Chinese LLaMA Alpaca
v5.0
?? Chinês | Inglês | Documentos/documentos | ❓ Perguntas/questões | Discussões/discussões | Arena Arena/arena

Este projeto de código aberto do modelo de lhama chinês e o modelo de alpaca ajustado para instruções para promover ainda mais a pesquisa aberta do grande modelo na comunidade chinesa de PNL. Esses modelos expandiram a lista de vocabulário chinês com base na llama original e usaram dados chineses para pré-treinamento secundário, melhorando ainda mais a capacidade básica de compreensão semântica dos chineses. Ao mesmo tempo, o modelo de alpaca chinês usa ainda mais dados de instruções chinesas para ajuste fino, o que melhora significativamente os recursos de compreensão e execução do modelo de instruções.
Relatório Técnico (V2) : [CUI, Yang e Yao] Eficiente e eficaz de texto para lhama e alpaca chinesa
Principal conteúdo deste projeto:
A figura abaixo mostra a velocidade real da experiência e o efeito do modelo chinês de alpaca-plus-7b após a implantação quantitativa da CPU local.
LLAMA-2 E ALPACA-2 MODELO DE GRANDES | Llama chinês multimodal e grande modelo de alpaca | Vle multimodal | Minirbt chinês | Lert chinês | Pert inglesa chinesa | MacBert chinês | Electra chinês | Xlnet chinês | Bert chinês | Ferramenta de destilação do conhecimento Textbrewer | Ferramenta de corte de modelos Princinente de texto
[2024/04/30] Chinês-llama-alpaca-3 foi lançado oficialmente, com a LLama-3-Chinese-8b de código aberto e a instrução LLAMA-3-CHINESE-8B baseada no LLAMA-3. Recomenda-se que todos os usuários do projeto de fase um e dois atualizem para o modelo de terceira geração, consulte: https://github.com/ymcui/chinese-llama-alpaca-3
[2024/03/27] Este projeto foi implantado no coração da máquina SOTA! Modelo Plataforma, Bem-vindo a seguir: https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] A versão chinesa-lama-alpaca-2 v2.0 foi lançada oficialmente, o código aberto chinês-lama-2-13b e chinês-alpaca-2-13b. Recomenda-se que todos os usuários da primeira fase atualizem para o modelo de segunda geração, consulte: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/31] A versão chinesa-llama-alpaca-2 v1.0 foi lançada oficialmente, consulte: https://github.com/ymcui/chinese-llama-alpaca-2
[2023/07/19] VERSÃO V5.0: Libere o modelo da série Alpaca-Pro, melhorando significativamente o comprimento e a qualidade da resposta; Ao mesmo tempo, libere o modelo da série Plus-33B.
[2023/07/19] Lançar os projetos de modelo de código aberto do LLAMA-2 e ALPACA-2 chinês, bem-vindo a seguir e aprender sobre as informações mais recentes.
[2023/07/10] Visualização do teste beta, aprenda sobre as próximas atualizações com antecedência: consulte a área de discussão para obter detalhes
[2023/07/07] A família Chinese-Llama-Alpaca adicionou outro membro, lançando um modelo multimodal chinês de llama e alpaca para perguntas, respostas e diálogos visuais e lançou uma versão de teste 7B.
[2023/06/30] Suporte de contexto 8K em llama.cpp (nenhuma modificação no modelo é necessária). Consulte a área de discussão para obter métodos e discussões relacionadas; Consulte o PR#705 para obter códigos que suportam o contexto 4K+ em Transformers.
[2023/06/16] VERSÃO V4.1: Libere uma nova versão do relatório técnico, adicione scripts de decodificação C-EVAL, adicione scripts de mesclagem de modelo de baixo recurso, etc.
