Chinese LLaMA Alpaca
v5.0
??Chinese | English | Documents/Docs | ❓ Questions/Issues | Discussions/Discussions | ⚔️ Arena/Arena

This project open source the Chinese LLaMA model and the instruction-tuned Alpaca model to further promote the open research of the big model in the Chinese NLP community. These models have expanded the Chinese vocabulary list based on the original LLaMA and used Chinese data for secondary pre-training, further improving the basic semantic understanding ability of Chinese. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine adjustment, which significantly improves the model's understanding and execution capabilities of instructions.
Technical Report (V2) : [Cui, Yang, and Yao] Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
Main content of this project:
The figure below shows the actual experience speed and effect of the Chinese Alpaca-Plus-7B model after local CPU quantitative deployment.
Chinese LLaMA-2&Alpaca-2 big model | Multimodal Chinese LLaMA&Alpaca big model | Multimodal VLE | Chinese MiniRBT | Chinese LERT | Chinese English PERT | Chinese MacBERT | Chinese ELECTRA | Chinese XLNet | Chinese BERT | Knowledge distillation tool TextBrewer | Model cutting tool TextPruner
[2024/04/30] Chinese-LLaMA-Alpaca-3 has been officially released, with open source Llama-3-Chinese-8B and Llama-3-Chinese-8B-Instruct based on Llama-3. It is recommended that all phase one and phase two project users upgrade to the third generation model, please refer to: https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
[2024/03/27] This project has been deployed in the Heart of Machine SOTA! model platform, welcome to follow: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] Chinese-LLaMA-Alpaca-2 v2.0 version has been officially released, open source Chinese-LLaMA-2-13B and Chinese-Alpaca-2-13B. It is recommended that all first-phase users upgrade to the second-generation model, please refer to: https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
[2023/07/31] Chinese-LLaMA-Alpaca-2 v1.0 version has been officially released, please refer to: https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
[2023/07/19] v5.0 version: Release the Alpaca-Pro series model, significantly improving the reply length and quality; at the same time, release the Plus-33B series model.
[2023/07/19] Launch the Chinese LLaMA-2 and Alpaca-2 open source big model projects, welcome to follow and learn about the latest information.
[2023/07/10] Beta test preview, learn about the upcoming updates in advance: see the discussion area for details
[2023/07/07] The Chinese-LLaMA-Alpaca family has added another member, launching a multimodal Chinese LLaMA&Alpaca model for visual question and answer and dialogue, and released a 7B test version.
[2023/06/30] 8K context support under llama.cpp (no modification to the model is required). Please refer to the discussion area for related methods and discussions; please refer to PR#705 for codes that support 4K+ context under transformers.
[2023/06/16] v4.1 version: Release a new version of the technical report, add C-Eval decoding scripts, add low-resource model merge scripts, etc.
[2023/06/08] v4.0 version: Release Chinese LLaMA/Alpaca-33B, add privateGPT usage examples, add C-Eval results, etc.
| chapter | describe |
|---|---|
| ⏬Model Download | Chinese LLaMA and Alpaca big model download address |
| ?Merge the model | (Important) Introduce how to merge the downloaded LoRA model with the original LLaMA |
| Local reasoning and rapid deployment | Introduces how to quantify models and deploy and experience large models using a personal computer |
| ?System effects | The user experience effect under some scenarios and tasks is introduced |
| Training details | Introduced the training details of Chinese LLaMA and Alpaca models |
| ❓FAQ | Replies to some FAQs |
| This project involves limitations of the model |
The LLaMA model officially released by Facebook is prohibited from commercial use, and the official does not have official open source model weights (although there are already many third-party download addresses on the Internet). In order to comply with the corresponding permission, the LoRA weights released here can be understood as a "patch" on the original LLaMA model. The two can be combined to obtain the full copyright. The following Chinese LLaMA/Alpaca LoRA model cannot be used alone and needs to be matched with the original LLaMA model. Please refer to the merge model steps given in this project to reconstruct the model.
