KaHIP
v3.17
กรอบการแบ่งกราฟ Kahip - Karlsruhe การแบ่งพาร์ติชันคุณภาพสูง
ปัญหาการแบ่งพาร์ติชันกราฟขอให้แบ่งโหนดกราฟของกราฟเป็นบล็อกขนาดเท่ากันซึ่งจำนวนขอบที่ทำงานระหว่างบล็อกจะลดลง Kahip เป็นครอบครัวของโปรแกรมการแบ่งกราฟ มันรวมถึง Kaffpa (Karlsruhe Fast Flow Partitioner) ซึ่งเป็นอัลกอริธึมการแบ่งกราฟหลายระดับในตัวแปรที่แข็งแกร่ง Eco และ Fast, Kaffpae (Kaffpaevolutionary) ซึ่งเป็นระบบวิวัฒนาการ ยิ่งไปกว่านั้นเทคนิคพิเศษยังรวมอยู่ในเครือข่ายถนนพาร์ติชัน (buffoon) เพื่อส่งออกตัวคั่นจุดสุดยอดจากพาร์ติชันที่กำหนดรวมถึงเทคนิคที่มุ่งไปสู่การแบ่งพาร์ติชันที่มีประสิทธิภาพของเครือข่ายสังคมออนไลน์ นี่คือภาพรวมของกรอบของเรา:
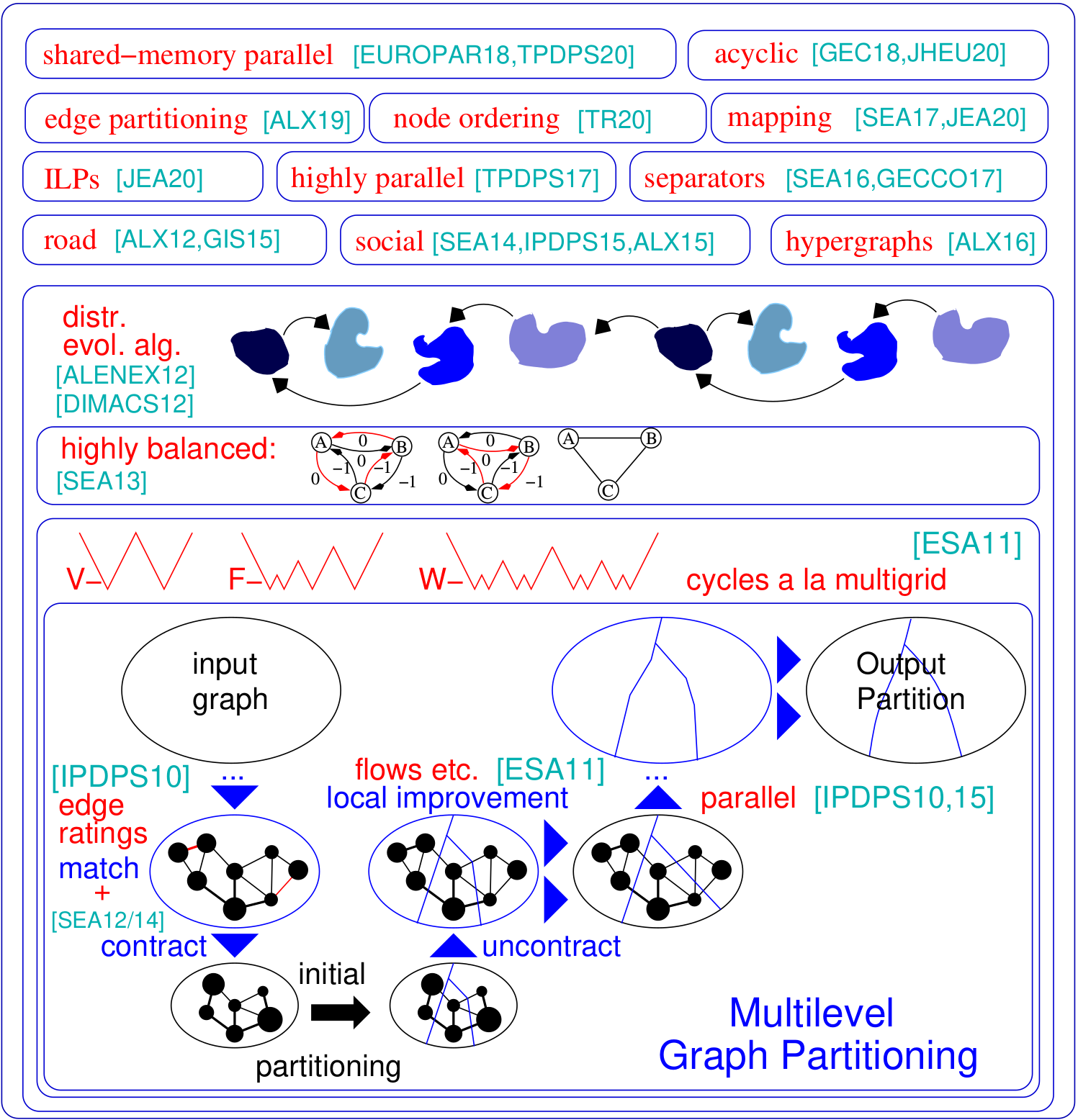
รองรับ Python : Kahip สามารถใช้ใน Python ได้ ดูด้านล่างวิธีการทำเช่นนั้น
การแบ่งลำดับชั้น : Kahip สามารถคำนวณการแบ่งลำดับชั้น สิ่งที่คุณต้องทำคือระบุลำดับชั้นและ Kahip พร้อมที่จะไปและทำหลายอย่างตามที่คุณระบุ
อัลกอริทึมการสั่งซื้อโหนด : แอปพลิเคชันจำนวนมากขึ้นอยู่กับการดำเนินการเมทริกซ์ที่ใช้เวลามากเช่นการแยกส่วนซึ่งสามารถเร่งความเร็วได้อย่างมีนัยสำคัญสำหรับเมทริกซ์เบาบางขนาดใหญ่โดยการตีความเมทริกซ์เป็นกราฟกระจัดกระจายและคำนวณโหนดที่ลดลง ที่นี่เราเพิ่มอัลกอริทึมใหม่เพื่อคำนวณการเติมคำสั่งที่ลดลงในกราฟ
ILPs สำหรับคุณภาพที่สูงขึ้น : โดยทั่วไปแล้ว ILPs จะไม่ปรับขนาดเป็นอินสแตนซ์ขนาดใหญ่ เราปรับให้เข้ากับการพัฒนาพาร์ติชันที่กำหนด เราทำเช่นนั้นโดยการกำหนดรุ่นที่เล็กกว่ามากซึ่งช่วยให้เราสามารถใช้การแตกสมมาตรและเทคนิคอื่น ๆ ที่ทำให้วิธีการปรับขนาดได้ เรารวม ILPs ที่สามารถใช้เป็นขั้นตอนหลังการประมวลผลเพื่อปรับปรุงพาร์ติชันคุณภาพสูงยิ่งขึ้น รหัสตอนนี้รวมอยู่ใน Kahip
TCMALLOC: เราเพิ่มความเป็นไปได้ในการเชื่อมโยงกับ TCMALLOC ขึ้นอยู่กับระบบของคุณสิ่งนี้สามารถให้อัลกอริทึมโดยรวมได้เร็วขึ้นเนื่องจากมีการทำงานของ Malloc ที่เร็วขึ้น
เร็วขึ้น IO : เราเพิ่มตัวเลือกให้กับ Kaffpa (ตัวเลือก -MMAP_IO) ที่เพิ่มความเร็ว iO ของไฟล์ข้อความอย่างมีนัยสำคัญ -บางครั้งตามลำดับของขนาด
เพิ่มการสนับสนุนสำหรับจุดสุดยอดและน้ำหนักขอบใน parhip : เราขยายฟังก์ชันการทำงานของ IO ของ parhip เพื่ออ่านกราฟถ่วงน้ำหนักในรูปแบบ Metis
การทำแผนที่หลายส่วนทั่วโลก : เราเพิ่มอัลกอริทึมการทำแผนที่กระบวนการ N-to-1 ทั่วโลก สิ่งนี้จะคำนวณการแมปกระบวนการที่ดีขึ้นสำหรับแอปพลิเคชันแบบขนานหากทราบข้อมูลเกี่ยวกับลำดับชั้นของระบบ/สถาปัตยกรรม
การกำหนดระดับใน parhip : เราเพิ่มตัวเลือกในการเรียกใช้ parhip ecticative, เช่นการวิ่งสองครั้งของ parhip โดยใช้เมล็ดเดียวกันจะส่งคืนผลลัพธ์เดียวกันเสมอ