[2023/06/08] VERSÃO V4.0: Libere a llama/alpaca-33b chinês, adicione exemplos de uso privado, adicionar resultados C-EVAL, etc.
| capítulo | descrever |
|---|---|
| ⏬Model Download | Lhama chinês e endereço de download de modelo grande de alpaca |
| ? Mescle o modelo | (IMPORTANTE) Apresente como mesclar o modelo Lora baixado com a llama original |
| Raciocínio local e implantação rápida | Introduz como quantificar modelos e implantar e experimentar modelos grandes usando um computador pessoal |
| ? Efeitos do sistema | O efeito da experiência do usuário em alguns cenários e tarefas é introduzido |
| Detalhes de treinamento | Introduziu os detalhes de treinamento dos modelos chineses de lhama e alpaca |
| ❓faq | Respostas a algumas perguntas frequentes |
| Este projeto envolve limitações do modelo |
O modelo LLAMA lançado oficialmente pelo Facebook é proibido de uso comercial, e o oficial não possui pesos oficiais do modelo de código aberto (embora já existam muitos endereços de download de terceiros na Internet). Para cumprir a permissão correspondente, os pesos da LORA lançados aqui podem ser entendidos como um "patch" no modelo de llama original. Os dois podem ser combinados para obter os direitos autorais completos. A seguinte modelo de lhama/alpaca lora não pode ser usada sozinha e precisa ser compatível com o modelo de lhama original. Consulte as etapas do modelo de mesclagem fornecidas neste projeto para reconstruir o modelo.
A figura a seguir mostra a relação entre este projeto e todos os grandes modelos lançados pelo projeto da segunda fase.
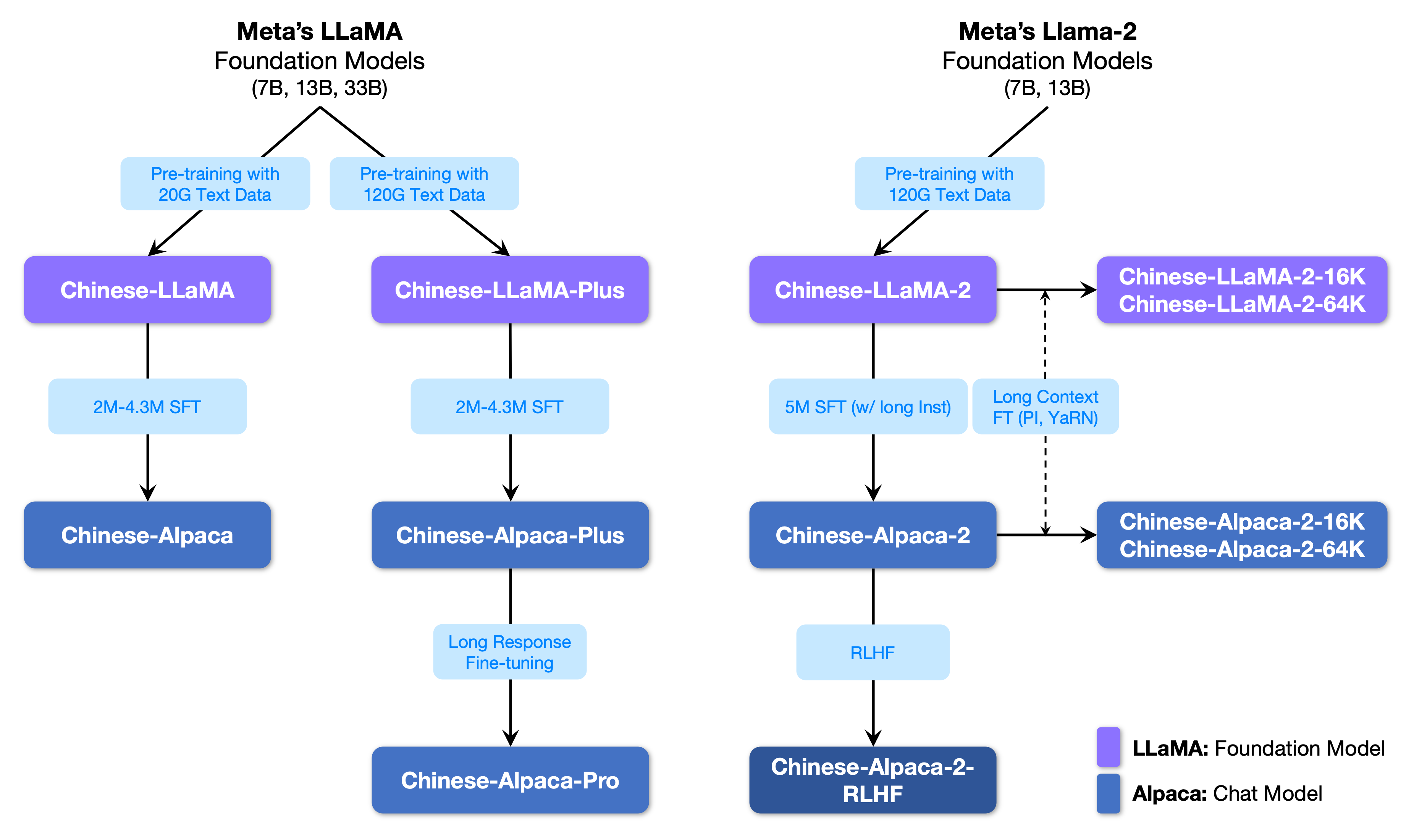
Abaixo está uma comparação básica dos modelos chineses de lhama e alpaca e cenários de uso recomendados (incluindo, entre outros). Para mais informações, consulte os detalhes do treinamento.
| Itens de comparação | Lhama chinesa | Alpaca chinesa |
|---|---|---|
| Método de treinamento | CLM tradicional | Instrução Ajuste fino |
| Tipo de modelo | Modelo base | Modelo de compreensão de instrução (classe chatgpt) |