The following figure shows the relationship between this project and all the big models launched by the second phase project.
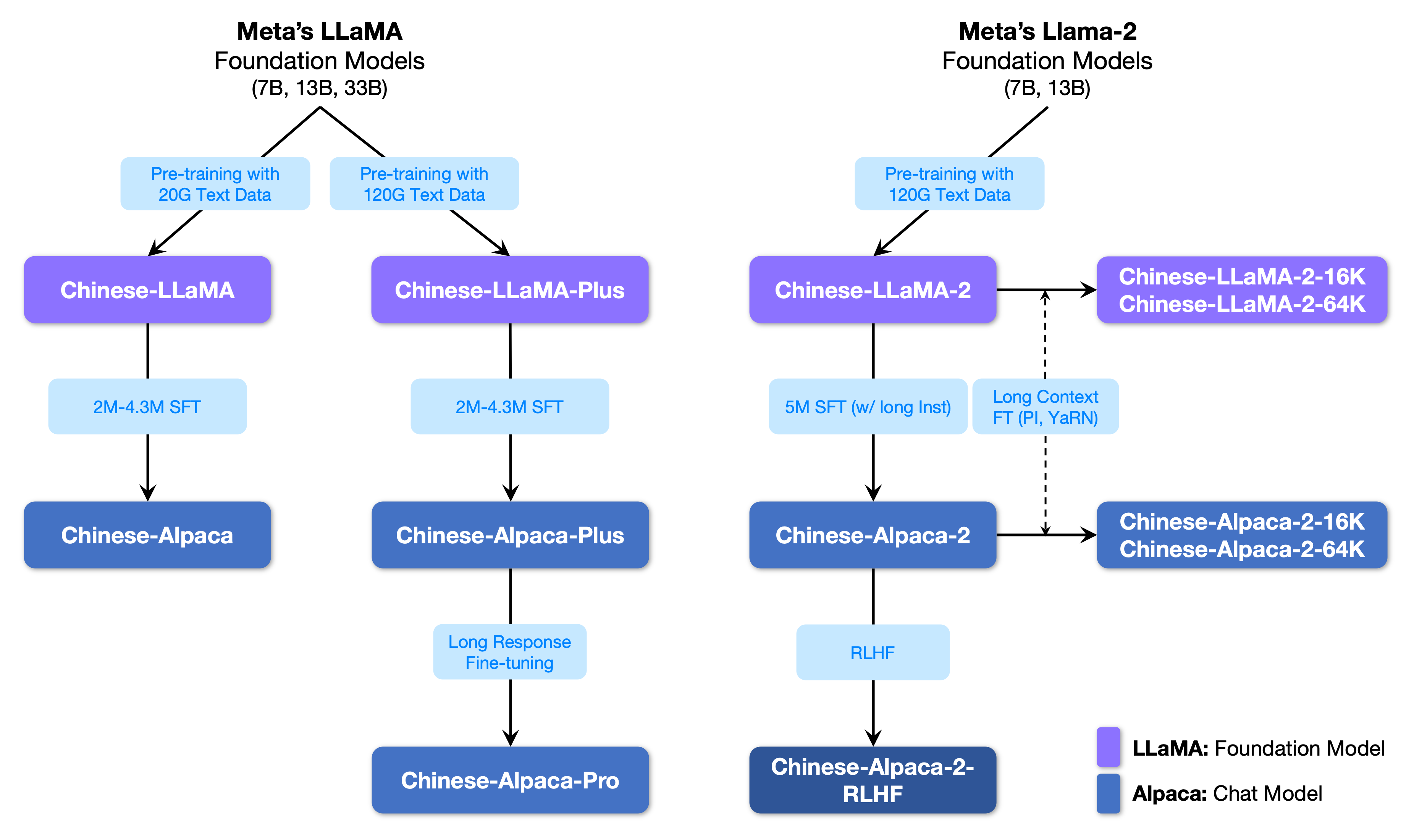
Below is a basic comparison of Chinese LLaMA and Alpaca models and recommended usage scenarios (including but not limited to). For more information, see the training details.
