Chinese LLaMA Alpaca
v5.0
Китайский | Английский | Документы/документы | ❓ Вопросы/проблемы | Обсуждения/дискуссии | ⚔ Арена/Арена

Этот проект с открытым исходным исходным кодом китайская модель ламы и модель Alpaca, настроенная на инструкции, для дальнейшего продвижения открытых исследований большой модели в китайском сообществе НЛП. Эти модели расширили китайский список словарного запаса на основе оригинальной ламы и использовали китайские данные для вторичного предварительного обучения, что еще больше улучшило базовую способность китайского семантического понимания. В то же время китайская модель Alpaca далее использует китайские данные инструкции для тонкой корректировки, что значительно улучшает возможности понимания и выполнения модели по инструкциям.
Технический отчет (V2) : [Cui, Yang и Yao] Эффективный и эффективный текст, кодирующий китайскую ламу и альпаку
Основное содержание этого проекта:
На рисунке ниже показана фактическая скорость опыта и эффект китайской модели Alpaca-Plus-7b после локального количественного развертывания ЦП.
Китайская лама-2 и альпака-2 большая модель | Мультимодальная китайская лама и альпака большая модель | Мультимодальный VLE | Китайский Minirbt | Китайский Лерт | Китайский английский pert | Китайский Макберт | Китайская электро | Китайский Xlnet | Китайский берт | Инструмент для дистилляции знаний TextBrewer | Модельный режущий инструмент текст
[2024/04/30] был официально освобожден Китай-лама-альпака-3 с открытым исходным кодом Llama-3-Chinese-8B и Llama-3-Chinese-8B-инструкт на основе Llama-3. Рекомендуется, чтобы все пользователи проекта на первом этапе и второе этап обновились до модели третьего поколения, пожалуйста, см.
[2024/03/27] Этот проект был развернут в самом сердце машины SOTA! Модельная платформа, добро пожаловать: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] была официально выпущена китайская-лама-альпака-2 v2.0 версия, с открытым исходным кодом Китай-Ллама-2-13B и китайский-альпака-2-13B. Рекомендуется, чтобы все пользователи первой фазы обновились до модели второго поколения, пожалуйста, см.
[2023/07/31] китайская-лама-альпака-2 v1.0 версия была официально выпущена, пожалуйста, см.
[2023/07/19] V5.0 Версия: выпустите модель серии Alpaca-Pro, значительно улучшив длину и качество ответа; В то же время выпустите модель серии Plus-33B.
[2023/07/19] запустите китайские проекты Llama-2 и Alpaca-2 с открытым исходным кодом, добро пожаловать и узнать о последней информации.
[2023/07/10] Предварительный просмотр бета -тестирования, узнайте о предстоящих обновлениях.
[2023/07/07] Семейство Китая-Ллама-Альпака добавило другого участника, запустив мультимодальную китайскую модель ламы и альпака для визуальных вопросов, ответов и диалога и выпустила тестовую версию 7b.
[2023/06/30] 8K Контекстная поддержка в рамках llama.cpp (модификация модели не требуется). Пожалуйста, обратитесь к области обсуждения для связанных методов и дискуссий; Пожалуйста, обратитесь к PR#705 для кодов, которые поддерживают контекст 4K+ под трансформаторами.
[2023/06/16] V4.1 Версия: выпустите новую версию технического отчета, добавить сценарии декодирования C-Eval, добавить сценарии слияния с низким ресурсом и т. Д.
[2023/06/08] v4.0 Версия: выпустить китайскую ламу/Alpaca-33B, добавить примеры приватетегии, добавить результаты C-Eval и т. Д.