Flag เวอร์ชัน : เราเพิ่มตัวเลือกในการส่งออกเวอร์ชันที่คุณใช้อยู่ในปัจจุบันใช้ตัวเลือก -เวอร์ชันของโปรแกรม
Parhip (การแบ่งพาร์ติชันคุณภาพสูงแบบขนาน): เทคนิคการแบ่งพาร์ติชันหน่วยความจำแบบขนานของเราแบบกระจายของเราได้รับการออกแบบมาเพื่อแบ่งพาร์ติชันเครือข่ายที่มีโครงสร้างแบบลำดับชั้นเช่นกราฟเว็บหรือเครือข่ายสังคมออนไลน์
อัลกอริธึมการทำแผนที่: อัลกอริทึมใหม่ของเราในการแมปบล็อกลงบนโปรเซสเซอร์เพื่อลดเวลาการสื่อสารโดยรวมตามพาร์ติชันลำดับชั้นของกราฟงานและอัลกอริทึมการค้นหาในท้องถิ่นที่รวดเร็ว
อัลกอริทึมการแบ่งพาร์ติชันขอบ: อัลกอริทึมใหม่ของเราในการคำนวณการแบ่งพาร์ติชันของกราฟ
https://kahip.github.io
คุณสามารถดาวน์โหลด kahip ด้วยบรรทัดคำสั่งต่อไปนี้:
git clone https://github.com/KaHIP/KaHIP ก่อนที่คุณจะเริ่มต้นคุณต้องติดตั้งแพ็คเกจซอฟต์แวร์ต่อไปนี้:
เมื่อคุณติดตั้งแพ็คเกจเพียงแค่พิมพ์
./compile_withcmake.sh ในกรณีนี้ไบนารีไลบรารีและส่วนหัวทั้งหมดอยู่ในโฟลเดอร์ ./deploy/
โปรดทราบว่าสคริปต์นี้ตรวจจับปริมาณคอร์ที่มีอยู่ในเครื่องของคุณและใช้ทั้งหมดสำหรับกระบวนการรวบรวม หากคุณไม่ต้องการให้ตั้งค่าตัวแปร NCores เป็นจำนวนแกนที่คุณต้องการใช้สำหรับการรวบรวม
หรือใช้กระบวนการสร้าง CMake มาตรฐาน:
mkdir build
cd build
cmake ../ -DCMAKE_BUILD_TYPE=Release
make
cd ..ในกรณีนี้ไบนารีไลบรารีและส่วนหัวอยู่ในโฟลเดอร์./build รวมถึง ./build/parallel/parallel_src/
นอกจากนี้เรายังมีตัวเลือกในการเชื่อมโยงกับ tcmalloc หากคุณติดตั้งให้เรียกใช้ cmake ด้วยตัวเลือกเพิ่มเติม -duse_tcmalloc = on
โดยเริ่มต้นโปรแกรมการสั่งซื้อโหนดเริ่มต้น หากคุณติดตั้ง Metis สคริปต์บิลด์จะรวบรวมโปรแกรมการสั่งซื้อโหนดที่เร็วขึ้นซึ่งใช้การลดลงก่อนที่จะเรียก Metis ND โปรดทราบว่า Metis ต้องการ gklib (https://github.com/karypislab/gklib)
หากคุณใช้ตัวเลือก -DUSE_ILP = ON และคุณติดตั้ง Gurobi แล้ว Build Script จะรวบรวมโปรแกรม ILP เพื่อปรับปรุงพาร์ติชันที่กำหนด ILP_IMPROVE และตัวแก้ไขที่แน่นอน ILP_EXACT หรือคุณสามารถส่งตัวเลือกเหล่านี้ไปที่./compile_withmake.sh ตัวอย่างเช่น:
./compile_withcmake -DUSE_ILP=Onนอกจากนี้เรายังมีตัวเลือกในการรองรับขอบ 64 บิต ในการใช้สิ่งนี้ให้รวบรวม kahip ด้วยตัวเลือก -d64bitmode = on
สุดท้ายเรามีตัวเลือกสำหรับการกำหนดระดับใน parhip เช่นสองวิ่งด้วยเมล็ดพันธุ์เดียวกันจะให้ผลลัพธ์เดียวกัน อย่างไรก็ตามโปรดทราบว่าตัวเลือกนี้สามารถลดคุณภาพของพาร์ติชันเนื่องจากอัลกอริทึมการแบ่งพาร์ติชันเริ่มต้นไม่ได้ใช้อัลกอริทึมความทรงจำที่ซับซ้อน แต่มีเพียงอัลกอริทึมหลายระดับเพื่อคำนวณการแบ่งพาร์ติชันเริ่มต้น ใช้ตัวเลือกนี้เฉพาะในกรณีที่คุณใช้ parhip เป็นเครื่องมือ อย่าใช้ตัวเลือกนี้หากคุณต้องการทำการเปรียบเทียบคุณภาพกับ parhip เพื่อใช้ประโยชน์จากตัวเลือกนี้ Run
