Chinese LLaMA Alpaca
v5.0
??中国語|英語|ドキュメント/ドキュメント| ❓質問/問題|ディスカッション/ディスカッション| ⚔️アリーナ/アリーナ

このプロジェクトは、中国のラマモデルと命令チューニングされたアルパカモデルをオープンソースして、中国のNLPコミュニティにおける大きなモデルのオープンな研究をさらに促進します。これらのモデルは、元のLlamaに基づいて中国の語彙リストを拡張し、中国のデータを二次的なトレーニングに使用し、中国語の基本的な意味的理解能力をさらに改善しました。同時に、中国のAlpacaモデルは、微調整のために中国の指導データをさらに使用し、モデルの指示の理解と実行機能を大幅に改善します。
テクニカルレポート(V2) :[CUI、Yang、Yao]中国のラマとアルパカ向けの効率的で効果的なテキストエンコード
このプロジェクトの主な内容:
以下の図は、ローカルCPUの定量的展開後の中国のAlpaca-Plus-7Bモデルの実際の経験速度と効果を示しています。
中国のllama-2&alpaca-2ビッグモデル|マルチモーダルチャイニーズラマ&アルパカビッグモデル|マルチモーダルVLE |中国のミニルブ|中国語のレート|中国の英語のパート|中国のマッバート|中国のエレクトラ|中国のxlnet |中国のバート|知識蒸留ツールTextBrewer |モデル切削工具TextPruner
[2024/04/30]中国語 - ラマ-Alpaca-3は、Llama-3に基づいて、オープンソースのLlama-3-Chinese-8BおよびLlama-3-Cinese-8B-Instructを使用して公式にリリースされました。すべてのフェーズ1およびフェーズ2のプロジェクトユーザーが第3世代モデルにアップグレードすることをお勧めします。https://github.com/ymcui/chinese-llama-alpaca-3を参照してください。
[2024/03/27]このプロジェクトは、マシンソタの中心に展開されています!モデルプラットフォーム、https://sota.jiqizhixin.com/project/chinese-llama-alpacaをフォローしてください
[2023/08/14]中国語 - ラマ-Alpaca-2 V2.0バージョンが公式にリリースされました。オープンソースの中国 - ラマ-2-13bおよび中国アルパカ-2-13b。すべての第1フェーズユーザーが第2世代モデルにアップグレードすることをお勧めします。https://github.com/ymcui/chinese-llama-alpaca-2を参照してください。
[2023/07/31]中国語 - ラマ - アルパカ-2 V1.0バージョンが正式にリリースされました。https://github.com/ymcui/chinese-llama-alpaca-2を参照してください。
[2023/07/19] V5.0バージョン:Alpaca-Proシリーズモデルをリリースし、返信の長さと品質を大幅に改善します。同時に、Plus-33Bシリーズモデルをリリースします。
[2023/07/19]中国のllama-2およびalpaca-2オープンソースの大規模なモデルプロジェクトを開始し、最新情報をフォローして学ぶことができます。
[2023/07/10]ベータテストのプレビュー、事前に今後の更新について学ぶ:詳細については、ディスカッション領域を参照してください
[2023/07/07]中国 - ラマ・アルパカファミリーは別のメンバーを追加し、視覚的な質問と回答と対話のためにマルチモーダルの中国のラマとアルパカモデルを立ち上げ、7Bテストバージョンをリリースしました。
[2023/06/30] llama.cppに基づく8Kコンテキストサポート(モデルの変更は不要)。関連する方法とディスカッションについては、ディスカッション領域を参照してください。トランスの下の4K+コンテキストをサポートするコードについては、PR#705を参照してください。
[2023/06/16] v4.1バージョン:テクニカルレポートの新しいバージョンをリリースし、C-Valデコードスクリプトを追加し、低リソースモデルマージスクリプトなどを追加します。