| глава | описывать |
|---|---|
| ⏬model скачать | Китайская лама и альпака большая модель. Адрес загрузки |
| ? Объединить модель | (Важно) представить, как объединить загруженную модель LORA с оригинальной ламой |
| Местные рассуждения и быстрое развертывание | Представляет, как количественно оценить модели и развернуть и испытать большие модели, используя персональный компьютер |
| ? Системные эффекты | Пользовательский эффект в некоторых сценариях и задачах вводится |
| Детали обучения | Представил подробности обучения китайских моделей ламы и альпаки |
| ❓faq | Ответ на некоторые часто задаваемых вопросов |
| Этот проект включает ограничения модели |
Модель Llama, официально выпущенная Facebook, запрещена коммерческим использованием, и у чиновника нет официальных весов модели с открытым исходным кодом (хотя в Интернете уже есть много сторонних адресов загрузки). Чтобы соответствовать соответствующему разрешению, выпущенные здесь веса LORA можно понимать как «патч» на оригинальной модели ламы. Эти два могут быть объединены, чтобы получить полное авторское право. Следующая китайская модель Llama/Alpaca Lora не может быть использована отдельно и должна быть сопоставлена с оригинальной моделью ламы. Пожалуйста, обратитесь к шагам модели Merge, приведенным в этом проекте, чтобы реконструировать модель.
На следующем рисунке показано взаимосвязь между этим проектом и всеми крупными моделями, запущенными в рамках второго этапа проекта.
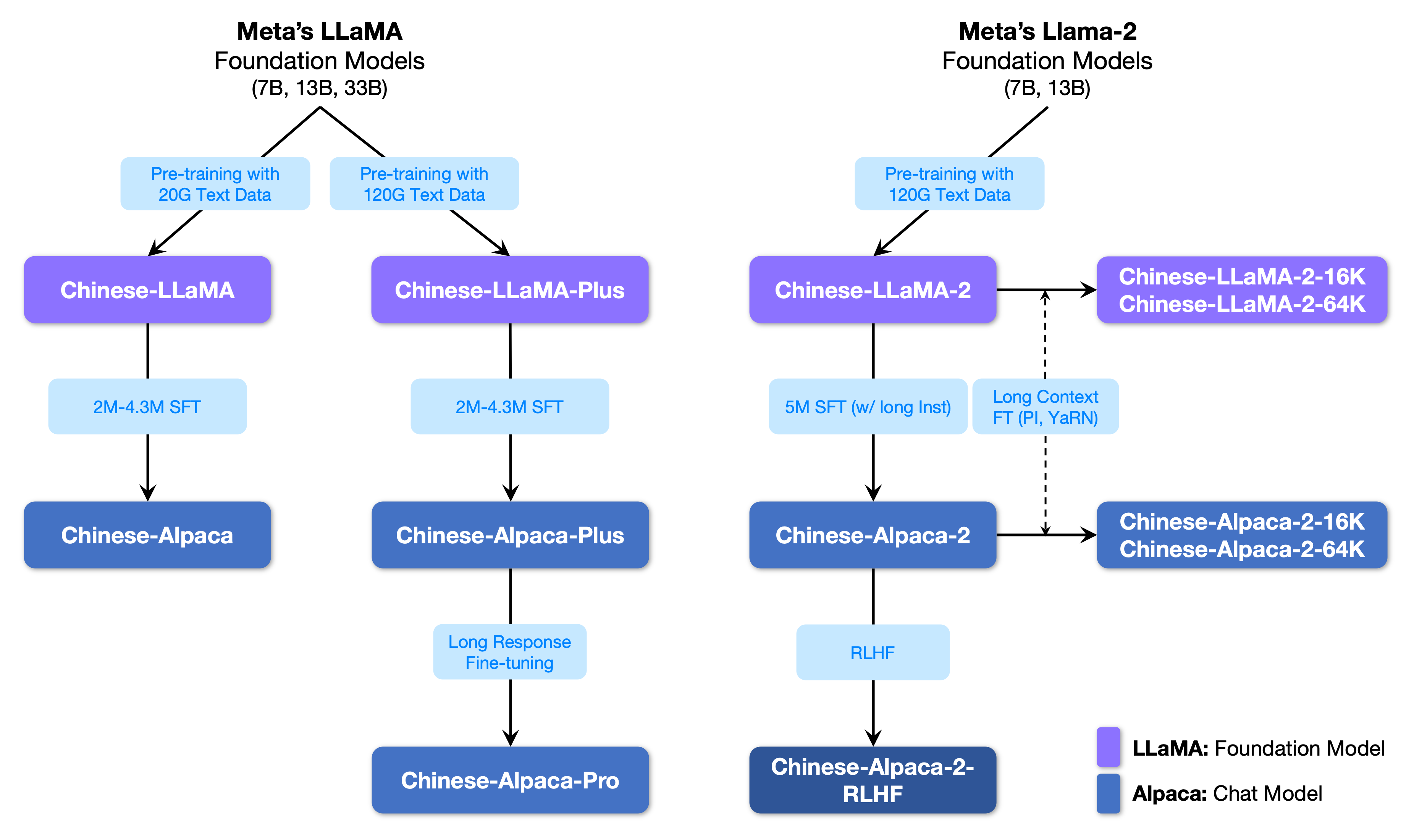
Ниже приведено базовое сравнение китайских моделей ламы и альпаки и рекомендуется сценарии использования (включая, помимо прочего). Для получения дополнительной информации см. Подробности обучения.