| Materiais de treinamento | Ensaio geral não marcado | Dados de instrução rotulados |
| Tamanho do vocabulário [3] | 4995 3 | 4995 4 = 49953+1 (token de bloco) |
| Modelo de entrada | desnecessário | Precisa atender aos requisitos de modelo [1] |
| Cenários aplicáveis ✔️ | Continuação de texto: Dado o conteúdo acima, deixe o modelo gerar o seguinte texto | Entendimento de instrução (perguntas e respostas, escrita, sugestões, etc.); Entendimento de contexto de várias rodadas (bate-papo, etc.) |
| Não aplicável | Comando de entendimento, várias rodadas de bate -papo, etc. | Geração de texto ilimitada |
| llama.cpp | Use o parâmetro -p para especificar o acima | Use o parâmetro -ins para iniciar o entendimento da instrução + modo de bate -papo |
| GENERAÇÃO DE TEXTO-WEBUI | Não é adequado para o modo de chat | Use --cpu para ser executado sem a placa gráfica |
| Llamachat | Selecione "Llama" ao carregar o modelo | Selecione "Alpaca" ao carregar o modelo |
| Código de inferência da HF | Não são necessários parâmetros de inicialização adicionais | Adicionar parâmetros na startup --with_prompt |
| Código da Web-Demo | não aplicável | Basta fornecer a posição do modelo Alpaca diretamente; Apoie várias rodadas de conversas |
| Exemplo de Langchain/privateGPT | não aplicável | Basta fornecer a localização do modelo Alpaca diretamente |
| Questões conhecidas | Se nenhum controle terminar, continuará a escrever até que o limite de comprimento de saída superior seja atingido. [2] | Use a versão Pro para evitar o problema da versão Plus muito curta. |
[1] LLAMA.CPP/LLAMACHAT/HF Código de inferência/código de democonização da Web/exemplos de Langchain etc. são incorporados, não há necessidade de adicionar modelos manualmente.
[2] Se a qualidade da resposta do modelo for particularmente baixa, absurdo ou não entender o problema, verifique se os parâmetros de modelo e inicialização corretos são usados.
[3] Alpaca com instruções de ajuste fino terá mais um token de bloco do que lhama, então, por favor, não misture a lista de vocabulário LLAMA/ALPACA .