[2023/06/08] v4.0バージョン:中国のllama/alpaca-33bをリリースし、privateptの使用例を追加し、c-val結果を追加します。
| 章 | 説明する |
|---|---|
| modelダウンロード | 中国のラマとアルパカのビッグモデルのダウンロードアドレス |
| モデルをマージします | (重要)ダウンロードしたLoraモデルと元のLlamaをマージする方法を紹介します |
| 地元の推論と迅速な展開 | モデルを定量化し、パーソナルコンピューターを使用して大規模なモデルを展開して体験する方法を紹介する |
| ?システム効果 | いくつかのシナリオとタスクの下でユーザーエクスペリエンス効果が導入されています |
| トレーニングの詳細 | 中国のラマモデルとアルパカモデルのトレーニングの詳細を紹介しました |
| ❓faq | いくつかのFAQへの返信 |
| このプロジェクトには、モデルの制限が含まれます |
Facebookが公式にリリースしたLlamaモデルは、商業用途が禁止されており、公式のオープンソースモデルの重みはありません(ただし、インターネットにはすでにサードパーティのダウンロードアドレスがたくさんあります)。対応する許可を順守するために、ここで解放されたロラの重みは、元のLlamaモデルの「パッチ」として理解できます。 2つを組み合わせて、完全な著作権を取得できます。次の中国のllama/alpaca loraモデルは単独で使用することはできず、元のllamaモデルと一致させる必要があります。モデルを再構築するために、このプロジェクトで与えられたマージモデルの手順を参照してください。
次の図は、このプロジェクトと第2フェーズプロジェクトによって開始されたすべての大きなモデルとの関係を示しています。
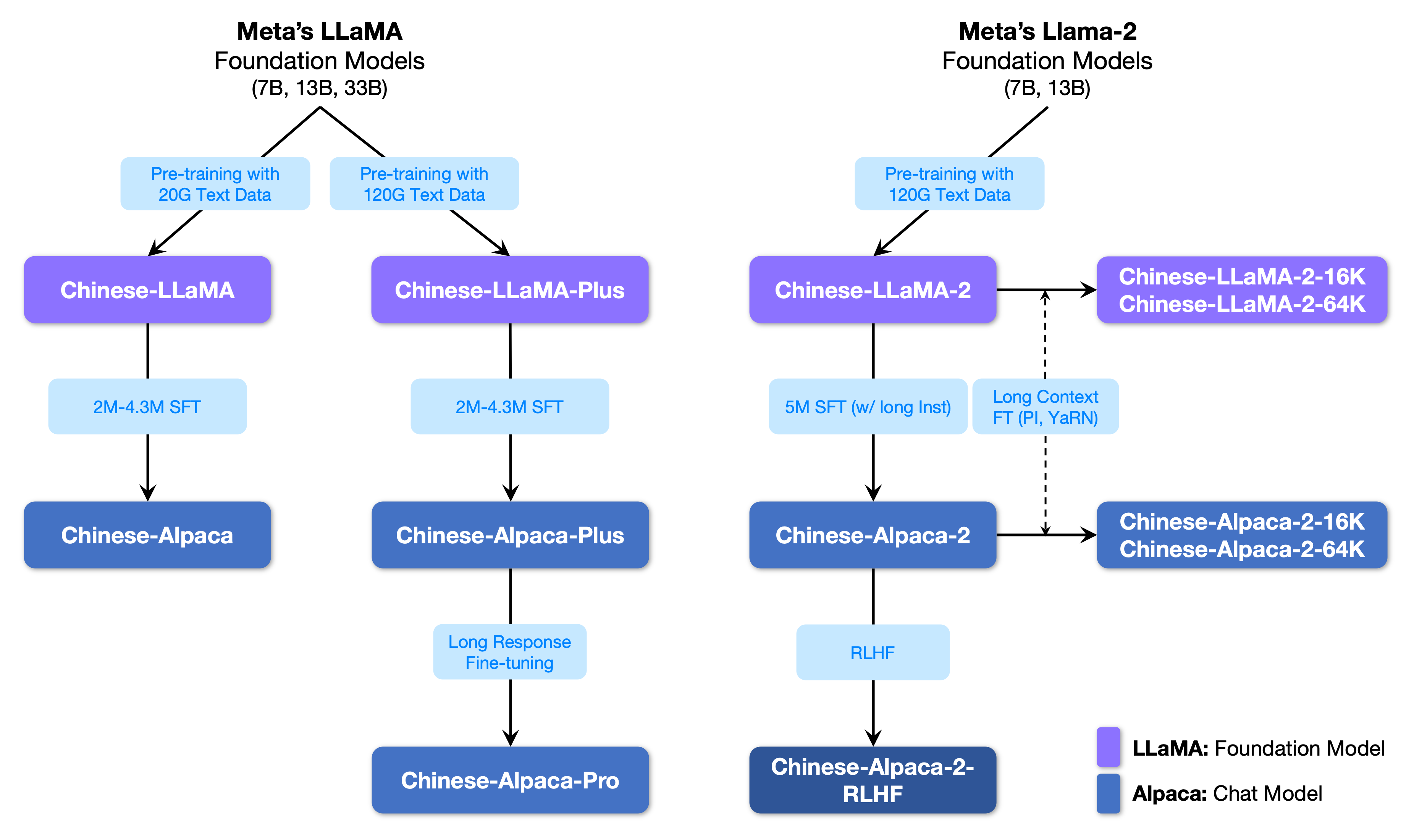
以下は、中国のラマモデルとアルパカモデルの基本的な比較と、推奨される使用シナリオ(を含むがこれらに限定されない)です。詳細については、トレーニングの詳細を参照してください。
| 比較項目 | 中国のラマ | 中国のアルパカ |
|---|---|---|
| トレーニング方法 | 従来のCLM | 指示の微細な調整 |
| モデルタイプ | ベースモデル | 指示理解モデル(クラスchatgpt) |
| トレーニング資料 | マークされていない一般的なエッセイ | ラベル付き命令データ |
| 語彙サイズ[3] | 4995 3 | 4995 4 = 49953+1(パッドトークン) |
| 入力テンプレート | 不要 | テンプレートの要件を満たす必要があります[1] |
| 該当するシナリオ✔️ | テキストの継続:上記のコンテンツを考えると、モデルに次のテキストを生成させます | 指示の理解(質問と回答、執筆、提案など);マルチラウンドコンテキストの理解(チャットなど) |
| 適用できない | コマンドの理解、複数のラウンドのチャットなど。 | 無制限のテキスト生成 |
| llama.cpp | -pパラメーターを使用して、上記を指定します | -insパラメーターを使用して、命令の理解 +チャットモードを開始します |
| Text-Generation-Webui | チャットモードには適していません | --cpuを使用してグラフィックカードなしで実行します |
| ラマチャット | モデルをロードするときに「llama」を選択します | モデルをロードするときに「Alpaca」を選択します |
| HF推論コード | 追加のスタートアップパラメーターは必要ありません | 起動時にパラメーターを追加--with_prompt |
| Web-Demoコード | 適用できない | Alpacaモデルの位置を直接提供するだけです。複数のラウンドの会話をサポートします |
| langchainの例/privategpt | 適用できない | Alpacaモデルの場所を直接提供するだけです |
| 既知の問題 | コントロールが終了しない場合、上部の出力長制限に達するまで書き込みを続けます。 [2] | Plusバージョンを使用して、Plusバージョンが短すぎるという問題を回避してください。 |