| Comparison items | Chinese LLaMA | Chinese Alpaca |
|---|---|---|
| Training method | Traditional CLM | Instruction fine adjustment |
| Model Type | Base model | Instruction understanding model (class ChatGPT) |
| Training materials | Unmarked general essay | Labeled instruction data |
| Vocabulary size [3] | 4995 3 | 4995 4 =49953+1 (pad token) |
| Input template | unnecessary | Need to meet the template requirements [1] |
| Applicable scenarios ✔️ | Text continuation: Given the above content, let the model generate the following text | Instruction understanding (questions and answers, writing, suggestions, etc.); multi-round context understanding (chat, etc.) |
| Not applicable | Command understanding, multiple rounds of chat, etc. | Unlimited text generation |
| llama.cpp | Use the -p parameter to specify the above | Use the -ins parameter to start the instruction understanding + chat mode |
| text-generation-webui | Not suitable for chat mode | Use --cpu to run without graphics card |
| LlamaChat | Select "LLaMA" when loading the model | Select "Alpaca" when loading the model |
| HF inference code | No additional startup parameters required | Add parameters at startup --with_prompt |
| web-demo code | not applicable | Just provide the Alpaca model position directly; support multiple rounds of conversations |
| LangChain Example/privateGPT | not applicable | Just provide the Alpaca model location directly |
| Known issues | If no control terminates, it will continue to write until the upper output length limit is reached. [2] | Please use the Pro version to avoid the problem of the Plus version being too short. |
[1] llama.cpp/LlamaChat/HF inference code/web-demo code/LangChain examples etc are embedded, no need to add templates manually.
[2] If the model answer quality is particularly low, nonsense, or not understanding the problem, please check whether the correct model and startup parameters are used.
[3] Alpaca with fine-tuned instructions will have one more pad token than LLaMA, so please do not mix the LLaMA/Alpaca vocabulary list .
The following is a list of models recommended for this project. Usually, more training data and optimized model training methods and parameters are used. Please give priority to these models (see other models for the rest of the models). If you want to experience ChatGPT dialogue interaction, please use the Alpaca model instead of the LLaMA model. For the Alpaca model, the Pro version has improved the problem of the response content that is too short, and the model reply effect has been significantly improved; if you prefer short replies, please select the Plus series.
| Model name | type | Training data | Reconstructing the model [1] | Size [2] | LoRA download [3] |
|---|---|---|---|---|---|
| Chinese-LLaMA-Plus-7B | Base model | General purpose 120G | Original LLaMA-7B | 790M | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-LLaMA-Plus-13B | Base model | General purpose 120G | Original LLaMA-13B | 1.0G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-LLaMA-Plus-33B? | Base model | General purpose 120G | Original LLaMA-33B | 1.3G [6] | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Pro-7B? | Instruction Model | Instruction 4.3M | Original LLaMA-7B & LLaMA-Plus-7B [4] | 1.1G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Pro-13B ? | Instruction Model | Instruction 4.3M | Original LLaMA-13B & LLaMA-Plus-13B [4] | 1.3G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Pro-33B ? | Instruction Model | Instruction 4.3M | Original LLaMA-33B & LLaMA-Plus-33B [4] | 2.1G | [Baidu] [Google] [?HF] [?ModelScope] |
[1] Refactoring requires the original LLaMA model, go to the LLaMA project to apply for use or refer to this PR. Due to copyright issues, this project cannot provide a download link.
[2] The reconstructed model size is larger than the original LLaMA of the same magnitude (mainly because of the expanded vocabulary list).
[3] After downloading, be sure to check whether the SHA256 of the model file in the compressed package is consistent. Please check SHA256.md.
[4] The Alpaca-Plus model needs to download the corresponding LLaMA-Plus model at the same time, please refer to the merge tutorial.