./compile_withcmake -DDETERMINISTIC_PARHIP=Onสำหรับคำอธิบายของรูปแบบกราฟ (และคำอธิบายที่กว้างขวางของโปรแกรมอื่น ๆ ทั้งหมด) โปรดดูคู่มือ เราให้ตัวอย่างสั้น ๆ ที่นี่
โปรแกรมและการกำหนดค่าเหล่านี้ใช้กราฟและแบ่งพาร์ติชันตามลำดับไม่มากก็น้อย เราแสดงรายการที่นี่ Kaffpa และ Kaffpae (เฟรมเวิร์กวิวัฒนาการ) และการกำหนดค่าของพวกเขา โดยทั่วไปการกำหนดค่าเป็นเช่นนั้นคุณสามารถลงทุนเวลามากในคุณภาพการแก้ปัญหาโดยใช้อัลกอริทึม Memetic อัลกอริทึม Memetic สามารถทำงานได้แบบขนานโดยใช้ MPI โดยทั่วไปยิ่งเวลาและทรัพยากรที่คุณลงทุนมากเท่าใดก็ยิ่งดีกว่าคุณภาพของพาร์ติชันของคุณ เรามีการแลกเปลี่ยนจำนวนมากติดต่อเราหากคุณไม่แน่ใจว่าอะไรดีที่สุดสำหรับแอปพลิเคชันของคุณ สำหรับคำอธิบายของอัลกอริทึมมีการดูข้อมูลอ้างอิงที่เราแสดงในคู่มือ
| ใช้เคส | ป้อนข้อมูล | โปรแกรม |
|---|---|---|
| รูปแบบกราฟ | graph_checker | |
| ประเมินพาร์ติชัน | ผู้ประเมินผล | |
| การแบ่งพาร์ติชันอย่างรวดเร็ว | ตาข่าย | Kaffpa preconfiguration ตั้งค่าเป็น FAST |
| การแบ่งพาร์ติชันที่ดี | ตาข่าย | Kaffpa preconfiguration ตั้งค่าเป็น eco |
| การแบ่งพาร์ติชันที่ดีมาก | ตาข่าย | Kaffpa preconfiguration ตั้งค่าเป็น strong |
| คุณภาพสูงสุด | ตาข่าย | Kaffpae ใช้ Mpirun จำกัด เวลาขนาดใหญ่ |
| การแบ่งพาร์ติชันอย่างรวดเร็ว | ทางสังคม | kaffpa preconfiguration ตั้งค่าเป็น fsocial |
| การแบ่งพาร์ติชันที่ดี | ทางสังคม | kaffpa preconfiguration ตั้งค่าเป็น esocial |
| การแบ่งพาร์ติชันที่ดีมาก | ทางสังคม | kaffpa preconfiguration ตั้งค่าเป็น ssocial |
| คุณภาพสูงสุด | ทางสังคม | kaffpae, ใช้ mpirun, ขีด จำกัด เวลาขนาดใหญ่, preconfiguration ssocial |
| คุณภาพที่สูงขึ้น | kaffpae, ใช้ mpirun, เวลาขนาดใหญ่ใช้ตัวเลือก --mh_enable_tabu_search, --mh_enable_kabape |
./deploy/graph_checker ./examples/rgg_n_2_15_s0.graph ./deploy/kaffpa ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=strong mpirun -n 24 ./deploy/kaffpaE ./examples/rgg_n_2_15_s0.graph --k 4 --time_limit=3600 --mh_enable_tabu_search --mh_enable_kabapE ส่วนใหญ่ของโครงการคืออัลกอริทึมแบบขนานหน่วยความจำที่ออกแบบมาสำหรับเครือข่ายที่มีโครงสร้างคลัสเตอร์แบบลำดับชั้นเช่นกราฟเว็บหรือเครือข่ายสังคมออนไลน์ น่าเสียดายที่พาร์ทิชันกราฟแบบขนานก่อนหน้านี้พัฒนาขึ้นสำหรับเครือข่ายที่มีลักษณะคล้ายตาข่ายปกติมากขึ้นนั้นไม่ได้ผลสำหรับเครือข่ายที่ซับซ้อน