[1] llama.cpp/llamachat/hf推論コード/web-demoコード/langchainの例などが組み込まれており、テンプレートを手動で追加する必要はありません。
[2]モデルの回答の品質が特に低い場合、ナンセンス、または問題を理解していない場合は、正しいモデルと起動パラメーターが使用されているかどうかを確認してください。
[3]微調整された手順を備えたAlpacaには、Llamaよりも1つのパッドトークンがありますので、Llama/Alpacaの語彙リストを混ぜないでください。
以下は、このプロジェクトに推奨されるモデルのリストです。通常、より多くのトレーニングデータと最適化されたモデルトレーニング方法とパラメーターが使用されます。これらのモデルを優先してください(残りのモデルについては、他のモデルを参照してください)。 ChatGpt Dialogue Interactionを体験したい場合は、Llamaモデルの代わりにAlpacaモデルを使用してください。 ALPACAモデルの場合、PROバージョンは短すぎる応答コンテンツの問題を改善し、モデルの応答効果が大幅に改善されました。短い返信が必要な場合は、Plusシリーズを選択してください。
| モデル名 | タイプ | トレーニングデータ | モデルの再構築[1] | サイズ[2] | ロラダウンロード[3] |
|---|---|---|---|---|---|
| 中国語 - ラマプラス7B | ベースモデル | 汎用120g | オリジナルのllama-7b | 790m | [Baidu] [Google] [?hf] [?modelscope] |
| 中国語 - ラマ-Plus-13B | ベースモデル | 汎用120g | オリジナルのllama-13b | 1.0g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国語 - ラマプラス33b? | ベースモデル | 汎用120g | オリジナルのllama-33b | 1.3g [6] | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-Pro-7B? | 指導モデル | 指示4.3m | オリジナルのllama-7b& llama-plus-7b [4] | 1.1g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-Pro-13B? | 指導モデル | 指示4.3m | オリジナルのllama-13b& llama-plus-13b [4] | 1.3g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-Pro-33B? | 指導モデル | 指示4.3m | オリジナルのllama-33b& llama-plus-33b [4] | 2.1g | [Baidu] [Google] [?hf] [?modelscope] |
[1]リファクタリングには、元のllamaモデルが必要で、Llamaプロジェクトにアクセスして使用を申請するか、このPRを参照してください。著作権の問題により、このプロジェクトはダウンロードリンクを提供できません。
[2]再構築されたモデルサイズは、同じ大きさの元のラマよりも大きくなっています(主に語彙リストが拡張されているため)。
[3]ダウンロード後、圧縮パッケージのモデルファイルのSHA256が一貫しているかどうかを確認してください。 sha256.mdを確認してください。
[4] Alpaca-Plusモデルは、対応するLlama-Plusモデルを同時にダウンロードする必要があります。Mergeチュートリアルを参照してください。
[5]いくつかの場所はそれを30Bと呼んでいますが、実際にFacebookはモデルを公開するときに誤ってそれを書きましたが、論文はまだ33bを書きました。
[6] FP16ストレージを使用するため、モデルサイズが小さいように。