[5] Some places call it 30B, but in fact Facebook wrote it wrongly when publishing the model, and the paper still wrote 33B.
[6] Use FP16 storage, so the model size is small.
The file directory in the compressed package is as follows (taking Chinese-LLaMA-7B as an example):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Due to factors such as training methods and training data, the following models are no longer recommended (may still be useful in specific scenarios) . Please give priority to the recommended models in the previous section.
| Model name | type | Training data | Refactoring the model | size | LoRA Download |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | Base model | General 20G | Original LLaMA-7B | 770M | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-LLaMA-13B | Base model | General 20G | Original LLaMA-13B | 1.0G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-LLaMA-33B | Base model | General 20G | Original LLaMA-33B | 2.7G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-7B | Instruction Model | Instruction 2M | Original LLaMA-7B | 790M | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-13B | Instruction Model | Instruction 3M | Original LLaMA-13B | 1.1G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-33B | Instruction Model | Instruction 4.3M | Original LLaMA-33B | 2.8G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Plus-7B | Instruction Model | Instruction 4M | Original LLaMA-7B & LLaMA-Plus-7B | 1.1G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Plus-13B | Instruction Model | Instruction 4.3M | Original LLaMA-13B & LLaMA-Plus-13B | 1.3G | [Baidu] [Google] [?HF] [?ModelScope] |
| Chinese-Alpaca-Plus-33B | Instruction Model | Instruction 4.3M | Original LLaMA-33B & LLaMA-Plus-33B | 2.1G | [Baidu] [Google] [?HF] [?ModelScope] |
All of the above models can be downloaded on Model Hub and the Chinese LLaMA or Alpaca LoRA models can be called using transformers and PEFT. The following model call name refers to the model name specified in .from_pretrained() .
Detailed list and model download address: https://huggingface.co/hfl
As mentioned earlier, the LoRA model cannot be used alone and must be merged with the original LLaMA to be converted into a complete model for model inference, quantification or further training. Please select the following method to convert and merge the model.
| Way | Applicable scenarios | Tutorial |
|---|---|---|
| Online conversion | Colab users can use the notebook provided by this project to convert online and quantify models. | Link |
| Manual conversion | Convert offline, generate models in different formats for quantization or further refinement | Link |
The following is the FP16 precision and 4-bit quantization size after merging the model. Make sure that the machine has sufficient memory and disk space before conversion (minimum requirements):
| Model version | 7B | 13B | 33B | 65B |
|---|---|---|---|---|
| Original model size (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| Quantized size (8-bit) | 7.8 GB | 14.9 GB | 32.4 GB | ~60 GB |
| Quantized size (4-bit) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
For details, please refer to this project >>> GitHub Wiki
The models in this project mainly support the following quantification, reasoning and deployment methods.
| Reasoning and deployment methods | Features | platform | CPU | GPU | Quantitative loading | Graphic interface | Tutorial |
|---|---|---|---|---|---|---|---|
| llama.cpp | Rich quantitative options and efficient local reasoning | General | ✅ | ✅ | ✅ | link | |
| ?Transformers | Native transformers inference interface | General | ✅ | ✅ | ✅ | ✅ | link |
| text-generation-webui | How to deploy the front-end Web UI interface | General | ✅ | ✅ | ✅ | ✅ | link |
| LlamaChat | Graphic Interactive Interface under macOS | MacOS | ✅ | ✅ | ✅ | link | |
| LangChain | LLM application development framework, suitable for secondary development | General | ✅ † | ✅ | ✅ † | link | |
| privateGPT | Multi-document local question and answer framework based on LangChain | General | ✅ | ✅ | ✅ | link | |
| Colab Gradio Demo | Start an interactive Gradio-based web service in Colab | General | ✅ | ✅ | ✅ | link | |
| API calls | Server demo that emulates OpenAI API interface | General | ✅ | ✅ | ✅ | link |
† : The LangChain framework supports it, but it is not implemented in the tutorial; please refer to the official LangChain documentation for details.