| Сравнение пунктов | Китайская лама | Китайская альпака |
|---|---|---|
| Метод обучения | Традиционный CLM | Инструкция тонкая корректировка |
| Тип модели | Базовая модель | Модель понимания инструкций (класс CHATGPT) |
| Учебные материалы | Оснастенное общее эссе | Замеченные данные инструкции |
| Размер словарного запаса [3] | 4995 3 | 4995 4 = 49953+1 (токен PAD) |
| Входной шаблон | ненужный | Необходимо соответствовать требованиям шаблона [1] |
| Применимые сценарии ✔ | Продолжение текста: Учитывая приведенное выше контент, пусть модель генерирует следующий текст | Понимание инструкций (вопросы и ответы, письмо, предложения и т. Д.); Понимание контекста многоуровневого контекста (чат и т. Д.) |
| Непригодный | Командное понимание, несколько раундов чата и т. Д. | Неограниченное генерацию текста |
| llama.cpp | Используйте параметр -p , чтобы указать выше | Используйте параметр -ins , чтобы запустить инструкцию «Понимание + режим чата» |
| Генерация текста-вабуи | Не подходит для режима чата | Использовать --cpu для работы без видеокарты |
| Лламачат | Выберите «Лама» при загрузке модели | Выберите «Альпака» при загрузке модели |
| Код вывода HF | Не требуется дополнительных параметров запуска | Добавить параметры при запуске --with_prompt |
| Веб-демо код | непригодный | Просто предоставьте позицию модели альпаки напрямую; Поддерживать несколько раундов разговоров |
| Пример Langchain/Privategpt | непригодный | Просто предоставьте расположение модели альпаки напрямую |
| Известные проблемы | Если контроль не заканчивается, оно будет продолжать писать до тех пор, пока не будет достигнут предел длины верхней вывода. [2] | Пожалуйста, используйте Pro версию, чтобы избежать проблемы, когда версия Plus будет слишком короткой. |
[1] Llama.cpp/Lmamachat/HF-код вывода/код веб-демо/примеры Langchain и т. Д. Встроены, нет необходимости добавлять шаблоны вручную.
[2] Если качество ответа модели особенно низкое, чепуха или не понимая проблему, проверьте, используются ли правильная модель и параметры запуска.
[3] Alpaca с тонкими настройками будет иметь еще один токен накладки, чем Llama, поэтому, пожалуйста, не смешивайте список словарного запаса ламы/альпаки .
Ниже приведен список моделей, рекомендованных для этого проекта. Обычно используются больше данных обучения и оптимизированных методов обучения модели и параметров. Пожалуйста, отдайте приоритет этим моделям (см. Другие модели для остальных моделей). Если вы хотите испытать взаимодействие в диалоге CHATGPT, используйте модель Alpaca вместо модели Llama. Для модели Alpaca, Pro -версия улучшила проблему содержания ответа, который слишком короткий, и эффект ответа модели был значительно улучшен; Если вы предпочитаете короткие ответы, выберите серию плюс.