圧縮パッケージのファイルディレクトリは次のとおりです(例として中国語のラマ-7Bを取得):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
トレーニング方法やトレーニングデータなどの要因により、次のモデルは推奨されなくなります(特定のシナリオでは依然として役立つ場合があります) 。前のセクションの推奨モデルを優先してください。
| モデル名 | タイプ | トレーニングデータ | モデルのリファクタリング | サイズ | ロラダウンロード |
|---|---|---|---|---|---|
| 中国語 - ラマ-7b | ベースモデル | 一般20g | オリジナルのllama-7b | 770m | [Baidu] [Google] [?hf] [?modelscope] |
| 中国語-llama-13b | ベースモデル | 一般20g | オリジナルのllama-13b | 1.0g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国語 - ラマ-33b | ベースモデル | 一般20g | オリジナルのllama-33b | 2.7g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-7b | 指導モデル | 指示2m | オリジナルのllama-7b | 790m | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-13b | 指導モデル | 指示3m | オリジナルのllama-13b | 1.1g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-33b | 指導モデル | 指示4.3m | オリジナルのllama-33b | 2.8g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカプラス7B | 指導モデル | 指示4m | オリジナルのllama-7b& llama-plus-7b | 1.1g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカ-Plus-13B | 指導モデル | 指示4.3m | オリジナルのllama-13b& llama-plus-13b | 1.3g | [Baidu] [Google] [?hf] [?modelscope] |
| 中国アルパカプラス33b | 指導モデル | 指示4.3m | オリジナルのllama-33b& llama-plus-33b | 2.1g | [Baidu] [Google] [?hf] [?modelscope] |
上記のすべてのモデルはモデルハブにダウンロードでき、中国のラマまたはアルパカロラモデルは、トランスとPEFTを使用して呼び出すことができます。次のモデル呼び出し名は.from_pretrained()で指定されたモデル名を指します。
詳細なリストとモデルのダウンロードアドレス:https://huggingface.co/hfl
前述のように、LORAモデルは単独で使用することはできず、モデルの推論、定量化、またはさらなるトレーニングのための完全なモデルに変換されるように、元のLlamaとマージする必要があります。モデルを変換してマージするには、次の方法を選択してください。
| 方法 | 適用可能なシナリオ | チュートリアル |
|---|---|---|
| オンライン変換 | Colabユーザーは、このプロジェクトが提供するノートブックを使用して、オンラインで変換してモデルを定量化できます。 | リンク |
| 手動変換 | オフラインに変換し、量子化またはさらなる改良のためにさまざまな形式でモデルを生成します | リンク |
以下は、モデルをマージした後のFP16精度と4ビットの量子化サイズです。変換前にマシンに十分なメモリとディスクのスペースがあることを確認してください(最小要件)。
| モデルバージョン | 7b | 13b | 33b | 65b |
|---|---|---|---|---|