A seguir, é apresentada uma lista de modelos recomendados para este projeto. Geralmente, são utilizados mais dados de treinamento e métodos e parâmetros de treinamento de modelos otimizados. Por favor, priorize esses modelos (consulte outros modelos para o restante dos modelos). Se você deseja experimentar a interação do diálogo ChatGPT, use o modelo ALPACA em vez do modelo LLAMA. Para o modelo ALPACA, a versão Pro melhorou o problema do conteúdo da resposta muito curto e o efeito da resposta do modelo foi significativamente melhorado; Se você preferir respostas curtas, selecione a série Plus.
| Nome do modelo | tipo | Dados de treinamento | Reconstruindo o modelo [1] | Tamanho [2] | Lora Download [3] |
|---|---|---|---|---|---|
| Chinês-llama-plus-7b | Modelo base | Objetivo geral 120g | Llama-7b original | 790m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-llama-plus-13b | Modelo base | Objetivo geral 120g | Llama-13b original | 1.0g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-llama-plus-33b? | Modelo base | Objetivo geral 120g | LLAMA-33B ORIGINAL | 1.3g [6] | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-pro-7b? | Modelo de instrução | Instrução 4.3m | Llama-7b original e Llama-plus-7b [4] | 1.1g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-Alpaca-Pro-13b? | Modelo de instrução | Instrução 4.3m | Lhama-13b original e Llama-plus-13b [4] | 1.3g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-pro-33b? | Modelo de instrução | Instrução 4.3m | Llama-33b original e Llama-plus-33b [4] | 2.1g | [Baidu] [Google] [? HF] [? Modelscope] |
[1] A refatoração requer o modelo de llama original, vá ao projeto LLAMA para se inscrever para uso ou consulte este PR. Devido a problemas de direitos autorais, este projeto não pode fornecer um link de download.
[2] O tamanho do modelo reconstruído é maior que a llama original da mesma magnitude (principalmente por causa da lista de vocabulário expandido).
[3] Após o download, verifique se o SHA256 do arquivo de modelo no pacote compactado é consistente. Por favor, verifique sha256.md.
[4] O modelo ALPACA-Plus precisa baixar o modelo llama-plus correspondente ao mesmo tempo, consulte o tutorial de mesclagem.
[5] Alguns lugares chamam de 30b, mas na verdade o Facebook escreveu incorretamente ao publicar o modelo, e o artigo ainda escreveu 33b.
[6] Use o armazenamento FP16, para que o tamanho do modelo seja pequeno.
O diretório de arquivos no pacote compactado é o seguinte (tomando chinês-llama-7b como exemplo):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
Devido a fatores como métodos de treinamento e dados de treinamento, os modelos a seguir não são mais recomendados (ainda podem ser úteis em cenários específicos) . Por favor, priorize os modelos recomendados na seção anterior.
| Nome do modelo | tipo | Dados de treinamento | Refatorando o modelo | tamanho | Lora Download |
|---|---|---|---|---|---|
| Chinês-llama-7b | Modelo base | Geral 20G | Llama-7b original | 770m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-llama-13b | Modelo base | Geral 20G | Llama-13b original | 1.0g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-llama-33b | Modelo base | Geral 20G | LLAMA-33B ORIGINAL | 2.7g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-7b | Modelo de instrução | Instrução 2m | Llama-7b original | 790m | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-13b | Modelo de instrução | Instrução 3m | Llama-13b original | 1.1g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-33b | Modelo de instrução | Instrução 4.3m | LLAMA-33B ORIGINAL | 2.8g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-plus-7b | Modelo de instrução | Instrução 4m | Llama-7b original e Llama-plus-7b | 1.1g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-plus-13b | Modelo de instrução | Instrução 4.3m | Lhama-13b original e LLAMA-PLUS-13B | 1.3g | [Baidu] [Google] [? HF] [? Modelscope] |
| Chinês-alpaca-plus-33b | Modelo de instrução | Instrução 4.3m | Llama-33b original e LLAMA-PLUS-33B | 2.1g | [Baidu] [Google] [? HF] [? Modelscope] |
Todos os modelos acima podem ser baixados no Model Hub e os modelos chineses de llama ou alpaca lora podem ser chamados usando Transformers e Peft. O nome da chamada do modelo a seguir refere -se ao nome do modelo especificado em .from_pretrained() .