ที่นี่เราจัดการกับปัญหานี้โดยการขนานและปรับใช้เทคนิคการแพร่กระจายฉลากเดิมที่พัฒนาขึ้นสำหรับการจัดกลุ่มกราฟ ด้วยการแนะนำข้อ จำกัด ขนาดการแพร่กระจายของฉลากจะใช้ได้กับทั้งระยะการหยาบและขั้นตอนการปรับแต่งของการแบ่งกราฟหลายระดับ วิธีนี้เราใช้ประโยชน์จากโครงสร้างคลัสเตอร์แบบลำดับชั้นที่มีอยู่ในเครือข่ายที่ซับซ้อนหลายแห่ง เราได้รับคุณภาพสูงมากโดยใช้อัลกอริทึมวิวัฒนาการแบบขนานอย่างสูงกับกราฟที่หยาบที่สุด ระบบที่ได้นั้นสามารถปรับขนาดได้มากขึ้นและมีคุณภาพสูงกว่าระบบที่ทันสมัยเช่น Parmetis หรือ PT-Scotch
อัลกอริทึมแบบขนานหน่วยความจำแบบกระจายของเราสามารถอ่านไฟล์ไบนารีรวมถึงไฟล์รูปแบบกราฟ Metis มาตรฐาน โดยทั่วไปไฟล์ไบนารีนั้นปรับขนาดได้มากกว่าการอ่านไฟล์ข้อความในแอปพลิเคชันคู่ขนาน วิธีที่จะไปที่นี่คือการแปลงไฟล์ metis เป็นไฟล์ไบนารีก่อน (สิ้นสุด. bgf) จากนั้นโหลดไฟล์นี้
| ใช้เคส | โปรแกรม |
|---|---|
| การแบ่งพาร์ติชันแบบขนาน | parhip, graph2binary, graph2binary_external, กล่องเครื่องมือ |
| หน่วยความจำแบบกระจายขนานตาข่าย | parhip กับ preconfigs ecomesh, fastmesh, ultrafastmesh |
| กระจายความทรงจำขนานสังคม | parhip กับ preconfigs ecosocial, fastsocial, ultrafastsocial |
| แปลง Metis เป็นไบนารี | graph2binary, graph2binary_external |
| ประเมินและแปลงพาร์ติชัน | กล่องเครื่องมือ |
./deploy/graph2binary examples/rgg_n_2_15_s0.graph examples/rgg_n_2_15_s0.bgf mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fastmesh mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastmeshปัญหาตัวคั่นโหนดขอให้แบ่งพาร์ติชันชุดโหนดของกราฟเป็นสามชุด A, B และ S เพื่อให้การลบการเชื่อมต่อ A และ B เราใช้อัลกอริธึมการค้นหาในท้องถิ่นที่ใช้การไหลและท้องถิ่นภายในกรอบหลายระดับเพื่อคำนวณตัวคั่นโหนด Kahip ยังสามารถคำนวณตัวคั่นโหนดได้ มันสามารถทำได้ด้วยตัวคั่นโหนดมาตรฐาน (2-way) แต่ยังสามารถคำนวณตัวคั่นโหนด K-way ได้
| ใช้เคส | โปรแกรม |
|---|---|
| ตัวแยก 2 ทาง | node_separator |
| ตัวแยก Kway | ใช้ kaffpa เพื่อสร้าง k-partition จากนั้น partition_to_vertex_separator เพื่อสร้างตัวคั่น |
./deploy/node_separator examples/rgg_n_2_15_s0.graphแอพพลิเคชั่นเช่นการแยกตัวประกอบสามารถเร่งความเร็วได้อย่างมีนัยสำคัญสำหรับเมทริกซ์ขนาดใหญ่ขนาดใหญ่โดยการตีความเมทริกซ์เป็นกราฟกระจัดกระจายและคำนวณโหนดที่สั่งซื้อที่ลดการเติมที่เรียกว่า ด้วยการใช้กฎการลดข้อมูลทั้งใหม่และที่มีอยู่อย่างละเอียดก่อนการผ่าที่ซ้อนกันเราจะได้รับคุณภาพที่ดีขึ้นและในเวลาเดียวกันการปรับปรุงครั้งใหญ่ในเวลาทำงานในหลากหลายกรณี หากติดตั้ง METIS สคริปต์บิลด์จะรวบรวมโปรแกรม FAST_NODE_ORRDERING ซึ่งจะลดการลดลงก่อนที่จะเรียกใช้ METIS เพื่อคำนวณการสั่งซื้อ โปรแกรมยังมีให้บริการผ่านห้องสมุด