| オリジナルモデルサイズ(FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| 量子化サイズ(8ビット) | 7.8 GB | 14.9 GB | 32.4 GB | 〜60 GB |
| 量子化サイズ(4ビット) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
詳細については、このプロジェクトを参照してください>>> github wiki
このプロジェクトのモデルは、主に次の定量化、推論、展開方法をサポートしています。
| 推論と展開方法 | 特徴 | プラットフォーム | CPU | GPU | 定量的荷重 | グラフィックインターフェイス | チュートリアル |
|---|---|---|---|---|---|---|---|
| llama.cpp | 豊富な定量的オプションと効率的なローカル推論 | 一般的な | ✅ | ✅ | ✅ | リンク | |
| ?変圧器 | ネイティブトランス推論インターフェイス | 一般的な | ✅ | ✅ | ✅ | ✅ | リンク |
| Text-Generation-Webui | フロントエンドWeb UIインターフェイスを展開する方法 | 一般的な | ✅ | ✅ | ✅ | ✅ | リンク |
| ラマチャット | MacOSの下でのグラフィックインタラクティブインターフェイス | macos | ✅ | ✅ | ✅ | リンク | |
| ラングチェーン | LLMアプリケーション開発フレームワーク、二次開発に適しています | 一般的な | ✅ † | ✅ | ✅ † | リンク | |
| privategpt | Langchainに基づくマルチドキュメントローカル質問と回答フレームワーク | 一般的な | ✅ | ✅ | ✅ | リンク | |
| Colab Gradio Demo | ColabでインタラクティブなグラデーションベースのWebサービスを開始します | 一般的な | ✅ | ✅ | ✅ | リンク | |
| API呼び出し | OpenAI APIインターフェイスをエミュレートするサーバーデモ | 一般的な | ✅ | ✅ | ✅ | リンク |
† :Langchainフレームワークはそれをサポートしていますが、チュートリアルには実装されていません。詳細については、公式のLangchainドキュメントを参照してください。
詳細については、このプロジェクトを参照してください>>> github wiki
同じPROPTを考慮して、関連するモデルの実際のテキスト生成パフォーマンスを迅速に評価するために、このプロジェクトは、中国のAlpaca-7B、中国のAlpaca-33b、中国のAlpaca-Plus-7B、および中国のAlpaca-PLUS-13Bのいくつかの一般的なタスクでのAlpaca-PLUS-13Bの効果を比較およびテストしました。返信の生成はランダムであり、ハイパーパラメーターやランダムシードの解読などの要因の影響を受けます。以下の関連するレビューは、絶対に厳密ではありません。テスト結果は、参照の乾燥専用です。自分で体験できます。
このプロジェクトは、「NLU」の客観的評価セットで関連するモデルもテストしました。このタイプの評価の結果は主観的ではなく、特定のタグ(タグマッピング戦略を設計する必要がある)の出力のみを必要とするため、別の観点から大きなモデルの機能を理解できます。このプロジェクトでは、最近発売されたC-Eval評価データセットに対する関連モデルの効果をテストしました。これには、12.3K多重選択の質問と対象52人の被験者が含まれていました。以下は、いくつかのモデルの有効およびテストセット評価結果(平均)です。完全な結果については、技術レポートを参照してください。
| モデル | 有効(ゼロショット) | 有効(5ショット) | テスト(ゼロショット) | テスト(5ショット) |
|---|---|---|---|---|
| 中国アルパカプラス33b | 46.5 | 46.3 | 44.9 | 43.5 |
| 中国アルパカ-33b | 43.3 | 42.6 | 41.6 | 40.4 |