Lista detalhada e modelo de download do modelo: https://huggingface.co/hfl
Como mencionado anteriormente, o modelo Lora não pode ser usado sozinho e deve ser mesclado com a lhama original para ser convertido em um modelo completo para inferência, quantificação ou treinamento adicional. Selecione o seguinte método para converter e mesclar o modelo.
| Caminho | Cenários aplicáveis | Tutorial |
|---|---|---|
| Conversão online | Os usuários do COLAB podem usar o notebook fornecido por este projeto para converter on -line e quantificar modelos. | Link |
| Conversão manual | Converter offline, gerar modelos em diferentes formatos para quantização ou refinamento adicional | Link |
A seguir, é apresentada a precisão do FP16 e o tamanho da quantização de 4 bits após a fusão do modelo. Certifique -se de que a máquina tenha espaço suficiente para memória e disco antes da conversão (requisitos mínimos):
| Versão modelo | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| Tamanho do modelo original (FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| Tamanho quantizado (8 bits) | 7,8 GB | 14,9 GB | 32,4 GB | ~ 60 GB |
| Tamanho quantizado (4 bits) | 3,9 GB | 7,8 GB | 17,2 GB | 38,5 GB |
Para detalhes, consulte este projeto >>> wiki do github
Os modelos deste projeto suportam principalmente os seguintes métodos de quantificação, raciocínio e implantação.
| Métodos de raciocínio e implantação | Características | plataforma | CPU | GPU | Carregamento quantitativo | Interface gráfica | Tutorial |
|---|---|---|---|---|---|---|---|
| llama.cpp | Ricas opções quantitativas e raciocínio local eficiente | Em geral | ✅ | ✅ | ✅ | link | |
| ? Transformadores | Interface de inferência dos transformadores nativos | Em geral | ✅ | ✅ | ✅ | ✅ | link |
| GENERAÇÃO DE TEXTO-WEBUI | Como implantar a interface da interface do usuário do front-end | Em geral | ✅ | ✅ | ✅ | ✅ | link |
| Llamachat | Interface interativa gráfica em macOS | Macos | ✅ | ✅ | ✅ | link | |
| Langchain | LLM Application Development Framework, adequado para desenvolvimento secundário | Em geral | ✅ † | ✅ | ✅ † | link | |
| privategpt | Multi-Document Local Question and Response Framework baseado em Langchain | Em geral | ✅ | ✅ | ✅ | link | |
| Demoção de Colab Gradio | Inicie um serviço web interativo baseado em graduação em colab | Em geral | ✅ | ✅ | ✅ | link | |
| Chamadas de API | Demoção do servidor que emula a interface da API OpenAi | Em geral | ✅ | ✅ | ✅ | link |
† : A estrutura Langchain suporta -a, mas não é implementada no tutorial; Consulte a documentação oficial de Langchain para obter detalhes.
Para detalhes, consulte este projeto >>> wiki do github
Para avaliar rapidamente o desempenho real da geração de texto dos modelos relevantes, dada a mesma propt, este projeto comparou e testou os efeitos da alpaca-7b chinesa, alpaca-13b chinês, alpaca-333 chinês, alpacA-mais chinês e alpaca-plus-plus-13B chinês neste projeto nesse projeto. A geração de resposta é aleatória e é afetada por fatores como decodificar hiperparâmetros e sementes aleatórias. As seguintes críticas relacionadas não são absolutamente rigorosas. Os resultados do teste são apenas para referência de secagem. Você pode experimentar você mesmo.