| Название модели | тип | Данные обучения | Реконструкция модели [1] | Размер [2] | Лора скачать [3] |
|---|---|---|---|---|---|
| Китай-лама-плюс-7b | Базовая модель | Общая цель 120G | Оригинальный лама-7b | 790 м | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китай-лама-плюс-13b | Базовая модель | Общая цель 120G | Оригинал Llama-13b | 1,0 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайский лама-плюс-33b? | Базовая модель | Общая цель 120G | Оригинал Llama-33b | 1,3 г [6] | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайский-альпака-про-7B? | Модель инструкции | Инструкция 4,3м | Оригинал Llama-7b & Llama-plus-7b [4] | 1,1 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-про-13b? | Модель инструкции | Инструкция 4,3м | Оригинал Llama-13b & Llama-Plus-13b [4] | 1,3 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайский-альпака-про-33B? | Модель инструкции | Инструкция 4,3м | Оригинал Llama-33B & Llama-plus-33b [4] | 2.1G | [Baidu] [Google] [? Hf] [? Modelcope] |
[1] Рефакторинг требует оригинальной модели Llama, перейдите в проект Llama, чтобы подать заявку на использование или обратиться к этому PR. Из -за проблем с авторским правом этот проект не может предоставить ссылку на скачивание.
[2] Реконструированный размер модели больше, чем оригинальная лама той же величины (в основном из -за расширенного списка словарного запаса).
[3] После загрузки обязательно проверьте, является ли SHA256 модели в сжатом пакете. Пожалуйста, проверьте sha256.md.
[4] Модель Alpaca-Plus должна загружать соответствующую модель Llama-Plus одновременно, пожалуйста, обратитесь к учебному пособию Merge.
[5] Некоторые места называют это 30B, но на самом деле Facebook написал это неправильно при публикации модели, и статья все еще написала 33B.
[6] Используйте хранилище FP16, поэтому размер модели невелик.
Справочник файлов в сжатом пакете заключается в следующем (в качестве примера, принимая китайский-лама-7b):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Из -за таких факторов, как методы обучения и данные обучения, следующие модели больше не рекомендуются (все еще могут быть полезны в конкретных сценариях) . Пожалуйста, уделите приоритет рекомендуемым моделям в предыдущем разделе.
| Название модели | тип | Данные обучения | Рефакторирование модели | размер | Лора скачать |
|---|---|---|---|---|---|
| Китай-лама-7b | Базовая модель | Генерал 20 г | Оригинальный лама-7b | 770 м | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китай-лама-13b | Базовая модель | Генерал 20 г | Оригинал Llama-13b | 1,0 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китай-лама-33b | Базовая модель | Генерал 20 г | Оригинал Llama-33b | 2,7 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-7B | Модель инструкции | Инструкция 2м | Оригинальный лама-7b | 790 м | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китай-Альпака-13b | Модель инструкции | Инструкция 3M | Оригинал Llama-13b | 1,1 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-33B | Модель инструкции | Инструкция 4,3м | Оригинал Llama-33b | 2,8 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-плюс-7b | Модель инструкции | Инструкция 4м | Оригинал Llama-7b & Llama-Plus-7b | 1,1 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-плюс-13b | Модель инструкции | Инструкция 4,3м | Оригинал Llama-13b & Llama-Plus-13b | 1,3 г | [Baidu] [Google] [? Hf] [? Modelcope] |
| Китайско-альпака-плюс-33B | Модель инструкции | Инструкция 4,3м | Оригинал Llama-33B & Llama-Plus-33b | 2.1G | [Baidu] [Google] [? Hf] [? Modelcope] |
Все вышеперечисленные модели могут быть загружены на модели Hub, а китайские модели Llama или Alpaca Lora можно назвать с помощью трансформаторов и PEFT. Следующее имя вызова модели относится к имени модели, указанного в .from_pretrained()
Подробный список скачивания списка и модели: https://huggingface.co/hfl
Как упоминалось ранее, модель LORA не может быть использована отдельно и должна быть объединена с исходной ламой, которая будет преобразована в полную модель для модели, количественного определения или дальнейшего обучения. Пожалуйста, выберите следующий метод для преобразования и объединения модели.
