive graphique sous macOS | Macos | ✅ | ✅ | ✅ | lien | |
| Lubriole | Framework de développement d'applications LLM, adapté au développement secondaire | Général | ✅ † | ✅ | ✅ † | lien | |
| privé | Cadre de questions et réponses locales à plusieurs documents basées sur Langchain | Général | ✅ | ✅ | ✅ | lien | |
| Colab Gradio Demo | Démarrer un service Web interactif basé sur Gradio à Colab | Général | ✅ | ✅ | ✅ | lien | |
| Appels API | Démo de serveur qui émule l'interface API OpenAI | Général | ✅ | ✅ | ✅ | lien |
† : Le cadre Langchain le prend en charge, mais il n'est pas implémenté dans le tutoriel; Veuillez vous référer à la documentation officielle de Langchain pour plus de détails.
Pour plus de détails, veuillez consulter ce projet >>> github wiki
Afin d'évaluer rapidement les performances de génération de texte réelles des modèles pertinents, compte tenu du même propt, ce projet a comparé et testé les effets de l'alpaca-7b chinois, de l'alpaca chinois-13b, de l'alpaca-33b chinois, de l'alpaca-+ 7b chinois et de l'alpaca-pllus-13b chinois dans ce projet sur certaines tâches communes. La réponse de génération est aléatoire et est affectée par des facteurs tels que le décodage des hyperparamètres et des graines aléatoires. Les revues connexes suivantes ne sont pas absolument rigoureuses. Les résultats des tests sont pour la référence de séchage uniquement. Vous êtes les bienvenus pour en faire l'expérience vous-même.
Ce projet a également testé les modèles pertinents sur l'ensemble d'évaluation objective de "NLU". Les résultats de ce type d'évaluation ne sont pas subjectifs et ne nécessitent que la sortie d'une balise donnée (la stratégie de cartographie de la balise doit être conçue), vous pouvez donc comprendre les capacités du grand modèle sous une autre perspective. Ce projet a testé les effets des modèles connexes sur l'ensemble de données d'évaluation C-Eval récemment lancé, qui contenait 12,3k de questions multiples et couvrait 52 sujets. Voici les résultats de l'évaluation valide et des tests de test (moyenne) de certains modèles. Veuillez vous référer au rapport technique pour les résultats complets.
| Modèle | Valide (zéro-shot) | VALIDE (5-Shot) | Test (zéro-shot) | Test (5-shot) |
|---|---|---|---|---|
| Chinois-alpaca-PLUS-33B | 46.5 | 46.3 | 44.9 | 43.5 |
| Chinois-alpaca-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinois-alpaca-plus-13b | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinois-alpaca-plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-Llama-plus-33b | 37.4 | 40.0 | 35.7 | 38.3 |
| Chinois-llama-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinois-Llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-Llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Il convient de noter qu'une évaluation complète de la capacité des grands modèles est toujours un problème important qui doit être résolu de toute urgence. Une vision raisonnable et dialectique de divers résultats d'évaluation liés aux grands modèles aidera le développement sain de la technologie des grands modèles. Il est recommandé que les utilisateurs testent sur les tâches qui les préoccupent et sélectionnent des modèles qui s'adaptent aux tâches connexes.
Veuillez vous référer à ce projet pour C-Eval Inference Code >>> GitHub Wiki
L'ensemble du processus de formation comprend trois parties: l'expansion du vocabulaire, la pré-formation et l'ajustement fin des instructions.
Pour plus de détails, veuillez consulter ce projet >>> github wiki
La FAQ reçoit une question fréquemment posée. Veuillez vérifier la FAQ avant de demander un problème.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Veuillez vous référer à ce projet pour des questions et réponses spécifiques >>> GitHub Wiki
Bien que les modèles de ce projet aient certaines capacités de compréhension et de génération chinoises, elles ont également des limites, y compris, mais sans s'y limiter:
Si vous pensez que ce projet est utile à vos recherches ou utilisez le code ou les données de ce projet, veuillez vous référer au rapport technique citant ce projet: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Nom du projet | Introduction | taper |
|---|---|---|
| Chinese-Llama-Alpaca-2 (projet officiel) | Chinois Llama-2, Alpaca-2 Big Model | texte |
| Visual-chinois-llama-alpaca (projet officiel) | Multimodal Chinese Llama & Alpaca Big Model | Multimodal |
Vous voulez rejoindre la liste? >>> Soumettre une demande
Ce projet est basé sur le développement secondaire des projets open source suivants. Je voudrais exprimer ma gratitude aux projets pertinents et au personnel de recherche et développement.
| Modèle de base, code | Quantification, raisonnement, déploiement | données |
|---|---|---|
| Lama par Facebook Alpaga par Stanford alpaca-lora par @tloen | llama.cpp par @ggerganov Llamachat par @alexrozanski GÉNÉRATION DE Texte-webui par @oobabooga | Données PCLUE et MT par @brightmart oasst1 par openassistant |
Les ressources liées à ce projet concernent uniquement la recherche universitaire et sont strictement interdites à des fins commerciales. Lorsque vous utilisez des pièces impliquant du code tiers, veuillez suivre strictement le protocole open source correspondant. Le contenu généré par le modèle est affecté par des facteurs tels que le calcul du modèle, le hasard et les pertes de précision quantitative. Ce projet ne garantit pas sa précision. Ce projet n'assume aucune responsabilité juridique pour toute sortie de contenu par le modèle, et elle n'est pas responsable des pertes pouvant résulter de l'utilisation des ressources pertinentes et des résultats de sortie. Ce projet est lancé et maintenu par des individus et des collaborateurs pendant leur temps libre, il est donc impossible de garantir qu'ils peuvent répondre rapidement pour résoudre les problèmes correspondants.
Si vous avez des questions, veuillez la soumettre dans le problème de GitHub. Posez des questions poliment et construisez une communauté de discussion harmonieuse.