Este projeto também testou os modelos relevantes no conjunto de avaliação objetivo de "NLU". Os resultados desse tipo de avaliação não são subjetivos e exigem apenas a saída de uma determinada tag (a estratégia de mapeamento de tags precisa ser projetada), para que você possa entender as capacidades do grande modelo de outra perspectiva. Este projeto testou os efeitos de modelos relacionados no conjunto de dados de avaliação C-Eval lançado recentemente, que continha 12,3 mil perguntas de múltipla escolha e abrangeu 52 indivíduos. A seguir, são apresentados os resultados de avaliação válida e de conjunto de testes (média) de alguns modelos. Consulte o relatório técnico para obter os resultados completos.
| Modelo | Válido (Zero-Shot) | Válido (5-shot) | Teste (zero-shot) | Teste (5-shot) |
|---|---|---|---|---|
| Chinês-alpaca-plus-33b | 46.5 | 46.3 | 44.9 | 43.5 |
| Chinês-alpaca-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinês-alpaca-plus-13b | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinês-alpaca-plus-7b | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinês-llama-plus-33b | 37.4 | 40.0 | 35.7 | 38.3 |
| Chinês-llama-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinês-llama-plus-13b | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinês-llama-plus-7b | 27.3 | 28.3 | 26.9 | 28.4 |
Deve -se notar que uma avaliação abrangente da capacidade dos grandes modelos ainda é uma questão importante que precisa ser resolvida com urgência. Uma visão razoável e dialética de vários resultados de avaliação relacionados a grandes modelos ajudará o desenvolvimento saudável da grande tecnologia de modelos. Recomenda -se que os usuários testem as tarefas com as quais se preocupem e selecione modelos que se adaptam às tarefas relacionadas.
Consulte este projeto para o código de inferência C-EVAL >>> github wiki
Todo o processo de treinamento inclui três partes: expansão do vocabulário, ajuste fino de pré-treinamento e instrução.
Para detalhes, consulte este projeto >>> wiki do github
A FAQ recebe uma pergunta frequente. Verifique as perguntas frequentes antes de pedir um problema.
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
Consulte este projeto para obter perguntas e respostas específicas >>> wiki do github
Embora os modelos deste projeto tenham certos recursos de compreensão e geração chineses, eles também têm limitações, incluindo, entre outros,:
Se você acha que este projeto é útil para sua pesquisa ou use o código ou os dados deste projeto, consulte o relatório técnico citando este projeto: https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| Nome do projeto | Introdução | tipo |
|---|---|---|
| Chinês-llama-alpaca-2 (projeto oficial) | Lhama chinês-2, alpaca-2 grande modelo | texto |
| Visual-Chinese-Llama-Alpaca (Projeto Oficial) | Modelo Big Multimodal Chinese Lhama & Alpaca | Multimodal |
Quer ingressar na lista? >>> Envie uma inscrição
Este projeto é baseado no desenvolvimento secundário dos seguintes projetos de código aberto. Gostaria de expressar minha gratidão aos projetos relevantes e à equipe de pesquisa e desenvolvimento.
| Modelo básico, código | Quantificação, raciocínio, implantação | dados |
|---|---|---|
| Lhama pelo Facebook Alpaca por Stanford Alpaca-Lora por @Tloen | llama.cpp por @ggerganov Llamachat por @alexrozanski Geração de texto-webui por @oobabooga | Dados Pclue e MT por @brightmart OASST1 por OpenAssistant |
Os recursos relacionados a este projeto são apenas para pesquisa acadêmica e são estritamente proibidos para fins comerciais. Ao usar peças envolvendo código de terceiros, siga estritamente o protocolo de código aberto correspondente. O conteúdo gerado pelo modelo é afetado por fatores como cálculo do modelo, aleatoriedade e perdas de precisão quantitativa. Este projeto não garante sua precisão. Este projeto não assume nenhuma responsabilidade legal por qualquer saída de conteúdo pelo modelo, nem é responsável por quaisquer perdas que possam surgir do uso de recursos relevantes e resultados de saída. Este projeto é iniciado e mantido por indivíduos e colaboradores em seu tempo livre, por isso é impossível garantir que eles possam responder prontamente para resolver os problemas correspondentes.
Se você tiver alguma dúvida, envie -o no problema do GitHub. Faça perguntas educadamente e construa uma comunidade de discussão harmoniosa.