| ใช้เคส | โปรแกรม |
|---|---|
| การสั่งซื้อโหนด | node_ordering (พร้อม preconfigurations ที่แตกต่างกัน) |
| การสั่งซื้อโหนดที่รวดเร็ว | fast_node_ordering |
./deploy/node_ordering examples/rgg_n_2_15_s0.graph ./deploy/fast_node_ordering examples/rgg_n_2_15_s0.graphการคำนวณแบบกระจายแบบศูนย์กลางนั้นปรากฏเป็นเทคนิคล่าสุดในการปรับปรุงข้อบกพร่องของอัลกอริทึมแบบ Think-A-Vertex บนเครือข่ายขนาดใหญ่ที่ไม่มีขนาดใหญ่ เพื่อเพิ่มความเท่าเทียมในโมเดลนี้การแบ่งพาร์ติชันขอบ-การแบ่งพาร์ติชันเป็นบล็อกขนาดเท่ากัน-ได้กลายเป็นทางเลือกแทนการแบ่งกราฟแบบดั้งเดิม (ตามโหนด) เรารวมอัลกอริทึมการสร้างกราฟแบบแยกและเชื่อมต่อแบบต่อเนื่องที่รวดเร็วและต่อเนื่องซึ่งให้พาร์ติชันขอบคุณภาพสูงในวิธีที่ปรับขนาดได้ เทคนิคของเราปรับขนาดเป็นเครือข่ายที่มีขอบหลายพันล้านและทำงานได้อย่างมีประสิทธิภาพบน PES หลายพัน PEs
| ใช้เคส | โปรแกรม |
|---|---|
| การแบ่งขอบ | edge_partitioning, distributed_edge_partitioning |
./deploy/edge_partitioning ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fast mpirun -n 4 ./deploy/distributed_edge_partitioning ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastsocial การสื่อสารและทอพอโลยีการทำแผนที่กระบวนการรับรู้เป็นวิธีที่มีประสิทธิภาพในการลดเวลาการสื่อสารในแอพพลิเคชั่นคู่ขนานที่มีรูปแบบการสื่อสารที่รู้จักในระบบหน่วยความจำขนาดใหญ่กระจาย เราแก้ไขปัญหาเป็นปัญหาการมอบหมายกำลังสอง (QAP) และรวมอัลกอริทึมเพื่อสร้างการแมปเริ่มต้นของกระบวนการไปยังโปรเซสเซอร์รวมถึงอัลกอริทึมการค้นหาในท้องถิ่นที่รวดเร็วเพื่อปรับปรุงการแมปต่อไป ด้วยการใช้ประโยชน์จากสมมติฐานที่มักจะใช้สำหรับแอพพลิเคชั่นและระบบซูเปอร์คอมพิวเตอร์ที่ทันสมัยเช่นรูปแบบการสื่อสารที่กระจัดกระจายและระบบการสื่อสารที่จัดลำดับชั้นเรามาถึงอัลกอริทึมที่ทรงพลังกว่าสำหรับ QAPs พิเศษเหล่านี้ อัลกอริทึมการก่อสร้างหลายระดับของเราใช้เทคนิคการแบ่งกราฟที่สมดุลอย่างสมบูรณ์แบบและใช้ประโยชน์จากลำดับชั้นของระบบการสื่อสารที่กำหนด ตั้งแต่ v3.0 เรารวมอัลกอริทึมหลายส่วนทั่วโลกที่แบ่งพาร์ติชันโดยตรงเครือข่ายอินพุตตามลำดับชั้นที่ระบุเพื่อให้ได้การแมป N-to-1 และหลังจากนั้นโทรอัลกอริทึมการทำแผนที่ 1 ถึง 1 เพื่อปรับปรุงการแมปต่อไป
| ใช้เคส | โปรแกรม |
|---|---|
| การทำแผนที่ไปยังเครือข่ายโปรเซสเซอร์ | kaffpa และใช้ตัวเลือก enable_mapping กับ resp การรับรู้ |