For details, please refer to this project >>> GitHub Wiki
In order to quickly evaluate the actual text generation performance of the relevant models, given the same propt, this project compared and tested the effects of Chinese Alpaca-7B, Chinese Alpaca-13B, Chinese Alpaca-33B, Chinese Alpaca-Plus-7B, and Chinese Alpaca-Plus-13B in this project on some common tasks. Generating reply is random and is affected by factors such as decoding hyperparameters and random seeds. The following related reviews are not absolutely rigorous. The test results are for drying reference only. You are welcome to experience it yourself.
This project also tested the relevant models on the objective evaluation set of "NLU". The results of this type of evaluation are not subjective, and only require the output of a given tag (the tag mapping strategy needs to be designed), so you can understand the capabilities of the big model from another perspective. This project tested the effects of related models on the recently launched C-Eval evaluation dataset, which contained 12.3K multiple-choice questions and covered 52 subjects. The following are the valid and test set evaluation results (Average) of some models. Please refer to the technical report for the complete results.
| Model | Valid (zero-shot) | Valid (5-shot) | Test (zero-shot) | Test (5-shot) |
|---|---|---|---|---|
| Chinese-Alpaca-Plus-33B | 46.5 | 46.3 | 44.9 | 43.5 |
| Chinese-Alpaca-33B | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinese-Alpaca-Plus-7B | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-LLaMA-Plus-33B | 37.4 | 40.0 | 35.7 | 38.3 |
| Chinese-LLaMA-33B | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinese-LLaMA-Plus-13B | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-LLaMA-Plus-7B | 27.3 | 28.3 | 26.9 | 28.4 |
It should be noted that comprehensive evaluation of the ability of big models is still an important issue that needs to be solved urgently. A reasonable and dialectical view of various evaluation results related to big models will help the healthy development of big model technology. It is recommended that users test on tasks they are concerned about and select models that adapt to related tasks.
Please refer to this project for C-Eval inference code >>> GitHub Wiki
The entire training process includes three parts: vocabulary expansion, pre-training and instruction fine adjustment.
For details, please refer to this project >>> GitHub Wiki
The FAQ is given a frequently asked question. Please check the FAQ before asking for an Issue.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Please refer to this project for specific questions and answers >>> GitHub Wiki
Although the models in this project have certain Chinese understanding and generation capabilities, they also have limitations, including but not limited to:
If you feel this project is helpful to your research or use the code or data of this project, please refer to the technical report citing this project: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Project name | Introduction | type |
|---|---|---|
| Chinese-LLaMA-Alpaca-2 (official project) | Chinese LLaMA-2, Alpaca-2 big model | text |
| Visual-Chinese-LLaMA-Alpaca (official project) | Multimodal Chinese LLaMA & Alpaca big model | Multimodal |
Want to join the list? >>> Submit an application
This project is based on the secondary development of the following open source projects. I would like to express my gratitude to the relevant projects and research and development staff.
| Basic model, code | Quantification, reasoning, deployment | data |
|---|---|---|
| LLaMA by Facebook Alpaca by Stanford alpaca-lora by @tloen | llama.cpp by @ggerganov LlamaChat by @alexrozanski text-generation-webui by @oobabooga | pCLUE and MT data by @brightmart oasst1 by OpenAssistant |
The resources related to this project are for academic research only and are strictly prohibited for commercial purposes. When using parts involving third-party code, please strictly follow the corresponding open source protocol. The content generated by the model is affected by factors such as model calculation, randomness and quantitative accuracy losses. This project does not guarantee its accuracy. This project assumes no legal liability for any content output by the model, nor is it liable for any losses that may arise from the use of relevant resources and output results. This project is initiated and maintained by individuals and collaborators in their spare time, so it is impossible to guarantee that they can respond promptly to solve the corresponding problems.
If you have any questions, please submit it in GitHub Issue. Ask questions politely and build a harmonious discussion community.