| Способ | Применимые сценарии | Учебник |
|---|---|---|
| Онлайн -конверсия | Пользователи Colab могут использовать ноутбук, предоставленную этим проектом, для преобразования онлайн и количественной оценки моделей. | Связь |
| Ручное обращение | Конвертировать автономный режим, генерировать модели в разных форматах для квантования или дальнейшего уточнения | Связь |
Ниже приведены точность FP16 и 4-битный размер квантования после объединения модели. Убедитесь, что у машины есть достаточное количество памяти и дискового пространства до преобразования (минимальные требования):
| Модельная версия | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| Исходный размер модели (FP16) | 13 ГБ | 24 ГБ | 60 ГБ | 120 ГБ |
| Квантованный размер (8-битный) | 7,8 ГБ | 14,9 ГБ | 32,4 ГБ | ~ 60 ГБ |
| Квантованный размер (4-битный) | 3,9 ГБ | 7,8 ГБ | 17,2 ГБ | 38,5 ГБ |
Для получения подробной информации, пожалуйста, обратитесь к этому проекту >>> github wiki
Модели в этом проекте в основном поддерживают следующие методы количественной оценки, рассуждения и развертывания.
| Методы рассуждения и развертывания | Функции | платформа | Процессор | Графический процессор | Количественная нагрузка | Графический интерфейс | Учебник |
|---|---|---|---|---|---|---|---|
| llama.cpp | Богатые количественные варианты и эффективные локальные рассуждения | Общий | ✅ | ✅ | ✅ | связь | |
| ? Трансформеры | Интерфейс вывода нативных трансформаторов | Общий | ✅ | ✅ | ✅ | ✅ | связь |
| Генерация текста-вабуи | Как развернуть интерфейс интерфейса веб-интерфейса интерфейса | Общий | ✅ | ✅ | ✅ | ✅ | связь |
| Лламачат | Графический интерактивный интерфейс под macOS | MacOS | ✅ | ✅ | ✅ | связь | |
| Лангхейн | LLM -структура разработки приложений, подходящая для вторичной разработки | Общий | ✅ † | ✅ | ✅ † | связь | |
| Приваттеги | Многодокументированная локальная структура вопросов и ответов на основе Langchain | Общий | ✅ | ✅ | ✅ | связь | |
| Colab Gradio Demo | Запустите интерактивную веб-сервис на основе Gradio в Colab | Общий | ✅ | ✅ | ✅ | связь | |
| API вызывает | Демонстрация сервера, которая эмулирует интерфейс API OpenAI | Общий | ✅ | ✅ | ✅ | связь |
† : Langchain Framework поддерживает его, но он не реализован в учебном пособии; Пожалуйста, обратитесь к официальной документации Langchain для получения подробной информации.
Для получения подробной информации, пожалуйста, обратитесь к этому проекту >>> github wiki
Чтобы быстро оценить фактическую производительность генерации текста соответствующих моделей, учитывая то же самое, этот проект сравнивал и проверил последствия китайского альпака-7B, китайского альпака-13B, китайского альпака-33B, китайского Alpaca-Plus-7B и китайского Alpaca-Plus-13b в этом проекте на некоторых общих Tasks. На создание ответа является случайным и влияет такие факторы, как декодирование гиперпараметров и случайные семена. Следующие связанные обзоры не являются абсолютно строгими. Результаты испытаний предназначены только для сушки. Вы можете испытать это самостоятельно.