| ทั่วโลก | global_multisection กับ resp การรับรู้ |
./deploy/kaffpa examples/rgg_n_2_15_s0.graph --k 256 --preconfiguration=eco --enable_mapping --hierarchy_parameter_string=4:8:8 --distance_parameter_string=1:10:100 ./deploy/global_multisection examples/rgg_n_2_15_s0.graph --preconfiguration=eco --hierarchy_parameter_string=4:3:3:3 --distance_parameter_string=1:10:100:200เราให้บริการ ILP เช่นเดียวกับ ILP เพื่อปรับปรุงพาร์ติชันที่กำหนด เราขยายพื้นที่ใกล้เคียงของปัญหาการรวมกันสำหรับการค้นหาในท้องถิ่นหลายครั้งโดยใช้การเขียนโปรแกรมเชิงเส้นจำนวนเต็ม สิ่งนี้ช่วยให้เราสามารถค้นหาชุดค่าผสมที่ซับซ้อนยิ่งขึ้นและด้วยเหตุนี้เพื่อปรับปรุงการแก้ปัญหาเพิ่มเติม อย่างไรก็ตามออกจากกล่องที่ ILPs สำหรับปัญหามักจะไม่ปรับขนาดเป็นอินพุตขนาดใหญ่โดยเฉพาะอย่างยิ่งเนื่องจากปัญหาการแบ่งพาร์ติชันกราฟมีความสมมาตรจำนวนมาก - เนื่องจากพาร์ติชันของกราฟแต่ละการเปลี่ยนแปลงของ ID บล็อกให้โซลูชันที่มีวัตถุประสงค์และสมดุลเดียวกัน เรากำหนดกราฟที่เล็กกว่ามากเรียกว่าโมเดลและแก้ปัญหาการแบ่งพาร์ติชันกราฟบนโมเดลเพื่อการเพิ่มประสิทธิภาพโดยโปรแกรมเชิงเส้นจำนวนเต็ม นอกจากสิ่งอื่น ๆ รุ่นนี้ยังช่วยให้เราสามารถใช้การแตกสมมาตรซึ่งช่วยให้เราสามารถปรับขนาดอินพุตที่ใหญ่ขึ้นได้ ในการรวบรวมโปรแกรมเหล่านี้คุณต้องเรียกใช้ cmake ในกระบวนการสร้างด้านบนเป็น cmake ../ -dcmake_build_type = release -duse_ilp = on หรือ run ./compile_withcmake -duse_ilp = on
| ใช้เคส | โปรแกรม |
|---|---|
| ผู้แก้ปัญหาที่แน่นอน | ilp_exact |
| การปรับปรุงผ่าน ILP | ilp_improve |
./deploy/ilp_improve ./examples/rgg_n_2_15_s0.graph --k 4 --input_partition=tmppartition4 ./deploy/ilp_exact ./examples/example_weighted.graph --k 3Kahip ยังมีไลบรารีและอินเทอร์เฟซเพื่อเชื่อมโยงอัลกอริทึมไปยังรหัสของคุณโดยตรง เราอธิบายรายละเอียดของอินเทอร์เฟซในคู่มือ ด้านล่างเราแสดงรายการโปรแกรมตัวอย่างที่เชื่อมโยงไลบรารี Kahip ตัวอย่างนี้ยังสามารถพบได้ใน MISC/EXTRACE_LIBRARY_CALL/
# include < iostream >
# include < sstream >
# include " kaHIP_interface.h "
int main ( int argn, char **argv) {
std::cout << " partitioning graph from the manual " << std::endl;
int n = 5 ;
int * xadj = new int [ 6 ];
xadj[ 0 ] = 0 ; xadj[ 1 ] = 2 ; xadj[ 2 ] = 5 ; xadj[ 3 ] = 7 ; xadj[ 4 ] = 9 ; xadj[ 5 ] = 12 ;
int * adjncy = new int [ 12 ];
adjncy[ 0 ] = 1 ; adjncy[ 1 ] = 4 ; adjncy[ 2 ] = 0 ; adjncy[ 3 ] = 2 ; adjncy[ 4 ] = 4 ; adjncy[ 5 ] = 1 ;