| 中国アルパカ-Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| 中国アルパカプラス7B | 36.7 | 32.9 | 36.4 | 32.3 |
| 中国語 - ラマプラス33b | 37.4 | 40.0 | 35.7 | 38.3 |
| 中国語 - ラマ-33b | 34.9 | 38.4 | 34.6 | 39.5 |
| 中国語 - ラマ-Plus-13B | 27.3 | 34.0 | 27.8 | 33.3 |
| 中国語 - ラマプラス7B | 27.3 | 28.3 | 26.9 | 28.4 |
大きなモデルの能力の包括的な評価は、緊急に解決する必要がある重要な問題であることに注意する必要があります。大きなモデルに関連するさまざまな評価結果の合理的で弁証法的な見解は、大きなモデル技術の健全な開発に役立ちます。ユーザーが懸念しているタスクでテストし、関連するタスクに適応するモデルを選択することをお勧めします。
c-val推論コードについては、このプロジェクトを参照してください>>> github wiki
トレーニングプロセス全体には、語彙の拡大、トレーニング前、監督の微調整の3つの部分が含まれます。
詳細については、このプロジェクトを参照してください>>> github wiki
よくある質問にはよくある質問が与えられます。問題を求める前に、FAQを確認してください。
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
特定の質問と回答については、このプロジェクトを参照してください>>> github wiki
このプロジェクトのモデルには、特定の中国の理解と生成能力がありますが、以下を含むがこれらに限定されない制限もあります。
このプロジェクトが調査に役立つと感じたり、このプロジェクトのコードまたはデータを使用したりする場合は、このプロジェクトを引用する技術レポートを参照してください:https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| プロジェクト名 | 導入 | タイプ |
|---|---|---|
| 中国語 - ラマ-alpaca-2 (公式プロジェクト) | 中国のllama-2、Alpaca-2ビッグモデル | 文章 |
| Visual-Chinese-llama-alpaca (公式プロジェクト) | マルチモーダルチャイニーズラマ&アルパカビッグモデル | マルチモーダル |
リストに参加したいですか? >>>申請書を送信します
このプロジェクトは、次のオープンソースプロジェクトの二次開発に基づいています。関連するプロジェクトと研究開発スタッフに感謝の気持ちを表明したいと思います。
| 基本モデル、コード | 定量化、推論、展開 | データ |
|---|---|---|
| FacebookによるLlama スタンフォードによるアルパカ @tloenによるAlpaca-Lora | @ggerganovによるllama.cpp @AlexrozanskiによるLlamachat @oobaboogaによるText-Generation-Webui | @brightmartによるPCLUEおよびMTデータ OpenAssistantによるOASST1 |
このプロジェクトに関連するリソースは、学術研究のみであり、商業目的で厳密に禁止されています。サードパーティコードを含むパーツを使用する場合は、対応するオープンソースプロトコルに厳密に従ってください。モデルによって生成されるコンテンツは、モデルの計算、ランダム性、定量的精度損失などの要因の影響を受けます。このプロジェクトは、その精度を保証するものではありません。このプロジェクトは、モデルによるコンテンツ出力に対する法的責任を想定しておらず、関連するリソースと出力結果の使用から生じる可能性のある損失についても責任を負いません。このプロジェクトは、暇なときに個人と協力者によって開始および維持されるため、対応する問題を解決するために迅速に対応できることを保証することは不可能です。
ご質問がある場合は、GitHub Issueで送信してください。丁寧に質問し、調和のとれたディスカッションコミュニティを構築します。