Этот проект также проверил соответствующие модели на наборе объективной оценки «NLU». Результаты этого типа оценки не являются субъективными и требуют только вывода данной теги (необходимо разработать стратегию отображения тегов), поэтому вы можете понять возможности большой модели с другой точки зрения. Этот проект проверил влияние связанных моделей на недавно запущенный набор данных C-Eval, который содержал 12,3K вопросов с несколькими вариантами ответов и охватывал 52 субъекта. Ниже приведены результаты оценки достоверных и набор тестов (среднее) некоторых моделей. Пожалуйста, обратитесь к техническому отчету для полных результатов.
| Модель | Действительно (нулевой выстрел) | Действительно (5-выстрел) | Тест (нулевой выстрел) | Тест (5 выстрелов) |
|---|---|---|---|---|
| Китайско-альпака-плюс-33B | 46.5 | 46.3 | 44,9 | 43,5 |
| Китайско-альпака-33B | 43,3 | 42,6 | 41.6 | 40.4 |
| Китайско-альпака-плюс-13b | 43,3 | 42.4 | 41,5 | 39,9 |
| Китайско-альпака-плюс-7b | 36.7 | 32,9 | 36.4 | 32.3 |
| Китай-лама-плюс-33b | 37.4 | 40.0 | 35,7 | 38.3 |
| Китай-лама-33b | 34.9 | 38.4 | 34.6 | 39,5 |
| Китай-лама-плюс-13b | 27.3 | 34.0 | 27.8 | 33,3 |
| Китай-лама-плюс-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Следует отметить, что всесторонняя оценка способности крупных моделей по -прежнему является важной проблемой, которую необходимо срочно решать. Разумное и диалектическое представление о различных результатах оценки, связанных с большими моделями, поможет здоровому развитию технологии крупной модели. Рекомендуется, чтобы пользователи проверяли задачи, которые они обеспокоены, и выбирать модели, которые адаптируются к связанным задачам.
Пожалуйста, обратитесь к этому проекту для C-Eval Code >>> Github Wiki
Весь процесс обучения включает в себя три части: расширение словарного запаса, предварительное обучение и инструкции.
Для получения подробной информации, пожалуйста, обратитесь к этому проекту >>> github wiki
FAQ получают часто задаваемый вопрос. Пожалуйста, проверьте FAQ, прежде чем попросить проблему.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Пожалуйста, обратитесь к этому проекту для конкретных вопросов и ответов >>> GitHub Wiki
Хотя модели в этом проекте имеют определенные китайские возможности понимания и генерации, они также имеют ограничения, включая, помимо прочего:
Если вы считаете, что этот проект полезен для вашего исследования или используйте код или данные этого проекта, пожалуйста, обратитесь к техническому отчету, ссылаясь на этот проект: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Название проекта | Введение | тип |
|---|---|---|
| Китайско-лама-альпака-2 (официальный проект) | Китайская лама-2, большая модель альпака-2 | текст |
| Визуал-китайз-лама-альпака (официальный проект) | Мультимодальная китайская лама и альпака большая модель | Мультимодальный |
Хотите присоединиться к списку? >>> отправить заявление
Этот проект основан на вторичной разработке следующих проектов с открытым исходным кодом. Я хотел бы выразить свою благодарность соответствующим проектам и сотрудникам по исследованиям и разработкам.
| Базовая модель, код | Количественная оценка, рассуждения, развертывание | данные |
|---|---|---|
| Лама от Facebook Альпака Стэнфорда Alpaca-Lora от @tloen | llama.cpp от @ggerganv Лламачат от @alexrozanski Генерация текста webui от @oobabooga | Pclue и MT Data от @brightmart OASST1 от OpenAssistant |
Ресурсы, связанные с этим проектом, предназначены только для академических исследований и строго запрещены для коммерческих целей. При использовании деталей, включающих сторонний код, пожалуйста, строго следуйте соответствующему протоколу с открытым исходным кодом. На содержание, генерируемое моделью, влияет такие факторы, как расчет модели, случайность и количественная точность. Этот проект не гарантирует его точности. Этот проект не несет никакой юридической ответственности за любые выводы контента по модели, а также не несет ответственности за какие -либо убытки, которые могут возникнуть в результате использования соответствующих ресурсов и результатов выходных данных. Этот проект инициируется и поддерживается отдельными лицами и сотрудниками в свободное время, поэтому невозможно гарантировать, что они могут быстро реагировать на решение соответствующих проблем.
Если у вас есть какие -либо вопросы, пожалуйста, отправьте их в выпуске GitHub. Вежливо задавать вопросы и построить гармоничное дискуссионное сообщество.