adjncy[ 6 ] = 3 ; adjncy[ 7 ] = 2 ; adjncy[ 8 ] = 4 ; adjncy[ 9 ] = 0 ; adjncy[ 10 ] = 1 ; adjncy[ 11 ] = 3 ;
double imbalance = 0.03 ;
int * part = new int [n];
int edge_cut = 0 ;
int nparts = 2 ;
int * vwgt = NULL ;
int * adjcwgt = NULL ;
kaffpa (&n, vwgt, xadj, adjcwgt, adjncy, &nparts, &imbalance, false , 0 , ECO, & edge_cut, part);
std::cout << " edge cut " << edge_cut << std::endl;
}Kahip ยังสามารถใช้ใน Python หากคุณต้องการใช้ใน Python First Run
python3 -m pip install pybind11
จากนั้นวิ่ง
./compile_withcmake.sh BUILDPYTHONMODULEเพื่อสร้างโมเดล Python สิ่งนี้จะสร้างโมดูล Python และใส่ตัวอย่าง callkahipfrompython.py ลงในโฟลเดอร์ปรับใช้ คุณสามารถเรียกใช้สิ่งนี้ได้โดยพิมพ์ต่อไปนี้ในโฟลเดอร์ Deploy:
python3 callkahipfrompython.py โปรดทราบว่าเราให้การสนับสนุนเบื้องต้นเท่านั้นเช่นคุณอาจต้องเปลี่ยนเส้นทางบางเส้นทางเป็น Python ภายในไฟล์ compile_withcmake ตัวอย่างสามารถพบได้ด้านล่าง:
import kahip ;
#build adjacency array representation of the graph
xadj = [ 0 , 2 , 5 , 7 , 9 , 12 ];
adjncy = [ 1 , 4 , 0 , 2 , 4 , 1 , 3 , 2 , 4 , 0 , 1 , 3 ];
vwgt = [ 1 , 1 , 1 , 1 , 1 ]
adjcwgt = [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]
supress_output = 0
imbalance = 0.03
nblocks = 2
seed = 0
# set mode
#const int FAST = 0;
#const int ECO = 1;
#const int STRONG = 2;
#const int FASTSOCIAL = 3;
#const int ECOSOCIAL = 4;
#const int STRONGSOCIAL = 5;
mode = 0
edgecut , blocks = kahip . kaffpa ( vwgt , xadj , adjcwgt ,
adjncy , nblocks , imbalance ,
supress_output , seed , mode )
print ( edgecut )
print ( blocks )โปรแกรมได้รับใบอนุญาตภายใต้ใบอนุญาต MIT หากคุณเผยแพร่ผลลัพธ์โดยใช้อัลกอริทึมของเราโปรดรับทราบผลงานของเราโดยอ้างถึงบทความต่อไปนี้:
@inproceedings{sandersschulz2013,
AUTHOR = {Sanders, Peter and Schulz, Christian},
TITLE = {{Think Locally, Act Globally: Highly Balanced Graph Partitioning}},
BOOKTITLE = {Proceedings of the 12th International Symposium on Experimental Algorithms (SEA'13)},
SERIES = {LNCS},
PUBLISHER = {Springer},
YEAR = {2013},
VOLUME = {7933},
PAGES = {164--175}
}
หากคุณใช้ parhip พาร์ทิชันคู่ขนานของเราโปรดอ้างอิงกระดาษต่อไปนี้ด้วย:
@inproceedings{meyerhenkesandersschulz2017,
AUTHOR = {Meyerhenke, Henning and Sanders, Peter and Schulz, Christian},
TITLE = {{Parallel Graph Partitioning for Complex Networks}},
JOURNAL = {IEEE Transactions on Parallel and Distributed Systems (TPDS)},
VOLUME = {28},
NUMBER = {9},
PAGES = {2625--2638},
YEAR = {2017}
}
หากคุณใช้อัลกอริทึมการทำแผนที่โปรดอ้างถึงกระดาษต่อไปนี้ด้วย:
@inproceedings{schulztraeff2017,
AUTHOR = {Schulz, Christian and Träff, Jesper Larsson},
TITLE = {{Better Process Mapping and Sparse Quadratic Assignment}},
BOOKTITLE = {Proceedings of the 16th International Symposium on Experimental Algorithms (SEA'17)},
PUBLISHER = {Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik},
VOLUME = {75},
SERIES = {LIPIcs},
PAGES = {4:1--4:15},
YEAR = {2017}
}
หากคุณใช้อัลกอริทึมการแบ่งพาร์ติชันขอบโปรดอ้างอิงกระดาษต่อไปนี้ด้วย:
@inproceedings{edgepartitioning2019,
AUTHOR = {Schlag, Sebastian and Schulz, Christian and Seemaier, Daniel and Strash, Darren},
TITLE = {{Scalable Edge Partitioning}},
BOOKTITLE = {Proceedings of the 21th Workshop on Algorithm Engineering and Experimentation (ALENEX)},
PUBLISHER = {SIAM},
PAGES = {211--225},
YEAR = {2019}
}
หากคุณใช้อัลกอริทึมการสั่งซื้อโหนดโปรดอ้างอิงกระดาษต่อไปนี้ด้วย:
@article{DBLP:journals/corr/abs-2004-11315,
author = {Wolfgang Ost and
Christian Schulz and
Darren Strash},
title = {Engineering Data Reduction for Nested Dissection},
journal = {CoRR},
volume = {abs/2004.11315},
year = {2020},
url = {https://arxiv.org/abs/2004.11315},
archivePrefix = {arXiv},
eprint = {2004.11315},
timestamp = {Tue, 28 Apr 2020 16:10:02 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2004-11315.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
หากคุณใช้อัลกอริทึม ILP เพื่อปรับปรุงพาร์ติชันโปรดอ้างถึงกระดาษต่อไปนี้:
@inproceedings{DBLP:conf/wea/HenzingerN018,
author = {Alexandra Henzinger and
Alexander Noe and
Christian Schulz},
title = {ILP-based Local Search for Graph Partitioning},
booktitle = {17th International Symposium on Experimental Algorithms, {SEA} 2018},
pages = {4:1--4:15},
year = {2018},
url = {https://doi.org/10.4230/LIPIcs.SEA.2018.4},
doi = {10.4230/LIPIcs.SEA.2018.4},
series = {LIPIcs},
volume = {103},
publisher = {Schloss Dagstuhl - Leibniz-Zentrum f{"{u}}r Informatik}
}
Yaroslav Akhremtsev
Adil Chhabra
Marcelo Fonseca Faraj
Roland Glantz
Alexandra Henzinger
Dennis Luxen
Henning Meyerhenke
Alexander Noe
Mark Olesen
Lara Ost
Ilya Safro
ปีเตอร์แซนเดอร์ส
Hayk Sargsyan
Sebastian Schlag
Christian Schulz (ผู้ดูแล)
Daniel Seemaier
Darren Strash
Jesper Larsson Träff


